 如何讓Bert模型在下游任務中提高性能?
如何讓Bert模型在下游任務中提高性能?

隨著Transformer 在NLP中的表現,Bert已經成為主流模型,然而大家在下游任務中使用時,是不是也會發現模型的性能時好時壞,甚至相同參數切換一下隨機種子結果都不一樣,又或者自己不管如何調,模型總達不到想象中的那么好,那如何才能讓Bert在下游任務中表現更好更穩呢?本文以文本分類為例,介紹幾種能幫你提高下游任務性能的方法。
Further Pre-training
最穩定也是最常用的提升下游任務性能的手段就是繼續進行預訓練了。繼續預訓練目前有以下幾種模式。
二階段
首先回顧一下,Bert 是如何使用的呢?
我們假設通用泛化語料為 ,下游任務相關的數據為 , Bert 即在通用語料 上訓練一個通用的Language Model, 然后利用這個模型學到的通用知識來做下游任務,也就是在下游任務上做fine-tune,這就是二階段模式。
大多數情況下我們也都是這么使用的:下載一個預訓練模型,然后在自己的數據上直接fine-tune。
三階段
在論文Universal Language Model Fine-tuning for Text Classification[1]中,作者提出了一個通用的范式ULMFiT:
在大量的通用語料上訓練一個LM(Pretrain);
在任務相關的小數據上繼續訓練LM(Domain transfer);
在任務相關的小數據上做具體任務(Fine-tune)。
那我們在使用Bert 時能不能也按這種范式,進行三階段的fine-tune 從而提高性能呢?答案是:能!
比如邱錫鵬老師的論文How to Fine-Tune BERT for Text Classification?[2]和Don't Stop Pretraining: Adapt Language Models to Domains and Tasks[3]中就驗證了,在任務數據 繼續進行pretraining 任務,可以提高模型的性能。
那如果我們除了任務數據沒有別的數據時,怎么辦呢?簡單,任務數據肯定是相同領域的,此時直接將任務數據看作相同領域數據即可。所以,在進行下游任務之前,不妨先在任務數據上繼續進行pre-training 任務繼續訓練LM ,之后再此基礎上進行fine-tune。
四階段
我們在實際工作上,任務相關的label data 較難獲得,而unlabeled data 卻非常多,那如何合理利用這部分數據,是不是也能提高模型在下游的性能呢?答案是:也能!
在大量通用語料上訓練一個LM(Pretrain);
在相同領域 上繼續訓練LM(Domain transfer);
在任務相關的小數據上繼續訓練LM(Task transfer);
在任務相關數據上做具體任務(Fine-tune)。
而且上述兩篇論文中也給出了結論:先Domain transfer 再進行Task transfer 最后Fine-tune 性能是最好的。
如何further pre-training
how to mask
首先,在further pre-training時,我們應該如何進行mask 呢?不同的mask 方案是不是能起到更好的效果呢?
在Roberta 中提出,動態mask 方案比固定mask 方案效果更好。此外,在做Task transfer 時,由于數據通常較小,固定的mask 方案通常也容易過擬合,所以further pre-training 時,動態隨機mask 方案通常比固定mask 效果更好。
而ERNIE 和 SpanBert 中都給出了結論,更有針對性的mask 方案可以提升下游任務的性能,那future pre-training 時是否有什么方案能更有針對性的mask 呢?
劉知遠老師的論文Train No Evil: Selective Masking for Task-Guided Pre-Training[4]就提出了一種更有針對性的mask 方案Selective Mask,進行further pre-training 方案,該方案的整體思路是:
在 上訓練一個下游任務模型 ;
利用 判斷token 是否是下游任務中的重要token,具體計算公式為:, 其中 為完整句子(序列), 為一個初始化為空的buffer,每次將句子中的token 往buffer中添加,如果加入的token 對當前任務的表現與完整句子在當前任務的表現差距小于閾值,則認為該token 為重要token,并從buffer 中剔除;
利用上一步中得到的token label,訓練一個二分類模型 ,來判斷句子中的token 是否為重要token;
利用 ,在domain 數據上進行預測,根據預測結果進行mask ;
進行Domain transfer pre-training;
在下游任務進行Fine-tuning。
上述方案驗證了更有針對性的mask 重要的token,下游任務中能得到不錯的提升。綜合下來,Selective Mask > Dynamic Mask > Static Mask
雖然selective mask 有提升,但是論文給出的思路太過繁瑣了,本質上是判斷token 在下游任務上的影響,所以這里給出一個筆者自己腦洞的一個方案:「通過 在unlabeled 的Domain data 上直接預測,然后通過不同token 下結果的熵的波動來確定token 對下游任務的影響」。這個方案我沒有做過實驗,有興趣的可以試試。
when to stop
在further pretraining 時,該何時停止呢?是否訓練的越久下游任務就提升的越多呢?答案是否定的。在進行Task transfer 時,應該訓練多少步,論文How to Fine-Tune BERT for Text Classification?[5]進行了實驗,最后得出的結論是100k步左右,下游任務上提升是最高的,這也與我自己的實驗基本吻合,訓練過多就會過擬合,導致下游任務上提升小甚至降低。
此外,由于下游任務數據量的不同,進行多少步結果是最優的也許需要實驗測試。這里給出一個更快捷穩妥的方案:借鑒PET本質上也是在訓練MLM 任務,我們可以先利用利用PET做fine-tuning,然后將最優模型作為預訓練后的模型來進行分類任務fine-tuning,這種方案我實驗后的結論是與直接進行Task transfer性能提升上相差不大。不了解PET的可以查看我之前博文PET-文本分類的又一種妙解[6].
