 為什么要引入遠程監督方法?
為什么要引入遠程監督方法?

從早期到現在來看關系抽取任務的話,基本的做法包括基于規則匹配、監督學習、半監督學習、無監督學習以及遠程監督學習等方法,上篇文章《從頭來看關系抽取》已經介紹了監督學習早期的一些開山之作,而今天的主人公是遠程監督來做關系抽取,那么為什么要引入遠程監督的方法,什么是遠程監督的方法,基于遠程監督的關系抽取的方法從古至今是怎么演變發展的,帶著這些疑問,我們簡單了解一下。
為什么要引入遠程監督方法?
監督學習
監督學習是利用標注好的訓練數據,傳統的機器學習模型或者是深度學習算法構建網絡模型,老生常談的問題,這種方法的問題在于雖然能夠利用標注質量高的數據獲取很好的效果,但是獲取高質量的標注數據需要花費昂貴的人力、物力,因此引出很多其他的學習方式,比如半監督、無監督、遠程監督、遷移學習等等。
半監督學習
半監督學習是解決獲取大量高質量標注數據難問題的一種解決方式,利用少部分高質量標注數據,通過相關算法學習,常用的是Bootstrapping learning 以及遠程監督方法。對于關系抽取任務來說,Bootstrapping 算法的輸入少量實體關系數據作為種子,找到更多有某種關系的相關數據。但是我們可以想到一個問題就是利用少量的種子數據在大規模數據中搜尋出來的結果,是否是我們真正想要的,會不會存歧義的數據,畢竟利用一點種子就想達到我們的目標,肯定是存在某些問題的,這也是 Bootstraping 算法的語義漂移問題。
遠程監督學習
遠程監督學習很早之前就被提出來了,但是應用在關系抽取任務上面應該是2009年的一篇論文,作為遠程監督學習在關系抽取的開山之作,下面會介紹這個工作。簡單來說,遠程監督關系抽取是通過將大規模非結構化文本中的語料與知識庫對齊,這樣便可以獲取大量訓練數據供模型訓練。遠程監督關系抽取的工作可以分為兩階段,其中后期以及目前的發展都集中在神經網絡提取特征信息結合多實例學習思想。
開山燎原-2009-ACL
論文題目:Distant supervision for relation extraction without labeled data
論文地址:https://www.aclweb.org/anthology/P09-1113.pdf
這篇文章應該是最早的將遠程監督學習用于關系抽取,是一篇開山之作。
文中提出了一個強有力的假設:如果兩個實體在已知知識庫中存在,并且兩者有相對應的某種關系,那么當這兩個實體在其他非結構化文本中存在的時候也能夠表達這種關系。基于這種強有力的假設,遠程監督算法可以利用已有的知識庫,給外部非結構化文本中的句子標注某種關系標簽,相當于自動語料標注,能夠獲取大量的標注數據供模型訓練。
訓練階段
