 機器學習的任務:從學術論文中學習數據預處理
機器學習的任務:從學術論文中學習數據預處理

作為工作中最關鍵的部分,數據預處理同時也是大多數數據科學家耗時最長的項目,他們大約80%的時間花在這上面。
這些任務有怎樣重要性?有哪些學習方法和技巧?本文就將重點介紹來自著名大學和研究團隊在不同培訓數據主題上的學術論文。主題包括人類注釋者的重要性,如何在相對較短的時間內創建大型數據集,如何安全處理可能包含私人信息的訓練數據等等。
1. 人類注釋器(human annotators)是多么重要?
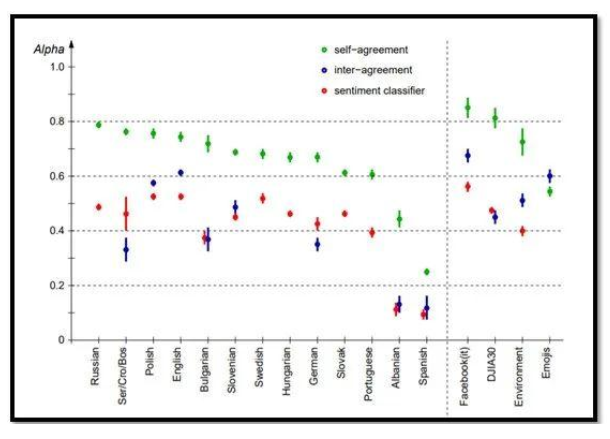
本文介紹了注釋器質量如何極大地影響訓練數據,進而影響模型的準確性的第一手資料。在這個情緒分類項目里,Joef Stefan研究所的研究人員用多種語言分析了sentiment-annotated tweet的大型數據集。
有趣的是,該項目的結果表明頂級分類模型的性能在統計學上沒有重大差異。相反,人類注釋器的質量是決定模型準確性的更大因素。
為了評估他們的注釋器,團隊使用了注釋器之間的認同過程和自我認同過程。研究發現,雖然自我認同是去除表現不佳的注釋器的好方法,但注釋者之間的認同可以用來衡量任務的客觀難度。
研究論文:《多語言Twitter情緒分類:人類注釋器的角色》(MultilingualTwitter Sentiment Classification: The Role of Human Annotators)
作者/供稿人:Igor Mozetic, Miha Grcar, Jasmina Smailovic(所有作者均來自Jozef Stefan研究所)
出版/最后更新日期:2016年5月5日
2.機器學習的數據收集調查
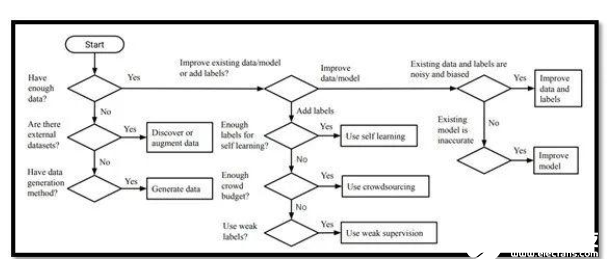
這篇論文來自韓國先進科學技術研究所的一個研究團隊,非常適合那些希望更好地了解數據收集、管理和注釋的初學者。此外,本文還介紹和解釋了數據采集、數據擴充和數據生成的過程。
對于剛接觸機器學習的人來說,這篇文章是一個很好的資源,可以幫助你了解許多常見的技術,這些技術可以用來創建高質量的數據集。
研究論文:《機器學習的數據收集調查》(A Survey on Data Collection for MachineLearning)
作者/供稿人: Yuji Roh, Geon Heo, Steven Euijong Whang (所有作者均來自韓國科學技術院)
出版/最后更新日期:2019年8月12日
3.用于半監督式學習和遷移學習的高級數據增強技術
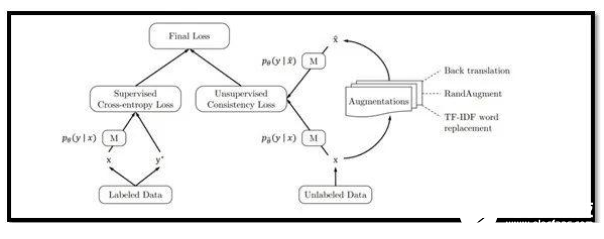
目前數據科學家面臨的最大問題之一就是獲得訓練數據。也可以說,深度學習所面臨最大的問題之一,是大多數模型都需要大量的標簽數據才能以較高的精度發揮作用。
為了解決這些問題,來自谷歌和卡內基·梅隆大學的研究人員提出了一個在大幅降低數據量的情況下訓練模型的框架。該團隊提出使用先進的數據增強方法來有效地將噪音添加到半監督式學習模型中使用的未標記數據樣本中,這個框架能夠取得令人難以置信的結果。
該團隊表示,在IMDB文本分類數據集上,他們的方法只需在20個標記樣本上進行訓練,就能夠超越最先進的模型。此外,在CIFAR-10基準上,他們的方法表現優于此前所有的方法。
論文題目:《用于一致性訓練的無監督數據增強》(UnsupervisedData Augmentation for Consistency Training)
作者/供稿人:Qizhe Xie (1,2), Zihang Dai (1,2), Eduard Hovy (2),Minh-Thang Luong (1), Quoc V. Le (1) (1 – Google研究院,谷歌大腦團隊, 2 – 卡耐基·梅隆大學)
發布日期 / 最后更新:2019年9月30日
