 人工智能正在加快速度從“云端”走向“邊緣”
人工智能正在加快速度從“云端”走向“邊緣”

人工智能(AI)正在加快速度從“云端”走向“邊緣”,進入到越來越小的物聯網設備中。在終端和邊緣側的微處理器上,實現的機器學習過程,被稱為微型機器學習,即TinyML。更準確的說,TinyML是指工程師們在mW功率范圍以下的設備上,實現機器學習的方法、工具和技術。
過去的十年中,由于處理器速度的提高和大數據的出現,我們見證了機器學習算法的規模呈指數級增長。在TinyML 2020 峰會上,英偉達、ARM、高通、谷歌、微軟、三星等公司紛紛展示了微型機器學習的最新成果。本次峰會得出了很多重要結論:
對于很多應用場景,TinyML技術和硬件已經進化到實用性較強的階段;
無論是算法、網絡,還是低于100KB的ML模型,都取得了重大突破;
視覺和音頻領域的低功耗需求快速增長。
TinyML 是機器學習和嵌入式 IoT 設備的交叉領域,是一門新興的工程學科,具有革新許多行業的潛力。
TinyML的主要受益者,是邊緣計算和節能計算領域。TinyML源自物聯網IoT的概念。物聯網的傳統做法,是將數據從本地設備發送到云端處理。一些人對這一方式在隱私、延遲、存儲和能源效率等方面存在疑慮。
能源效率:無論通過有線還是無線方式,數據傳輸都非常耗能,比使用乘積累加運算單元(multiply-accumulate units,MAU)的本機計算高出約一個數量級。最節能的做法,是研發具備本地數據處理能力的物聯網系統。相對于“以計算為中心”的云模型,“以數據為中心”的計算思想已得到了人工智能先驅者的一些先期探討,并已在當前得到了應用。
隱私:數據傳輸中存在侵犯隱私的隱患。數據可能被惡意行為者攔截,并且存儲在云等單個位置中時,數據固有的安全性也會降低。通過將數據大部保留在設備上,可最大程度地減少通信需求,進而提高安全性和隱私性。
存儲:許多物聯網設備所獲取的大部分數據是毫無用處的。想象一下,一臺安防攝像機每天 24 小時不間斷地記錄著建筑物的入口情況。在一天的大部分時間中,該攝像機并沒有發揮任何作用,因為并沒有什么異常情況發生。采用僅在必要時激活的更智能的系統,可降低對存儲容量的需求,進而降低需傳輸到云端的數據量。
延遲:標準的物聯網設備,例如 Amazon Alexa,需將數據傳輸到云來處理,然后由算法的輸出給出響應。從這個意義上講,設備只是云模型的一個便捷網關,類似于和 Amazon 服務器之間的信鴿。設備本身并非智能的,響應速度完全取決于互聯網性能。如果網速很慢,那么 Amazon Alexa 的響應也會變慢。自帶自動語音識別功能的智能 IoT 設備,由于降低甚至是完全消除了對外部通信的依賴,因此降低了延遲。
上述問題推動著邊緣計算的發展。邊緣計算的理念就是在部署在云“邊緣”的設備上實現數據處理功能。這些邊緣設備在內存、計算和功能方面都高度受限于設備自身的資源,進而需要研發更為高效的算法、數據結構和計算方法。