how to fine-tuning
不同的fine-tuning 方法也是影響下游任務性能的關鍵因素。
optimizer
關于優化方案上,Bert 的論文中建議使用與bert 預訓練時一致的方案進行fine-tuning,即使用weighted decay修正后的Adam,并使用warmup策略 搭配線性衰減的學習率。不熟悉的同學可以查看我之前的博文optimizer of bert[7]
learning rate
不合適的learning rate可能會導致災難性遺忘,通常learning rate 在 之間,更大的learning rate可能就會發生災難性遺忘,不利于優化。
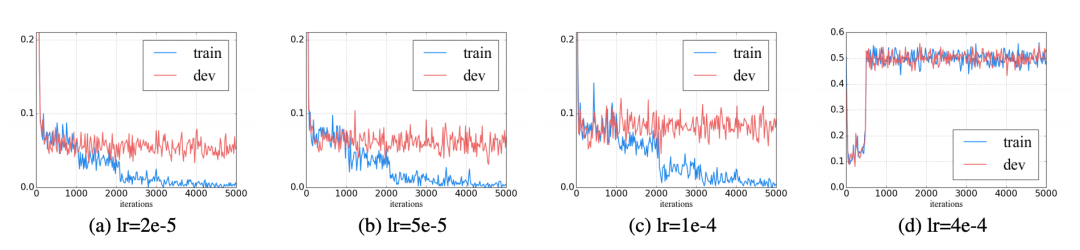
此外,對transformer 逐層降低學習率也能降低發生災難性遺忘的同時提升一些性能。
multi-task
Bert在預訓練時,使用了兩個task:NSP 和 MLM,那在下游任務中,增加一個輔助的任務是否能帶來提升呢?答案是否定的。如我之前嘗試過在分類任務的同時,增加一個相似性任務:讓樣本與label desc的得分高于樣本與其他樣本的得分,但是最終性能并沒有得到提升。具體的實驗過程請看博文模型增強之從label下手[8]。
此外,論文How to Fine-Tune BERT for Text Classification?[9]也任務multi-task不能帶來下游任務的提升。
which layer
Bert的結構上是一個12層的transformer,在做文本分類時,通常我們是直接使用最后一層的[CLS]來做fine-tuning,這樣是最優的嗎?有沒有更好的方案?
論文How to Fine-Tune BERT for Text Classification?[10]中針對這個問題也做了實驗,對比了不同的layer不同的抽取策略,最終結論是所有層拼接效果最好,但是與直接使用最后一層差距不大。
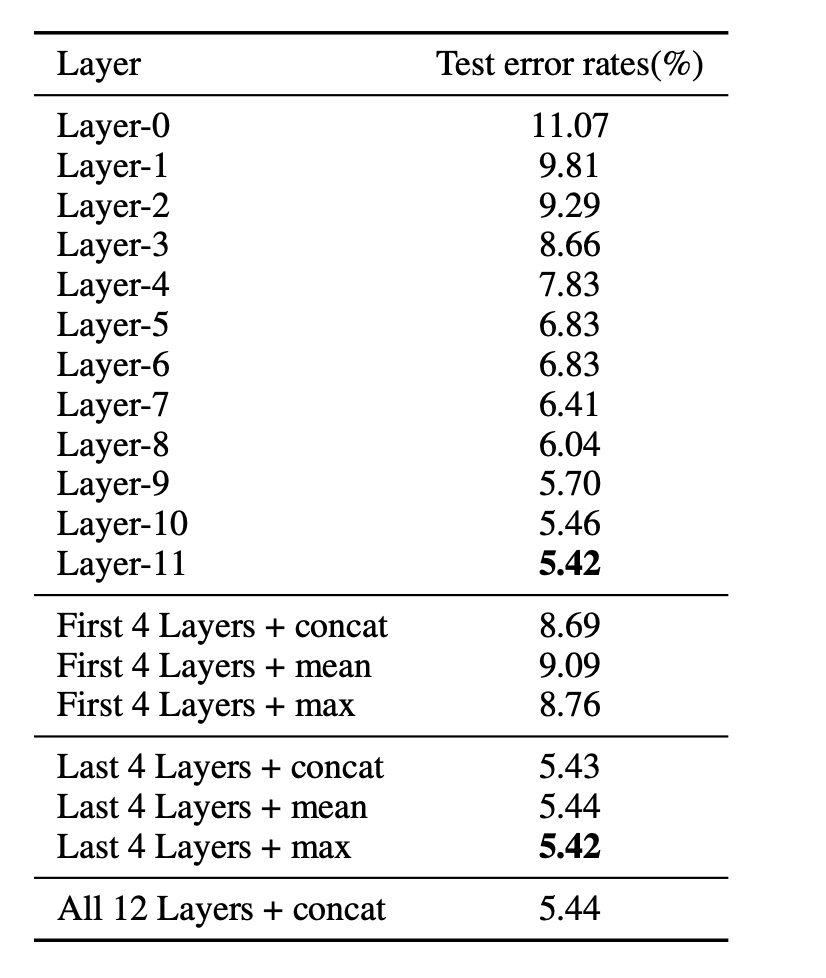
而論文Hate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model[11]中,作者通過組合多種粒度的語義信息,即將12層的[CLS]拼接后,送人CNN,在Hate Speech Detection 中能帶來8個點的提升!cnn.png)
所以在fine-tuning時,也可以想一想到底是哪種粒度的語義信息對任務更重要。
Self-Knowledge Distillation
self-knowledge distillation(自蒸餾)也是一種常用的提升下游任務的手段。做法是先在Task data上fine-tuning 一個模型,然后通過模型得到Task data 的soft labels,然后使用soft labels 代替hard label 進行fine-tuning。更多細節可以查看之前的博文Knowledge Distillation之知識遷移[12]
