 多模態中NLP與CV融合的方式有哪些?
多模態中NLP與CV融合的方式有哪些?

最早接觸多模態是一個抖音推薦項目,有一些視頻,標題,用戶點贊收藏等信息,給用戶推薦作品,我當時在這個項目里負責用NLP部分上分,雖然最后用wide and deep 整個團隊效果還可以,但是從a/b test 看文本部分在其中起到的作用為0... ( ) 現在看來還是wide and deep這種方式太粗暴了(對于復雜信息的融合),本文寫寫多模態掃盲基礎和最近大家精巧的一些圖像文本融合的模型設計,主要是在VQA(視覺問答)領域,也有一個多模態QA,因為在推薦領域,你也看到了,即使NLP的貢獻為零,用戶特征足夠,效果也能做到很好了。
一. 概念掃盲
多模態(MultiModal)
多種不同的信息源(不同的信息形式)中獲取信息表達
五個挑戰
表示(Multimodal Representation)的意思,比如shift旋轉尺寸不變形,圖像中研究出的一種表示
表示的冗余問題
不同的信號,有的象征性信號,有波信號,什么樣的表示方式方便多模態模型提取信息
表示的方法
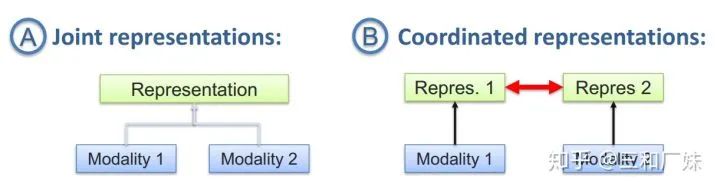
聯合表示將多個模態的信息一起映射到一個統一的多模態向量空間
協同表示負責將多模態中的每個模態分別映射到各自的表示空間,但映射后的向量之間滿足一定的相關性約束。
2. 翻譯/轉化/映射
信號的映射,比如給一個圖像,將圖像翻譯成文字,文字翻譯成圖像,信息轉化成統一形式后來應用
方式,這里就跟專門研究翻譯的領域是重疊,基于實例的翻譯,涉及到檢索,字典(規則)等,基于生成方法如生成翻譯的內容
3. 對齊
多模態對齊定義為從兩個或多個模態中查找實例子組件之間的關系和對應,研究不同的信號如何對齊(比如給電影,找出劇本中哪一段)
對齊方式,有專門研究對齊的領域,主要兩種,顯示對齊(比如時間維度上就是顯示對齊的),隱式對齊(比如語言的翻譯就不是位置對位置)
4. 融合
比如情感分析中語氣和語句的融合等
這個最難也是被研究最多的領域,比如音節和唇語頭像怎么融合,本筆記主要寫融合方式
二. 應用
試聽語音識別,多媒體內容檢索,視頻理解,視頻總結,事件監測,情感分析,視頻會議情感分析,媒體描述,視覺問答等,應用其實很廣,只不過被現在的智能程度大大限制了,whatever, 我覺得視覺也語言的結合比純NLP,是離智能更近的一步。
三.VQA掃盲 and 常用方式
VQA(Visual Question Answering)
給定一張圖片(視頻)和一個與該圖片相關的自然語言問題,計算機能產生一個正確的回答。這是文本QA和Image Captioning的結合,一般會涉及到圖像內容上的推理,看起來更炫酷(不是指邏輯,就就指直觀感受)。
