 QuestDB時序數據庫性能居然領先ClickHouse和InfluxDB這么多
QuestDB時序數據庫性能居然領先ClickHouse和InfluxDB這么多

作者:Vlad Ilyushchenko,QuestDB的CTO
在QuestDB (https://questdb.io/, https://github.com/questdb/questdb),我們已經建立了一個專注于性能的開源時間序列數據庫。我們創建QuestDB初衷是為了將我們在超低延遲交易方面的經驗以及我們在該領域開發的技術方法帶到各種實時數據處理用途中。
QuestDB的旅程始于2013年的原型設計,我們在去年HackerNews發布會期間(https://news.ycombinator.com/item?id=23975807)發表的一篇文章中描述了2013年之后所發生的變化。我們的用戶在金融服務、物聯網、應用監控和機器學習領域都部署了QuestDB,使時間序列分析變得快速、高效和便捷。
什么是存儲時間序列數據的最佳方式?
在項目的早期階段,我們受到了基于矢量的append-only系統(如kdb+)的啟發,因為這種模型帶來了速度和簡潔代碼路徑的優勢。QuestDB的數據模型使用了我們稱之為基于時間的數組,這是一種線性數據結構。這允許QuestDB在數據獲取過程中把數據切成小塊,并以并行方式處理所有數據。以錯誤的時間順序到達的數據在被持久化到磁盤之前會在內存中進行處理和重新排序。因此,數據在到達數據庫中之前已經按時間排序。因此,QuestDB不依賴計算密集的索引來為任何時間序列的查詢重新排序數據。
這種liner模型與其他開源數據庫(如InfluxDB或TimescaleDB)中的LSM樹或基于B樹的存儲引擎不同。
