 DPDK內存的基本概念
DPDK內存的基本概念

作者簡介:Anatoly Burakov,英特爾軟件工程師,
目前在維護DPDK中的VFIO和內存子系統
引言
內存管理是數據面開發套件(DPDK)的一個核心部分,以此為基礎,DPDK的其他部分和用戶應用得以發揮其最佳性能。本系列文章將詳細介紹DPDK提供的各種內存管理的功能。
但在此之前,有必要先談一談為何DPDK中內存管理要以現有的方式運作,它背后又有怎樣的原理,再進一步探討DPDK具體能夠提供哪些與內存相關的功能。本文將先介紹DPDK內存的基本原理,并解釋它們是如何幫助DPDK實現高性能的。
請注意,雖然DPDK支持FreeBSD,而且也會有正在運行的Windows端口,但目前大多數與內存相關的功能僅適用于Linux*。
標準大頁
現代CPU架構中,內存管理并不以單個字節進行,而是以頁為單位,即虛擬和物理連續的內存塊。這些內存塊通常(但不是必須) 存儲在RAM中。在英特爾64和IA-32架構上,標準系統的頁面大小為4KB。
基于安全性和通用性的考慮,軟件的應用程序訪問的內存位置使用的是操作系統分配的虛擬地址。運行代碼時,該虛擬地址需要被轉換為硬件使用的物理地址。這種轉換是操作系統通過頁表轉換來完成的,頁表在分頁粒度級別上(即4KB一個粒度)將虛擬地址映射到物理地址。為了提高性能,最近一次使用的若干頁面地址被保存在一個稱為轉換檢測緩沖區(TLB)的高速緩存中。每一分頁都占有TLB的一個條目。如果用戶的代碼訪問(或最近訪問過)16 KB的內存,即4頁,這些頁面很有可能會在TLB緩存中。
如果其中一個頁面不在TLB緩存中,嘗試訪問該頁面中包含的地址將導致TLB查詢失敗;也就是說,操作系統寫入TLB的頁地址必須是在它的全局頁表中進行查詢操作獲取的。因此,TLB查詢失敗的代價也相對較高(某些情況下代價會非常高),所以最好將當前活動的所有頁面都置于TLB中以盡可能減少TLB查詢失敗。
然而,TLB的大小有限,而且實際上非常小,和DPDK通常處理的數據量(有時高達幾十GB)比起來,在任一給定的時刻,4KB 標準頁面大小的TLB所覆蓋的內存量(幾MB)微不足道。這意味著,如果DPDK采用常規內存,使用DPDK的應用會因為TLB頻繁的查詢失敗在性能上大打折扣。
為解決這個問題,DPDK依賴于標準大頁。從名字中很容易猜到,標準大頁類似于普通的頁面,只是會更大。有多大呢?在英特爾64和1A-32架構上,目前可用的兩種大頁大小為2MB和1GB。也就是說,單個頁面可以覆蓋2 MB或1 GB大小的整個物理和虛擬連續的存儲區域。
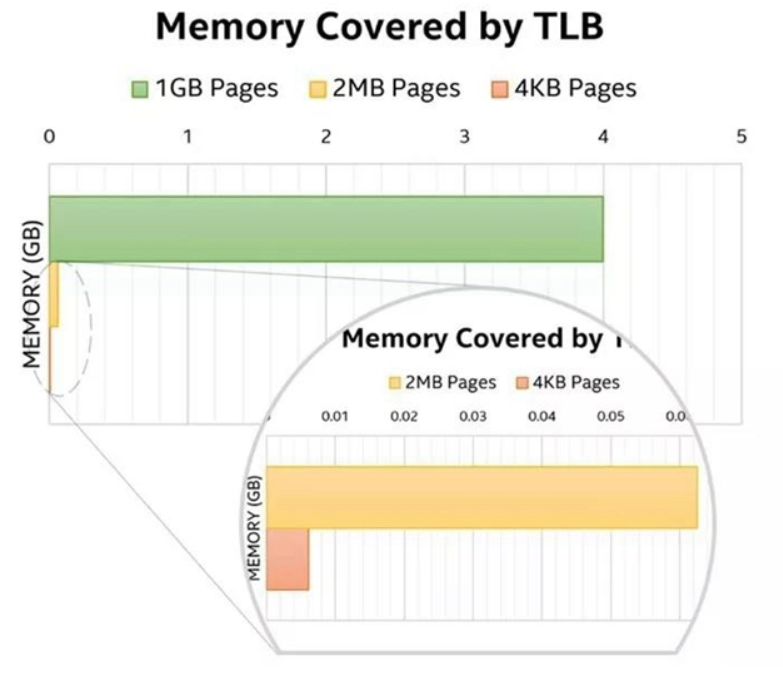
圖1. TLB內存覆蓋量比較
這兩種頁面大小DPDK都可以支持。有了這樣的頁面大小,就可以更容易覆蓋大內存區域,也同時避免(同樣多的)TLB查詢失敗。反過來,在處理大內存區域時,更少的TLB查詢失敗也會使性能得到提升,DPDK的用例通常如此。
將內存固定到NUMA節點
