") 視覺新范式Transformer之ViT的成功
視覺新范式Transformer之ViT的成功

這是一篇來自谷歌大腦的paper。這篇paper的主要成果是用Transformer[1]取代CNN,并證明了CNN不是必需的,甚至在大規(guī)模數(shù)據(jù)集預(yù)訓(xùn)練的基礎(chǔ)上在一些benchmarks做到了SOTA,并且訓(xùn)練時使用的資源更少。
圖像分塊
要將圖片分塊是因為Transformer是用于NLP領(lǐng)域的,在NLP里面,Transformer的輸入是一個序列,每個元素是一個word embedding。因此將Transformer用于圖像時也要找出word的概念,于是就有了這篇paper的title:AN IMAGE IS WORTH 16X16 WORDS,將一張圖片看成是16*16個“單詞”。
inductive biases
在機器學(xué)習(xí)中,人們對算法做了各種的假設(shè),這些假設(shè)就是inductive biases(歸納偏置),例如卷積神經(jīng)網(wǎng)絡(luò)就有很強的inductive biases。文中做了一個實驗,在中等大小數(shù)據(jù)集訓(xùn)練時,精度會略遜色于ResNets。但是這個結(jié)果也是應(yīng)該預(yù)料到的,因為Transformer缺少了CNN固有的一些inductive biases,比如平移不變性和局部性。所以當(dāng)沒有足夠的數(shù)據(jù)用于訓(xùn)練時,你懂的。但是恰恰Transformer就強在這一點,由于Transformer運算效率更高,而且模型性能并沒有因為數(shù)據(jù)量的增大而飽和,至少目前是這樣的,就是說模型性能的上限很高,所以Transformer很適合訓(xùn)練大型的數(shù)據(jù)集。
ViT
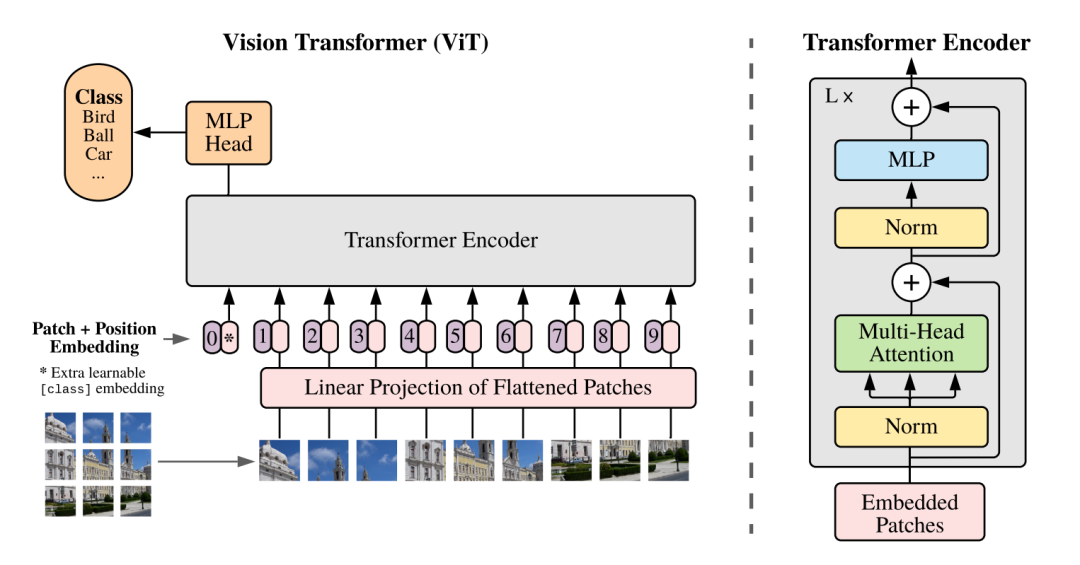
在ViT中,模型只有Encoder的,沒有Decoder,因為只是用于識別任務(wù),不需要Decoder。