除了更好的數據獲取能力,QuestDB的數據布局使CPU能夠更快地訪問數據。我們的代碼庫利用最新CPU架構的SIMD指令,對多個數據元素并行處理同類操作。我們將數據存儲在列中,并按時間進行分區,以在查詢時從磁盤中提取最小的數據量。
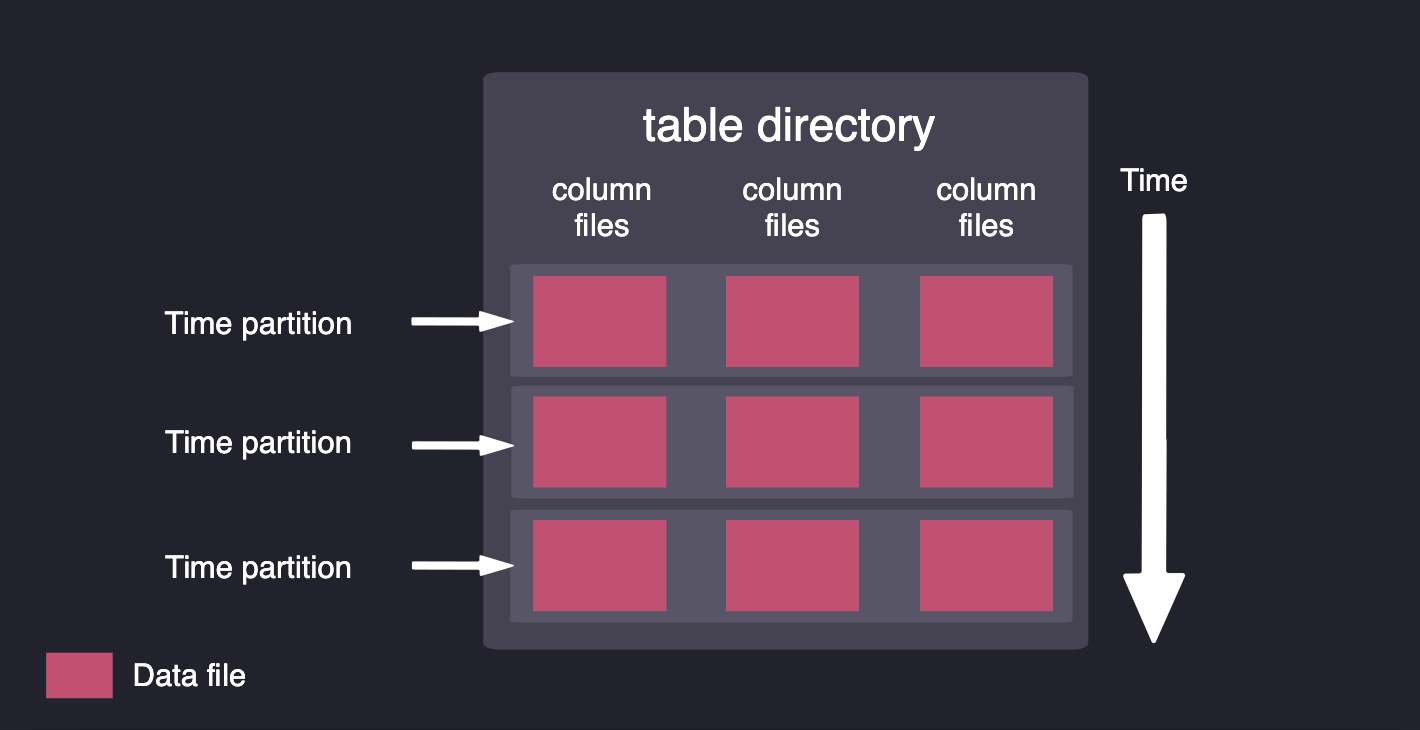
數據被存儲在列中,并按時間進行分區
QuestDB與ClickHouse、InfluxDB和TimescaleDB相比如何?
我們看到時間序列基準測試套件(TSBS https://github.com/timescale/tsbs)經常出現在關于數據庫性能的討論,因此我們決定提供對QuestDB和其他系統進行基準測試的能力。TSBS是一個Go程序集,用于生成數據集,然后對讀寫性能進行基準測試。該套件是可擴展的,因此可以包括不同的用例和查詢類型,并在不同系統之間進行比較。
