 視頻去模糊-STFAN, 達到速度,精度和模型大小同步考慮的SOTA性能
視頻去模糊-STFAN, 達到速度,精度和模型大小同步考慮的SOTA性能

該文是商湯研究院、南京科技以及哈工大聯合提出的一種采用動態濾波器卷積進行視頻去模糊的方法。由于相機抖動、目標運動以及景深變化會導致視頻中存在spatially variant blur現象。現有的去模糊方法通常在模糊視頻中估計光流進行對齊。這種方法會因光流估計的不夠精確導致生成的視頻存在偽影,或無法有效去除模糊。為克服光流估計的局限性,作者提出了一種的STFAN框架(同時進行對齊和去模糊)。它采用了類似FRVSR的思路進行視頻去模糊(它前一幀的模糊以及去模糊圖像聯合當前幀模糊圖像作為輸出,經CNN后輸出當前幀去模糊圖像),其CNN架構采用了空間自使用濾波器進行對齊與去模糊。
作者提出一種新的FAC操作進行對齊,然后從當前幀移除空間可變模糊。最后,作者設計了一個重建網絡用于復原清晰的圖像。
作者在合成數據與真實數據進行了量化對比分析,所提方法取得了SOTA性能(同時考慮了精度、速度以及模型大小)。
文章作者: Happy
Abstract
論文將視頻去模糊中的近鄰幀對齊與非均勻模糊移除問題建模為element-wise filter adaptive convolution processes。論文的創新點包含:
- 提出一個濾波器自適應卷積計算單元,它用于特征域的對齊與去模糊;
- 提出一個新穎的STFAN用于視頻去模糊,它集成幀對齊、去模糊到同一個框架中,而無需明顯的運動估計;
- 從精度、速度以及模型大小方面對所提方法進行了量化評估,取得了SOTA性能。
Method
?上圖給出了文中所用到的網絡架構示意圖。從中可以看出,它包含三個子模塊:特征提取、STFAN以及重建模塊。它的輸入包含三個圖像(前一幀模糊圖像,前一幀去模糊圖像以及當前幀模糊圖像),由STFAN生成對齊濾波器與去模糊濾波器,然后采用FAC操作進行特征對齊與模糊移除。最后采用重建模塊進行清晰圖像生成。
FAC
?關于如何進行代碼實現,見文末,這里就不再進行更多的介紹。
網絡架構
?如前所述,該網絡架構包含三個模塊,這里將分別針對三個子模塊進行簡單的介紹。
- 特征提取網絡。該模塊用于從模糊圖像$B_t$中提取特征$E_t$,它由三個卷積模塊構成,每個卷積模塊包含一個stride=2的卷積以及兩個殘差模塊(激活函數選擇LeakyReLU)。這里所提取的特征被送入到STFAN模塊中采用FAC操作進行去模糊。該網絡的配置參數如下:
注:上述兩個濾波器生成模塊均包含一個卷積和兩個殘差模塊并后接一個1x1卷積用于得到期望的輸出通道。基于所得到的兩組濾波器,采用FAC對前一幀的去模糊特征與當前幀的幀特征進行對齊,同時在特征層面進行模糊移除。最后,將兩者進行拼接送入到重建模塊中。該模塊的配置參數如下:
- 重建模塊。該模塊以STFAN中的融合特征作為輸入,輸出清晰的去模糊圖像。該模塊的配置參數如下所示。
損失函數
?為更有效的訓練所提網絡,作者考慮如下兩種損失函數:
- MSE Loss。它用于度量去模糊圖像R與真實圖像S之間的差異。
- Perceptional Loss。它用于度量去模糊圖像R與真實圖像S在特征層面的相似性。
總體的損失定義為:
$$ L_{deblur} = L_{mse} + 0.01 * L_{perceptual}$$
Experiments
Dataset
?訓練數據源自《Deep video deblurring for hand-held camars》,它包含71個視頻(6708對數據),被劃分為61用于訓練(5708對數據),10個用于測試(1000對數據)。
?在數據增廣方面,作者將每個視頻劃分為長度為20的序列。
?為增廣運動的多樣性,對序列數據進行隨機逆序。對每個序列數據,執行相同的圖像變換(包含亮度、對比度調整(從[0.8, 1.2]范圍內均勻采樣))、幾何變換(包含隨機水平/垂直鏡像)以及裁剪。
?為提升模塊在真實場景的魯棒性,對序列圖像添加了高斯(N(0, 0.01))隨機噪聲。
Training Settings
?整個網絡采用kaiming方式進行初始化,采用Adam優化器( [公式] ),初始學習率設為1e-4,每400k迭代乘以0.1。總計迭代次數為900k。
Results
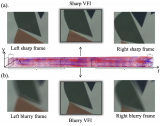
?下面兩圖給出了不同去模糊方法的量化對比以及視覺效果對比。更多實驗結果以及相關分析請查閱原文。
小結
?本文提出一種新穎的基于動態濾波器卷積的時空網絡用于視頻去模塊。該網路可以動態的生成用于對齊與去模糊的濾波器。基于所生成濾波器以及FAC單元,該網絡可以執行時序對齊與特征去模糊。這種無明顯運動估計的方法使得它可以處理動態場景中的空間可變的模塊現象。
結合論文所提供的網絡架構,以及論文附加文檔中所提供的相關參數,簡單的整理代碼如下:了精度、速度以及模型大小)。
參考代碼
結合論文所提供的網絡架構,以及論文附加文檔中所提供的相關參數,參考代碼如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 論文中各個模塊中設計的殘差模塊(文中未提到是否有BN層,因此這里未添加BN)。