4.利用弱監督對大量數據進行標注
對于許多機器學習項目來說,獲取和注釋大型數據集需要花費大量的時間。在這篇論文中,來自斯坦福大學的研究人員提出了一個通過稱為“數據編程”的過程自動創建數據集的系統。
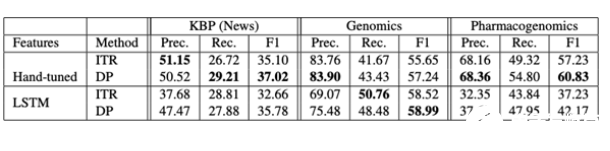
上表是直接從論文中提取的,使用數據編程(DP)顯示了與遠程監督的ITR方法相比的精度、召回率和F1得分。
該系統采用弱監管策略來標注數據子集。產生的標簽和數據可能會有一定程度的噪音。然而,該團隊隨后通過將訓練過程表示為生成模型,從數據中去除噪音,并提出了修改損失函數的方法,以確保它對“噪音感知”。
研究論文:《數據編程:快速創建大型訓練集》(DataProgramming: Creating Large Training Sets, Quickly)
作者/供稿人:Alexander Ratner, Christopher De Sa, Sen Wu, DanielSelsam, Christopher Re(作者均來自斯坦福大學)
發布/最后更新日期:2017年1月8日
5.如何使用半監督式知識轉移來處理個人身份信息(PII)
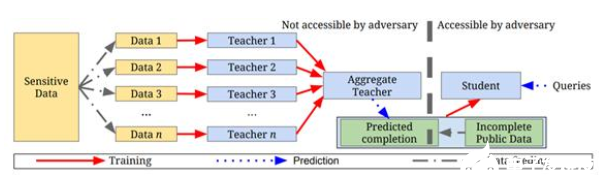
來自谷歌和賓夕法尼亞州立大學的研究人員介紹了一種處理敏感數據的方法,例如病歷和用戶隱私信息。這種方法被稱為教師集合私有化(PATE),可以應用于任何模型,并且能夠在MNIST和SVHN數據集上實現最先進的隱私/效用權衡。
然而,正如數據科學家Alejandro Aristizabal在文章中所說,PATE所設計的一個主要問題為該框架要求學生模型與教師模型共享其數據。在這個過程中,隱私得不到保障。
為此Aristizabal提出了一個額外的步驟,為學生模型的數據集加密。你可以在他的文章Making PATEBidirectionally Private中讀到這個過程,但一定要先閱讀其原始研究論文。
論文題目:《從隱私訓練數據進行深度學習的半監督式知識轉移》(Semi-SupervisedKnowledge Transfer for Deep Learning From Private Training Data)
作者/供稿人:Nicolas Papernot(賓夕法尼亞州立大學)、Martin Abadi(谷歌大腦)、Ulfar Erlingsson(谷歌)、Ian Goodfellow(谷歌大腦)、Kunal Talwar(谷歌大腦)。
發布日期 / 最后更新:2017年3月3日
閱讀頂尖學術論文是了解學術前沿的不二法門,同時也是從他人實踐中內化重要知識、學習優秀研究方法的好辦法,多讀讀論文絕對會對你有幫助。
-
機器學習
+關注
關注
66文章
8553瀏覽量
136935 -
論文
+關注
關注
1文章
103瀏覽量
15415 -
數據預處理
+關注
關注
1文章
20瀏覽量
3000
發布評論請先 登錄
機器學習特征工程:分類變量的數值化處理方法

人工智能與機器學習在這些行業的深度應用
機器學習和深度學習中需避免的 7 個常見錯誤與局限性
數據預處理軟核加速模塊設計
思必馳與上海交大聯合實驗室五篇論文入選NeurIPS 2025
量子機器學習入門:三種數據編碼方法對比與應用

超小型Neuton機器學習模型, 在任何系統級芯片(SoC)上解鎖邊緣人工智能應用.
思必馳與上海交大聯合實驗室兩篇論文入選ICML 2025
邊緣計算中的機器學習:基于 Linux 系統的實時推理模型部署與工業集成!

機器學習賦能的智能光子學器件系統研究與應用


嵌入式AI技術之深度學習:數據樣本預處理過程中使用合適的特征變換對深度學習的意義
**【技術干貨】Nordic nRF54系列芯片:傳感器數據采集與AI機器學習的完美結合**
Raspberry Pi Pico 2 上實現:實時機器學習(ML)音頻噪音抑制功能



 工商網監
工商網監
評論