以下是我們在AWS EC2 m5.8xlarge實例上使用多達14個worker的純cpu用例的基準測試結果,該實例有16個內核。
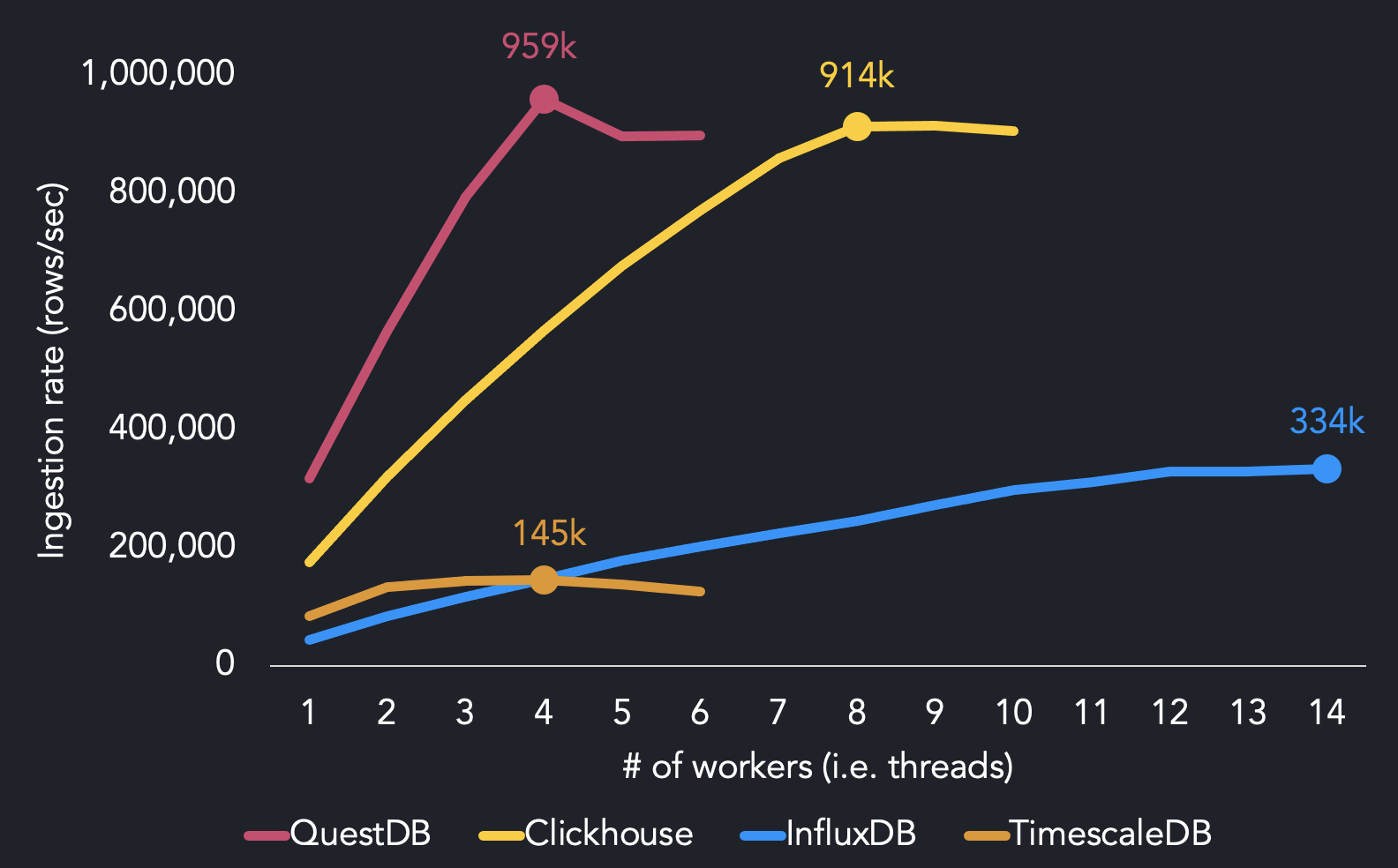
TSBS結果比較了QuestDB、InfluxDB、ClickHouse和TimescaleDB的最大獲取吞吐量。
我們使用4個worker達到最大的攝取性能,而其他系統需要更多的CPU資源來達到最大的吞吐量。QuestDB用4個線程達到了95.9萬行/秒。我們發現InfluxDB需要14個線程才能達到最大的攝取率(334k行/秒),而TimescaleDB用4個線程達到145k行/秒。ClickHouse以兩倍于QuestDB的線程達到914k行/秒。
