") 關(guān)于一項(xiàng)改進(jìn)Transformer的工作
關(guān)于一項(xiàng)改進(jìn)Transformer的工作

NAACL2021中,復(fù)旦大學(xué)大學(xué)數(shù)據(jù)智能與社會(huì)計(jì)算實(shí)驗(yàn)室(Fudan DISC)和微軟亞洲研究院合作進(jìn)行了一項(xiàng)改進(jìn)Transformer的工作,論文的題目為:Mask Attention Networks: Rethinking and Strengthen Transformer,被收錄為長(zhǎng)文。
文章摘要
Transformer的每一層都由兩部分構(gòu)成,分別是自注意力網(wǎng)絡(luò)(SAN)和前饋神經(jīng)網(wǎng)絡(luò)(FFN)。當(dāng)前的大部分研究會(huì)拆開這兩份部分來分別進(jìn)行增強(qiáng)。在我們的研究當(dāng)中,我們發(fā)現(xiàn)SAN和FFN本質(zhì)上都屬于一類更廣泛的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),遮罩注意力網(wǎng)絡(luò)(MANs),并且其中的遮罩矩陣都是靜態(tài)的。我們認(rèn)為這樣的靜態(tài)遮罩方式限制了模型對(duì)于局部信息的建模的。因此,我們提出了一類新的網(wǎng)絡(luò),動(dòng)態(tài)遮罩注意力網(wǎng)絡(luò)(DMAN),通過自身的學(xué)習(xí)來調(diào)整對(duì)于局部信息的建模。為了更好地融合各個(gè)子網(wǎng)絡(luò)(SAN,F(xiàn)FN,DMAN)的優(yōu)勢(shì),我們提出了一種層疊機(jī)制來將三者融合起來。我們?cè)跈C(jī)器翻譯和文本摘要任務(wù)上驗(yàn)證了我們的模型的有效性。
研究背景
目前大家會(huì)從SAN或者FFN來對(duì)Transformer進(jìn)行改進(jìn),但是這樣的方案忽略了SAN和FFN的內(nèi)在聯(lián)系。
在我們的工作當(dāng)中,我們使用Mask Attention Network作為分析框架來重新審視SAN和FFN。Mask Attention Networks使用一個(gè)遮罩矩陣來和鍵值對(duì)的權(quán)重矩陣進(jìn)行對(duì)應(yīng)位置的相乘操作來確定最終的注意力權(quán)重。在下圖中,我們分別展示了SAN和FFN的遮罩矩陣。由于對(duì)于關(guān)系建模沒有任何的限制,SAN更擅長(zhǎng)長(zhǎng)距離建模來從而可以更好地捕捉全局語(yǔ)意,而FFN因?yàn)檎谡志仃嚨南拗疲瑹o法獲取到其他的token的信息,因而更關(guān)注自身的信息。
盡管SAN和FFN取得了相當(dāng)好的效果,但是最近的一些研究結(jié)果表明,Transformer在捕捉局部信息的能力上有所欠缺。我們認(rèn)為這種欠缺是因?yàn)槭且驗(yàn)樽⒁饬仃嚨挠?jì)算當(dāng)中都是有靜態(tài)遮罩矩陣的參與所導(dǎo)致的。我們發(fā)現(xiàn)兩個(gè)不相關(guān)的token之間的權(quán)重可能因?yàn)橹虚g詞的關(guān)系而錯(cuò)誤地產(chǎn)生了較大的注意力權(quán)重。例如“a black dog jumps to catch the frisbee”, 盡管“catch”和“black”關(guān)系不大,但是因?yàn)槎叨脊餐泥従印癲og”的關(guān)系很大,進(jìn)而產(chǎn)生了錯(cuò)誤了聯(lián)系,使得“catch”忽略了自己真正的鄰居。
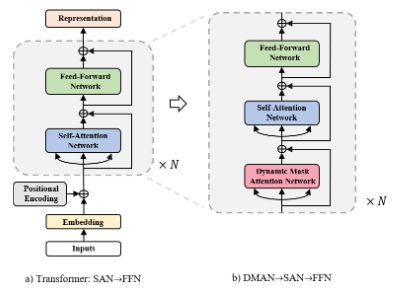