此類改進同樣適用于規模較大的模型,在不降低模型準確率(accuracy)的同時,實現機器學習模型效率數個數量級的提高。例如,Microsoft開發的Bonsai算法可小到2 KB,但比通常40MB的kNN算法或是4MB的神經網絡具有更好的性能。這個結果聽上去可能無感,但如果換句話說——在規模縮小了一萬倍的模型上取得同樣的準確率,這就十分令人印象深刻了。規模如此小的模型,可以運行在2KB內存的Arduino Uno上。簡而言之,現在可以在售價5美元的微控制器上構建此類機器學習模型。
機器學習正處于一個交叉路口,兩種計算范式齊頭并進,即以計算為中心的計算,和以數據為中心的計算。
在以計算為中心的計算范式下,數據是在數據中心的實例上存儲和分析的;而在以數據為中心的計算范式下,處理是在數據的原始位置執行的。
盡管在目前,以計算為中心的計算范式似乎很快會達到上限,但是以數據為中心的計算范式才剛剛起步。
當前,物聯網設備和嵌入式機器學習模型日益普及。人們可能并未注意到其中許多設備,例如智能門鈴、智能恒溫器,以及只要用戶說話甚至拿起就可以“喚醒”的智能手機。
下面將深入介紹 TinyML 的工作機制,以及在當前和將來的應用情況。
應用領域
目前,TinyML主要的兩個重點應用領域是:
關鍵字發現:大多數人已經非常熟悉此應用,例如“你好,Siri”和“你好,Google”等關鍵字,通常也稱為“熱詞”或“喚醒詞”。設備會連續監聽來自麥克風的音頻輸入,訓練實現僅響應與所學關鍵字匹配的特定聲音序列。這些設備比自動語音識別(automatic speech recognition,ASR)更簡單,使用更少的資源。Google智能手機等設備還使用了級聯架構實現揚聲器的驗證,以確保安全性。
視覺喚醒詞:視覺喚醒詞使用圖像類似替代喚醒詞的功能,通過對圖像做二分類表示存在與否。例如,設計一個智能照明系統,在檢測到人的存在時啟動,并在人離開時關閉。同樣,野生動物攝影師可以使用視覺喚醒功能在特定的動物出現時啟動拍攝,安防攝像機可以在檢測到人活動時啟動拍攝。
下圖全面展示當前TinyML機器學習的應用概覽。
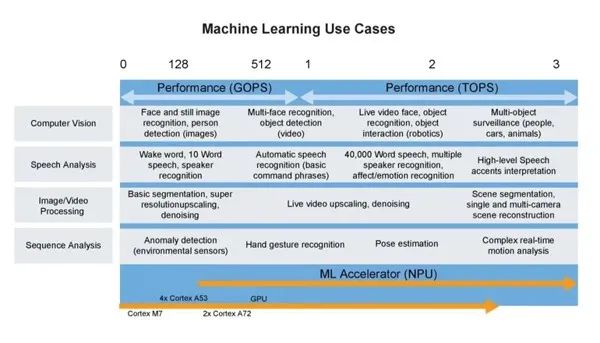
圖3 TinyML 的機器學習用例(圖片來源:NXP)
TinyML工作機制
TinyML 算法的工作機制與傳統機器學習模型幾乎完全相同,通常在用戶計算機或云中完成模型的訓練。訓練后處理是TinyML真正發揮作用之處,通常稱為“深度壓縮”(deep compression)。
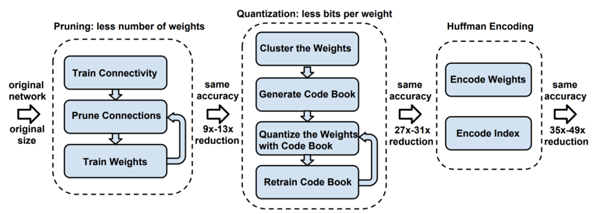
圖4 深度壓縮示意圖(來源:[ArXiv 論文](https://arxiv.org/pdf/1510.00149.pdf))
模型蒸餾(Distillation)
模型在訓練后需要更改,以創建更緊湊的表示形式。這一過程的主要實現技術包括剪枝(pruning)和知識蒸餾。
知識蒸餾的基本理念,是考慮到較大網絡內部存在的稀疏性或冗余性。雖然大規模網絡具有較高的表示能力,但如果網絡容量未達到飽和,則可以用具有較低表示能力的較小網絡(即較少的神經元)表示。在 Hinton 等人 2015 年發表的研究工作中,將 Teacher 模型中轉移給 Student 模型的嵌入信息稱為“黑暗知識”(dark knowledge)。