當在4個線程上運行時,QuestDB比ClickHouse快1.7倍,比InfluxDB快6.5倍,比TimescaleDB快6.6倍。
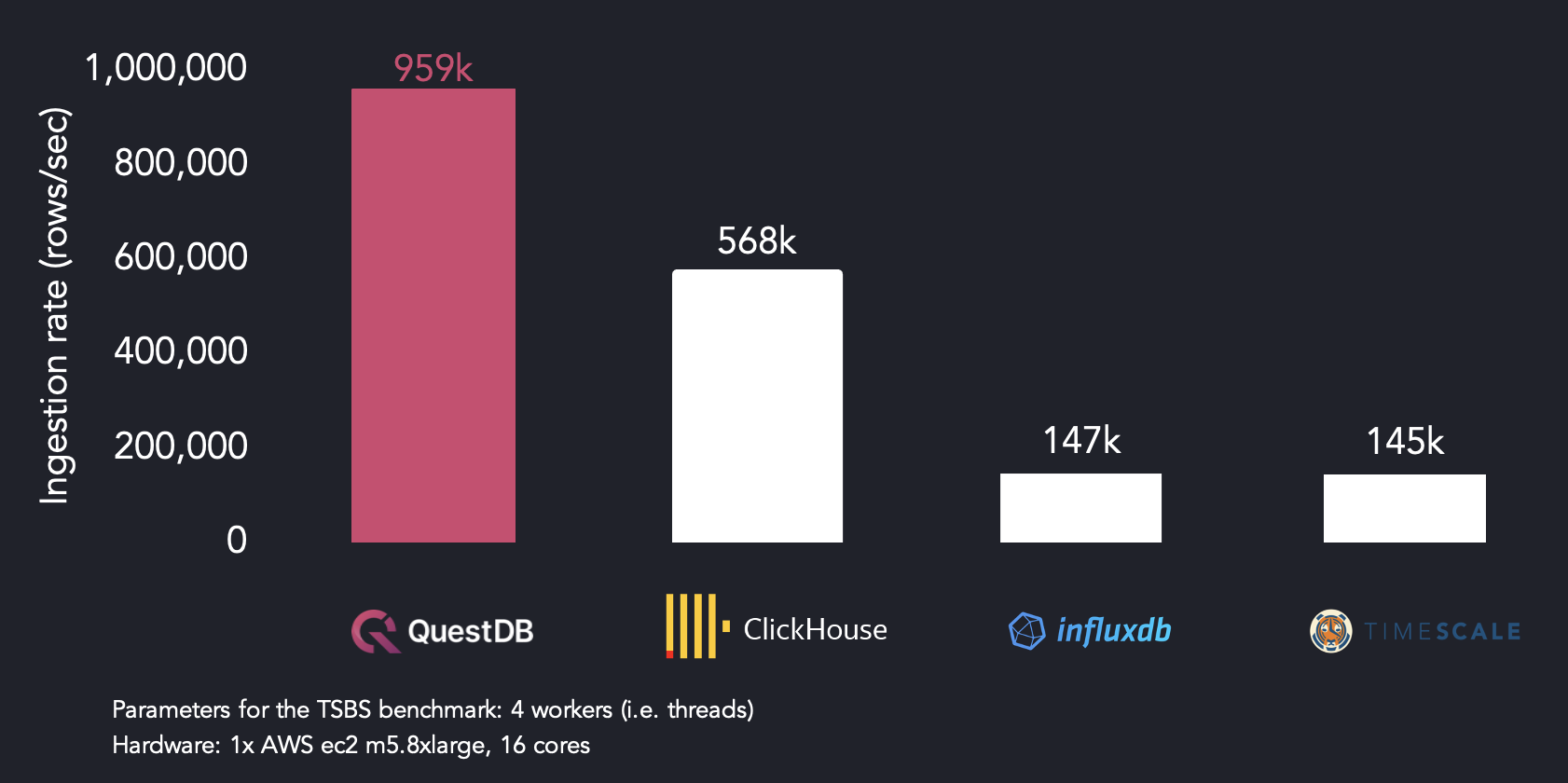
使用4個線程的TSBS基準測試結果:QuestDB、InfluxDB、ClickHouse和TimescaleDB每秒獲取的行數。
當我們使用AMD Ryzen5處理器再次運行該套件時,我們發現,我們能夠使用5個線程達到每秒143萬行的最大吞吐量。與我們在AWS上的參考基準m5.8xlarge實例所使用的英特爾至強Platinum相比:
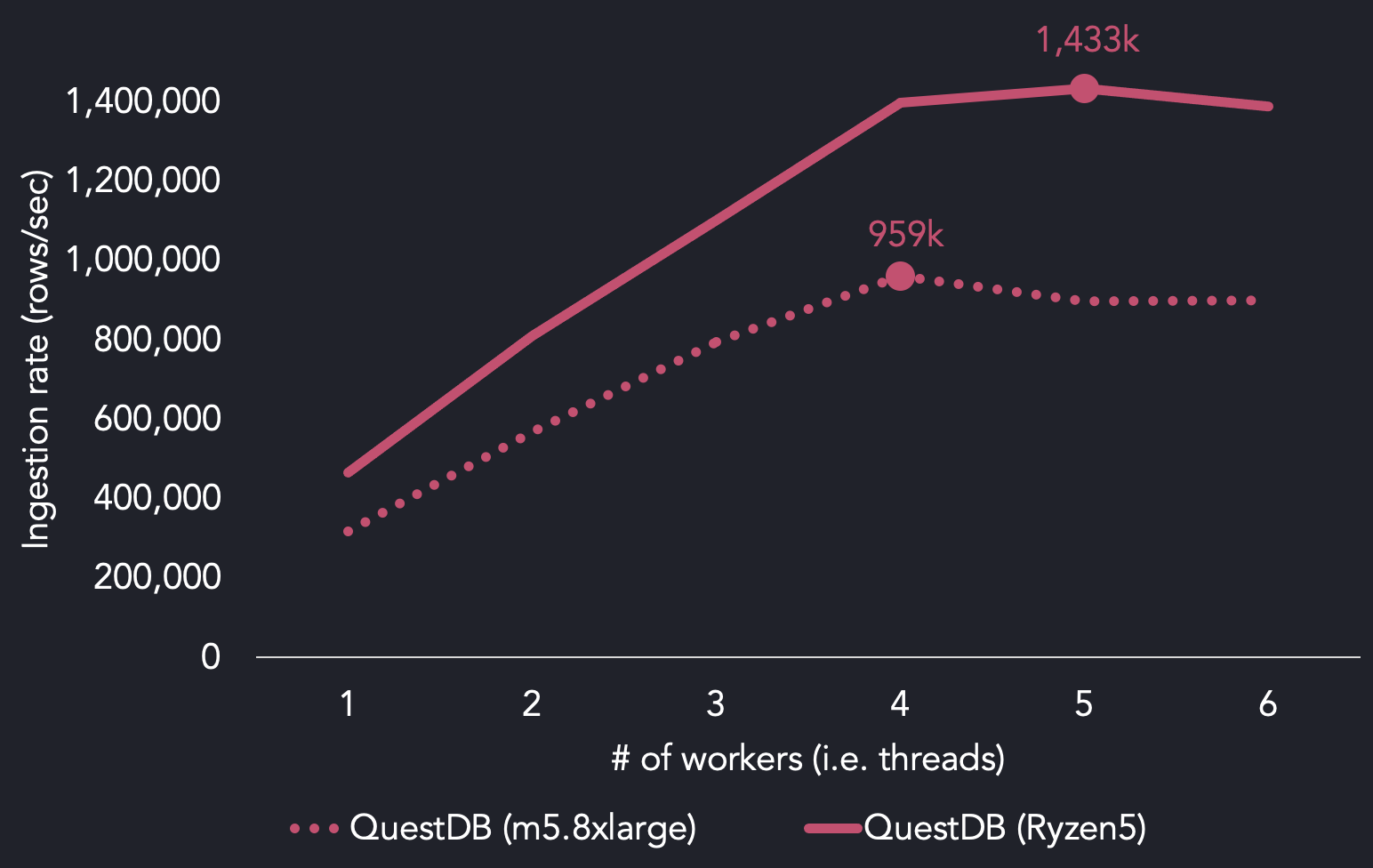
比較QuestDB TSBS在AWS EC2與AMD Ryzen5上的負載結果
你應該如何存儲亂序的時間序列數據?