文中所采用的知識庫為Freebase,非結構化文本采用的是維基百科等數據。既然是要判定句子中的實體是否在知識庫中存在,那么必然要識別出對應的實體,識別實體部分文中依賴NER標注工具。如果句子中的兩個實體存在于知識庫中且具有某種關系,便從句子中抽取出特征(很多特征),并把具有這種關系的多個句子中特征拼接作為這個關系的某一特征向量,從不同的句子中抽取出的特征拼接,會讓后面的分類器獲取更多的信息。
特征
訓練的分類器需要很多的特征,2009年的時候還在大量的構造特征工程,因此構造的也正也幾乎完全是詞典或者語法特征,主要包括以下:
Lexical features
1、Thesequenceofwordsbetweenthetwoentities 2、Thepart-of-speechtagsofthesewords 3、Aflagindicatingwhichentitycamefirstinthesentence 4、AwindowofkwordstotheleftofEntity1andtheirpart-of-speechtags 5、AwindowofkwordstotherightofEntity2andtheirpart-of-speechtags
另外還有關系依存句法樹以及實體類別特征等。
測試階段
在測試階段中,將再次使用NER工具識別實體,句子中一起出現的每一對實體都被認為是一個潛在的關系實例,當這些實體同時出現便從句子中提取特征添加到該實體對的特征向量中。例如在測試集中10個句子中出現了一對實體,每個句子提取3個特征,那么這個實體對將有30個相關特征,對測試語料庫中每個句子的每個實體對進行特征提取,分類器根據實體對出現的所有特征為每個實體對預測關系。
問題
1、文中提出的假設太過強橫,必然會出現大量的badcase,比如句子中出現的兩個實體刻畫的并非實體庫中對應的關系描述,這樣會引入噪音臟數據,影響最終的結果。例如,創始人(喬布斯,蘋果)和ceo(喬布斯,蘋果)都是正確的。
2、文中依賴于NER工具、以及構造詞典語法句法等特征,也會存在錯誤傳播問題。
多實例學習-2011-ACL
論文題目:Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations
論文地址:https://www.aclweb.org/anthology/P11-1055.pdf
本文針對上篇文章中的強假設導致的badcase,采用多實例學習的思想,減少遠程監督噪音數據的影響。提出新的模型MULTIR,引入多實例學習的概率圖形模型,從而解決重疊關系抽取問題,重疊關系問題指的是同一對實體之間的存在多種不同類型的關系,同時結合句子級別和文檔級別的特征進行關系抽取,MULTIR在計算推理上面具有很高的效率。
