 探討實時機器學習的概念及其應用現狀
探討實時機器學習的概念及其應用現狀

實時機器學習正得到越來越廣泛的應用和部署。近日,計算機科學家和 AI 領域科技作家 Chip Huyen 在其博客中總結了實時機器學習的概念及其應用現狀,并對比了實時機器學習在中美兩國的不同發展現狀。
與美國、歐洲和中國一些大型互聯網公司的機器學習和基礎設施工程師聊過之后,我發現這些公司可以分為兩大類。一類公司重視實時機器學習的基礎設施投資(數億美元),并且已經看到了投資回報。另一類公司則還在考慮實時機器學習是否有價值。
對于實時機器學習的含義,現在似乎還沒有明確的共識,而且也還沒有人深入探討過產業界該如何做實時機器學習。我與數十家在做實時機器學習的公司聊過之后,總結整理了這篇文章。
本文將實時機器學習分為兩個層級:
層級 1:機器學習系統能實時給出預測結果(在線預測)
層級 2:機器學習系統能實時整合新數據并更新模型(在線學習)
本文中的「模型」指機器學習模型,「系統」指圍繞模型的基礎設施,包括數據管道和監測系統。
層級 1:在線預測
這里「實時」的定義是指毫秒到秒級。
用例
延遲很重要,對于面向用戶的應用而言尤其重要。2009 年,谷歌的實驗表明:如果將網絡搜索的延遲從 100 ms 延長至 400 ms,則平均每用戶的日搜索量會降低 0.2%-0.6%。2019 年,Booking.com 發現延遲增加 30%,轉化率就會降低 0.5% 左右——該公司稱這是「對業務有重大影響的成本」。
不管你的機器學習模型有多好,如果它們給出預測結果的時間太長,就算只是毫秒級,用戶也會轉而點擊其它東西。
批量預測的問題
一個稱不上解決方案的措施是不使用在線預測。你可以用離線方法批量生成預測結果,然后將它們保存起來(比如保存到 SQL 表格中),最后在需要時拉取已有的預測結果。
當輸入空間有限時,這種方法是有效的——畢竟你完全知道有多少可能的輸入。舉個例子,如果你需要為你的用戶推薦電影。你已經知道有多少用戶,那么你可以每隔一段時間(比如每幾個小時)為每個用戶生成一組推薦。
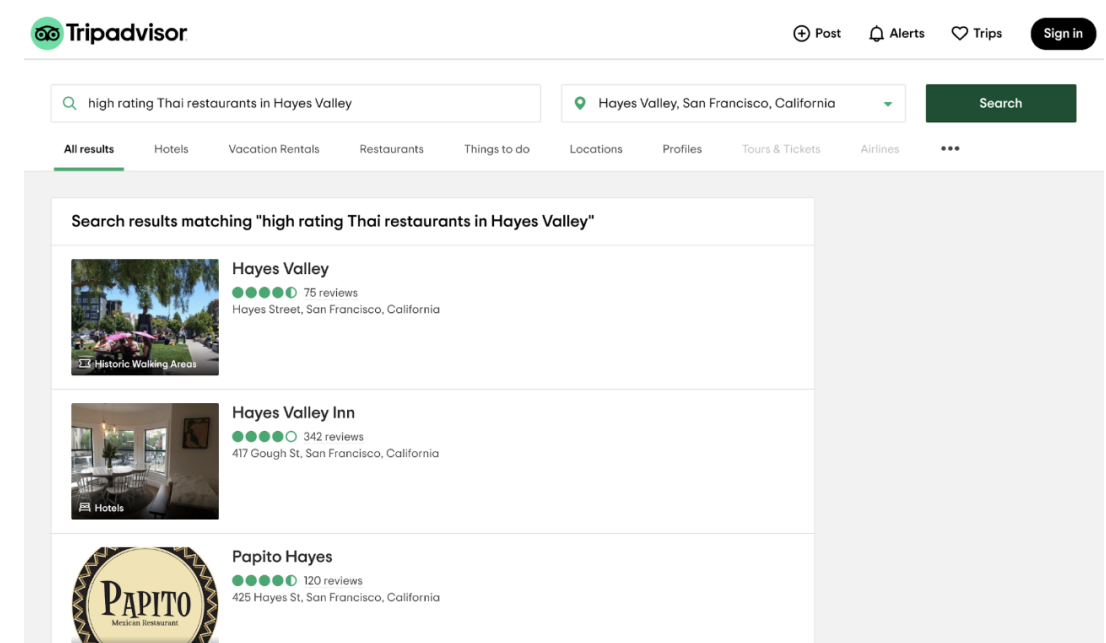
為了讓用戶輸入空間有限,很多應用采取的方法是讓用戶從已有類別中選擇,而不是讓用戶輸入查詢。例如,如果你進入旅游出行推薦網站 TripAdvisor,你必須首先選擇一個預定義的都會區,而無法直接輸入任何位置。
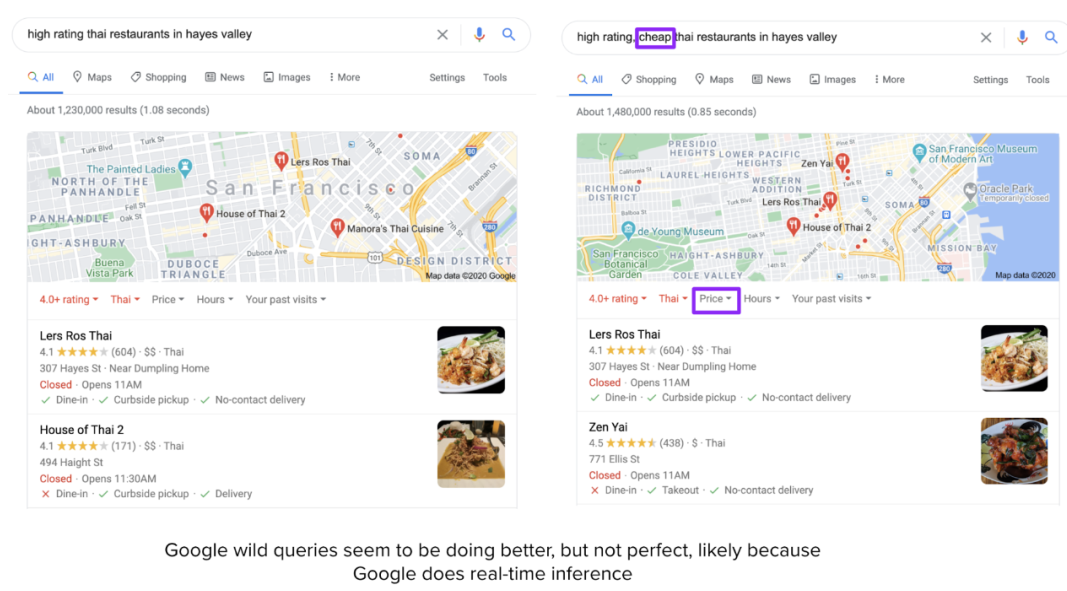
這種方法存在很多局限性。TripAdvisor 在其預定義的類別內表現還算可以,比如「舊金山」的「餐廳」,但如果你想自己輸入「Hayes Valley 的高分泰式餐廳」這樣的查詢,那么結果會相當差。