事實證明,在攝取過程中對 "亂序"(O3)的數據進行重新排序特別具有挑戰性。這是一個新的方法,我們想在這篇文章中詳細介紹一下。我們對如何處理失序攝取的想法是增加一個三階段的方法。
1.保持追加模式,直到記錄不按順序到達為止
2.在內存中對暫存區的未提交的記錄進行排序
3.在提交時對分類的無序數據和持久化的數據進行核對和合并
前兩個步驟很直接,也很容易實現,依然只是處理追加的數據,這一點沒變。只有在暫存區有數據的時候,昂貴的失序提交才會啟動。這種設計的好處是,輸出是向量,這意味著我們基于向量的閱讀器仍然是兼容的。
這種預提交的排序和合并方式給數據獲取增加了一個額外的處理階段,同時也帶來了性能上的損失。不過,我們還是決定探索這種方法,看看我們能在多大程度上通過優化失序提交來減少性能損耗。
我們如何分類、合并和提交無序的時間序列數據
處理一個暫存區給了我們一個獨特的機會來全面分析數據,在這里我們可以完全避免物理合并,并通過快速和直接的memcpy或類似的數據移動方法來替代。由于我們的基于列的存儲,這種方法可以被并行化。我們可以采用SIMD和非時序數據訪問,這對我們來說是很重要的。
我們通過優化版本的radix排序對來自暫存區的時間戳列進行排序,所產生的索引被用于并行對暫存區的其余列進行排序。
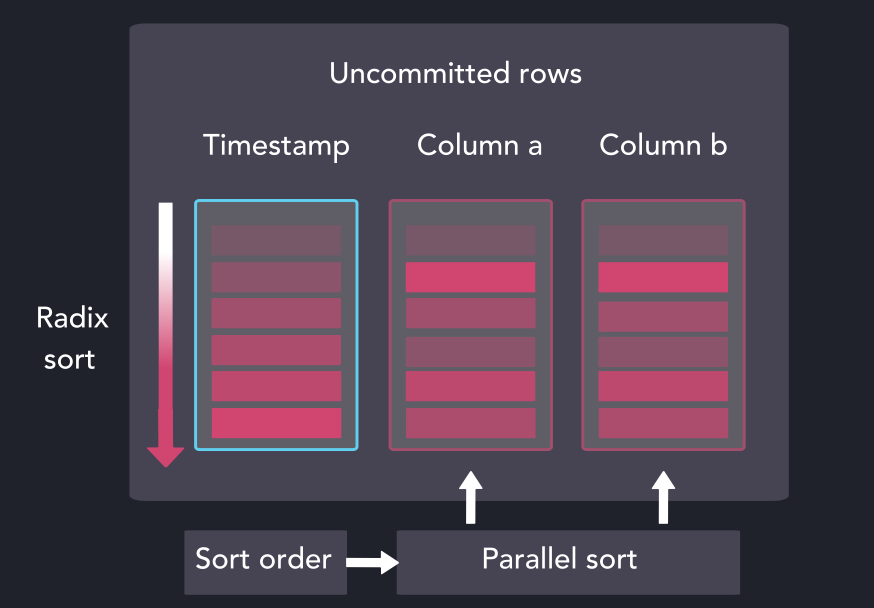
并行得將列進行排序
現在排序的暫存區是相對于現有分區數據進行映射的。從一開始可能并不明顯,但我們正試圖為以下三種類型的每一種建立所需的操作和維度。
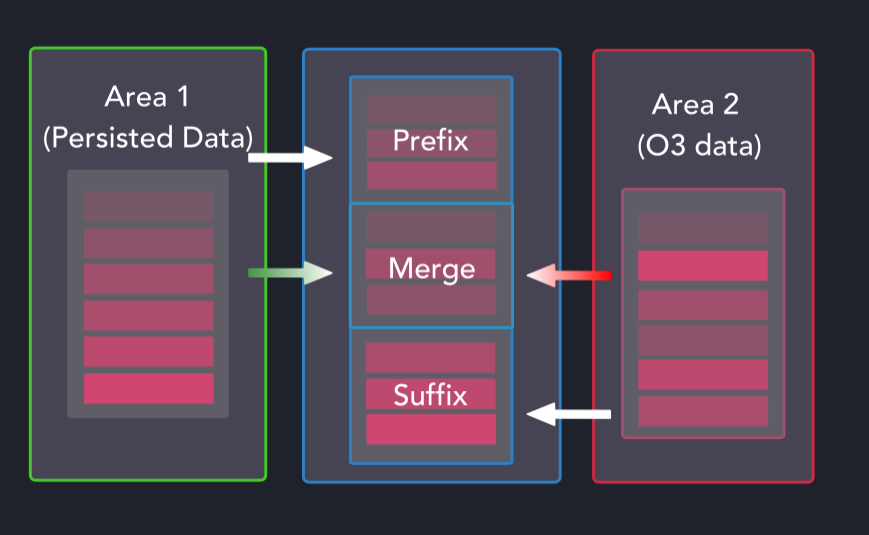
失序(O3)排序和合并方案
當以這種方式合并數據集時,前綴和后綴組可以是持續的數據、失序的數據,或者沒有數據。合并組(Merge Group)是最繁忙的,因為它可以被持久化的數據、失序的數據、失序的數據和持久化的數據占據,或者沒有數據。
當明確了如何分組和處理暫存區的數據時,一個工人池就會執行所需的操作,在少量的情況下調用memcpy,其他都轉向SIMD優化的代碼。通過前綴、合并和后綴拆分,提交的最大活度(增加CPU容量的易感性)可以通過partition_affected x number_of_columns x 3得到。
時間序列數據應該多久進行一次排序和合并?