目前VQA的四大方式
Joint embedding approaches,只是直接從源頭編碼的角度開始融合信息,這也很自然的聯想到最簡單粗暴的方式就是把文本和圖像的embedding直接拼接(ps:粗暴拼接這種方式很work),Billiner Fusion 最常用了,Fusion屆的LR
Attention mechanisms,很多VQA的問題都在attention上做文章,attention本身也是一個提取信息的動作,自從attention is all you need后,大家對attention的應用可以說是花式了,本文后面專門介紹CVPR2019的幾篇
Compositional Models,這種方式解決問題的思路是分模塊而治之,各模塊分別處理不同的功能,然后通過模塊的組裝推理得出結果
比如在[1]中,上圖,問題是What color is his tie?先選擇出 attend 和classify 模塊,并且根據推理方式組裝模塊,最后得出結論 4.Models using external knowledge base利用外部知識庫來做VQA和很好理解,QA都喜歡用知識庫,這種知識儲備一勞永逸,例如,為了回答“圖上有多少只哺乳動物”這樣的問題,模型必須得知道“哺乳動物”的定義,而你想從圖像上去學習到哺乳動物是有難度的,因此把知識庫接進來檢索是種解決方式,例如在[2]
四. 多模態中CV和NLP融合的幾種方式
1. Bilinear Fusion 雙線性融合 and Joint embedding Bilinear Fusion 雙線性融合是最常見的一種融合方式了,很多論文用這種方式做基礎結構,在CVPR2019一遍VQA多模態推理[3]中,提出的CELL就是基于這個,作者做關系推理,不僅對問題與圖片區域的交互關系建模,也對圖片區域間的聯系建模。并且推導過程是逐步逼近的過程。
作者提出的MuRel,Bilinear Fusion 將每個圖像區域特征都分別與問題文本特征融合得到多模態embedding(Joint embedding ),后者對這些embedding進行成對的關系建模。
第一部分雙線性融合,所謂雙線性簡單來講就是函數對于兩個變量都是線性的,參數(表達兩種信息關聯)是個多為矩陣,作者采用的MUTAN模型里面的Tucker decomposition方法, 將線性關系的參數分解大大減小參數量 第二部分Pairwise relation學習的是經過融合后節點之間的兩兩關系(主要是圖像的關系),然后和原始text 信息有效(粗暴)拼接 最后如下圖放在網絡,進行迭代推理。實驗結果顯示在跟位置推斷類的問題中,這種結構表現比較好。