甚至很多技術較為激進的公司也會使用批量預測,并由此顯現出其局限性,比如 Netflix。如果你最近看了很多恐怖片,那么當你再次登錄 Netflix 時,推薦電影中大部分會是恐怖片。但如果你今天心情愉悅,搜索了「喜劇」開始瀏覽喜劇類別,那么 Netflix 應該學習并在推薦列表中展示更多喜劇吧?然而,它在生成下一個批量推薦列表之前并不會更新當前列表。
在上面的兩個例子中,批量預測會降低用戶體驗(這與用戶參與和用戶留存緊密相關),但不會導致災難性的后果。其它這類例子還有廣告排序、Twitter 的熱門趨勢標簽排序、Facebook 的新聞訂閱排序、到達時間估計等等。
還有一些應用,如果沒有在線預測會出現災難性的后果,甚至變得毫無作用,比如高頻交易、自動駕駛汽車、語音助手、手機的人臉 / 指紋解鎖、老年人跌倒檢測、欺詐檢測等。雖然在欺詐交易發生 3 小時后檢測到比檢測不到要好一些,但如果能實時檢測到欺詐,就可以直接防止其發生了。
如果將批量預測換成實時預測,我們就可以使用動態特征來得到更相關的預測結果。靜態特征是變化緩慢或不變化的信息,比如年齡、性別、工作、鄰居等。動態特征是基于當前狀況的特征,比如你正在看什么節目、剛剛給什么內容點了贊等。如果能知曉用戶現在對什么感興趣,那么系統就能給出更加相關的推薦。
解決方案
要讓系統具備在線預測能力,它必須要用兩個組件:
快速推理:模型要能在毫秒級時間內給出預測結果;
實時數據管道:能夠實時處理數據、將其輸入模型和返回預測結果的流程管道。
1. 快速推理
當模型太大或預測時間太長時,可采用的方法有三種:
讓模型更快(推理優化)
比如聚合運算、分散運算、內存占用優化、針對具體硬件編寫高性能核等。
讓模型更小(模型壓縮)
起初,這類技術是為了讓模型適用于邊緣設備,讓模型更小通常能使其運行速度更快。最常見的模型壓縮技術是量化(quantization),比如在表示模型的權重時,使用 16 位浮點數(半精度)或 8 位整型數(定點數),而不是使用 32 位浮點數(全精度)。在極端情況下,一些人還嘗試了 1 位表征(二元加權神經網絡),如 BinaryConnect 和 Xnor-net。Xnor-net 的作者創立了一家專注模型壓縮的創業公司 Xnor.ai,并已被蘋果公司以 2 億美元收購。
另一種常用的技術是知識蒸餾,即訓練一個小模型(學生模型)來模仿更大模型或集成模型(教師模型)。即使學生模型通常使用教師模型訓練得到,但它們也可能同時訓練。在生產環境中使用蒸餾網絡的一個例子是 DistilBERT,它將 BERT 模型減小了 40%,同時還保留了 BERT 模型 97% 的語言理解能力,速度卻要快 60%。