多實例學習可以被描述為:假設訓練數據集中的每個數據是一個包(Bag),每個包都是一個示例(instance)的集合,每個包都有一個訓練標記,而包中的示例是沒有標記的;如果包中至少存在一個正標記的示例,則包被賦予正標記;而對于一個有負標記的包,其中所有的示例均為負標記。(這里說包中的示例沒有標記,而后面又說包中至少存在一個正標記的示例時包為正標記包,是相對訓練而言的,也就是說訓練的時候是沒有給示例標記的,只是給了包的標記,但是示例的標記是確實存在的,存在正負示例來判斷正負類別)。通過定義可以看出,與監督學習相比,多示例學習數據集中的樣本示例的標記是未知的,而監督學習的訓練樣本集中,每個示例都有一個一已知的標記;與非監督學習相比,多示例學習僅僅只有包的標記是已知的,而非監督學習樣本所有示例均沒有標記。但是多示例學習有個特點就是它廣泛存在真實的世界中,潛在的應用前景非常大。from http://blog.csdn.net/tkingreturn/article/details/39959931
經典-2015-EMNLP
論文題目:Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks
論文地址:https://www.aclweb.org/anthology/D15-1203.pdf
上面的幾篇文章已經提出了遠程監督學習在關系抽取的開山之作,以及后面會通過多實例學習(Multi Instance Learning, MIL)來減少其中的噪音數據,這篇文章也是在前人的基礎之上去做的工作,主要有兩部分,其中之一是提出piece-wise卷積神經網絡自動抽取句子中的特征信息,從而替換之前設計的特征工程;另外和之前一樣,采用多實例學習思想來減緩錯誤的badcase數據,既這篇文章將多實例學習整合到卷積神經網絡中來完成關系抽取任務。
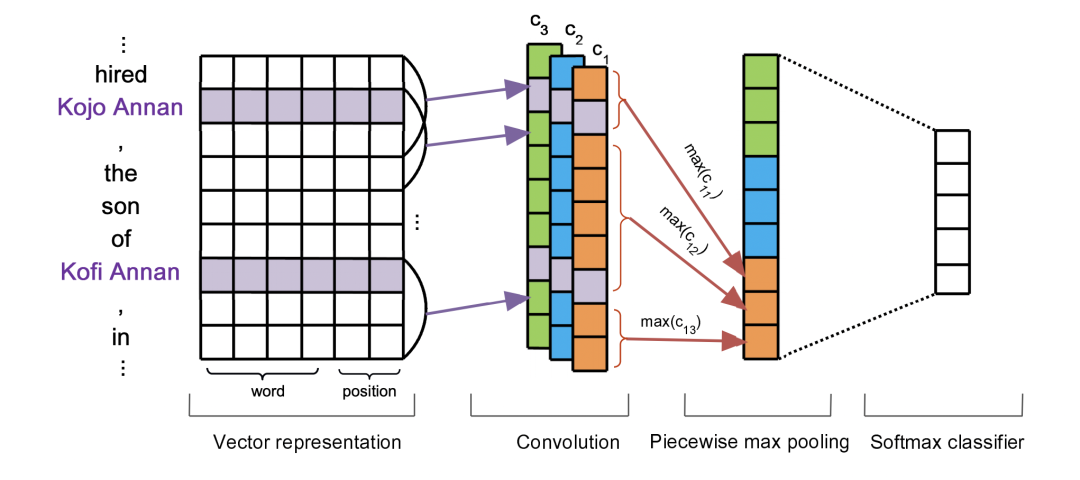
Piecewise-CNN
Vector representation
上圖是PCNN針對bags中的一個句子編碼的情況,主要分為幾部分,其中向量表示部分也和之前我們介紹過的幾篇一樣,采用的預訓練的word embedding以及句子中詞和兩個實體之間的相對距離向量,下圖中再對這個解釋一下,圖中 son 對兩個實體的相對距離分為是-2和3,到時候會把這些均轉換為向量表示,采用隨機初始化的方式。

Convolution
卷積部分從圖中便可以看出采用的是多卷積核操作,文中的Zero Padding值為1 , 卷積核的長為向量矩陣的長,寬為3,從上到下,單向滑動。