為了強(qiáng)化Transformer在局部建模的能力,我們提出了動(dòng)態(tài)遮罩注意力網(wǎng)絡(luò)(DMAN)。在DMAN當(dāng)中, 在特定距離內(nèi)的單詞相比于一般的注意力機(jī)制會(huì)得到更多的注意力權(quán)重,進(jìn)而得到更多的關(guān)注。另外,為了更好地融合SAN,F(xiàn)FN和DMAN三者的能力,我們提出使用DMAN-》SAN-》FFN這樣的方式來搭建網(wǎng)絡(luò)結(jié)構(gòu)。
方法描述
回顧Transformer
SAN的注意力機(jī)制使用下面的公式來將鍵值對(duì)映射到新的輸出。
其中是查詢向量組成的有序矩陣,是鍵值對(duì)的組合,是的特征維度。
為了進(jìn)一步增強(qiáng)transformer捕捉不同文本特征的的能力,對(duì)于一個(gè)文本特征的輸入序列, SAN會(huì)使用多頭注意力機(jī)制。
在FFN當(dāng)中,每一個(gè)
的計(jì)算都是獨(dú)立于其他的輸入的。具體來說,它由兩個(gè)全連接層組成。
定義一類新網(wǎng)絡(luò): Mask Attention Networks
我們?cè)赟AN的注意力函數(shù)的基礎(chǔ)上定義帶遮罩的注意力函數(shù)。
其中M是一個(gè)遮罩矩陣,它既可以是靜態(tài)的,也可以是動(dòng)態(tài)的。
在這個(gè)新的遮罩矩陣的基礎(chǔ)上,我們定義一類新網(wǎng)絡(luò): Mask Attention Networks(MANs)
其中F是激活函數(shù),M^i是第i個(gè)注意力上的遮罩矩陣。
接下來我們來說明SAN和FFN都是MANs當(dāng)中的特例。
從MANs的視角來看,對(duì)于SAN,我們令
這個(gè)時(shí)候MANs可以寫成下面的形式。這個(gè)結(jié)果告訴我們SAN是MANs當(dāng)中固定遮罩矩陣為全1的特例
對(duì)于FFN,我們令
那么得到SAN是MANs當(dāng)中固定遮罩矩陣為單位陣的特例。
SAN和FFN在局部建模上的問題
直觀上來說,因?yàn)镕FN的遮罩矩陣是一個(gè)單位陣,所以FFN只能獲取自身的信息而無法獲知鄰居的信息。對(duì)于SAN,每一個(gè)token都可以獲取到句子其它的所有token的信息。我們發(fā)現(xiàn)不在鄰域當(dāng)中的單詞也有可能得到一個(gè)相當(dāng)大的注意力得分。因此,SAN可能在語(yǔ)義建模的過程當(dāng)中引入噪聲,進(jìn)而忽視了局部當(dāng)中的有效信號(hào)。
動(dòng)態(tài)遮罩注意力網(wǎng)絡(luò)
顯然地我們可以通過靜態(tài)的遮罩矩陣來使模型只考慮特定鄰域內(nèi)的單詞,從而達(dá)到更好的局部建模的效果。但是這樣的方式欠缺靈活性,考慮到鄰域的大小應(yīng)該隨著query token來變化,所以我們構(gòu)建了下面的策略來動(dòng)態(tài)地調(diào)節(jié)鄰域的大小。
其中是當(dāng)前的層數(shù),是當(dāng)前的注意力head, 和分別是兩個(gè)和的位置。都是可學(xué)習(xí)的變量。
組合Mask Attention Networks當(dāng)中的各類網(wǎng)絡(luò)結(jié)構(gòu)
我們采用下圖的方式來組合這三種網(wǎng)絡(luò)結(jié)構(gòu)。
實(shí)驗(yàn)
我們的實(shí)驗(yàn)主要分為兩個(gè)部分,機(jī)器翻譯和文本摘要。
機(jī)器翻譯
我們?cè)贗WSLT14 De-En和WMT14 En-De上分別對(duì)我們的模型進(jìn)行了驗(yàn)證。相比于Transformer,我們的模型在base和big的參數(shù)大小設(shè)定下,分別取得了1.8和2.0的BLEU的提升。
文本摘要
在文本摘要的任務(wù)上,我們分別在CNN/Daily Mail和Gigaword這兩個(gè)數(shù)據(jù)集上分別進(jìn)行了驗(yàn)證。相比于Transformer,我們的模型在R-avg上分別有1.5和0.7的效果提升。
對(duì)比不同的子網(wǎng)絡(luò)堆疊方式