2. 花式動態attention融合 這篇[4]作者更上篇一樣同時注意到了模態內和模態間的關系,即作者說的intra-modality relation(模態內部關系)和inter-modality relation(跨模態關系),但是作者更機智(個人觀點)的用了attention來做各種fusion。 作者認為intra-modality relation是對inter-modality relation的補充:圖像區域不應該僅獲得來自問題文本的信息,而且需要與其他圖像區域產生關聯。 模型結構是首先各自分別對圖像和文本提取特征,然后通過通過模態內部的attention建模和模態間的attention建模,這個模塊堆疊多次,最后拼接后進行分類。模態間的attention是相互的(文本對圖像,圖像對文本),attention就是采用transform中的attention.
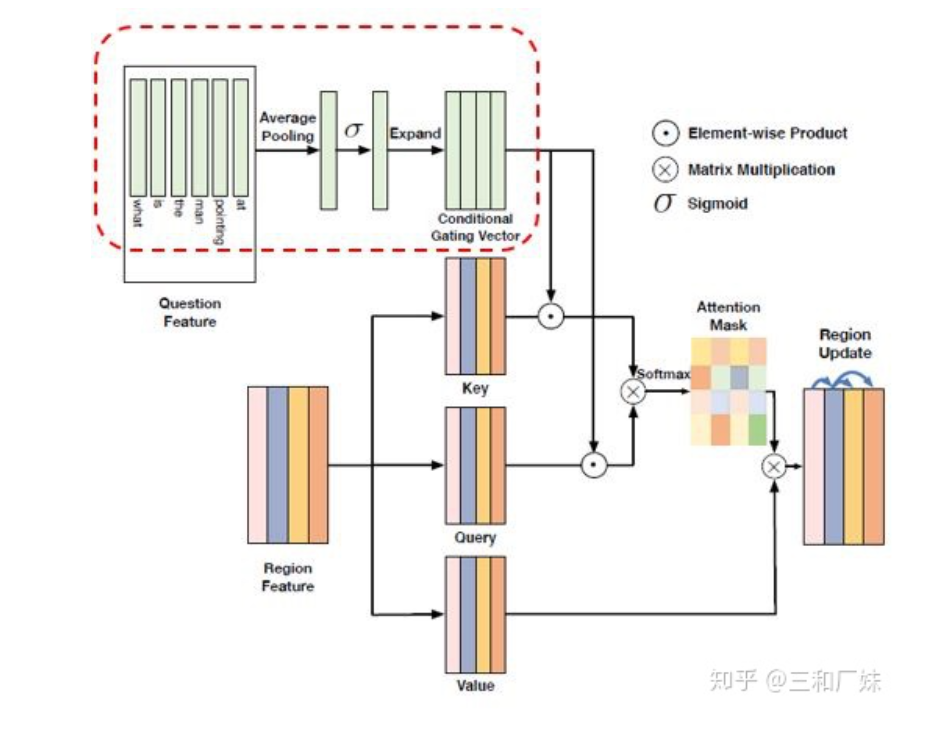
進行模態內關系建模的模塊是Dynamic Intra-modality Attention Flow (DyIntraMAF), 文中最大的亮點是進行了 條件attention,即圖像之間的attention信心建立不應該只根據圖像,也要根據不同的具體問題而產生不同的關聯。
這種條件attention的condition設計有點類似lstm的門機制,通過加入gating機制來控制信息,下圖中圖像的self attention 就是經過了text的門機制來過濾信息。最后作者做了很多ablation studies,達到了SOTA效果。
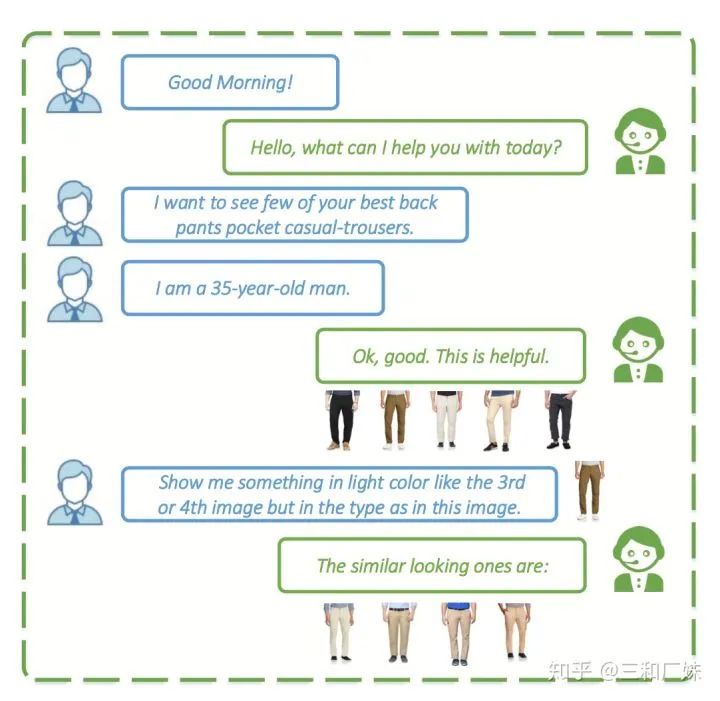
3. VQA對話系統 另外有一篇[5]個多模態的QA,這篇文章fusion 挺普通的multimodal fusion 也是普通的 billinear, 但是這個應用場景非常非常實用,我們通常用語言描述的說不清楚的時候,會有一圖勝千言語感覺,而多模態就是從這個點出發,發一張圖,like this, like that... 文中就是用這個做商業客服的QA
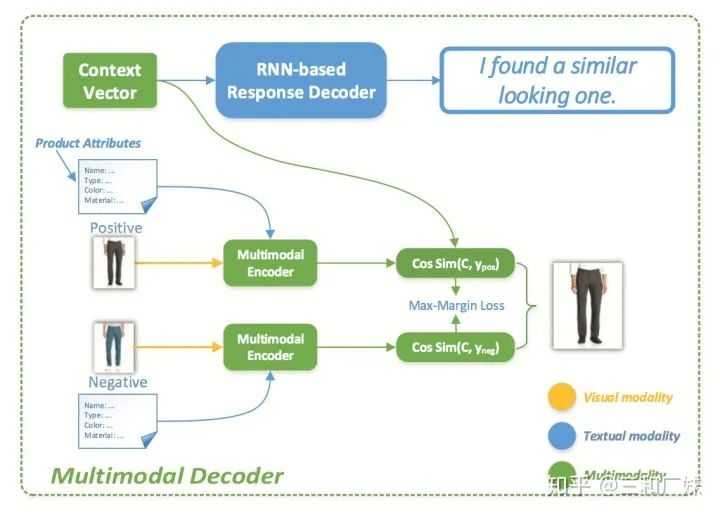
模型比較常規,encoder端,先CNN提取了圖片特征,然后根據商品屬性建一個屬性分類樹,文本常規處理,最后通過MFB融合
Decoder 時,文本RNNdecode, 但是圖像居然是用求cos相似,就電商那種產品數據的量級,除非在業務上做很多前置工作,這種計算量就不現實
In all
這篇屬于擴展NLP的廣度,寫的不深,選的論文和很隨便(因為我不很了解),作為一個NLPer, 寬度上來說我覺得這也是一個方向.