首先按照慣例,先把圖像的patch映射成一個embedding,即圖中的linear projection層。然后加上position embedding,這里的position是1D的,因為按照作者的說法是在2D上并沒有性能上的提升。最后還要加上一個learnable classification token放在序列的前面,classification由MLP完成。
Hybrid Architecture。模型也可以是CNN和Transformer的混合,即Transformer的輸入不是原圖像的patch,而是經(jīng)過CNN得到的feature map的patch。
實驗結(jié)果
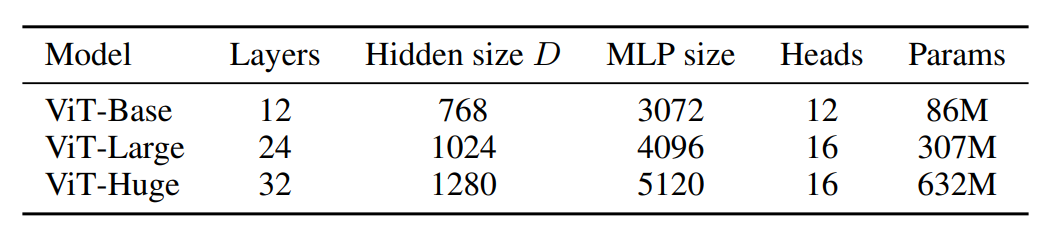
不同大小的ViT的參數(shù)量。
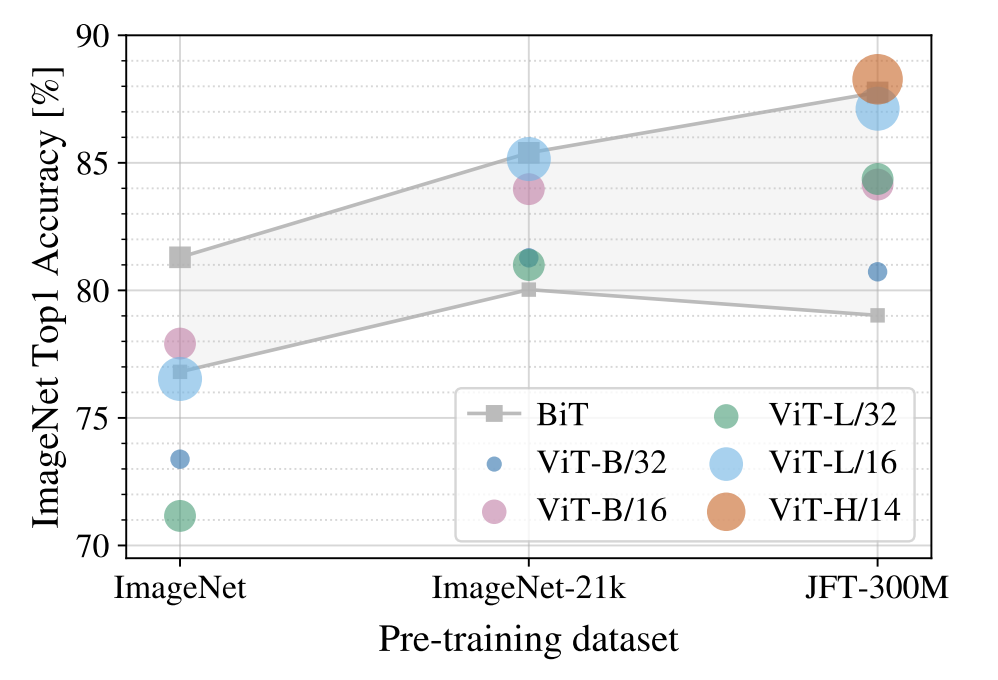
可以看到在預(yù)訓(xùn)練數(shù)據(jù)集很小的情況下ViT的效果并不好,但是好在隨著預(yù)訓(xùn)練數(shù)據(jù)集越大時ViT的效果越好,最終超過ResNet。
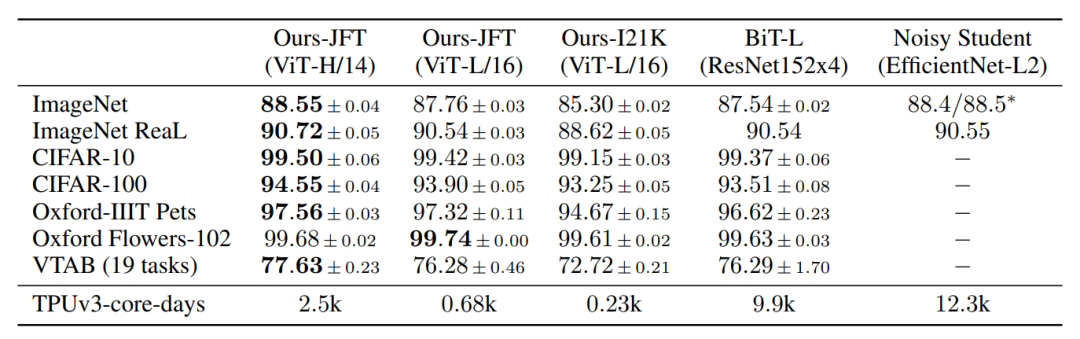
BiT[2]是谷歌用JFT-300M(谷歌內(nèi)部非公開數(shù)據(jù)集)訓(xùn)練的ResNet模型。Noisy Student[3]是谷歌提出借助半監(jiān)督大大提升了imagenet性能的算法。可以看到,在JFT-300M預(yù)訓(xùn)練的情況下,ViT比ResNet好上不少,并且開銷更小。
總結(jié)
ViT的成功我認為是以下幾點:
1、self-attention比CNN更容易捕捉long-range的信息;
2、大量的數(shù)據(jù),在視覺中CNN是人類實踐中很成功的inductive biases,顯然大量的數(shù)據(jù)是能戰(zhàn)勝inductive biases的;
3、計算效率高,因為self-attention可以看作是矩陣運算,所以效率很高,容易訓(xùn)練大型的模型。
原文標題:視覺新范式Transformer之ViT