我們對(duì)比了一些不同的子網(wǎng)絡(luò)堆疊方式的結(jié)果。從這張表中我們可以發(fā)現(xiàn):
C#5,C#4,C#3》C#1,C#2,這說明DMAN的參與可以提高模型的效果。
C#5,C#4》C#3,C#2,說明DMAN和SAN有各自的優(yōu)點(diǎn),它們分別更擅長(zhǎng)全局建模和局部建模,所以可以更好地合作來增強(qiáng)彼此。
C#5》C#4,說明先建模局部再全局比相反的順序要更好一些。
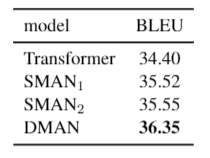
我們比較了兩組不同的靜態(tài)遮罩策略。
SMAN1:遮蓋距離超過b的所有單詞,,為句子長(zhǎng)度。
SMAN2:b=4。
從結(jié)果來看,我們發(fā)現(xiàn)DMAN的效果遠(yuǎn)遠(yuǎn)好于上述兩種靜態(tài)遮罩方法,這說明給不同的單詞確實(shí)在鄰域的建模上確實(shí)存在差異。
結(jié)論
在這篇論文當(dāng)中,我們介紹了遮罩注意力網(wǎng)絡(luò)(MANs)來重新審視SAN和FFN,并指出它們是MANs的兩種特殊情況。我們進(jìn)而分析了兩種網(wǎng)絡(luò)在局部建模上的不足,并提出使用動(dòng)態(tài)遮罩的方法來更好地進(jìn)行局部建模。考慮到SAN,F(xiàn)FN和DMAN不同的優(yōu)點(diǎn),我們提出了一種DMAN-》SAN-》FFN的方式來進(jìn)行建模。我們提出的模型在機(jī)器翻譯和文本摘要上都比transformer取得了更好的效果。
原文標(biāo)題:遮罩注意力網(wǎng)絡(luò):對(duì)Transformer的再思考與改進(jìn)
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
8264瀏覽量
94704 -
Transforme
+關(guān)注
關(guān)注
0文章
12瀏覽量
8957
原文標(biāo)題:遮罩注意力網(wǎng)絡(luò):對(duì)Transformer的再思考與改進(jìn)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
是德科技與聯(lián)發(fā)科技聯(lián)合完成一項(xiàng)工作原型驗(yàn)證
Transformer 入門:從零理解 AI 大模型的核心原理
Transformer如何讓自動(dòng)駕駛大模型獲得思考能力?
研華科技攜手森云智能率先完成一項(xiàng)重要技術(shù)突破
美國(guó)國(guó)際貿(mào)易委員會(huì)裁定英飛凌在針對(duì)英諾賽科的一項(xiàng)專利侵權(quán)案中勝訴
算法工程師不愿做標(biāo)注工作,怎么辦?

Transformer如何讓自動(dòng)駕駛變得更聰明?
易飛揚(yáng)獲得一項(xiàng)有源電纜系統(tǒng)的關(guān)鍵發(fā)明專利

知行科技機(jī)器人業(yè)務(wù)新獲一項(xiàng)合作
自動(dòng)駕駛中Transformer大模型會(huì)取代深度學(xué)習(xí)嗎?

【「DeepSeek 核心技術(shù)揭秘」閱讀體驗(yàn)】第三章:探索 DeepSeek - V3 技術(shù)架構(gòu)的奧秘
華為Pura80發(fā)布,一項(xiàng)卡脖子傳感器技術(shù)獲突破,一項(xiàng)傳感器技術(shù)仍被卡脖子!
Transformer架構(gòu)中編碼器的工作流程

Transformer架構(gòu)概述




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論