當分配常規內存時,理論上,它可以被分配到RAM中的任何位置。這在單CPU系統上沒有什么問題,但是許多DPDK用戶是在支持非統一內存訪問 (NUMA) 的多CPU系統上運行應用的。對于NUMA來說,所有內存都是不同的:某一個CPU對一些內存的訪問(如不在該CPU所屬NUMA NODE上的內存)將比其他內存訪問花費更長的時間,這是由于它們相對于執行所述內存訪問的CPU所在的物理位置不同。進行常規內存分配時,通常無法控制該內存分配到哪里,因此如果DPDK在這樣的系統上使用常規內存,就可能會導致以下的情況:在一個CPU上執行的線程卻在無意中訪問屬于非本地NUMA節點的內存。
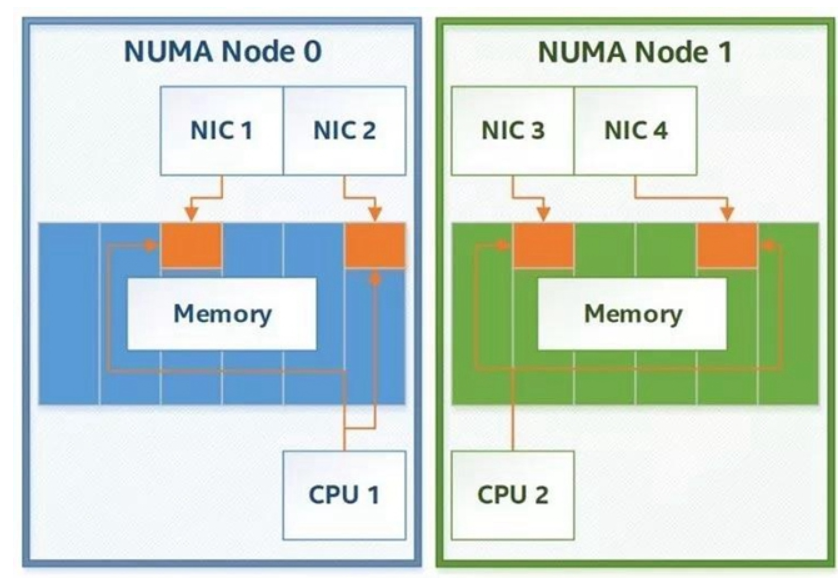
圖2. 理想的NUMA節點分配
雖然這種跨NUMA節點訪問在所有現代操作系統上都比較少有,因為這樣的訪問都是都是NUMA感知的,而且即使沒有DPDK還是有方法能對內存實施NUMA定位。但是DPDK帶來的不僅僅是NUMA感知,事實上,整個DPDK API的構建都旨在為每個操作提供明確的NUMA感知。如果不明確請求NUMA節點訪問(其中所述結構必須位于內存中),通常無法分配給定的DPDK數據結構。
DPDK API提供的這種明確的NUMA感知有助于確保用戶應用在每個操作中都能考慮到NUMA感知;換句話說,DPDK API可以減少寫出編寫性能差的代碼的可能性。
硬件、物理地址和直接內存存取(DMA)
DPDK被認為是一組用戶態的網絡包輸入/輸出庫,到目前為止,它基本上保持了最初的任務聲明。但是,電腦上的硬件不能處理用戶空間的虛擬地址,因為它不能感知任何用戶態的進程和其所分配到的用戶空間虛擬地址。相反,它只能訪問真實的物理地址上的內存,也就是CPU、RAM和系統所有其他的部分用來相互通信的地址。
出于對效率的考量,現代硬件幾乎總是使用直接內存存取(DMA)事務。通常,為了執行一個DMA事務,內核需要參與創建一個支持DMA的存儲區域,將進程內虛擬地址轉換成硬件能夠理解的真實物理地址,并啟動DMA事務。這是大多數現代操作系統中輸入輸出的工作方式;然而,這是一個耗時的過程,需要上下文切換、轉換和查找操作,這不利于高性能輸入/輸出。
DPDK的內存管理以一種簡單的方式解決了這個問題。每當一個內存區域可供DPDK使用時,DPDK就通過詢問內核來計算它的物理地址。由于DPDK使用鎖定內存,通常以大頁的形式,底層內存區域的物理地址預計不會改變,因此硬件可以依賴這些物理地址始終有效,即使內存本身有一段時間沒有使用。然后,DPDK會在準備由硬件完成的輸入/輸出事務時使用這些物理地址,并以允許硬件自己啟動DMA事務的方式配置硬件。這使DPDK避免不必要的開銷,并且完全從用戶空間執行輸入/輸出。
IOMMU和IOVA
默認情況下,任何硬件都可以訪問整個系統,因此它可以在任何地方執行DMA 事務。這有許多安全隱患。例如,流氓和/或不可信進程(包括在VM (虛擬機)內運行的進程)可能使用硬件設備來讀寫內核空間,和幾乎其他任何存儲位置。為了解決這個問題,現代系統配備了輸入輸出內存管理單元(IOMMU)。這是一種硬件設備,提供DMA地址轉換和設備隔離功能,因此只允許特定設備執行進出特定內存區域(由IOMMU指定)的DMA 事務,而不能訪問系統內存地址空間的其余部分。
