 剖析計算機視覺識別簡史
剖析計算機視覺識別簡史

最近,物體識別已經成為計算機視覺和 AI 最令人激動的領域之一。即時地識別出場景中所有的物體的能力似乎已經不再是秘密。隨著卷積神經網絡架構的發展,以及大型訓練數據集和高級計算技術的支持,計算機現在可以在某些特定設置(例如人臉識別)的任務中超越人類的識別能力。
我感覺每當計算機視覺識別方面有什么驚人的突破發生了,都得有人再講一遍是怎么回事。這就是我做這個圖表的原因。它試圖用最簡潔的語言和最有吸引力的方式講述物體識別的現代史。故事開始于2012年 AlexNet 贏得了 ILSVRC(ImageNet大規模視覺識別挑戰賽)。
信息圖由2頁組成,第1頁總結了重要的概念,第2頁則勾畫了歷史。每一個圖解都是重新設計的,以便更加一致和容易理解。所有參考文獻都是精挑細選的,以便讀者能夠知道從哪里找到有關細節的解釋。
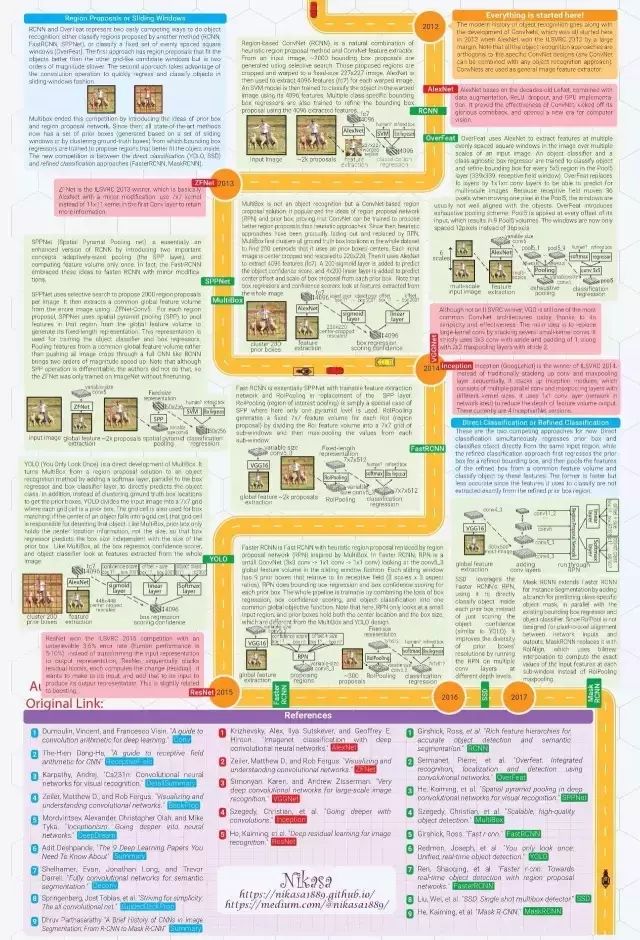

計算機視覺 6 大關鍵技術
圖像分類:根據圖像的主要內容進行分類。數據集:MNIST, CIFAR, ImageNet
物體定位:預測包含主要物體的圖像區域,以便識別區域中的物體。數據集:ImageNet
物體識別:定位并分類圖像中出現的所有物體。這一過程通常包括:劃出區域然后對其中的物體進行分類。數據集:PASCAL, COCO
語義分割:把圖像中的每一個像素分到其所屬物體類別,在樣例中如人類、綿羊和草地。數據集:PASCAL, COCO
實例分割:把圖像中的每一個像素分到其物體類別和所屬物體實例。數據集:PASCAL, COCO
關鍵點檢測:檢測物體上一組預定義關鍵點的位置,例如人體上或者人臉上的關鍵點。數據集:COCO
關鍵人物
這種圖列出了物體識別技術中的關鍵人物:J. Schmidhuber;Yoshua Bengio ;Yann Lecun;Georey Hinton ;Alex Graves ;Alex Krizhevsky ;Ilya Sutskever ;Andrej Karpathy;Christopher Olah ;Ross Girshick;Matthew Zeiler ;Rob Fergus ;Kaiming He ;Pierre Sermanet ;Christian Szegedy ;Joseph Redmon ;Shaoqing Ren ;Wei Liu ;Karen Simonyan;Andrew Zisserman;Evan Shelhamer ;Jonathan Long ;Trevor Darrell;Springenberg ;Mordvintsev ;V. Dumoulin ;Francesco Visin;Adit Deshpande ……
重要的 CNN 概念
1. 特征 (圖案,神經元的激活,特征探測)