其它技術還包括剪枝(尋找對預測最無用的參數并將它們設為 0)、低秩分解(用緊湊型模塊替代過度參數化的卷積濾波器,從而減少參數數量、提升速度)。詳細分析請參閱 Cheng 等人 2017 年的論文《A Survey of Model Compression and Acceleration for Deep Neural Networks》。
模型壓縮方面的研究論文數量正在增長,可直接使用的實用程序也在迅速增多。相關的開源項目也不少,這里有一份 40 大模型壓縮開源項目列表:https://awesomeopensource.com/projects/model-compression。
讓硬件更快
這是另一個蓬勃發展的研究領域。大公司和相關創業公司正競相開發新型硬件,以使大型機器學習模型能在云端和設備端(尤其是設備)更快地推理乃至訓練。據 IDC 預測,到 2020 年,執行推理的邊緣和移動設備總數將達 37 億臺,另外還有 1.16 億臺被用于執行訓練。
2. 實時數據管道
假設你有一個駕乘共享應用并希望檢測出欺詐交易,比如使用被盜信用卡支付。當該信用卡的實際所有者發現未授權支付時,他們會向銀行投訴,你就必須退款。為了最大化利潤,欺詐者可能會連續多次叫車或使用多個賬號叫車。2019 年,商家估計欺詐交易平均占年度網絡銷售額的 27%。檢測出被盜信用卡的時間越長,你損失的錢就會越多。
為了檢測一項交易是否為欺詐交易,僅檢查交易本身是不夠的。你至少需要檢查該用戶在該交易方面的近期歷史記錄、他們在應用內的近期行程和活動、該信用卡的近期交易以及在大約同一時間發生的其它交易。
為了快速獲得這類信息,你需要盡可能地將這些信息放在內存之中。每當一件你關心的事情發生時,比如用戶選擇了一個位置、預定了一次行程、聯系了一位司機、取消了一次行程、添加了一張信用卡、移除了一張信用卡等,關于該事件的信息都要進入你的內存庫。只要這些信息還有用,它們就會一直留在內存里(通常是幾天內的事件),然后再被放入永久存儲庫(比如 S3)或被丟棄。針對該任務,最常用的工具是 Apache Kafka,此外還有 Amazon Kinesis 等替代工具。Kafka 是一種流式存儲,可在數據流動時保存數據。
流式數據不同于靜態數據,靜態數據是已完全存在于某處的數據,比如 CSV 文件。當從 CSV 文件讀取數據時,你知道該任務什么時候結束。而流式數據不會結束。
一旦你有了某種管理流式數據的方法,你需要將其中的特征提取出來,然后輸入機器學習模型中。在流式數據的特征之上,你可能還需要來自靜態數據的特征(當該賬號被創建時,該用戶的評分是多少等等)。你需要一種工具來處理流式數據和靜態數據,以及將來自多個數據源的數據組合到一起。
流式處理 vs 批處理