文章出處:【微信公眾號:深度學(xué)習(xí)實戰(zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
機器視覺
+關(guān)注
關(guān)注
165文章
4798瀏覽量
126054 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136940 -
Transforme
+關(guān)注
關(guān)注
0文章
12瀏覽量
8957
原文標題:視覺新范式Transformer之ViT
文章出處:【微信號:gh_a204797f977b,微信公眾號:深度學(xué)習(xí)實戰(zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
哈爾濱工業(yè)大學(xué)與鴻之微科技座談會成功舉辦
Transformer 入門:從零理解 AI 大模型的核心原理
Transformer如何讓自動駕駛大模型獲得思考能力?
告別漏檢與低效,維視智造用2D+3D視覺攻克3C連接器質(zhì)檢難題
潤和軟件旗下捷科入編2025“人工智能+”行業(yè)生態(tài)范式案例集

Transformer如何讓自動駕駛變得更聰明?
使用MotorControl Workbench_6.3.2配置STM32H743VIT6E的FOC電機控制軟件時,找不到對應(yīng)型號怎么解決?
MotorControl Workbench_6.3.2配置單片機時找不到STM32H743VIT6E,如何解決?
STM32H743VIT6用QSPI的接口,想換個CS的管腳,但芯片內(nèi)置是綁死的,這個要怎么處理?
Transformer架構(gòu)中編碼器的工作流程

Transformer架構(gòu)概述

ALVA空間智能視覺焊接方案重構(gòu)工業(yè)焊接范式
演講實錄丨阿丘科技李嘉悅:大模型驅(qū)動的AI檢測范式變革——大模型、小模型、智能體的協(xié)同進化

?VLM(視覺語言模型)?詳細解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論