當一個特定的圖案(特征)被呈現在輸入區(接受域)中時,一個隱藏的神經元就被會被激活。
神經元識別的團可以被進行可視化,其方法是:1)優化其輸入區,將神經元的激活(deep dream)最大化;2)將梯度(gradient)可視化或者在其輸入像素中,引導神經元激活的梯度(反向傳播以及經引導的反向傳播)3)將訓練數據集中,激活神經元最多的圖像區域進行可視化。
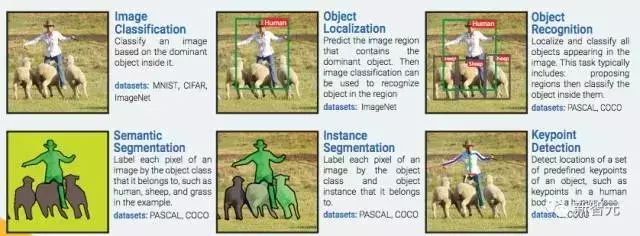
2. 感受野 (特征的輸入區)
輸入圖像區會影響特征的激活。換句話說,它就是特征參考的區域。
通常,越高層上的特征會的接受域會更寬,這能讓它能學會捕捉更多的復雜/抽象圖案。ConvNet 的架構決定了感受野是如何隨著層數的改變而改變的。
3. 特征地圖(feature map,隱藏層的通道)
指的是一系列的特征,通過在一個滑動窗口(例如,卷積)的方式,在一個輸入地圖中的不同位置應用相同的特征探測器來創造。在相同的特征地圖上的特征,有著一致的可接收形狀,并且會尋找不同位置上的相同圖案。這構成了ConvNet的空間不變性。
4. 特征量(卷積中的隱藏層)
這是一組特征地圖,每一張地圖會在輸入地圖中的一些固定位置搜尋特定的特征。所有的特征的接受域大小都是一樣的。
5.作為特征量的全連接層

全連接層(fc layers,在識別任務中通常粘附在一個ConvNet的尾端),這一特征量在每一張特征滴入上都有一個特征,其接收域會覆蓋整張圖像。全連接層中的權重矩陣W可以被轉化成一個CNN核。
將一個核wxhxk 卷積成一個CNN 特征量wxhxd會得到一個1x1xk特征量(=FC layer with k nodes)。將一個1x1xk 的過濾核卷積到一個1x1xd特征量,得到一個1x1xk的特征量。通過卷積層替換完全連接的圖層可以使ConvNet應用于任意大小的圖像。
6. 反卷積
這一操作對卷積中的梯度進行反向傳播。換句話說,它是卷積層的反向傳遞。反向的卷積可以作為一個正常的卷積部署,并且在輸入特征中不需要任何插入。