Piecewise max pooling
這部分也是之前介紹過的一篇論文中的類似做法,根據實體的位置將句子分為左中右三部分,對左中右三部分分別max-pooling,最后將所有的結果拼接,過softmax層,圖中的一個細節就是分段pooling的時候并沒有丟失兩個實體,而是將兩個實體劃分在在左中兩段中,這是一個細節,圖中也很明顯給畫出來了。
MIL-PCNN
上面的PCNN網絡結構展示的是多實例學習中一個bag(包)中的一個instance(句子)的情況,而多實例學習的輸入到網絡中的是一個包,里面包含了很多句子。假設我們存在 個bags {},每個bag包含個句子 。多實例學習的目的是預測看不見的袋子的標簽。在本文中,bag中的所有實例都是獨立考慮的,并且bag中的instance是沒有label的,只有bag中才有label,因此只需要關注bag的label即可。
模型圖中經過softmax得到的是bag中的一個instance的關系類別概率,而非bag的,因此重新定義了基于bag的損失函數,文中采取的措施是At-Least-One的假設,每個bag中至少有一個標注正確的instance,這樣就可以找到bag中置信度得分最高的instance,代表當前bag的結果。定義如下的目標函數
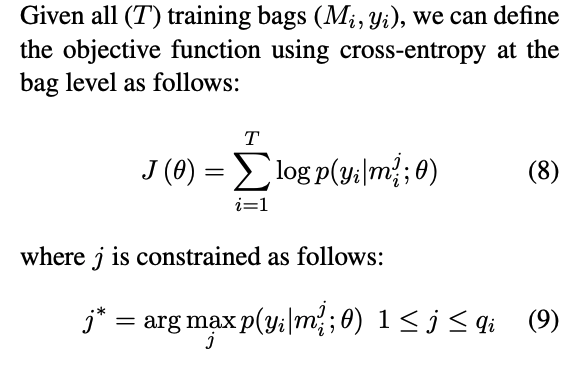
2016-ACL
論文題目:Neural Relation Extraction with Selective Attention over Instances
論文地址:https://www.aclweb.org/anthology/P16-1200.pdf
這篇文章是在上一篇文章PCNN的基礎之上進行的改進,主要是因為PCNN在多實例學習部分采用的是選取bag中置信度最高的instance(句子)作為bag的標簽,這樣的做法可能會丟失太多的信息,因為一個bag中正負樣本的數量是不定的,可能存在多個正樣本或者多個負樣本。這篇文章為了充分利用bag中的所有instance信息,利用注意力機制充分利用instance信息,減弱噪音的影響。模型的整體結構如下圖。
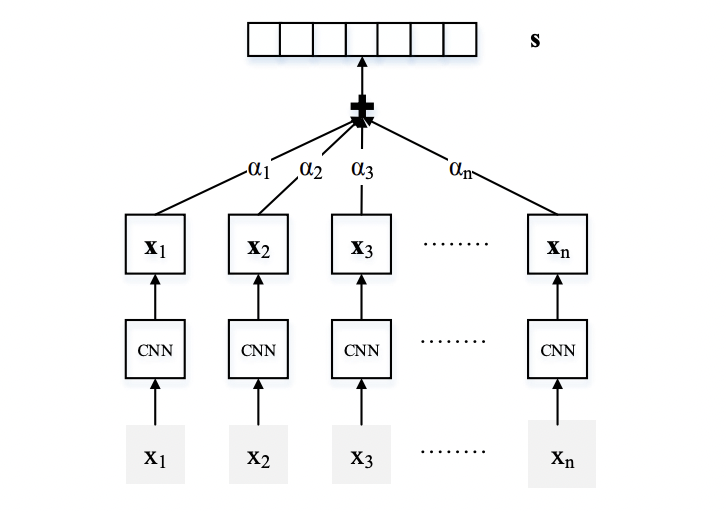
模型的整體結構也是分為兩大部分
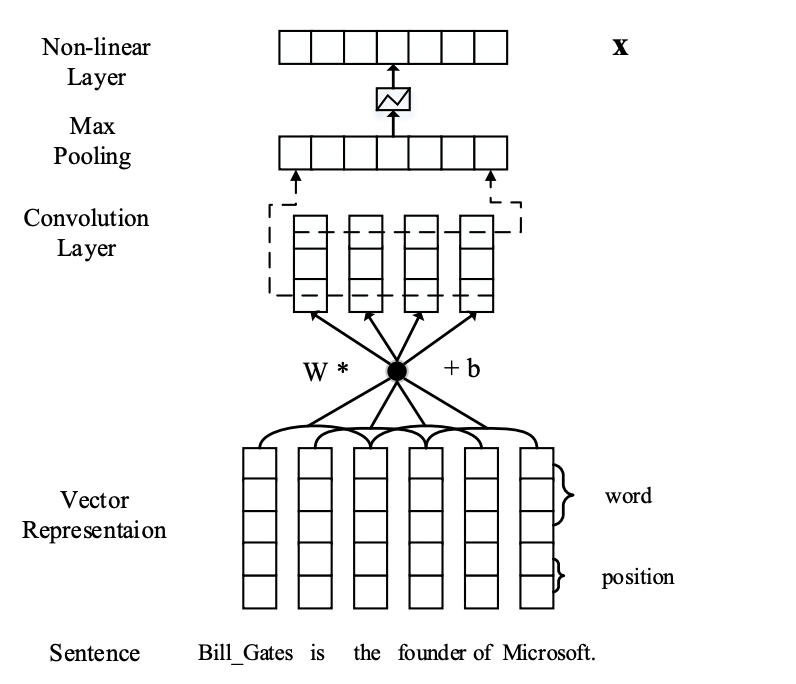
Sentence Encoder:句子編碼部分采用的方式和上文的PCNN一樣,包括輸入部分的詞向量和位置向量,卷積神經網絡,以及分段max-pooling,這部分的方式沒有區別,這部分的模型結構如下圖所示。