由于IOMMU的參與,硬件使用的物理地址可能不是真實的物理地址,而是IOMMU分配給硬件的(完全任意的)輸入輸出虛擬地址(IOVA)。一般來說,DPDK社區可以互換使用物理地址和IOVA這兩個術語,但是根據上下文,這兩者之間的區別可能很重要。例如,DPDK 17.11和更新的DPDK長期支持(LTS)版本在某些情況下可能根本不使用實際的物理地址,而是使用用戶空間虛擬地址(甚至完全任意的地址)來實現DMA。IOMMU負責地址轉換,因此硬件永遠不會注意到兩者之間的差異。
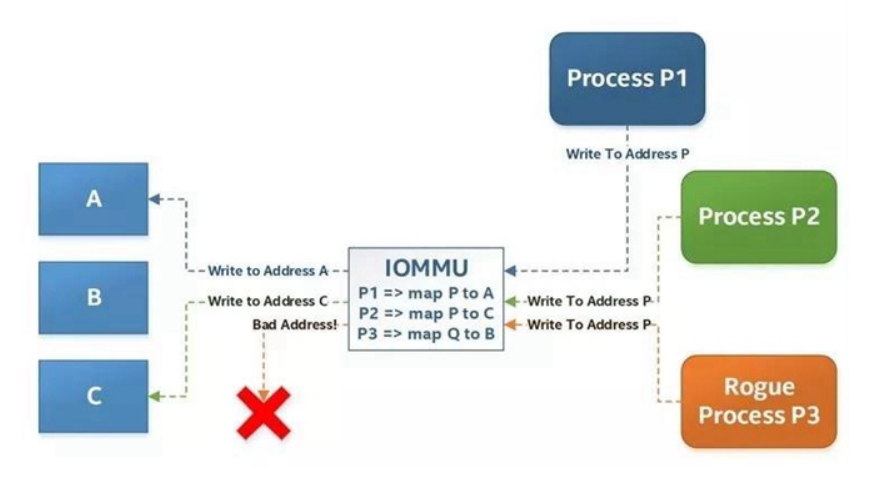
圖3 .IOMMU將物理地址重新映射到IOVA地址的示例
根據DPDK的初始化方式,IOVA地址可能代表也可能不代表實際的物理地址,但有一點始終是正確的:DPDK知道底層內存布局,因此可以利用這一點。例如,它可以以創建IOVA連續虛擬區域的方式映射頁面,或者甚至利用IOMMU來重新排列內存映射,以使內存看起來IOVA連續,即使底層物理內存可能不連續。
因此,這種對底層物理內存區域的感知是DPDK工具包中的又一個利器。大多數數據結構不關心IOVA地址,但當它們關心時,DPDK為軟件和硬件提供了利用物理內存布局的工具,并針對不同的用例進行優化。
請注意,IOMMU不會自行設置任何映射。相反,平臺、硬件和操作系統必須進行配置,來使用IOMMU。這種配置說明超出了本系列文章的范圍,但是在DPDK文檔和其他地方有相關說明。一旦系統和硬件設置為使用IOMMU,DPDK就可以使用IOMMU為DPDK分配的任何內存區域設置DMA映射。使用IOMMU是運行DPDK的推薦方法,因為這樣做更安全,并且它提供了可用性優勢。
內存分配和管理
DPDK不使用常規內存分配函數,如malloc()。相反,DPDK管理自己的內存。更具體地說,DPDK分配大頁并在此內存中創建一個堆(heap)并將其提供給用戶應用程序并用于存取應用程序內部的數據結構。
使用自定義內存分配器有許多優點。最明顯的一個是終端應用程序的性能優勢:DPDK創建應用程序要使用的內存區域,并且應用程序可以原生支持大頁、NUMA節點親和性、對DMA地址的訪問、IOVA連續性等等性能優勢,而無需任何額外的開發。
DPDK內存分配總是在CPU高速緩存行(cache line)的邊界上對齊,每個分配的起始地址將是系統高速緩存行大小的倍數。這種方法防止了許多常見的性能問題,例如未對齊的訪問和錯誤的數據共享,其中單個高速緩存行無意中包含(可能不相關的)多個內核同時訪問的數據。對于需要這種對齊的用例(例如,分配硬件環結構),也支持任何其他二次冪值 (當然> =高速緩存行大小)。
DPDK中的任何內存分配也是線程安全的。這意味著在任何CPU核心上發生的任何分配都是原子的,不會干擾任何其他分配。這可能看起來很無足輕重 (畢竟,常規glibc內存分配例程通常也是線程安全的),但是一旦在多處理環境中考慮,它的重要性就會變得更加清晰。