左圖,紅色的輸入單元負責上方四個單元的激活(四個彩色的框),進而能從這些輸出單元中獲得梯度。這一梯度反向傳播能夠通過反卷積(右圖)部署。
7. 端到端物體識別管道(端到端學習/系統)
這是一個包含了所有步驟的物體識別管道 (預處理、區域建議生成、建議分類、后處理),可以通過優化單個對象函數來進行整體訓練。單個對象函數是一個可差分的函數,包含了所有的處理步驟的變量。這種端到端的管道與傳統的物體識別管道的完全相反。在這些系統中,我們還不知道某個步驟的變量是如何影響整體的性能的,所以,么一個步驟都必須要獨立的訓練,或者進行啟發式編程。
重要的目標識別概念
1. Bounding box proposal
提交邊界框(Bounding box proposal,又稱興趣區域,提交區域,提交框)
輸入圖像上的一個長方形區域,內含需要識別的潛在對象。提交由啟發式搜索(對象、選擇搜索或區域提交網絡RPN)生成。
一個邊界框可以由4 元素向量表示,或表達為 2 個角坐標(x0,y0,x1,y1),或表達為一個中心坐標和寬與高(x,y,w,h)。邊界框通常會配有一個信心指數,表示其包含對象物體的可能性。
兩個邊界框的區別一般由它們的向量表示中的 L2 距離在測量。w 和 h 在計算距離前會先被對數化。
2. Intersection over Union
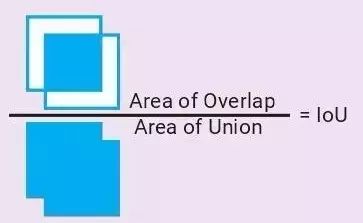
重疊聯合比(Intersection over Union,又稱 IoU,Jaccard 相似度)
兩個邊界框相似度的度量值=它們的重疊區域除以聯合區域
3. 非最大抑制(Non Maxium Suppression,又稱 NMS)
一個融合重疊邊界框(提交或偵測出的)的一般性算法。所有明顯和高信度邊界框重疊的邊界框(IoU 》 IoU_threshold)都會被抑制(去除)。
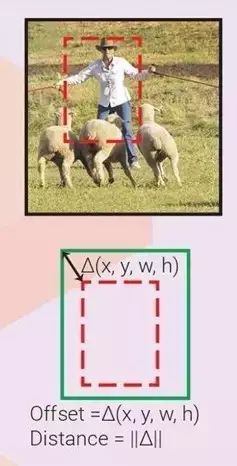
4. 邊界框回歸(邊界框微調)
觀察一個輸入區域,我們可以得到一個更適合隱含對象的邊界框,即使該對象僅部分可見。下圖顯示了在只看到一部分對象時,得出真實邊界框(ground truth box)的可能性。因此,可以訓練回歸量,來觀察輸入區域,并預測輸入區域框和真實框之間的 offset △(x,y,w,h)。如果每個對象類別都有一個回歸量,就稱為特定類別回歸量,否則就稱為不可知類別(class-agnostic,一個回歸量用于所有類別)。邊界框回歸量經常伴有邊界框分類器(信度評分者),來評估邊界框中在對象存在的可信度。分類器既可以是特定類別的,也可以是不可知類別的。如果不定義首要框,輸入區域框就扮演首要框的角色。
5. 首要框(Prior box,又稱默認框、錨定框)

如果不使用輸入區域作為唯一首要框,我們可以訓練多個邊界框回歸量,每一個觀測相同的輸入區域,但它們各自的首要框不同。每一個回歸量學習預測自己的首要框和真實框之間的 offset。這樣,帶有不同首要框的回歸量可以學習預測帶有不同特性(寬高比,尺寸,位置)的邊界框。相對于輸入區域,首要框可以被預先定義,或者通過群集學習。適當的框匹配策略對于使訓練收斂是至關重要的。
6. 框匹配策略

我們不能指望一個邊界框回歸量可以預測一個離它輸入區域或首要框(更常見)太遠的對象邊界框。因此,我們需要一個框匹配策略,來判斷哪一個首要框與真實框相匹配。每一次匹配對回歸來說都是一個訓練樣本。可能的策略有:(多框)匹配每一個帶有最高 IoU 的首要框的真實框;(SSD,FasterRCNN)匹配帶有任何 IoU 高于 0.5 的真實框的首要框。
7. 負樣本挖掘(Hard negative example mining)
對于每個首要框,都有一個邊界框分類器來評估其內部含有對象的可能性。框匹配之后,所有其他首要框都為負。如果我們用了所有這些負樣本,正負之間本會有明顯的不平衡。可能的解決方案是:隨機挑選負樣本(FasterRCNN),或挑選那些分類器判斷錯誤最嚴重的樣本,這樣負和正之間的比例大概是3:1 。
重要視覺模型發展:AlexNet→ZFNet→VGGNet
→ResNet→MaskRCNN
一切從這里開始:現代物體識別隨著ConvNets的發展而發展,這一切始于2012年AlexNet以巨大優勢贏得ILSVRC 2012。請注意,所有的物體識別方法都與ConvNet設計是正交的(任意ConvNet可以與任何對象識別方法相結合)。ConvNets用作通用圖像特征提取器。
2012年 AlexNet:AlexNet基于有著數十年歷史的LeNet,它結合了數據增強、ReLU、dropout和GPU實現。它證明了ConvNet的有效性,啟動了ConvNet的光榮回歸,開創了計算機視覺的新紀元。