能夠快速復制數據是一個不錯的選擇,但我們認為在大多數時間序列獲取場景中可以避免大量的數據復制。假設大多數實時失序的情況是由傳遞機制和硬件抖動造成的,我們可以推斷出時間戳分布將在一定區間范圍。
例如,如果任何新的時間戳值有很大概率落在先前收到的值的10秒內,那么邊界就是10秒,我們稱這個為滯后邊界。
當時間戳值遵循這種模式時,推遲提交可以使失序提交成為正常的追加操作。失序系統可以處理任何種類的延遲,但如果延遲的數據在指定的滯后邊界內到達,它將被優先快速處理。
如何比較時間序列數據庫的性能
我們已經在TimescaleDB的TSBS GitHub倉庫中開啟了一個合并請求(Questdb基準支持 https://github.com/timescale/tsbs/issues/157),增加了針對QuestDB運行基準測試的能力。同時,用戶可以克隆我們的基準測試fork(https://github.com/questdb/tsbs),并運行該套件以查看自己的結果。
tsbs_generate_data --use-case="cpu-only" --seed=123 --scale=4000 `。
--timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-02T00:00:00Z" \
--log-interval="10s" --format="influx" > /tmp/bigcpu
tsbs_load_questdb --file /tmp/bigcpu --workers 4
構建具有授權許可的開源數據庫
在進一步推動數據庫性能的同時,使開發人員能夠輕松地開始使用我們的產品,這一點每天都激勵著我們。這就是為什么我們專注于建立一個堅實的開發者社區,他們可以通過我們的開源分銷模式參與并改進產品。
除了使QuestDB易于使用之外,我們還希望使其易于審計、審查,提交代碼或其他的項目貢獻。QuestDB的所有源代碼都在GitHub(https://github.com/questdb/questdb)上以Apache 2.0許可證提供,我們歡迎對此產品的各種貢獻,包括在GitHub上創建issue或者提交代碼。
發布評論請先 登錄
艾體寶干貨 | 多模型數據庫解決的到底是什么問題?

工業上面為什么有這么多通訊協議?

華納云為游戲數據庫選擇高性能NVMe SSD存儲
數據庫性能瓶頸分析與SQL優化實戰案例
數據庫性能優化指南
數據庫數據恢復—服務器異常斷電導致Oracle數據庫故障的數據恢復案例
數據庫數據恢復—MongoDB數據庫文件丟失的數據恢復案例
數據庫數據恢復—SQL Server數據庫被加密如何恢復數據?

工業數據中臺如何支持智能決策
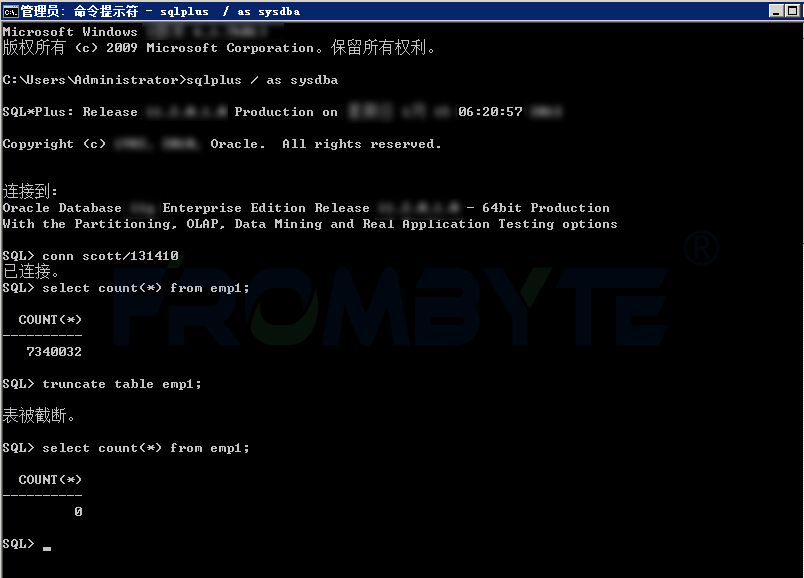
oracle數據恢復—oracle數據庫誤執行錯誤truncate命令如何恢復數據?