DPDK支持特定風格的協同多處理,其中主進程管理所有DPDK資源,多個輔助進程可以連接到主進程,并共享由主進程管理的資源的訪問。
DPDK的共享內存實現不僅通過映射不同進程中的相同資源 (類似于shmget () 機制) 來實現,還通過復制另一個進程中主進程的地址空間來實現。因此,由于兩個進程中的所有內容都位于相同的地址,指向DPDK內存對象的任何指針都將跨進程工作,無需任何地址轉換。這對于跨進程傳遞數據時的性能非常重要。
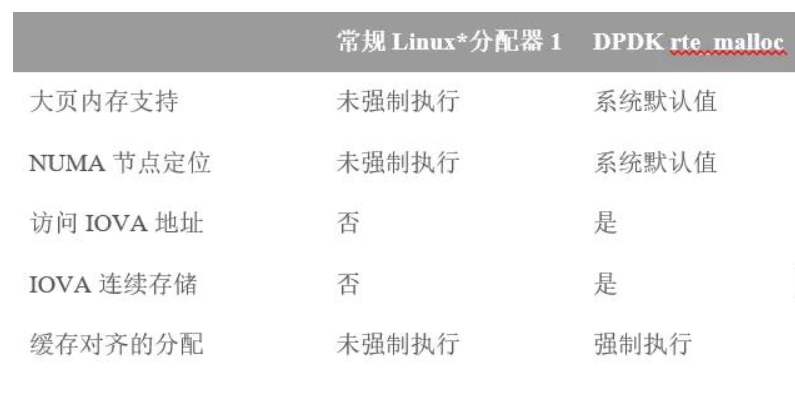
表1. 操作系統和DPDK分配器的比較
內存池
DPDK也有一個內存池管理器,在整個DPDK中廣泛用于管理大型對象池,對象大小固定。它的用途很多——包輸入/輸出、加密操作、事件調度和許多其他需要快速分配或解除分配固定大小緩沖區的用例。DPDK內存池針對性能進行了高度優化,并支持可選的線程安全(如果用戶不需要線程安全,則無需為之付費)和批量操作,所有這些都會導致每個緩沖區的分配或空閑操作周期計數達到兩位數以下。
也就是說,即使DPDK內存池的主題出現在幾乎所有關于DPDK內存管理的討論中,從技術上講,內存池管理器是一個建立在常規DPDK內存分配器之上的庫。它不是標準DPDK內存分配工具的一部分,它的內部工作與DPDK內存管理例程完全分離 (并且非常不同) 。因此,這超出了本系列文章的范圍。但是,有關DPDK內存池管理器庫的更多信息可以在DPDK文檔中找到。
結論
本文介紹了構成DPDK內存管理子系統基礎的許多核心原理,并證明了DPDK的高性能并不是偶然,而是其體系架構的必然結果。
本系列接下來的文章將深入探討IOVA尋址及其在DPDK中的使用;以歷史的視角,回顧DPDK長期支持(LTS)版本17.11及更早版本中提供的內存管理功能;同時也會介紹18.11及更高版本DPDK版本中做出的更改和提供的新功能。
文章轉載自DPDK與SPDK開源社區
原文標題:DPDK內存篇(一): 基本概念
文章出處:【微信公眾號:Linuxer】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
cpu
+關注
關注
68文章
11277瀏覽量
224949 -
內存
+關注
關注
9文章
3209瀏覽量
76357 -
DPDK
+關注
關注
0文章
14瀏覽量
1966
原文標題:DPDK內存篇(一): 基本概念
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

進程概念和特征

TVS二極管的基本概念和主要作用
USB/HID及其基本概念
eFUSE內存是如何組織的?
電壓波動與閃變的基本概念
免費分享:一個低成本8電1光+5G|+WI-FI6+ SATA3.0+DPDK融合網關方案
SiC MOSFET的基本概念
群延遲的基本概念和仿真實例分析

替代專用硬件!一文梳理開源VPP+DPDK技術和產業界應用實例



 工商網監
工商網監
評論