RCNN:基于區域的ConvNet(RCNN)是啟發式區域提案法(heuristic region proposal method)和ConvNet特征提取器的自然結合。從輸入圖像,使用選擇性搜索生成約2000個邊界框提案。這些被推出區域被裁剪并扭曲到固定大小的227x227圖像。
然后,AlexNet為每個彎曲圖像提取4096個特征(fc7)。然后訓練一個SVM模型,使用4096個特征對該變形圖像中的對象進行分類。并使用4096個提取的特征來訓練多個類別特定的邊界框回歸器來改進邊界框。
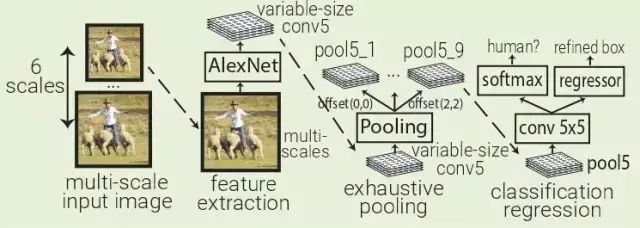
OverFeat:OverFeat使用AlexNet在一個輸入圖像的多個層次下的多個均勻間隔方形窗口中提取特征。訓練一個對象分類器和一個類別不可知盒子回歸器,用于對Pool5層(339x339接收域窗口)中每5x5區域的對象進行分類并對邊界框進行細化。
OverFeat將fc層替換為1x1xN的卷積層,以便能夠預測多尺度圖像。因為在Pool5中移動一個像素時,接受場移動36像素,所以窗口通常與對象不完全對齊。OverFeat引入了詳盡的池化方案:Pool5應用于其輸入的每個偏移量,這導致9個Pool5卷。窗口現在只有12像素而不是36像素。
2013 年 ZFNet:ZFNet 是 ILSVRC 2013 的冠軍得主,它實際上就是在 AlexNet 的基礎上做了鏡像調整(mirror modification):在第一個卷積層使用 7×7 核而非 11×11 核保留了更多的信息。
SPPNet:SPPNet(Spatial Pyramid Pooling Net)本質上是 RCNN 的升級,SFFNet 引入了 2 個重要的概念:適應大小池化(adaptively-sized pooling,SPP 層),以及對特征量只計算一次。實際上,Fast-RCNN 也借鑒了這些概念,通過鏡像調整提高了 RCNN 的速度。
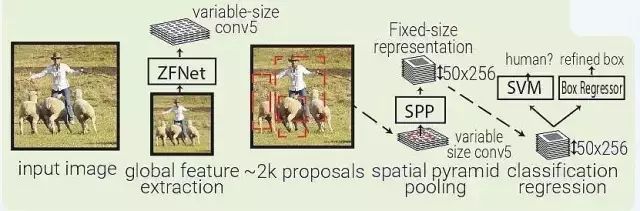
SPPNet 用選擇性搜索在每張圖像中生成 2000 個區域(region proposal)。然后使用 ZFNet-Conv5 從整幅圖像中抓取一個共同的全體特征量。對于每個被生成的區域,SPPNet 都使用 spatial pyramid pooling(SPP)將該區域特征從全體特征量中 pool 出來,生成一個該區域的長度固定的表征。
這個表征將被用于訓練目標分類器和 box regressor。從全體特征量 pooling 特征,而不是像 RNN 那樣將所有圖像剪切(crops)全部輸入一個完整的 CNN,SPPNet 讓速度實現了 2 個數量級的提升。
需要指出,盡管 SPP 運算是可微分的,但作者并沒有那么做,因此 ZFNet 僅在 ImageNet 上訓練,沒有做 finetuning。
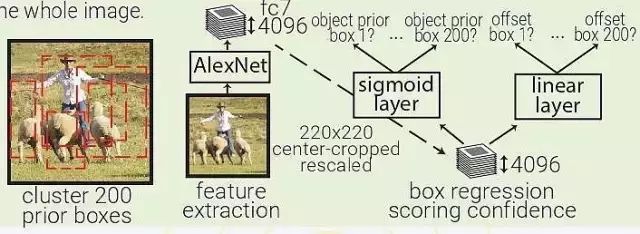