Selective Attention over Instances:這部分是文章的重點,改進的地方主要是在這里,利用注意力機制對bag中的instance進行加權,得到bag的最終向量表示,,其中 是權重,文中具體的有兩種計算權重的方式。
Average: 將bag中所有instance的重要程度都等同看待,即,這會放大instance的噪音影響,文中將其作為對比實驗的一個baseline。
Selective Attention: 這部分attention的目的是加強正樣本的instance、弱化負樣本instance的噪音影響。具體的計算公式見下面,其中 代表的是句子句子和關系 的相關程度, 為attention的對角矩陣,這樣就可以得到加權后的bag向量表示 。
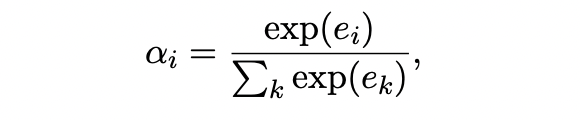
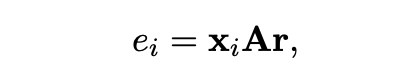
2016-COLING
論文題目:Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks
論文地址:https://www.aclweb.org/anthology/C16-1139.pdf
這篇文章也是在PCNN的基礎之上進行的改進,主要有兩方面,其一也是和上文一樣認為PCNN的at-least-once假設太過強硬,應該充分利用bag中的所有instance信息,另外是評估了數據集中存在18.3%的重疊關系數據,因此之前的單標簽是不合理的,所以這篇文章針對這兩部分進行了改進,模型的整體結構如下圖。
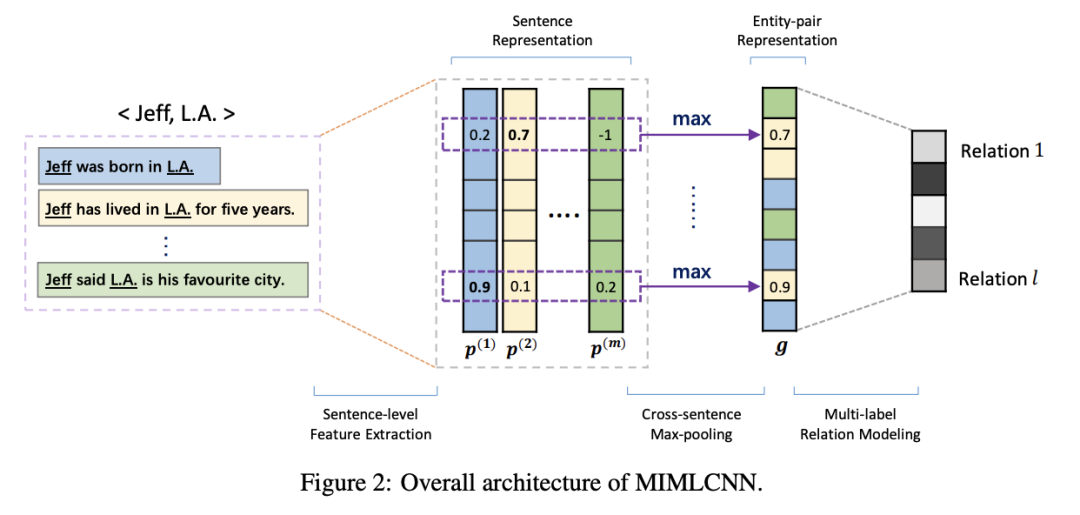
Sentence-level Feature Extraction:這部分和之前的PCNN一樣,Embedding (word + position) -> CNN -> 分段最大池化獲取每一個instance的句子表示。
Cross-sentence Max-pooling:這篇文章融合bag中所有instance信息的方法和上文不一樣,不是采用的注意力機制,而是采用了非常簡單直觀或者說粗暴的方式,將bag中每個instance的句子信息取每一維度的最大值,獲取bag的向量表示,就如圖中中間部分所示。
Multi-label Relation Modeling:之前的方式都是采用softmax多標簽分類的方式,而這篇文章為了解決重疊關系問題,將不在采用softmax,而是對每一個 relation 做 sigmoid ,然后根據閾值來判定該instance是否應該包含這個 relation 。
2017-AAAI
論文題目:Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions
論文地址:https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/download/14491/14078
這篇文章的關鍵點主要也是兩部分,其一也是考慮了at-least-once的假設太多強硬,需要采用注意力機制考慮bag中更多的instance信息,另外一個是之前的方法都過多關注實體本身,而忽略了實體背后的文本描述信息,因此,這篇文章的將實體鏈接到實體描述文本上面獲取很多的信息表達,文章的主要結構如下。
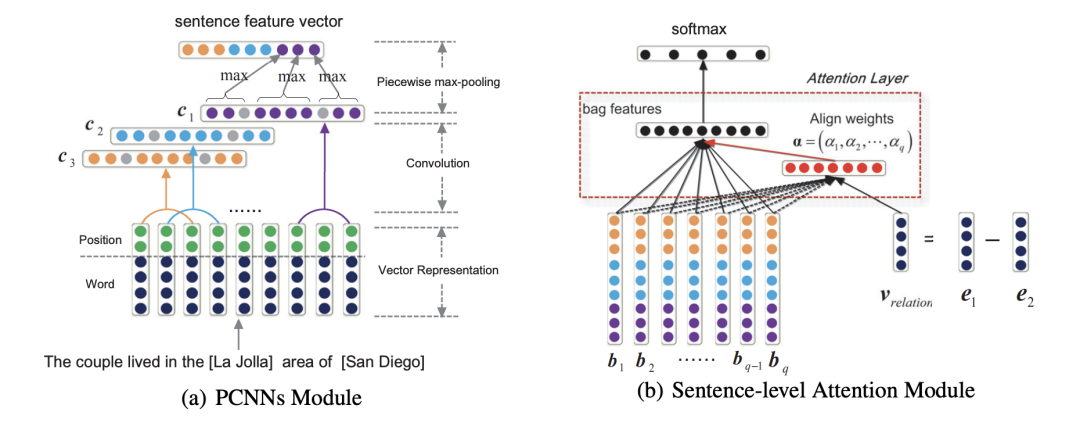
主要包括三部分
(a) PCNNs Module:這部分還是和之前一樣,完全延續了 PCNN 的模型結構,采用word + position -> CNN -> Piecewise Max-pooling獲取文中的 bag 中的句子信息表達。
(b) Sentence-level Attention Module:這部分類似之前的Selective Attention,也是計算 bag 中每個 instance 與 relation 的相關性,這里關系的向量采用的是 兩個實體信息來表達,然后計算相關的權重(如下),最后通過加權的方式獲取 bag 的向量表達,然后過線性層和softmax層做多分類,沒有考慮重疊關系。
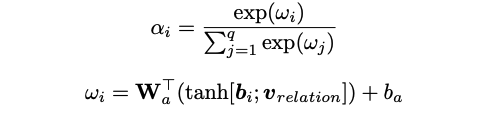
Entity Descriptions:這部分是將實體的文本描述信息編碼,采用的是簡單的CNN + max-pooling 獲取實體描述文本的向量表達,文中提出,為了盡可能使實體的向量表達與實體描述文本的向量表達在語義空間中接近,直接定義了一個距離公式計算loss, ,然后和上面判別關系的loss結合, ,兩個損失函數聯合訓練。

2018-EMNLP
論文題目:Hierarchical Relation Extraction with Coarse-to-Fine Grained Attention
論文地址:https://www.aclweb.org/anthology/D18-1247.pdf
這篇文章主要考慮到之前的關系抽取方法中,沒有考慮到關系之間是存在語義依賴關系的,而且,知識庫的關系中很多都是帶有層級結構的,另外,之前的方法沒有對關系的長尾分布問題進行仔細的考量,易導致關系數量多的則準確率更高,關系數量極少的準確率堪憂,針對上面的問題,這篇文章提出了在多實例學習中采用注意力機制的思想,提出層次化注意力機制來做具有層級的關系抽取問題,而且對于長尾分布的關系抽取也有很明顯的改善。