人們通常使用「批處理」指代靜態數據處理,因為這些數據可以分批處理。這與即到即處理的「流式處理」相反。批處理的效率很高——你可以使用 MapReduce 等工具來處理大量數據。流式處理的速度很快,因為你可以在每一份數據到達時馬上就完成處理。Apache Flink 的一位 PMC 成員 Robert Metzger 則有不同意見,他認為流式處理可以做到像批處理一樣高效,因為批處理是流式處理的一種特殊形式。
處理流數據的難度更大,因為數據量沒有限定,而且數據輸入的比率和速度也會變化。比起用批處理器來執行流式處理,使用流式處理器來執行批處理要更容易。
Apache Kafka 有一些流式處理的能力,某些公司將這些能力置于它們的 Kafka 流式存儲之上,但 Kafka 流式處理在處理不同數據源方面的能力比較有限。還有一些擴展 SQL 使其支持流數據的努力,SQL 是為靜態數據表設計的一種常用查詢語言。不過,最常用的流式處理工具還是 Apache Flink,而且它還有原生支持的批處理。
在機器學習生產應用的早期,很多公司都是在已有的 MapReduce/Spark/Hadoop 數據管道上構建自己的機器學習系統。當這些公司想做實時推理時,它們需要為流式數據構建一個單獨的數據管道。
使用兩個不同的管道來處理數據是機器學習生產過程中常見 bug 的來源,比如如果一個管道沒有正確地復制到另一個管道中,那么兩個管道可能會提取出兩組不同的特征。如果這兩個管道由不同的團隊維護,那么這會是尤其常見的問題,比如開發團隊維護用于訓練的批處理管道,而部署團隊則維護用于推理的流式處理管道。為了將 Flink 整合進批處理和流式處理流程中,包括 Uber 和微博在內的公司都對它們的基礎設施進行了重大檢修。
事件驅動型方法 vs 請求驅動型方法
過去十年,軟件世界已經進入了微服務時代。微服務的思路是將業務邏輯分解成可獨立維護的小組件——每個小組件都是一個可獨立運行的服務。每個組件的維護者都可以在不咨詢該系統其余部分的情況下快速更新和測試該組件。
微服務通常與 REST 緊密結合,這是一套可讓微服務互相通信的方法。REST API 是需求驅動型的。客戶端(服務)會通過 POST 和 GET 之類的方法向服務器發送明確的請求,然后服務器返回響應結果。為了注冊請求,服務器必須監聽請求。
因為在請求驅動的世界中,數據是根據向不同服務的請求而處理的,所以沒有一項服務了解數據如何流經整個系統的整體情況。我們來看一個包含 3 項服務的簡單系統:
A 服務管理可接單的司機
B 服務管理出行需求
C 服務預測每次展示給有需求客戶的最佳可能定價
由于價格取決于供需關系,因此服務 C 的輸出取決于服務 A 和 B 的輸出。首先,該系統需要服務之間的通信:為了執行預測,C 需要查詢 A 和 B;而 A 需要查詢 B 才能知道是否需要移動更多司機,A 還要查詢 C 以了解怎樣的定價比較合適。其次,我們沒法輕松地監控 A 或 B 的邏輯對 C 性能的影響,也沒法在 C 性能突然下降時輕松地對數據流執行映射以進行調試。