class ResBlock(nn.Module):
def __init__(self, inc):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(inc, inc, 3, 1, 1)
self.lrelu = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(inc, inc, 3, 1, 1)
def forward(self, x):
res = self.conv2(self.lrelu(self.conv1(x)))
return res + x
# 特征提取模塊
class FeatureExtract(nn.Module):
def __init__(self):
super(FeatureExtract, self).__init__()
self.net = nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1),
ResBlock(32),
ResBlock(32),
nn.Conv2d(32, 64, 3, 2, 1),
ResBlock(64),
ResBlock(64),
nn.Conv2d(64, 128, 3, 2, 1),
ResBlock(128),
ResBlock(128))
def forward(self, x):
return self.net(x)
# 重建模塊
# (注:ConvTranspose的參數參考附件文檔設置,pad參數是估計所得,只有這組參數能夠滿足論文的相關特征之間的尺寸關系,如有問題,請反饋更新)
class ReconBlock(nn.Module):
def __init__(self):
super(ReconBlock, self).__init__()
self.up1 = nn.ConvTranspose2d(256, 64, 4, 2, 1)
self.res2 = ResBlock(64)
self.res3 = ResBlock(64)
self.up4 = nn.ConvTranspose2d(64, 32, 3, 2, 1)
self.res5 = ResBlock(32)
self.res6 = ResBlock(32)
self.conv7 = nn.Conv2d(32, 3, 3, 1, 1)
def forward(self, feat, inputs):
N, C, H, W = feat.size()
up1 = self.up1(feat, output_size=(H * 2, W * 2))
res2 = self.res2(up1)
res3 = self.res3(res2)
up4 = self.up4(res3, output_size=(H * 4, W * 4))
res5 = self.res5(up4)
res6 = self.res6(res5)
conv7 = self.conv7(res6)
return conv7 + inputs
# FAC(以下代碼源自本人博客[動態濾波器卷積在CV中的應用]中的相關分析)
def unfold_and_permute(tensor, kernel, stride=1, pad=-1):
if pad < 0:
pad = (kernel - 1) // 2
tensor = F.pad(tensor, (pad, pad, pad, pad))
tensor = tensor.unfold(2, kernel, stride)
tensor = tensor.unfold(3, kernel, stride)
N, C, H, W, _, _ = tensor.size()
tensor = tensor.reshape(N, C, H, W, -1)
tensor = tensor.permute(0, 2, 3, 1, 4)
return tensor
def weight_permute_reshape(tensor, F, S2):
N, C, H, W = tensor.size()
tensor = tensor.permute(0, 2, 3, 1)
tensor = tensor.reshape(N, H, W, F, S2)
return tensor
# Filter_adaptive_convolution
def FAC(feat, filters, kernel_size):
N, C, H, W = feat.size()
pad = (kernel_size - 1) // 2
feat = unfold_and_permute(feat, kernel_size, 1, pad)
weight = weight_permute_reshape(filters, C, kernel_size**2)
output = feat * weight
output = output.sum(-1)
output = output.permute(0,3,1,2)
return output
# Architecture
class STFAN(nn.Module):