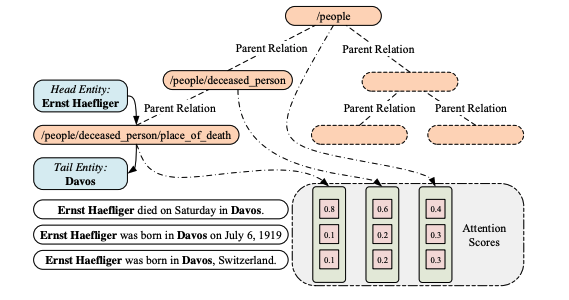
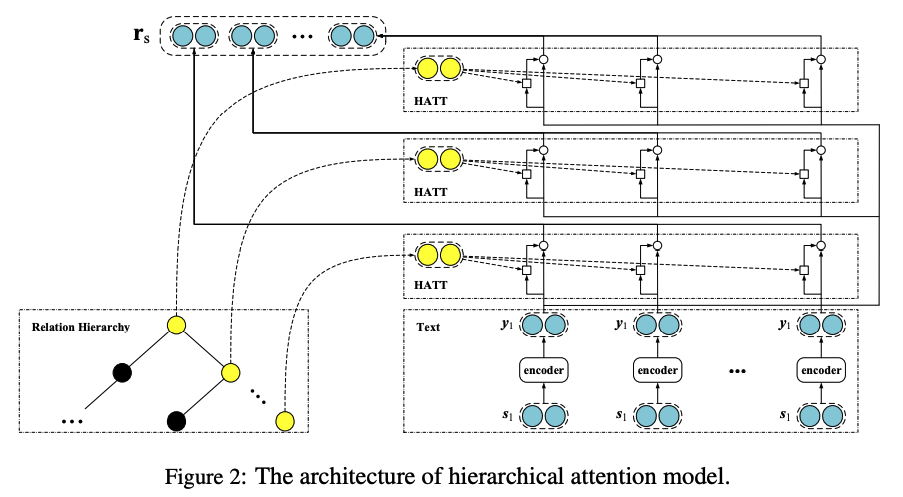
2018-EMNLP
論文題目:RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information
論文地址:https://www.aclweb.org/anthology/D18-1157.pdf
這篇文章主題思想還是遠程監督的思想,考慮到知識庫中除了實體關系之外,還有很多其他的信息可以加以利用,因此在模型中考慮了這部分特征信息,比如關系的別名信息以及實體的類別信息。另外,之前看到的很多文章都是采用了CNN的網絡結構,但是本文不同,摒棄了之前的CNN網絡結構,而是采用Bi-GRU以及GCN的文本編碼方式,考慮到采用GCN的編碼方式還是考量了Bi-GRU對文本的長距離信息依賴。文章的模型結構如下。
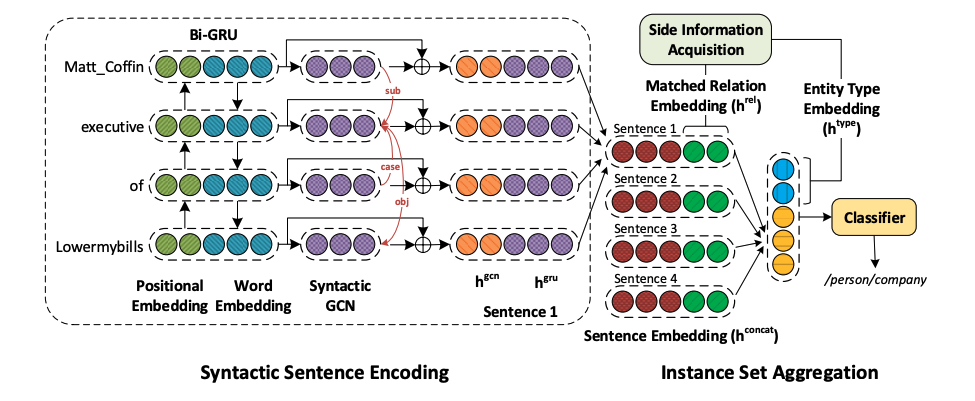
總結
以上是幾篇遠程監督關系抽取的論文,從09年的開山之作,到前兩年的一些工作,文中的工作雖然沒有覆蓋全部,但是基本的方法已有大概的脈絡梳理,總體來說,輸入表示部分基本都是詞向量與位置編碼結合,獲取句子語義部分采用CNN,Piecewise max-pool池化較多,當然也有采用GRU/GCN等,另外大多數工作基本都是多實例學習 + 注意力機制的改進與創新,其他的一些涉及到重疊關系、長尾分布等相關處理。除了前幾年的一些工作之外,最近也有遠程監督關系抽取的一些工作。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107802 -
分類器
+關注
關注
0文章
153瀏覽量
13787 -
機器學習
+關注
關注
66文章
8553瀏覽量
136962
原文標題:【關系抽取】從頭來看關系抽取-遠程監督來襲
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

2026年十大遠程辦公趨勢

PLC遠程控制不求人,手把手教你詳細設置方法
電能質量在線監測裝置遠程能校準諧波精度嗎?

遠程打印難題?一鍵搞定,再也不用跑辦公室啦!
信號發生器遠程控制LabVIEW自動化方法技巧
德國莫爾利用全新的在線配置器改進了電纜引入裝置設計流程

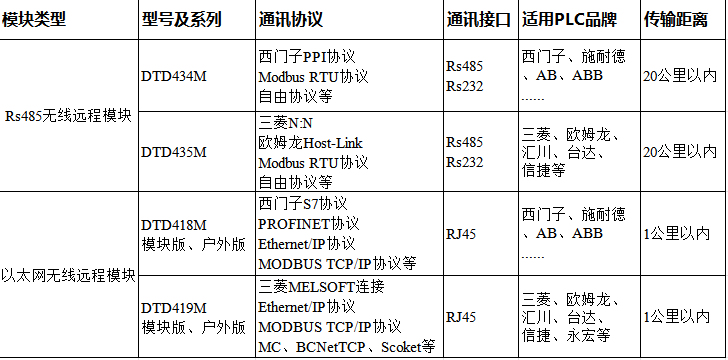
無線遠程模塊:工業/農業/物流的“遠程遙控”已就位
使用MATLAB進行無監督學習


礦山泵站遠程監控物聯網方案
皮帶秤PLC數據采集遠程監控系統方案




 工商網監
工商網監
評論