原文標題:多模態中NLP與CV融合的一些方式
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
深度學習
+關注
關注
73文章
5599瀏覽量
124396 -
MLP
+關注
關注
0文章
57瀏覽量
4989
原文標題:多模態中NLP與CV融合的一些方式
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
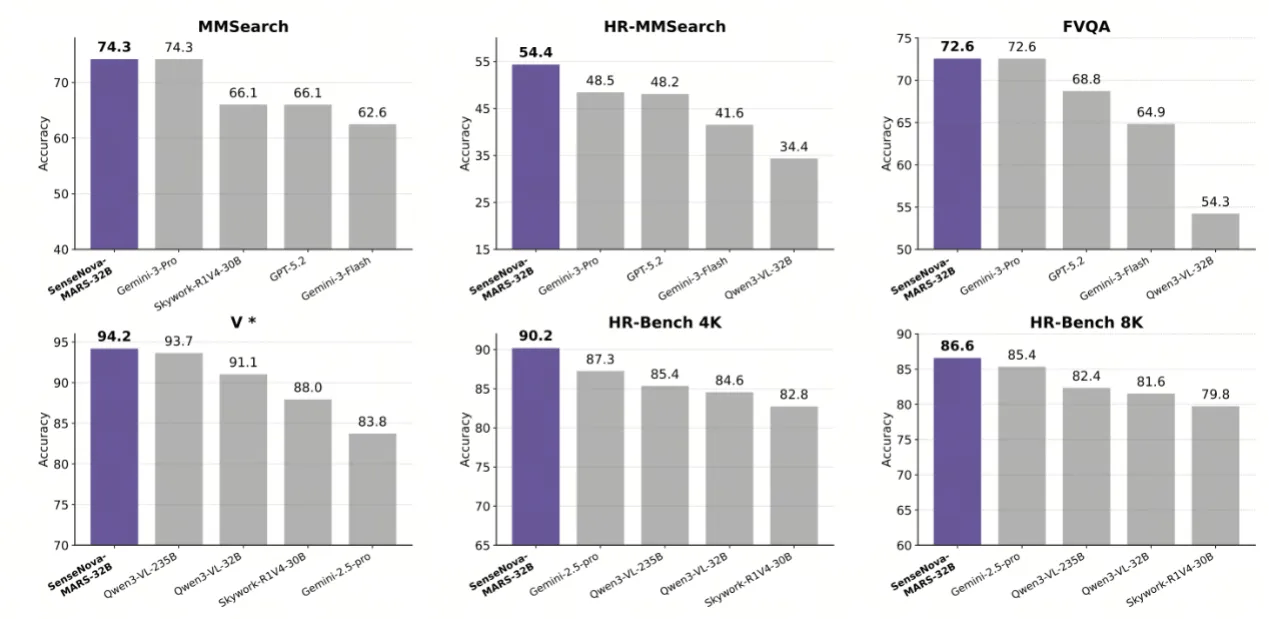
商湯開源SenseNova-MARS:突破多模態搜索推理天花板
多模態感知大模型驅動的密閉空間自主勘探系統的應用與未來發展
亞馬遜云科技上線Amazon Nova多模態嵌入模型

米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
NVIDIA助力圖靈新訊美推出企業級多模態視覺大模型融合解決方案

商湯日日新SenseNova融合模態大模型 國內首家獲得最高評級的大模型
Android Studio中的Gemini支持多模態輸入功能
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

海康威視發布多模態大模型AI融合巡檢超腦
移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗

移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗




 工商網監
工商網監
評論