才不過三項服務,情況就已經很復雜了。想象一下,如果有成百上千項服務——就像現在的主流互聯網公司那樣,服務間的通信將多得難以實現。通過 HTTP 以 JSON blob 形式發送數據是 REST 請求的常用模式,但這種方法的速度很慢。服務間的數據傳輸可能會變成瓶頸,拖慢整個系統的速度。
如果我們不再讓 20 項服務向 A 發送請求,而是每當 A 中有事件發生時,該事件都被廣播到一個數據流中,這樣無論哪個服務需要 A 的數據,都可以訂閱該數據流,然后選擇其所需的部分?如果有一個所有服務都可以廣播事件并且訂閱的數據流呢?該模式被稱為 pub/sub:發布和訂閱。Kafka 等解決方案都支持這樣的操作。由于所有數據都會流經一個數據流,因此你可以設置一個儀表盤來監控數據及其在系統中的變化情況。因為這種架構基于服務的事件廣播,因此被稱為事件驅動型方法。
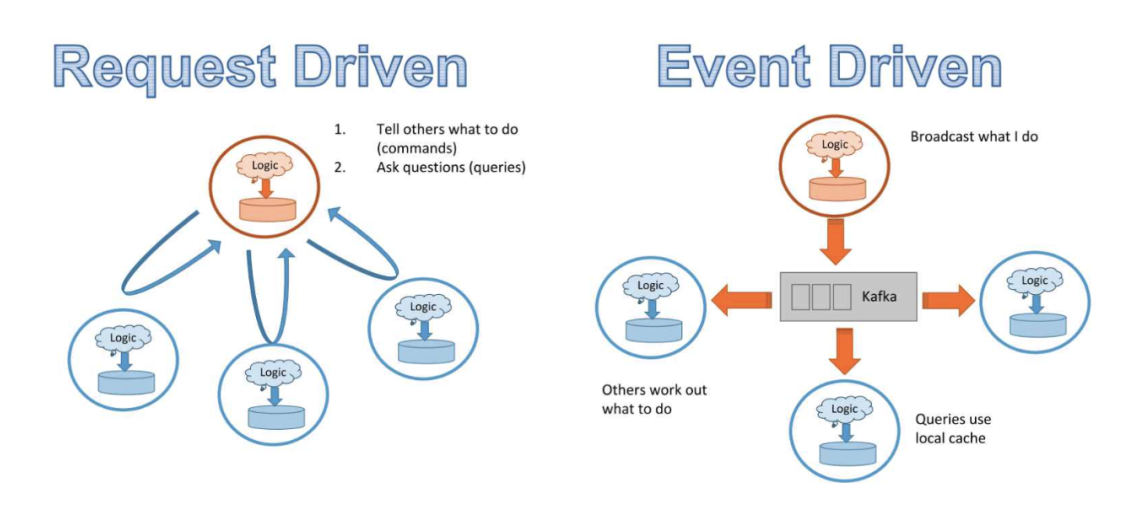
請求驅動型和事件驅動型架構對比。(圖源:https://www.infoq.com/presentations/microservices-streams-state-scalability/)
請求驅動型架構適用于更依賴邏輯而非數據的系統,事件驅動型架構則更適合數據量大的系統。
挑戰
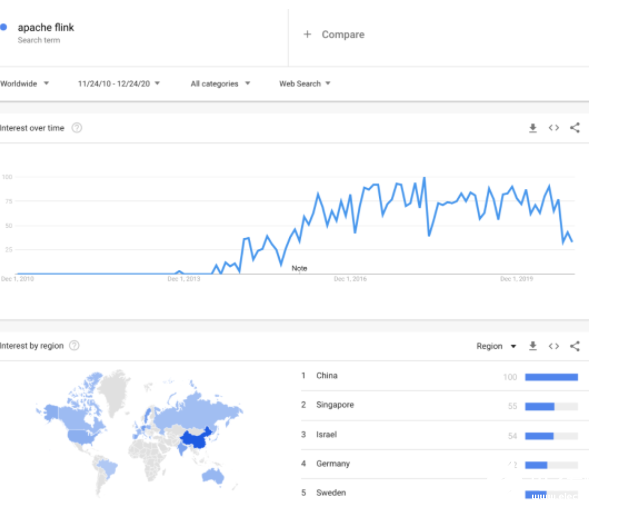
很多公司在從批處理轉向流式處理,從請求驅動型架構轉向事件驅動型架構。在與美國和中國的主要互聯網公司談過之后,我的感覺是美國這種轉變速度要慢一些,而中國的則快得多。流式架構的采用與 Kafka 和 Flink 的流行程度緊密相關。Robert Metzger 告訴我,他觀察到亞洲使用 Flink 的機器學習負載比美國的多。「Apache Flink」這個關鍵詞的谷歌搜索趨勢與這一觀察一致。
流式架構沒有更受歡迎的原因有很多:
1. 公司沒有看到流式架構的優勢。
這些公司的系統規模還沒有達到服務間通信會造成瓶頸的程度。
它們沒有能受益于在線預測的應用。
它們有能受益于在線預測的應用,但還不知道這一點,因為它們之前從未進行過在線預測。
2. 基礎設施所需的前期投資較高。
基礎設施更新的成本較高并且可能損害已有應用,管理者不愿意投資升級支持在線預測的基礎設施。
3. 思維轉換
從批處理轉向流式處理需要轉換思維。使用批處理,你知道任務會在何時完成。使用流式處理,則無法知曉。你可以制定一些規則,比如獲得之前 2 分鐘內所有數據點的平均,但如果一個發生在 2 分鐘之前的事件被延遲了,還沒有進入數據流呢?使用批處理,你可以合并處理定義良好的表格,但在流式處理模式下,不存在可以合并的表格,那么合并兩個數據流的操作是什么意思呢?