下圖給出了知識蒸餾的過程:
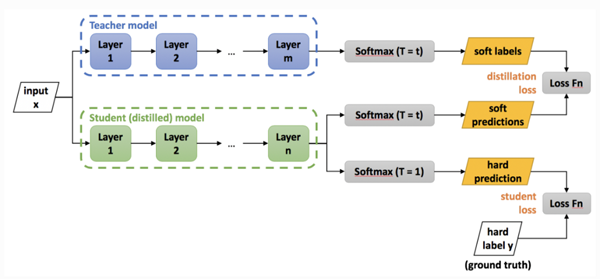
圖 5 深度壓縮過程圖
圖中Teacher模型是經過訓練的卷積神經網絡模型,任務是將其“知識”轉移給稱為Student 模型的,參數較少的小規模卷積網絡模型。此過程稱為“知識蒸餾”,用于將相同的知識包含在規模較小的網絡中,從而實現一種網絡壓縮方式,以便用于更多內存受限的設備上。
同樣,剪枝有助于實現更緊湊的模型表示。寬泛而言,剪枝力圖刪除對輸出預測幾乎無用的神經元。這一過程通常涉及較小的神經權重,而較大的權重由于在推理過程中具有較高的重要性而會得到保留。隨后,可在剪枝后的架構上對網絡做重新訓練,調優輸出。
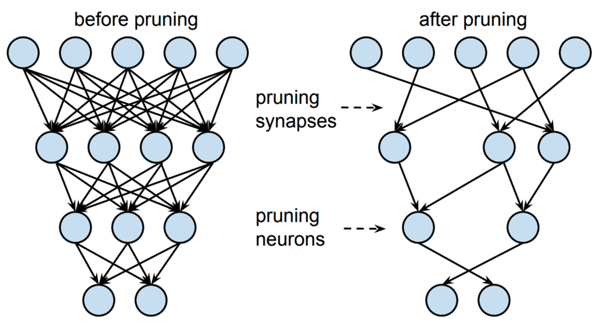
圖6 對蒸餾模型知識表示做剪枝的圖示
量化(Quantization)
蒸餾后的模型,需對此后的訓練進行量化,形成兼容嵌入式設備架構的格式。
為什么要做量化?假定對于一臺Arduino Uno,使用8位數值運算的ATmega328P微控制器。在理想情況下要在Uno上運行模型,不同于許多臺式機和筆記本電腦使用32位或64位浮點表示,模型的權重必須以8位整數值存儲。通過對模型做量化處理,權重的存儲規模將減少到1/4,即從32位量化到8位,而準確率受到的影響很小,通常約1-3%。
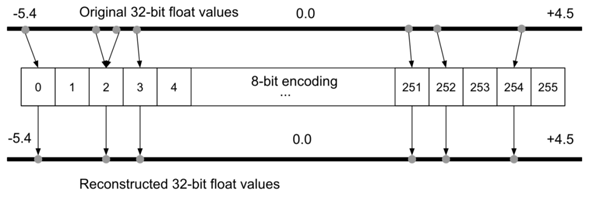
圖7 8 位編碼過程中的量化誤差示意圖(圖片來源:《[TinyML](https://tinymlbook.com/)》一書)
由于存在量化誤差,可能會在量化過程中丟失某些信息。例如在基于整型的平臺上,值為3.42的浮點表示形式可能會被截取為3。為了解決這個問題,有研究提出了量化可感知(quantization-aware,QA)訓練作為替代方案。QA訓練本質上是在訓練過程中,限制網絡僅使用量化設備可用的值。
霍夫曼編碼
編碼是可選步驟。編碼通過最有效的方式來存儲數據,可進一步減小模型規模。通常使用著名的 霍夫曼編碼。
編譯
對模型量化和編碼后,需將模型轉換為可被輕量級網絡解釋器解釋的格式,其中最廣為使用的就是TF Lite(約500 KB大小)和TF Lite Micro(約20 KB)。模型將編譯為可被大多數微控制器使用并可有效利用內存的C 或C++ 代碼,由設備上的解釋器運行。
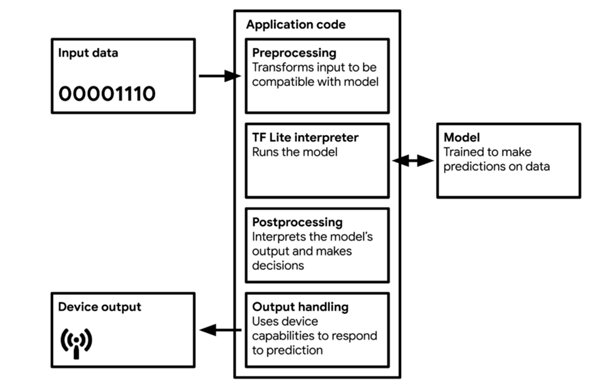
圖8 TinyML 應用的工作流圖(來源:Pete Warden 和 Daniel Situnayake 編寫的《[TinyML](https://tinymlbook.com/)》一書)
大多數TinyML技術,針對的是處理微控制器所導致的復雜性。TF Lite和TF Lite Micro非常小,是因為其中刪除了所有非必要的功能。不幸的是,它們同時也刪除了一些有用的功能,例如調試和可視化。這意味著,如果在部署過程中出現錯誤,可能很難判別原因。
為什么不在設備上訓練?