MultiBox:MultiBox 不像是目標識別,更像是一種基于 ConvNet 的區域生成解決方案。MultiBox 讓區域生成網絡(region proposal network,RPN)和 prior box 的概念流行了起來,證明了卷積神經網絡在訓練后,可以生成比啟發式方法更好的 region proposal。自此以后,啟發式方法逐漸被 RPN 所取代。
MultiBox 首先將整個數據集中的所有真實 box location 聚類,找出 200 個質心(centroid),然后將其用于priorbox的中心。每幅輸入的圖像都會被從中心被裁減和重新調整大小,變為 220×220。
然后,MultiBox 使用 ALexNet 提取 4096 個特征(fc7)。再加入一個 200-sigmoid 層預測目標置信度分數,另外還有一個 4×200-linear 層從每個 prior box 預測 centre offset 和 box proposal。注意下圖中顯示的 box regressors 和置信度分數在看從整幅圖像中抓取的特征。
2014 年 VGGNet:雖然不是 ILSVRC 冠軍,VGGNet 仍然是如今最常見的卷積架構之一,這也是因為它簡單有效。VGGNet 的主要思想是通過堆疊多層小核卷積層,取代大核的卷積層。VGGNet 嚴格使用 3×3 卷積,步長和 padding 都為1,還有 2×2 的步長為 2 的 maxpooling 層。
2014 年 Inception:Inception(GoogLeNet)是2014 年 ILSVRC 的冠軍。與傳統的按順序堆疊卷積和 maxpooling 層不同,Inception 堆疊的是 Inception 模塊,這些模塊包含多個并行的卷積層和許多核的大小不同的 maxpooling 層。Inception 使用 1×1 卷積層減少特征量輸出的深度。目前,Inception 有 4 種版本。
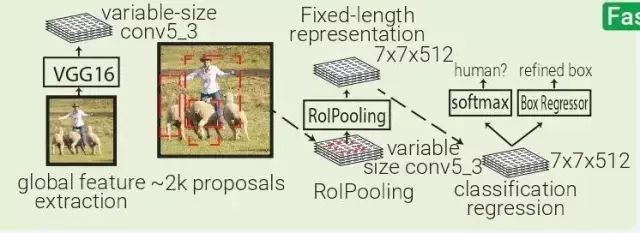
Fast RCNN:Fast RCNN本質上源于SPPNET,不同的是 Fast RCNN 帶有訓練好的特征提取網絡,用 RolPooling 取代了 SPP 層。
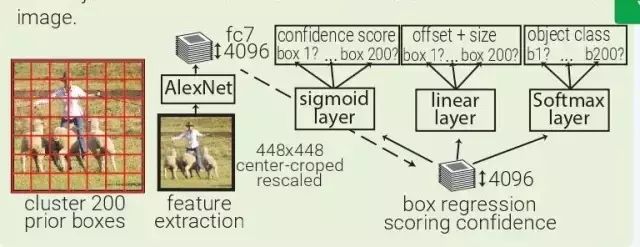
YOLO:YOLO(You Only Look Once)是由 MultiBox 直接衍生而來的。通過加了一層 softmax 層,與 box regressor 和 box 分類器層并列,YOLO 將原本是區域生成的 MultiBox 轉為目標識別的方法,能夠直接預測目標的類型。
2015 ResNet:ResNet以令人難以置信的3.6%的錯誤率(人類水平為5-10%)贏得了2015年ILSVRC比賽。ResNet不是將輸入表達式轉換為輸出表示,而是順序地堆疊殘差塊,每個塊都計算它想要對其輸入的變化(殘差),并將其添加到其輸入以產生其輸出表示。這與boosting有一點關。