def __init__(self, kernel_size=5):
super(STFAN, self).__init__()
filters = 128 * kernel_size ** 2
self.ext = nn.Sequential(nn.Conv2d(9,32,3,1,1),
ResBlock(32),
ResBlock(32),
nn.Conv2d(32,64,3,2,1),
ResBlock(64),
ResBlock(64),
nn.Conv2d(64,128,3,2,1),
ResBlock(128),
ResBlock(128))
self.align = nn.Sequential(nn.Conv2d(128,128,3,1,1),
ResBlock(128),
ResBlock(128),
nn.Conv2d(128, filters, 1))
self.deblur1 = nn.Conv2d(filters, 128, 1, 1)
self.deblur2 = nn.Sequential(nn.Conv2d(256,128,3,1,1),
ResBlock(128),
ResBlock(128),
nn.Conv2d(128, filters, 1))
self.conv22 = nn.Conv2d(256, 128, 3, 1, 1)
def forward(self, pre, cur, dpre):
ext = self.ext(torch.cat([dpre, pre, cur], dim=1))
align = self.align(ext)
d1 = self.deblur1(align)
deblur = self.deblur2(torch.cat([ext, d1], dim=1))
return align, deblur
class Net(nn.Module):
def __init__(self, kernel_size=5):
super(Net, self).__init__()
self.kernel_size = kernel_size
self.feat = FeatureExtract()
self.stfan = STFAN()
self.fusion = nn.Conv2d(256, 128, 3, 1, 1)
self.recon = ReconBlock()
def forward(self, pre, cur, dpre, fpre):
# Feature Extract.
feat = self.feat(cur)
# STFAN
align, deblur = self.stfan(pre, cur, dpre)
# Align and Deblur
falign = FAC(fpre, align, self.kernel_size)
fdeblur = FAC(feat, deblur, self.kernel_size)
fusion = torch.cat([falign, fdeblur], dim=1)
# fpre for next
fpre = self.fusion(fusion)
# Reconstruction
out = self.recon(fusion, cur)
return out, fpre
def demo():
pre = torch.randn(4, 3, 64, 64)
cur = torch.randn(4, 3, 64, 64)
dpre = torch.randn(4, 3, 64, 64)
fpre = torch.randn(4, 128, 16, 16)
model = Net()
model.eval()
with torch.no_grad():
output = model(pre, cur, dpre, fpre)
print(output[0].size())
print(output[1].size())
if __name__ == "__main__":
demo()
本文章著作權歸作者所有,任何形式的轉載都請注明出處。更多動態濾波,圖像質量,超分辨相關請關注我的專欄深度學習從入門到精通。
-
人工智能
+關注
關注
1817文章
50095瀏覽量
265306 -
機器學習
+關注
關注
66文章
8553瀏覽量
136934
發布評論請先 登錄
LMH1981多格式視頻同步分離器:高性能視頻應用的理想之選
超高精度 MEMS 加速度計:極致性能的微型傳感新標桿
同步帶模組如何破解激光加工速度與精度?

AURIX tc367通過 MCU SOTA 更新邏輯 IC 閃存是否可行?
基于模糊自適應PID控制的永磁同步電機伺服系統研究
含轉矩閉環的異步電機微分先行PID雙模糊自整定矢量控制系統
無刷直流電機自適應模糊PID控制系統
無刷直流電機模糊自適應PID控制的研究
無刷直流電機模糊自適應PID的研究及仿真
無刷直流電機模糊PI控制系統建模與仿真
無模型自適應控制在永磁同步電機轉速中的仿真研究
改進粒子群算法的永磁同步電機PID控制器
永磁同步電機自適應高階滑模Type-2模糊控制
永磁同步電機(PMSM)調速系統的智能控制算法研究
基于事件相機的統一幀插值與自適應去模糊框架(REFID)



 工商網監
工商網監
評論