在設備上進行訓練會引入額外的復雜性。由于數值精度的降低,要確保網絡訓練所需的足夠準確率是極為困難的。在標準臺式計算機的精度下,自動微分方法是大體準確的。計算導數的精度可達令人難以置信的10^{-16},但是在8 位數值上做自動微分,將給出精度較差的結果。在反向傳播過程中,會組合使用求導并最終用于更新神經參數。在如此低的數值精度下,模型的準確率可能很差。
盡管存在上述問題,一些神經網絡還是使用了 16 位和 8 位浮點數做了訓練。
計算效率如何?
可以通過定制模型,提高模型的計算效率。一個很好的例子就是MobileNet V1 和MobileNet V2,它們是已在移動設備上得到廣泛部署的模型架構,本質上是一種通過重組(recast)實現更高計算效率卷積運算的卷積神經網絡。這種更有效的卷積形式,稱為深度可分離卷積結構(depthwiseseparable convolution)。針對架構延遲的優化,還可以使用基于硬件的概要(hardware-based profiling)和神經架構搜索(neural architecture search)等技術。
新一輪人工智能革命
在資源受限的設備上運行機器學習模型,為許多新的應用打開了大門。使標準的機器學習更加節能的技術進步,將有助于消除數據科學對環境影響的一些擔憂。此外,TinyML支持嵌入式設備搭載基于數據驅動算法的全新智能,進而應用在了從 預防性維護 到 檢測森林中的鳥叫聲 等多種場景中。
盡管繼續擴大模型的規模是一些機器學習從業者的堅定方向,但面向內存、計算和能源效率更高的機器學習算法發展也是一個新的趨勢。TinyML仍處于起步階段,在該方向上的專家很少。該方向正在快速增長,并將在未來幾年內,成為人工智能在工業領域的重要新應用。
原文標題:TinyML:下一輪人工智能革命
文章出處:【微信公眾號:FPGA入門到精通】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
FPGA
+關注
關注
1660文章
22408瀏覽量
636240 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265295
原文標題:TinyML:下一輪人工智能革命
文章出處:【微信號:xiaojiaoyafpga,微信公眾號:電子森林】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
從云端集中到邊緣分布:邊緣智算如何重塑算力網絡布局

邊緣計算和人工智能,別再傻傻分不清啦!
利用超微型 Neuton ML 模型解鎖 SoC 邊緣人工智能
Arm 洞察與思考:為什么 AI 向邊緣遷移的速度超乎想象
AI 邊緣計算網關:開啟智能新時代的鑰匙?—龍興物聯
挖到寶了!人工智能綜合實驗箱,高校新工科的寶藏神器
挖到寶了!比鄰星人工智能綜合實驗箱,高校新工科的寶藏神器!
超小型Neuton機器學習模型, 在任何系統級芯片(SoC)上解鎖邊緣人工智能應用.
為何邊緣設備正成為AI的新重心
最新人工智能硬件培訓AI 基礎入門學習課程參考2025版(大模型篇)
邊緣計算如何顛覆人工智能變革
從邊緣計算 到云端計算



 工商網監
工商網監
評論