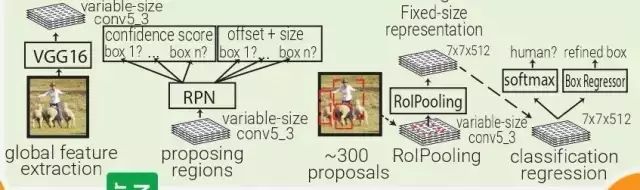
Faster RCNN:受 Multibox 的啟發,Faster RCNN 用啟發式區域生成代替了區域生成網絡(RPN)。在 Faster RCNN 中,PRN 是一個很小的卷積網絡(3×3 conv → 1×1 conv → 1×1 conv)在移動窗口中查看 conv5_3 全體特征量。
每個移動窗口都有 9 個跟其感受野相關的 prior box。PRN 會對每個 prior box 做 bounding box regression 和 box confidence scoring。通過結合以上三者的 loss 成為一個共同的全體特征量,整個管道可以被訓練。
注意,在這里 RPN 只關注輸入的一個小的區域;prior box 掌管中心位置和 box 的大小,Faster RCNN 的 box 設計跟 MultiBox 和 YOLO 的都不一樣。
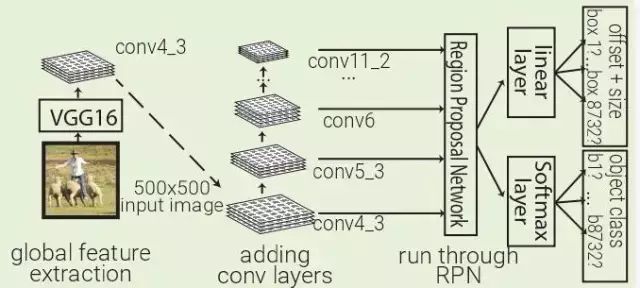
2016 年 SSD:SSD 利用 Faster RCNN 的 RPN,直接對每個先前的 box 內的對象進行分類,而不僅僅是對對象置信度(類似于YOLO)進行分類。通過在不同深度的多個卷積層上運行 RPN 來改善前一個 box 分辨率的多樣性。
2017 年 Mask RCNN:通過增加一支特定類別對象掩碼預測,Mask RCNN 擴展了面向實例分割的Faster RCNN,與已有的邊界框回歸量和對象分類器并行。由于 RolPool 并非設計用于網絡輸入和輸出間的像素到像素對齊,MaskRCNN 用 RolAlign 取代了它。RolAlign 使用了雙線性插值來計算每個子窗口的輸入特征的準確值,而非 RolPooling 的最大池化法。
編輯:jq
-
SVM
+關注
關注
0文章
154瀏覽量
33694 -
卷積
+關注
關注
0文章
95瀏覽量
19009 -
分類器
+關注
關注
0文章
153瀏覽量
13786 -
計算機視覺
+關注
關注
9文章
1715瀏覽量
47625
原文標題:計算機視覺識別簡史:從 AlexNet、ResNet 到 Mask RCNN
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【上海晶珩睿莓 1 單板計算機】人臉識別
上海計算機視覺企業行學術沙龍走進西井科技
使用代理式AI激活傳統計算機視覺系統的三種方法
STM32計算機視覺開發套件:B-CAMS-IMX攝像頭模塊技術解析


【作品合集】賽昉科技VisionFive 2單板計算機開發板測評
易控智駕榮獲計算機視覺頂會CVPR 2025認可
工業計算機的重要性

自動化計算機經過加固后有什么好處?
自動化計算機的功能與用途

工業計算機與商用計算機的區別有哪些

基于LockAI視覺識別模塊:手寫數字識別

利用邊緣計算和工業計算機實現智能視頻分析
一文帶你了解工業計算機尺寸

計算機網絡入門指南



 工商網監
工商網監
評論