4. Python 不兼容
Python 算得上是機器學習的通用語言,但 Kafka 和 Flink 基于 Java 和 Scala 運行。引入流式處理可能會導致工作流程中的語言不兼容。Apache Beam 在 Flink 之上提供了一個用于與數據流通信的 Python 接口,但你仍然需要能用 Java/Scala 開發的人。
5. 更高的處理成本
批處理意味著你可以更加高效地使用計算資源。如果你的硬件能夠一次處理 1000 個數據點,那么使用它來一次處理 1 個數據點就顯得有些浪費了。
層級 2:在線學習
這里的「實時」定義在分鐘級。
定義「在線學習」
我使用的詞語是「在線學習」而非「在線訓練」,原因是后者存在爭議。根據定義,在線訓練的意思是基于每個輸入的數據點進行學習。非常少的公司會真正這么做,原因包括:
這種方法存在災難性遺忘的問題——神經網絡在學習到新信息時會突然遺忘之前學習的信息。
基于單個數據點的學習流程比基于批量數據的學習流程成本更高(通過降低硬件的規格,使之降到僅能處理單個數據點的水平,這個問題可以得到一定緩解)。
即使一個模型能使用每個輸入的數據點進行學習,這也不意味著在每個數據點之后都會部署新的權重。由于我們目前對機器學習算法學習方式的理解還很有限,因此模型更新后,我們還需要對其進行評估,查看表現如何。
對大多數執行所謂的在線訓練的公司而言,它們的模型都是以微批量學習的,并且會在一段時間之后進行評估。在評估之后,只有該模型的表現讓人滿意時才會得到更廣泛的部署。微博從學習到部署的模型更新迭代周期為 10 分鐘。
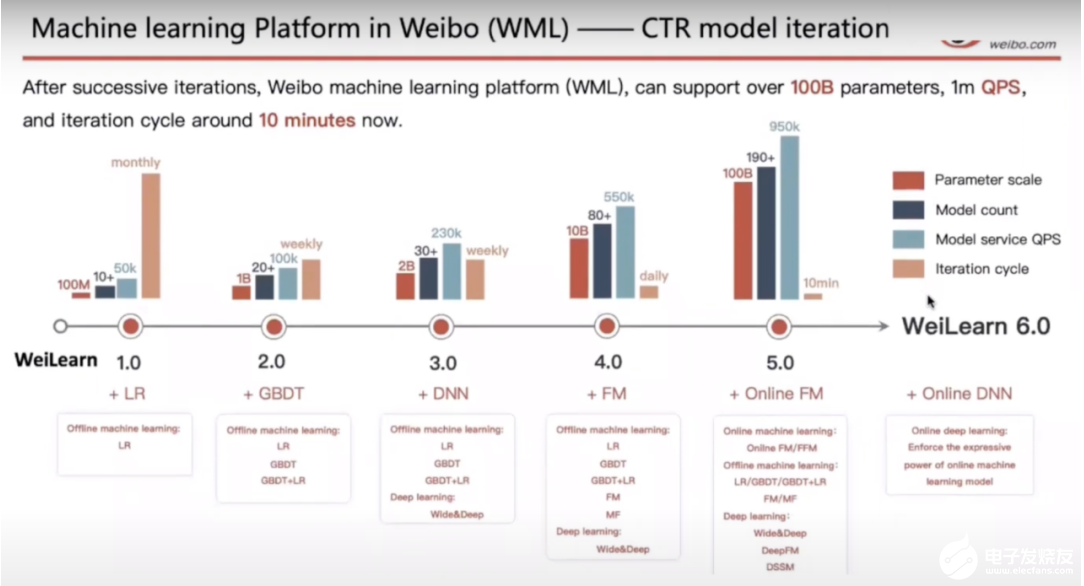
微博使用 Flink 的機器學習(圖源:https://www.youtube.com/watch?v=WQ520rWgd9A)
用例
TikTok 讓人上癮。它的秘訣在于推薦系統,其能快速學習你的偏好并推薦你可能會接著看下去的視頻,從而為用戶提供一個不斷刷新視頻的體驗。TikTok 能做到這一點的原因是其母公司字節跳動建立了一套成熟的基礎設施,使其推薦系統能夠實時地學習用戶偏好。
推薦系統是在線學習的理想應用之一。推薦系統有很自然的標簽——如果一位用戶點擊一個推薦,那么這個預測就是正確的。并非所有推薦系統都需要在線預測。用戶對房子、汽車、航班和酒店的偏好不太可能過一分鐘就變了,因此對于這樣的系統,持續學習并不太合理。但是,用戶對在線內容的偏好卻會很快改變,比如視頻、文章、新聞、推文、帖子和貼圖。(比如我剛讀到章魚有時會毫無緣由地擊打魚,現在我想看看相關視頻。)由于用戶對在線內容的偏好會實時變化,因此廣告系統也需要實時更新以展示相關廣告。
