 能夠0.052秒打開100GB數據的一個高性能Python庫
能夠0.052秒打開100GB數據的一個高性能Python庫

當今的數據集越來越大,臺式機的內存甚至都裝不下,更不用說你的筆記本電腦了,盡管如此,在大數據時代,我們總是避免不了要使用大數據集,于是Vaex誕生了。
什么是Vaex?
Vaex是一個高性能Python庫,可以可視化和探索大型表格數據集,它可以在 N 維網格上計算每秒超過十億(10^9)個對象 / 行的統計信息,例如均值、總和、計數、標準差等, 磁盤上大小超過100GB的數據,用Vaex只需要0.052秒就可以打開。
使用直方圖、密度圖和三維體繪制完成可視化,從而可以交互式探索大數據。Vaex 使用內存映射、零內存復制策略獲得最佳性能(不浪費內存)。
Vaex具有以下功能特性:
基于Python數據科學站(例如Panda、Scikit-Learn、arrow、xgboost、lightgbm),標準API易于采用。為Jupyter環境量身定制。
電腦運算,結合了內存映射,復雜的表達系統和快速核外算法。有效地可視化和探索大型數據集,并在一臺機器上構建機器學習模型。
基準測試,每秒可視化10億個樣本。與標準實現相比,PCA轉換速度提高了10倍,可在2分鐘內處理10億個樣本。完全超出核心。
高效
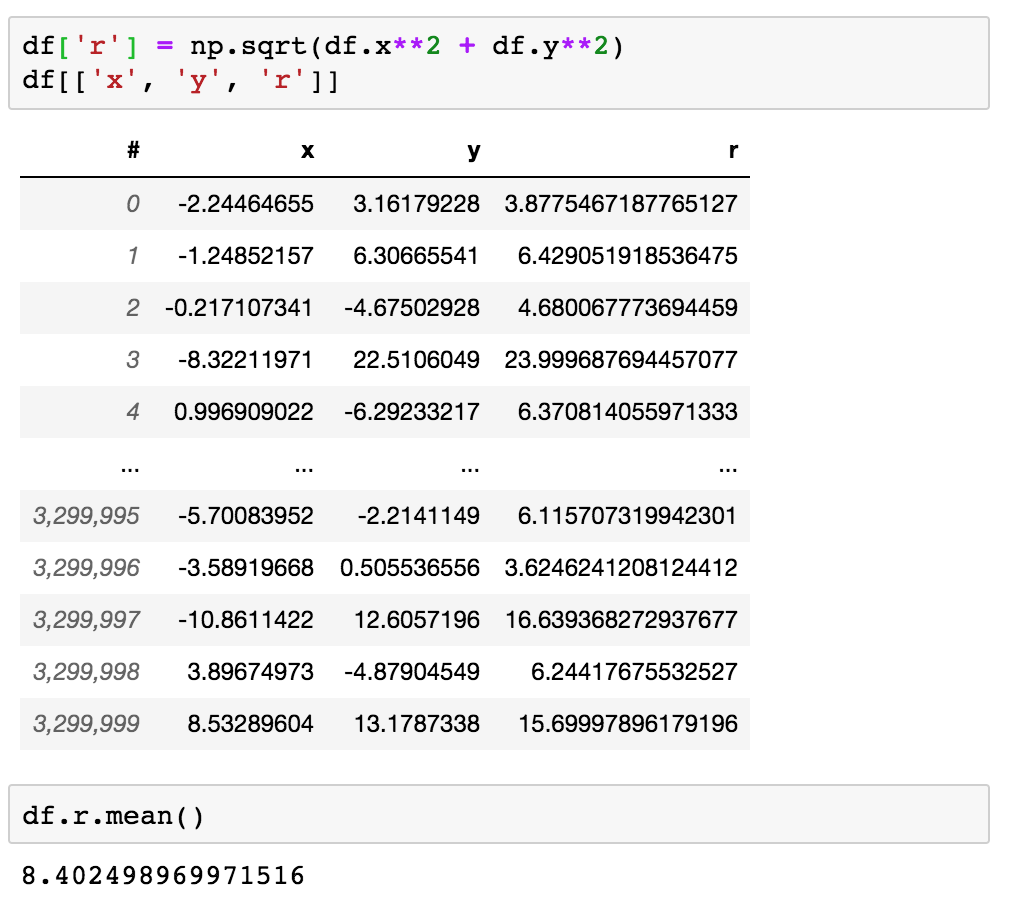
Vaex不僅僅是Panda的替代品。盡管在執行諸如的表達式時,它具有類似于panda的API用于列訪問np.sqrt(ds.x**2 + ds.y**2),但不會進行任何計算。而是創建一個vaex表達式對象,并在打印輸出時顯示一些預覽值。

使用表達式系統,vaex僅在需要時執行計算。同樣,數據也不必是本地的:表達式可以通過發送的方式,統計信息可以遠程計算,這是vaex-server程序包提供的。
虛擬列
我們還可以將表達式添加到DataFrame中,從而生成虛擬列。虛擬列的行為類似于常規列,但不占用任何內存。Vaex在實列和虛列之間沒有區別,
如果表達式在運行時真的很復雜怎么辦?通過使用Pythran或Numba,我們可以使用手動實時(JIT)編譯來優化計算。