SQLSERVER數據庫是什么
MySQL數據庫是什么
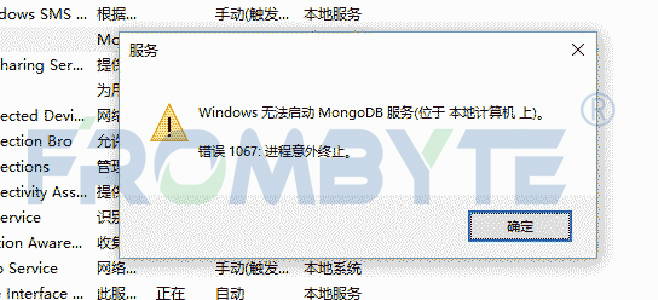
數據庫數據恢復——MongoDB數據庫文件拷貝后服務無法啟動的數據恢復
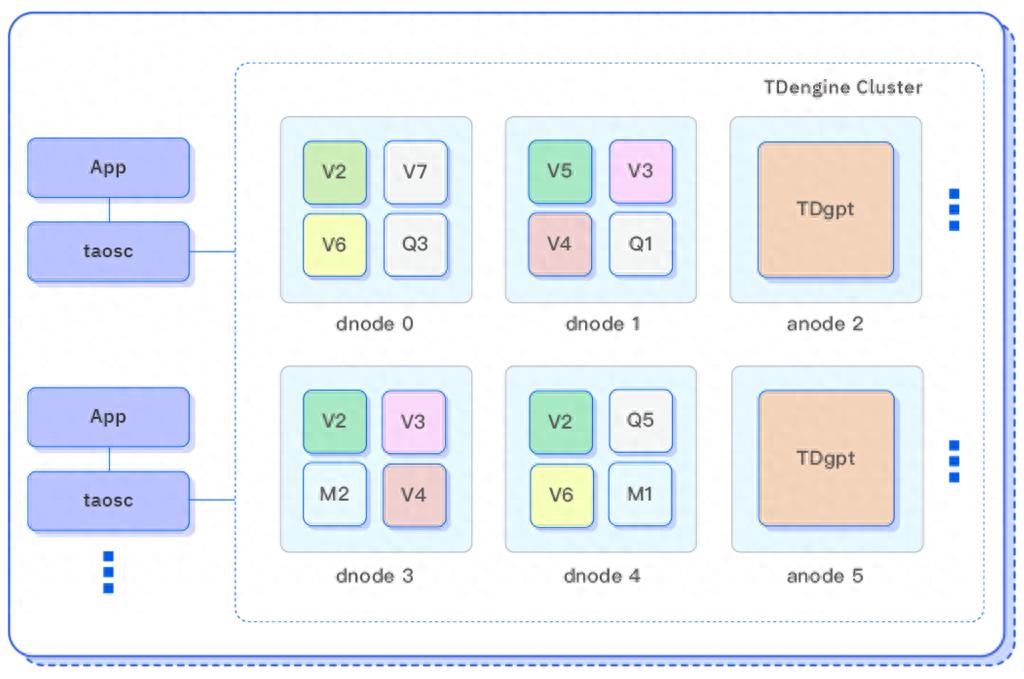
TDengine 發布時序數據分析 AI 智能體 TDgpt,核心代碼開源



 工商網監
工商網監
評論