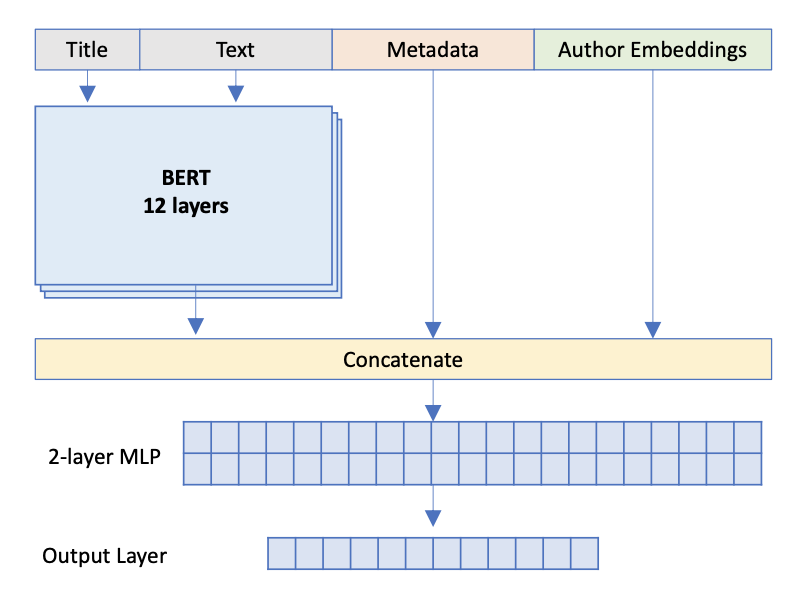
知識注入
通過注入外部知識到bert中也能提升Bert的性能,常用的方式主要有兩種:
在bert embedding 層注入:通過將外部Embedding 與Bert token-embedding 拼接(相加)進行融合,然后進行transformer一起作用下游;
在transformer的最后一層,拼接外部embedding,然后一起作用下游。
如Enriching BERT with Knowledge Graph Embeddings for Document Classification[13]中,通過在transformer的最后一層中拼接其他信息,提高模型的性能。
數據增強
NLP中數據增強主要有兩種方式:一種是保持語義的數據增強,一種是可能破壞語義的局部擾動增強。
保持語義通常采用回譯法,局部擾動的通常使用EDA,更多細節可以查看之前博文NLP中的數據增強[14]
原文標題:【BERT】如何提升BERT在下游任務中的性能
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
模型
+關注
關注
1文章
3752瀏覽量
52102 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:【BERT】如何提升BERT在下游任務中的性能
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GT-BGA-2003高性能BGA插座
半導體下游應用趨勢:智能汽車、物聯網與數據中心新機遇
大模型驅動的發射任務智能調度分系統軟件平臺的應用與未來發展
提高RISC-V在Drystone測試中得分的方法
【產品介紹】Altair HPCWorks高性能計算管理平臺(HPC平臺)

NVMe高速傳輸之擺脫XDMA設計27: 橋設備模型設計
【「DeepSeek 核心技術揭秘」閱讀體驗】+混合專家
明遠智睿RK3588:創新了高性能,讓顧慮煙消云散
高性能低功耗雙核Wi-Fi6+BLE5.3二合一
訊飛星辰MaaS平臺實現高性能DeepSeek V3上線
IBM Spectrum LSF如何助力半導體企業應對AI時代的高性能芯片需求
KaihongOS操作系統FA模型與Stage模型介紹
開售RK3576 高性能人工智能主板
RAKsmart高性能服務器集群:驅動AI大語言模型開發的算力引擎
?VLM(視覺語言模型)?詳細解析




 工商網監
工商網監
評論