 論Linux的頁遷移(Page Migration)
論Linux的頁遷移(Page Migration)

對于用戶空間的應用程序,我們通常根本不關心page的物理存放位置,因為我們用的是虛擬地址。所以,只要虛擬地址不變,哪怕這個頁在物理上從DDR的這里飛到DDR的那里,用戶都基本不感知。那么,為什么要寫一篇論述頁遷移的文章呢?
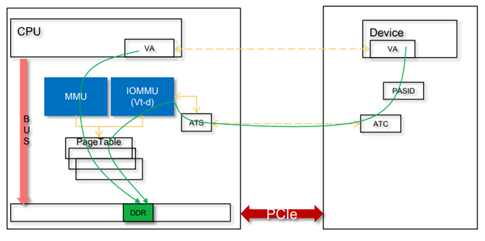
我認為有2種場景下,你會關注這個Page遷移的問題:一個是在Linux里面寫實時程序,尤其是Linux的RT補丁打上后的情況,你希望你的應用有一個確定的時延,不希望跑著跑著你的Page正在換位置而導致的延遲;再一個場景就是在用戶空間做DMA的場景,尤其是SVA(SharedVirtual Addressing),設備和CPU共享頁表,設備共享進程的虛擬地址空間的場景,如果你DMA的page跑來跑去,勢必導致設備DMA的暫停,設備的傳輸性能出現嚴重抖動。這種場景下,設備的IOMMU和CPU的MMU會共享Page table:
1.CoW導致的頁面遷移
1.1 fork
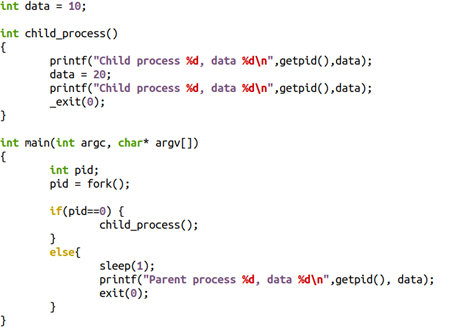
典型的CoW(寫時拷貝)與fork()相關,當父子兄弟進程共享一部分page,而這些page本身又應該是具備獨占屬性的時候,這樣的page會被標注為只讀的,并在某進程進行寫動作的時候,產生page fault,其后內核為其申請新的page。比如下面的代碼中,把10寫成20的進程,在寫的過程中,會得到一頁新的內存,data原本的虛擬地址會指向新的物理地址,從而發生page的migration。
1.2 KSM
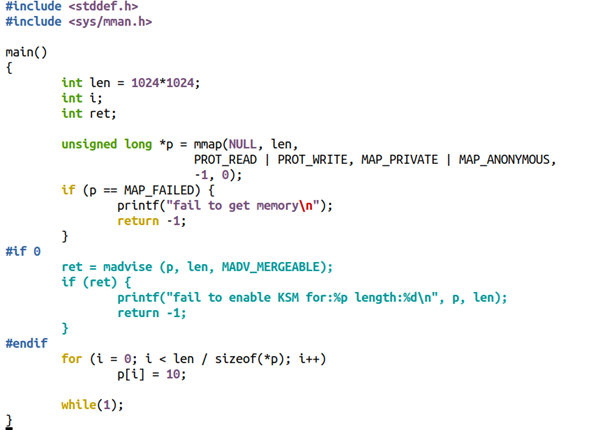
其他的CoW的場景有KSM(Kernel same-page merging)。KSM會掃描多個進程的內存,如果發現有page的內容是一模一樣的,則會將其merge為一個page,并將其標注為寫保護的。之后對這個page執行CoW,誰寫誰得到新的拷貝。比如,你在用qemu啟動一個虛擬機的時候,使用mem-merge=on,就可以促使多個VM共享許多page,從而有利于實現“超賣”。
sudo /x86_64-softmmu/qemu-system-x86_64 -enable-kvm -m 1G -machinemem-merge=on
不過這本身也引起了虛擬機的一些安全漏洞,可被side-channel攻擊。
比如,把下面的代碼編譯為a.out,并且啟動兩份a.out進程
./a.out&./a.out
代碼:
我們看到這2個a.out的內存消耗情況如下:

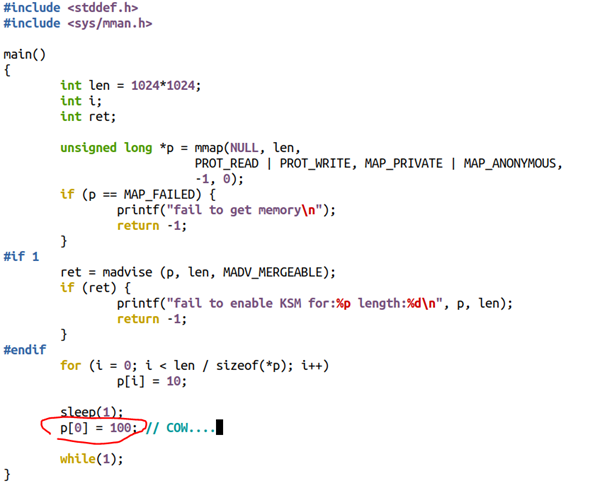
但是,如果我們把中間的if0改為if 1,也就是暗示mmap()的這1MB內存可能要merge,則耗費內存的情況發生顯著變化:

耗費的內存大大減小了。
我們可以看看pageshare的情況:

Merge發生在進程內部,也發生在進程之間。
當然,如果在page已經被merge的情況下,誰再寫merge過的page,則會引起寫時拷貝,比如如下代碼中的p[0]=100這句話。
2.內存規整導致的頁面遷移
2.1 CMA引起的內存遷移
CMA (TheContiguousMemory Allocator)可運行作為dma_alloc_coherent()的后端,它的好處在于,CMA區域的空閑部分,可以被應用程序拿來申請MOVABLE的page。如下圖中的一個CMA區域的紅色部分已經被設備驅動通過dma_alloc_coherent()拿走,但是藍色部分目前被用戶進程通過malloc()等形式拿走。
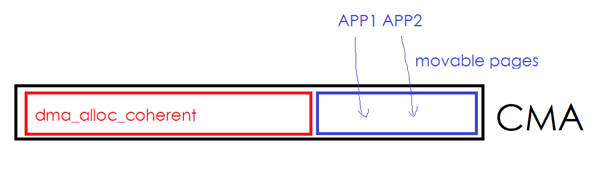
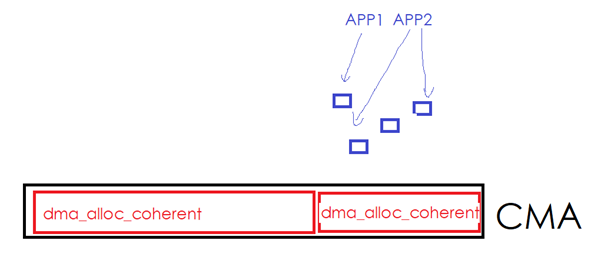
一旦設備驅動繼續通過dma_alloc_coherent()申請更多的內存,則內核必須從別的非CMA區域里面申請一些page,然后把藍色的區域往新申請的page移走。用戶進程占有的藍色page發現了遷移。
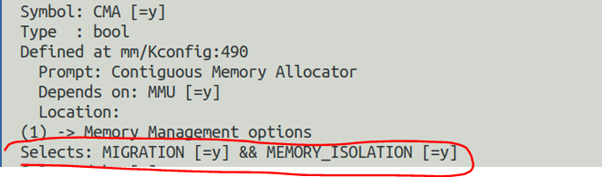
CMA在內核的配置選項中依賴于MMU,且會自動使能MIGRATION(Pagemigration)和MEMORY_ISOLATION:
2.2 alloc_pages
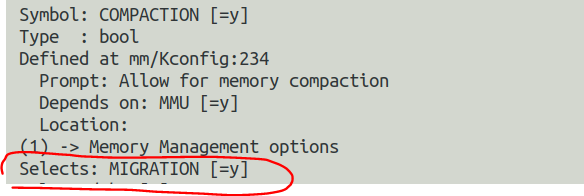
當內核使能了COMPACTION,則Linux的底層buddy分配器會在alloc_pages()中嘗試進行內存遷移以得到連續的大內存。COMPACTION這個選項也會使能CMA一節提及的MIGRATION選項。
從代碼的順序上來看,alloc_pages()分配order比較高的連續內存的時候,是優先考慮COMPACTION,再次考慮RECLAIM的。
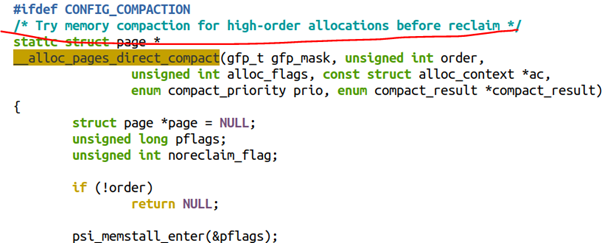
2.3 /proc/sys/vm/compact_memory
當然,上面alloc_pages所提及的compaction也可以被用戶手動的觸發,觸發方式:
echo 1 >/proc/sys/vm/compact_memory
將1寫入compact_memory文件,則內核會對各個zone進行規整,以便能夠盡可能地提供連續內存塊。
我的Ubuntu已經運行了一段時間,內存稍微有些碎片化了,我們來對比下手動執行
compact_memory前后,buddy的情況:

可以清晰地看出來,執行compact_memory后,DMA32 ZONE和NORMAL ZONE里面,order比較大的連續page數量都明顯增大了。
2.4 huge page
再次展開內核的COMPACTION選型,你會發現COMPACTION會被透明巨頁自動選中:
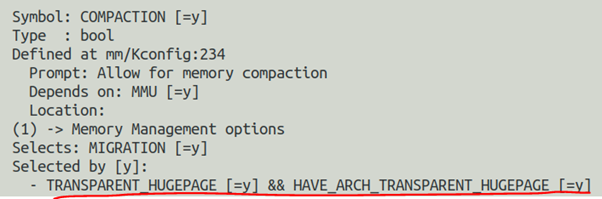
這說明透明巨頁是依賴于COMPACTION選項的。
所謂透明巨頁,無非就是應用程序在運行的時候,神不知鬼不覺地偷偷地就使用到了Hugepage的功能,這個過程對用戶是透明的。與透明對應的無非就是不透明的巨頁,這種方式下,應用程序需要顯示地告訴內核我需要使用巨頁。
我們先來看看不透明的巨頁是怎么玩的?一般用戶程序可以這樣寫,在mmap里面會加上MAP_HUGETLB的Flag,當然這個巨頁也必須是提前預設好的,否則mmap就會失敗。
ptr_ = mmap(NULL, memory_size_, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB, -1, 0);
比如下面的代碼我們想申請2MB的巨頁:
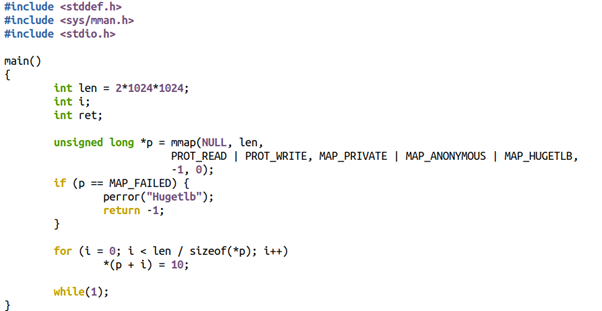
程序執行的時候會返回錯誤,打印如下:
$ ./a.out Hugetlb:Cannotallocatememory
原因很簡單,因為現在系統里面2MB的巨頁數量和free的數量都是0:

我們如何讓它申請成功呢?我們首先需要保證系統里面有一定數量的巨頁。這個時候我們可以寫nr_hugepages得到巨頁:

我們現在讓系統得到了10個大小為2048K的巨頁。
現在來重新運行a.out,就不在出錯了,而且系統里面巨頁的數量發生了變化:

Free的數量從10頁變成了9頁。
聰明的童鞋應該想到了,當我們嘗試預留巨頁的時候,它最終還是要走到buddy,假設系統里面沒有連續的大內存,系統是否會進行內存遷移以幫忙規整出來巨頁呢?這顯然符合前面說的alloc_pages()的邏輯。從alloc_buddy_huge_page()函數的實現也可以看出這一點:
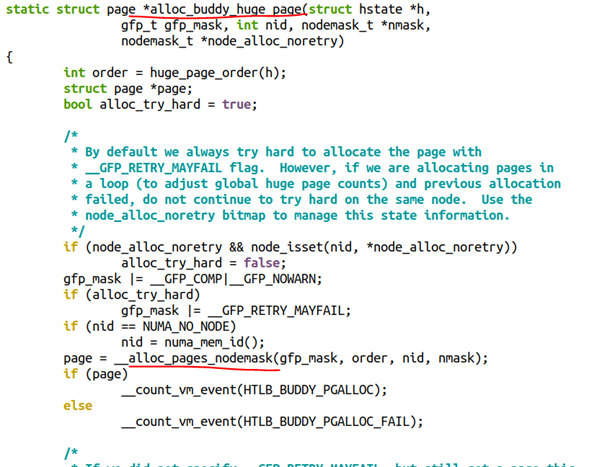
另外,這種巨頁的特點是“預留式”的,不會free給系統,也不會被swap。因此可有效防止用戶態DMA的性能抖動。對于DPDK這樣的場景,人們喜歡這種巨頁分配,減少了頁面的數量和TLB的miss,縮短了虛擬地址到物理地址的重定位的轉換時間,因此提高了性能。
當然,我們在運行時通過寫nr_hugepages的方法設置巨頁,這種方法未必一定能夠成功。所以,工程中也可以考慮通過內核啟動的bootargs來設置巨頁,這樣Linux開機的過程中,就可以直接從bootmem里面分配巨頁,而不必在運行時通過order較高的alloc_pages()來獲取。這個在內核文檔的kernel-parameters.txt說的比較清楚,你可以在bootargs里面設置各種不同hugepagesize有多少個頁數:
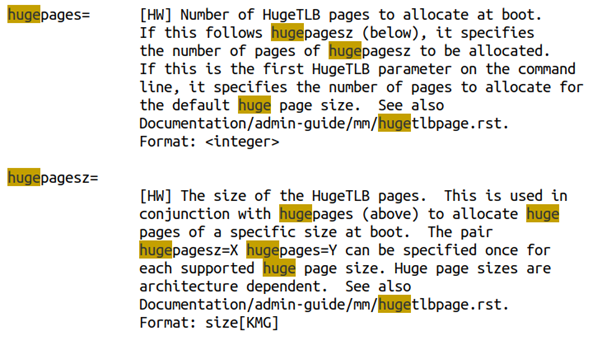
透明巨頁聽起來是比較牛逼的,因為它不需要你在應用程序里面通過MAP_HUGETLB來顯式地指定,但是實際的使用場景則未必這么牛逼。
使用透明巨頁的最激進的方法莫過于把enabled和defrag都設置為always:
echo always >/sys/kernel/mm/transparent_hugepage/enabledechoalways>/sys/kernel/mm/transparent_hugepage/defrag
enabled寫入always暗示對所有的區域都盡可能使用透明巨頁,defrag寫入always暗示內核會激進地在用戶申請內存的時候進行內存回收(RECLAIM)和規整(COMPACTION)來獲得THP(透明巨頁)。
我們來前面的例子代碼稍微進行更改,mmap16MB內存,并且去掉MAP_HUGETLB:

運行這個程序,并且得到它的pmap情況:
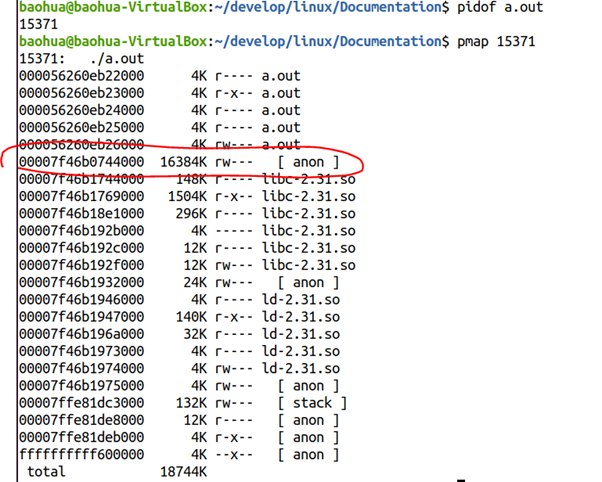
我們發現從00007f46b0744000開始,有16MB的anon內存區域,顯然對應著我們代碼里面的mmap(16*1024*1024)的區域。
我們進一步最終/proc/15371/smaps,可以得到該區域的內存分布情況:
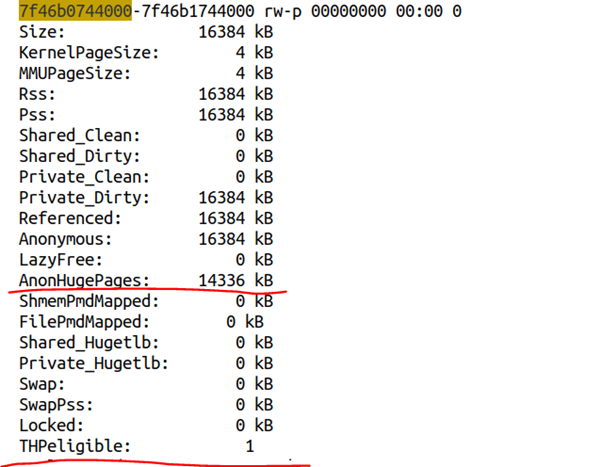
顯然該區域是THPeligible的,并且獲得了透明巨頁。內核文檔filesystems/proc.rst對THPeligible的描述如下:
"THPeligible" indicates whether the mapping is eligible for allocating THP pages - 1 if true, 0 otherwise. It just shows the current status.
透明巨頁的生成,顯然會涉及到前面的內存COMPACTION過程。透明巨頁在實際的用戶場景里面,可能反而因為內存的RECLAIM和COMPACTION而降低了性能,比如有些VMA區域的壽命很短申請完使用后很快釋放,或者某些使用大內存的進程是短命鬼,進行規整花了很久,而跑起來就釋放了這部分內存,顯然是不值得的。類似《權力的游戲》中的夜王,花了那么多季進行內存規整準備干夜王這個透明巨頁,結果夜王上來就被秒殺了,你說我花了多時間追劇冤不冤?
所以,透明巨頁在實際的工程中,又引入了一個半透明的因子,就是內核可以只針對用戶通過madvise()暗示了需要巨頁的區間進行透明巨頁分配,暗示的時候使用的參數是MADV_HUGEPAGE:

所以,默認情況下,許多系統會把enabled和defrag都設置為madvise:
echo madvise >/sys/kernel/mm/transparent_hugepage/enabledechomadvise>/sys/kernel/mm/transparent_hugepage/defrag
或者干脆把透明巨頁的功能關閉掉:
echo never >/sys/kernel/mm/transparent_hugepage/enabledechonever>/sys/kernel/mm/transparent_hugepage/defrag
如果我們只對madvise的區域采用透明巨頁,則用戶的代碼可以這么寫:
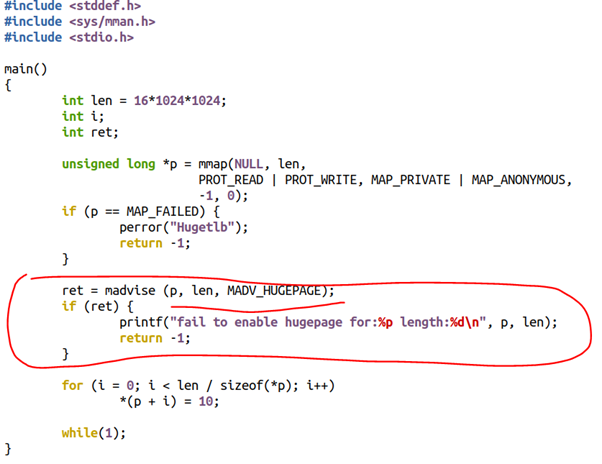
既然我都已經這么寫代碼了,我還透明個什么鬼?所以,我寧可為了某種確定性,而去追求預留式的,非swap的巨頁了。
3.NUMABalancing引起的頁面遷移
在一個典型的NUMA系統中,存在多個NODE,很可能每個NODE都有CPU和Memory,NODE和NODE之間通過某種總線再互聯。下面中的NUMA系統有4個NODE,每個NODE有24個CPU和1個內存,NODE之間通過紅線互聯:
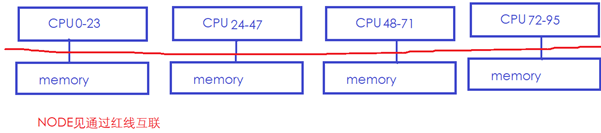
在這樣的系統中,通常CPU訪問本地NODE節點的memory會比較快,而跨NODE訪問memory則會慢很多(紅色總線慢)。所以Linux的NUMA自動均衡機制,會嘗試將內存遷移到正在訪問它的CPU節點所在的NODE,如下圖中綠色的memory經常被CPU24訪問,但是它位于NODE0的memory:
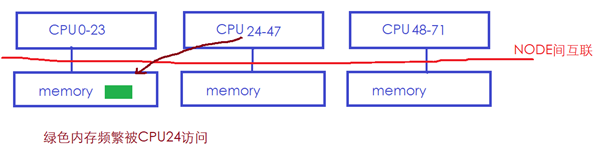
則Linux內核可能會將綠色內存遷移到CPU24所在的本地memory:
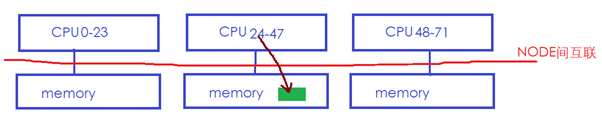
這樣CPU24訪問它的時候就會快很多。
顯然NUMA_BALANCING也是依賴MIGRATION機制的:

下面我們來寫個多線程的程序,這個程序里面有28個線程(一個主線程,26個dummy線程執行死循環,以及一個寫內存的線程):

我們開那么多線程的目的,無非是為了讓write_thread_start對應的線程,盡可能地不被分配到主線程所在的NUMA節點。
這個程序的主線程最開始寫了64MB申請的內存,30秒后,通過write_done=1來暗示write_thread_start()線程你可以開始寫了,write_thread_start()則會把這64MB也寫一遍,如果主線程和write_thread_start()線程不在一個NODE節點的話,內存遷移就有可能發生。
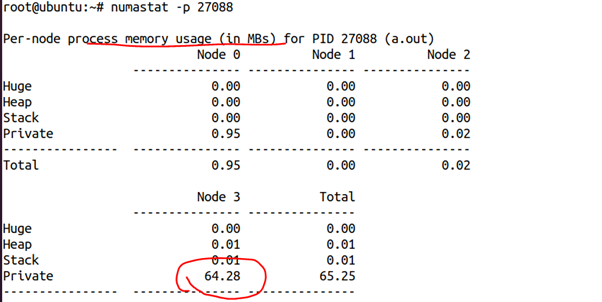
這是我們剛開始2秒的時候獲得的該進程的numastat,可以看出,這64MB內存幾乎都在NODE3上面:
但是30秒后,我們再次看它的NUMA狀態,則發生了巨大的變化:
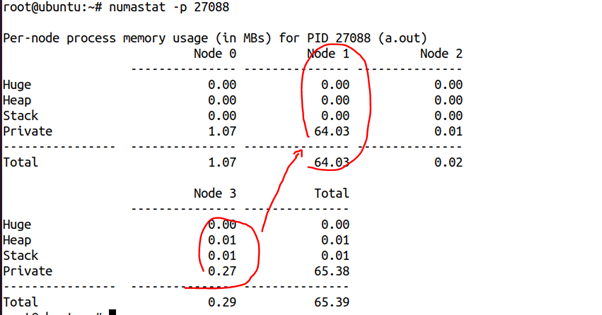
64MB內存跑到NODE1上面去了。由此我們可以推斷,write_thread_start()線程應該是在NODE1上面跑,從而引起了這個遷移的發生。
當然,我們也可以通過numactl--cpunodebind=2類似的命令來規避這個問題,比如:
# numactl --cpunodebind=2 ./a.out
NUMA Balancing的原理是通過把進程的內存一部分一部分地周期性地進行unmap(比如每次256MB),在頁表里面把掃描的部分的PTE設置為 “no access permission” ,以在其后訪問它的時候,強制產生pagefault,進而探測page fault發生在本地NODE還是遠端NODE,來獲知CPU和memory是否較遠的。這說明,哪怕沒有真實的遷移發生,NUMA balancing也會導致進程的內存訪問出現Page fault。
-
cpu
+關注
關注
68文章
11279瀏覽量
224975 -
Linux
+關注
關注
88文章
11760瀏覽量
219026 -
代碼
+關注
關注
30文章
4968瀏覽量
73965
原文標題:宋寶華:論Linux的頁遷移(Page Migration)上集
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「Linux 設備驅動開發(第 2 版)」閱讀體驗】+讀深入理解Linux內核內存分配
京東關鍵詞搜索商品列表的Python實戰
分享一個Linux音頻開發實用站:ALSA項目官網使用指南

別再裝系統了!Linux 鏡像到底是什么?一篇講到你懷疑人生

破解銅/銀遷移難題:納米級離子捕捉劑在先進封裝中的工程化應用
無質量損失的數據遷移:Nikon SLM Solutions信賴3Dfindit企業版
新思科技攜手是德科技推出AI驅動的射頻設計遷移流程
Windows 與 Linux 系統切換:聚徽工控一體機的系統遷移避坑經驗
如何精準提取MOSFET溝道遷移率
Allegro Skill布局功能之按頁擺放器件介紹
Arm助力開發者加速遷移至Arm架構云平臺 Arm云遷移資源分享
DietPi 9.10:帶來 RISC-V 升級與樹莓派內核遷移

KVM主機遷移方法



 工商網監
工商網監
評論