遠程數據幀甚至支持JIT版本的表達式,擔心RAM不夠?你還可以選擇以RAM為代價擠出額外的性能。
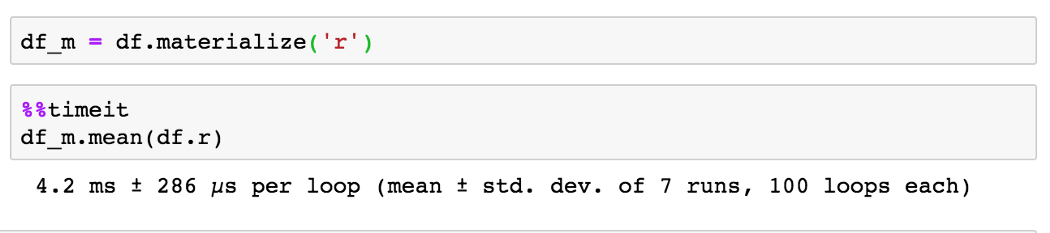
可視化
進行有意義的繪圖和可視化是了解數據的最佳方法。。但是,當你的DataFrame包含10億行時,制作標準散點圖不僅會花費很長時間,而且會導致毫無意義且難以理解的可視化。
讓我們看看這些想法的一些實際例子。我們可以使用直方圖可視化單個列的內容。
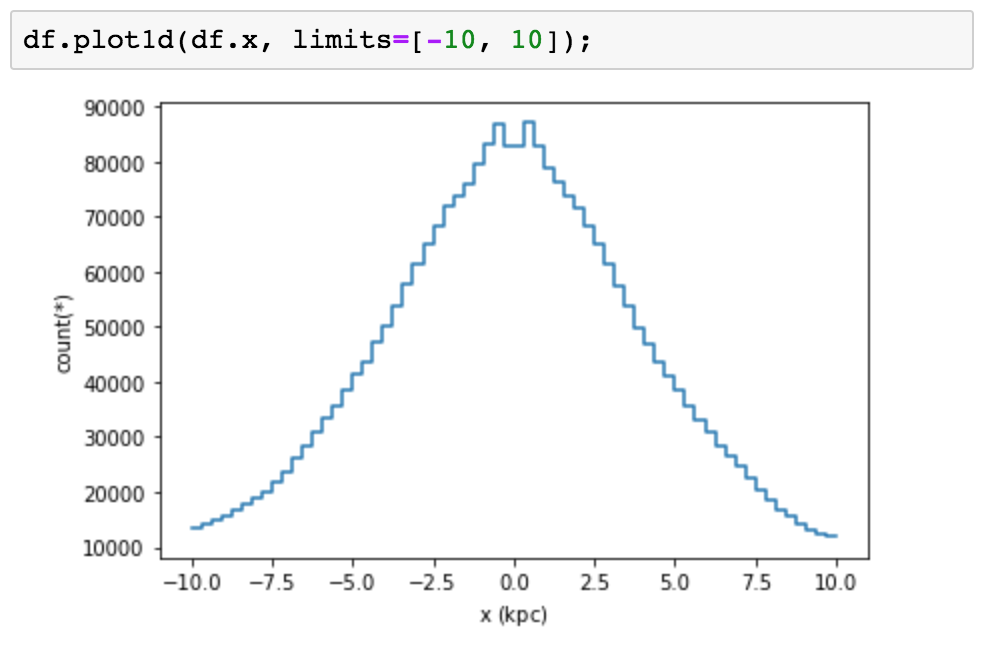
可以將其擴展為兩個維度,從而生成熱圖。我們可以像典型的熱圖那樣簡單地計算落入每個樣本中,而不是計算平均值,取總和的對數或幾乎任何自定義統計量。
我們甚至可以使用ipyvolume進行3維體積渲染。
原文標題:0.052秒打開100GB數據!這個Python開源庫牛X了
文章出處:【微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
python
+關注
關注
57文章
4876瀏覽量
90041 -
大數據
+關注
關注
64文章
9063瀏覽量
143761
原文標題:0.052秒打開100GB數據!這個Python開源庫牛X了
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
高性能ADL5243:100 MHz至4000 MHz RF/IF數字控制VGA的設計與應用
國產高性能ONFI IP解決方案全解析
深度剖析LM5107:高性能100V/1.4 - A峰值半橋柵極驅動器
“秒啟秒開秒加載”背后:一場鴻蒙發起的“性能革命”

炎核開源開放平臺上架推出OpenSparseBlas高性能稀疏計算庫
一文了解Mojo編程語言
數據全復用高性能池化層設計思路分享
華納云為游戲數據庫選擇高性能NVMe SSD存儲
RT-Thread Studio v2.2.9打開時無法選擇工作空間怎么解決?
知乎開源“智能預渲染框架” 幾行代碼實現鴻蒙應用頁面“秒開”
數據庫性能優化指南
GB10超級芯片開賣!正式殺入AI PC
快手上線鴻蒙應用高性能解決方案:數據反序列化性能提升90%
搭載天璣9400+旗艦AI芯片的真我GT7性能超能打
移動工作站是什么?為什么工程師說它能省40%成本?




 工商網監
工商網監
評論