 一個使用YoloV5的深度指南,使用WBF進行性能提升
一個使用YoloV5的深度指南,使用WBF進行性能提升

導讀
一個使用YoloV5的深度指南,使用WBF進行性能提升。
網上有大量的YoloV5教程,本文的目的不是復制內容,而是對其進行擴展。我最近在做一個目標檢測競賽,雖然我發現了大量創建基線的教程,但我沒有找到任何關于如何擴展它的建議。此外,我想強調一下YoloV5配置中影響性能的最重要部分,因為畢竟數據科學主要是關于實驗和超參數調整。
在這之前,我想說使用目標檢測模型和使用圖像分類模型在框架和庫的工作方式上是不同的。這是我注意到的,我花了很長時間才弄明白。大多數流行的目標檢測模型(如YoloV5、EfficientDet)使用命令行接口來訓練和評估,而不是使用編碼方法。這意味著,你所需要做的就是獲取特定格式的數據(COCO或VOC),并將命令指向它。這通常與使用代碼訓練和評估模型的圖像分類模型不同。
數據預處理
YoloV5期望你有兩個目錄,一個用于訓練,一個用于驗證。在這兩個目錄中,你需要另外兩個目錄,“Images”和“Labels”。Images包含實際的圖像,每個圖像的標簽都應該有一個帶有該圖像標注的.txt文件,文本文件應該有與其對應的圖像相同的名稱。
標注格式如下:
<'class_id'><'x_center'><'y_center'>
要在代碼中做到這一點,你可能需要一個類似的函數,在原始數據幀中有圖像項,它們的類id和它們的邊界框:
defcreate_file(df,split_df,train_file,train_folder,fold): os.makedirs('labels/train/',exist_ok=True) os.makedirs('images/train/',exist_ok=True) os.makedirs('labels/val/',exist_ok=True) os.makedirs('images/val/',exist_ok=True) list_image_train=split_df[split_df[f'fold_{fold}']==0]['image_id'] train_df=df[df['image_id'].isin(list_image_train)].reset_index(drop=True) val_df=df[~df['image_id'].isin(list_image_train)].reset_index(drop=True) fortrain_imgintqdm(train_df.image_id.unique()): withopen('labels/train/{train_img}.txt','w+')asf: row=train_df[train_df['image_id']==train_img] [['class_id','x_center','y_center','width','height']].values row[:,1:]/=SIZE#Imagesize,512here row=row.astype('str') forboxinrange(len(row)): text=''.join(row[box]) f.write(text) f.write(' ') shutil.copy(f'{train_img}.png', f'images/train/{train_img}.png') forval_imgintqdm(val_df.image_id.unique()): withopen(f'{labels/val/{val_img}.txt','w+')asf: row=val_df[val_df['image_id']==val_img] [['class_id','x_center','y_center','width','height']].values row[:,1:]/=SIZE row=row.astype('str') forboxinrange(len(row)): text=''.join(row[box]) f.write(text) f.write(' ') shutil.copy(f'{val_img}.png', f'images/val/{val_img}.png')
注意:不要忘記保存在標簽文本文件中的邊界框的坐標**必須被歸一化(從0到1)。**這非常重要。另外,如果圖像有多個標注,在文本文件中,每個標注(預測+邊框)將在單獨的行上。
在此之后,你需要一個配置文件,其中包含標簽的名稱、類的數量以及訓練和驗證的路徑。
importyaml classes=[‘Aorticenlargement’, ‘Atelectasis’, ‘Calcification’, ‘Cardiomegaly’, ‘Consolidation’, ‘ILD’, ‘Infiltration’, ‘LungOpacity’, ‘Nodule/Mass’, ‘Otherlesion’, ‘Pleuraleffusion’, ‘Pleuralthickening’, ‘Pneumothorax’, ‘Pulmonaryfibrosis’] data=dict( train=‘../vinbigdata/images/train’,#trainingimagespath val=‘../vinbigdata/images/val’,#validationimagespath nc=14,#numberofclasses names=classes ) withopen(‘./yolov5/vinbigdata.yaml’,‘w’)asoutfile: yaml.dump(data,outfile,default_flow_style=False)
現在,你需要做的就是運行這個命令:
pythontrain.py—img640—batch16—epochs30—data./vinbigdata.yaml—cfgmodels/yolov5x.yaml—weightsyolov5x.pt
從經驗中需要注意的事情:
好了,現在我們已經瀏覽了基本知識,讓我們來看看重要的東西:
別忘了歸一化坐標。
如果你的初始性能比預期的差得多,那么最可能的原因(我在許多其他參賽者身上看到過這種情況)是你在預處理方面做錯了什么。這看起來很瑣碎,但有很多細節你必須注意,特別是如果這是你的第一次。
YoloV5有多種型號(yolov5s、yolov5m、yolov5l、yolov5x),不要只選擇最大的一個,因為它可能會過擬合。從一個基線開始,比如中等大小的,然后試著改善它。
雖然我是在512尺寸的圖像上訓練的,但我發現用640來infer可以提高性能。