在線學習對系統適應罕見事件至關重要。以黑色星期五在線購物為例,由于黑色星期五一年僅發生一次,因此亞馬遜和其它電商網站不可能有足夠多的歷史數據來學習用戶在那天的行為,因此它們的系統需要持續學習那天的狀況以應對變化。
再以 Twitter 的搜索為例,有時候某些名人會發布一些愚蠢的內容。舉個例子,當關于「Four Seasons Total Landscaping(直譯為:四季完全景觀美化)」的新聞上線時,很多人會去搜索「total landscaping」。如果你的系統沒有立即學習到這里的「total landscaping」是指特朗普的一場新聞發布會,那么用戶就會看到大量關于園藝的推薦。
在線學習還可以幫助解決冷啟動(cold start)問題。冷啟動是指新用戶加入你的應用時,你還沒有他們的信息。如果沒有任何形式的在線學習,你就只能向新用戶推薦一般性內容,直到你下一次以離線方式訓練好模型。
解決方案
因為在線學習相對較為新穎,大多數做在線學習的公司也不會公開談論其細節,因此目前還不存在標準解決方案。
在線學習并不意味著「無批量學習」。在在線學習方面最成功的公司也會同時以離線方式訓練其模型,然后再將在線版本與離線版本組合起來。
挑戰
無論是理論上還是實踐中,在線學習都面臨著諸多挑戰。
理論挑戰
在線學習顛覆了我們對機器學習的許多已有認知。在入門級機器學習課程中,學生學到的東西雖然細節有所不同,但核心都是「使用足夠多 epoch 訓練你的模型直到收斂」。而在線學習沒有 epoch——你的模型只會看見每個數據一次。在線學習也不存在收斂這個說法,基礎數據分布會不斷變化,沒有什么可以收斂到的靜態分布。
在線學習的另一大理論挑戰是模型評估。在傳統的批訓練中,你會在靜態的留出測試集上評估模型。如果新模型在同一個測試集上優于現有模型,那我們就說新模型更好。但是,在線學習的目標是讓模型適應不斷變化的數據。如果更新后的模型是在現在的數據上訓練的,而且我們知道現在的數據不同于過去的數據,那么再在舊有數據集上測試更新后的模型是不合理的。
那么,我們該怎么知道在前 10 分鐘的數據上訓練的模型優于使用前 20 分鐘的數據訓練的模型呢?答案是必須在當前數據上比較兩個模型。在線學習需要在線評估,但是向用戶提供還未測試的模型聽起來簡直是災難。
不過,很多公司都這么做。新模型首先要進行離線測試,以確保它們不會造成災難性后果,然后再通過復雜的 A/B 測試系統,與現有模型并行地進行在線評估。只有當新模型在該公司關心的某個指標上的表現優于現有模型時,它才能得到更廣泛的部署。(本文不再討論如何選擇在線評估的指標。)
實踐挑戰
在線訓練目前還沒有標準的基礎設施。一些公司選擇使用參數服務器的流式架構,但除此之外,我了解過的公司都不得不構建許多自己的基礎設施。此處不再詳細討論,因為一些公司要求我對這些信息保密,因為他們構建的方案是為自己服務的——這是他們的競爭優勢。
美國和中國的 MLOps 競賽
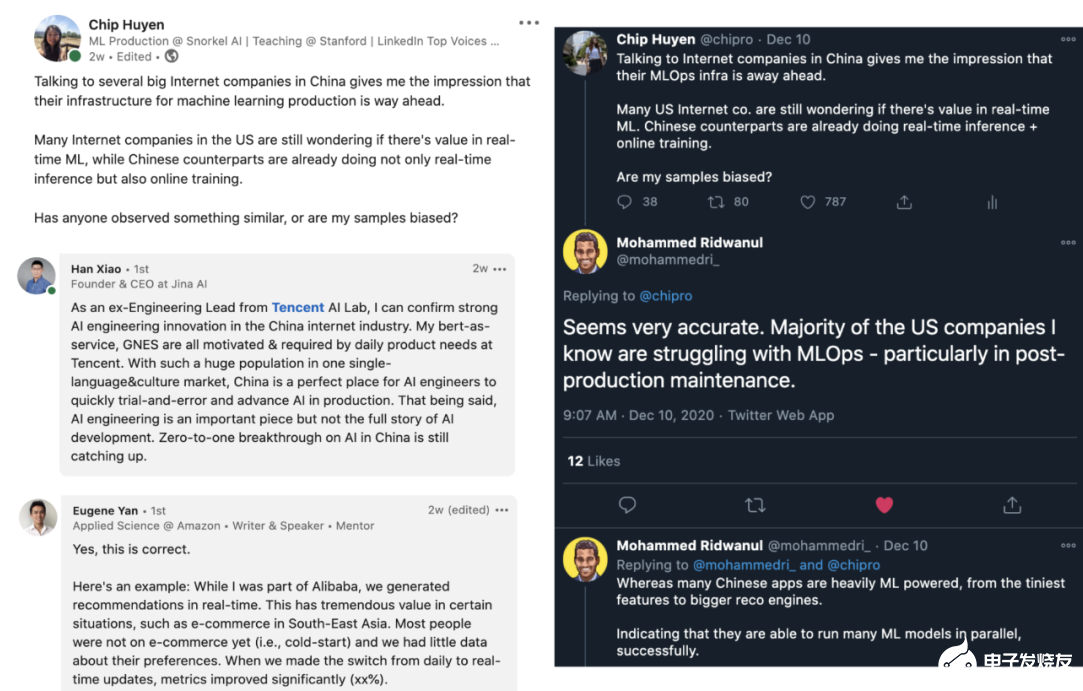
我讀過許多有關美國和中國 AI 競賽的文章,但大多數比較關注研究論文、專利、引用和投資。但當我與美國和中國公司聊過實時機器學習的話題之后,我才注意到他們的 MLOps 基礎設施有著驚人的差距。
美國很少互聯網公司嘗試過在線學習,而即使是使用在線學習的公司,也不過是將其用于簡單的模型,比如 Logistic 回歸。而不管是與中國公司直接談,還是與曾在兩個國家的公司工作過的人談,給我的印象都是在線學習在中國公司里更常見,而且中國的工程師也更愿意嘗試在線學習。下圖是一些對話截圖。
總結
實時機器學習發展正盛,不管你是否已經準備好。盡管大多數公司還在爭論在線推理和在線學習是否有價值,但某些正確部署的公司已經看到了投資回報,它們的實時算法可能將成為它們保持競爭優勢的重要因素。
編輯:hfy
-
FPGA
+關注
關注
1660文章
22412瀏覽量
636296 -
機器學習
+關注
關注
66文章
8553瀏覽量
136941
發布評論請先 登錄
機器學習和深度學習中需避免的 7 個常見錯誤與局限性

機器視覺的核心技術和應用場景
穿孔機頂頭檢測儀 機器視覺深度學習
機器視覺光源技術深度解析:行業現狀與創新趨勢

機器視覺光學基礎概念——眩光、鬼影與熱點

如何在機器視覺中部署深度學習神經網絡

2025嵌入式行業現狀如何?
FPGA在機器學習中的具體應用
磁性元件行業專利現狀探討
A股機器人概念崛起:科義巡檢機器人與視頻行為分析系統共推智能化發展
邊緣計算中的機器學習:基于 Linux 系統的實時推理模型部署與工業集成!

工業機器人與協作機器人概念不同

貿澤電子2025技術創新論壇探討“邊緣AI與機器學習”新紀元

工業物聯網平臺是什么(概念及功能)
Raspberry Pi Pico 2 上實現:實時機器學習(ML)音頻噪音抑制功能



 工商網監
工商網監
評論