不要忘記加載預訓練的權重(-weights標志)。遷移學習將大大提高你的性能,并將為你節省大量的訓練時間(在我的例子中,大約50個epoch,每個epoch大約需要20分鐘!)
Yolov5x需要大量的內存,當訓練尺寸為512,批大小為4時,它需要大約14GB的GPU內存(大多數GPU大約8GB內存)。
YoloV5已經使用了數據增強,你可以選擇喜歡或不喜歡的增強,你所需要做的就是使用yolov5/data/hyp.scratch.yml文件去調整。
默認的yolov5訓練腳本使用weights and biases,說實話,這非常令人印象深刻,它在模型訓練時保存所有度量。但是,如果你想關閉它,只需在訓練腳本標記中添加WANDB_MODE= " dryrun "即可。
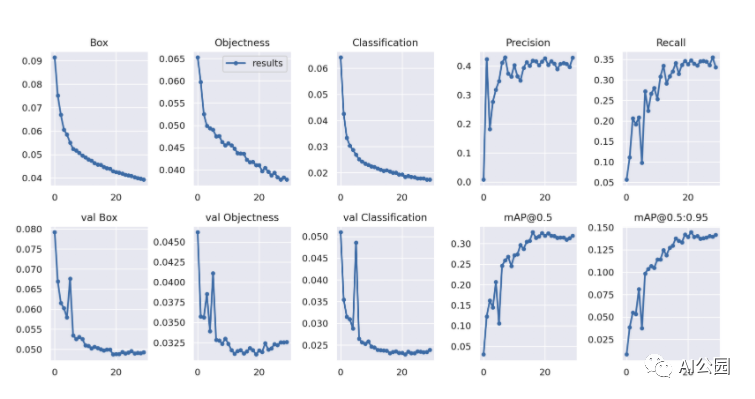
我希望早就發現的一件事是,YoloV5將大量有用的指標保存到目錄YoloV5 /runs/train/exp/中。訓練之后,你可以找到“confusion_matrix.png”和“results.png”,其中的result .png應該是這樣的:
使用WBF預處理
好了,現在你已經調整了超參數,升級了你的模型,測試了多種圖像大小和交叉驗證。現在是介紹一些提高性能的技巧的時候了。
加權框融合是一種在訓練前(清理數據集)或訓練后(使預測更準確)動態融合框的方法。如果你想知道更多,你可以在這里查看我的文章:
WBF:優化目標檢測,融合過濾預測框 (qq.com)
要使用它對數據集進行預處理,這將大多數參賽者的性能提高了大約10-20%,你可以這樣使用:
fromensemble_boxesimport* forimage_idintqdm(df['image_id'],leave=False): image_df=df[df['image_id']==image_id].reset_index(drop=True) h,w=image_df.loc[0,['height','width']].values boxes=image_df[['x_min','y_min','x_max','y_max']].values.tolist() #Normalisealltheboundingboxes(bydividingthembysize-1 boxes=[[j/(size-1)forjini]foriinboxes] scores=[1.0]*len(boxes)#setallofthescoresto1sinceweonlyhave1modelhere labels=[float(i)foriinimage_df['class_id'].values] boxes,scores,labels=weighted_boxes_fusion([boxes],[scores],[labels],weights=None,iou_thr=iou_thr, skip_box_thr=skip_box_thr) list_image.extend([image_id]*len(boxes)) list_h.extend([h]*len(boxes)) list_w.extend([w]*len(boxes)) list_boxes.extend(boxes) list_cls.extend(labels.tolist()) #bringtheboundingboxesbacktotheiroriginalsize(bymultiplyingbysize-1)list_boxes=[[int(j*(size-1))forjini]foriinlist_boxes] new_df['image_id']=list_image new_df['class_id']=list_cls new_df['h']=list_h new_df['w']=list_w #Unpackthecoordinatesfromtheboundingboxes new_df['x_min'],new_df['y_min'], new_df['x_max'],new_df['y_max']=np.transpose(list_boxes)
這意味著要在將邊框坐標保存到標注文件之前完成。你還可以嘗試在用YoloV5以同樣的方式預測邊界框之后使用它。
首先,在訓練YoloV5之后,運行:
!pythondetect.py—weights/runs/train/exp/weights —img640 —conf0.005 —iou0.45 —source$test_dir —save-txt—save-conf—exist-ok
然后提取框、分數和標簽:
runs/detect/exp/labels
然后傳遞到:
boxes,scores,labels=weighted_boxes_fusion([boxes],[scores],[labels],weights=None,iou_thr=iou_thr, skip_box_thr=skip_box_thr)
最后的思考
我希望你已經學到了一些關于擴展你的基線YoloV5的知識,我認為最重要的事情總是要考慮的是遷移學習,圖像增強,模型復雜性,預處理和后處理技術。這些是你可以輕松控制和使用YoloV5來提高性能的大部分方面。
責任編輯:lq
-
圖像分類
+關注
關注
0文章
96瀏覽量
12489 -
目標檢測
+關注
關注
0文章
233瀏覽量
16492 -
遷移學習
+關注
關注
0文章
74瀏覽量
5850
原文標題:高級YoloV5指南,使用WBF來提升目標檢測性能
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于迅為RK3588開發板實現高性能機器狗主控解決方案-?AI能力實戰:YOLOv5目標檢測例程

迅為如何在RK3576上部署YOLOv5;基于RK3576構建智能門禁系統

技術分享 | RK3588基于Yolov5的目標識別演示

基于瑞芯微RK3576的 yolov5訓練部署教程

在k230上使用yolov5檢測圖像卡死,怎么解決?
yolov5訓練部署全鏈路教程

使用yolov5轉為kmodel之后,運行MicroPython報錯誤:IndexError: index is out of bounds怎么解決?
在K230上部署yolov5時 出現the array is too big的原因?
se5 8使用YOLOv5_object示例程序出錯“Not able to open cpu.so”的原因?
RV1126 yolov8訓練部署教程



 工商網監
工商網監
評論