 進程虛擬內存布局以及進程的虛擬內存分配釋放流程,涉及的代碼
進程虛擬內存布局以及進程的虛擬內存分配釋放流程,涉及的代碼

隨著cpu技術發展,現在大部分移動設備、PC、服務器都已經使用上64bit的CPU,但是關于Linux內核的虛擬內存管理,還停留在歷史的用戶態與內核態虛擬內存3:1的觀念中,導致在解決一些內存問題時存在誤解。
例如現在主流的移動設備操作系統Android,經常遇到進程使用大量內存導致被lmk殺死,分配不到內存而觸發OOM/ANR,或者分配內存慢導致卡頓,內核態使用哪個分配內存的函數更合理等問題,有些涉及物理內存分配,有些涉及虛擬內存分配,如果不熟悉虛擬內存管理的技術知識,可能走很多彎路。
我們計劃通過一系列文章來介紹虛擬內存分配/釋放,缺頁處理,內存壓縮/回收,內存分配器等知識,梳理虛擬內存的管理。本章節結合代碼介紹進程虛擬內存布局以及進程的虛擬內存分配釋放流程,涉及的代碼是android-8.1, 內核版本kernel-4.9,架構是arm64。
進程虛擬內存空間
虛擬地址空間分布
理論上,64bit地址支持訪問的地址空間是[0, 2(64-1)],而實際上現有的應用程序都不會用這么大的地址空間,并且arm64芯片現在也不支持訪問這么大的地址空間,arm64架構芯片最大支持訪問48bit的地址空間。例如在Android系統中,整個虛擬地址空間分成兩部分,如下圖所示:
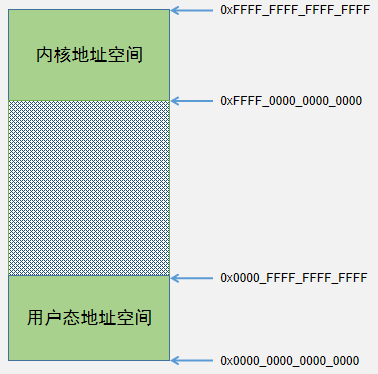
其中[0x0001000000000000,0xFFFF000000000000]之間的地址是不規范地址,不能使用;該段內存把整個虛擬地址空間劃分為兩段,低段內存為進程用戶態地址空間,高段內存為內核地址空間。參考代碼(archarm64includeasmmemory.h):

如果內核打開CONFIG_COMPAT選項,說明用戶態既支持64位進程,也支持32位進程;由于32bit的地址最多可以訪問的虛擬地址空間最多只有4GB(232 Byte),所以32位進程的用戶態進程地址空間與64位進程是有區別的。
32位進程的用戶態地址空間是[0x0, 0x00000000FFFF_FFFF]
64位進程的用戶態地址空間是[0x0, 0x0000FFFFFFFF_FFFF]
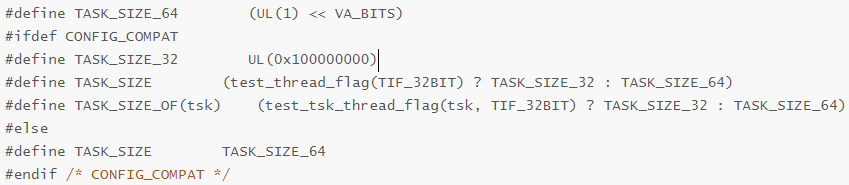
從代碼看出,32bit進程用戶空間大小是4GB,64bit進程的虛擬內存大小與CONFIG_ARM64_VA_BITS的值相關;如果CONFIG_ARM64_VA_BITS是48bit則可以達到256TB,現在的移動設備顯然用不到這么大的內存空間,所以大部分Android設備中CONFIG_ARM64_VA_BITS默認配置的是39,即64bit進程的最大虛擬地址空間大小是512GB。
雖然32bit或者64bit的進程在用戶態內存空間大小不一樣,但是當它們陷入到內核態后,訪問的內核空間地址是沒有差異的,都是從VA_START開始,直到0xFFFFFFFFFFFFFFFF結束,也是512GB。
每個進程的虛擬地址空間主要分為如下幾個區域(如圖):
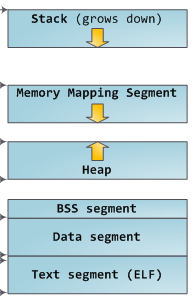
代碼段(text)、數據段(data)和未初始化數據段(bss)。
動態庫的代碼段、數據段和未初始化數據段。
堆(heap),動態分配和釋放的內存。
棧(stack),存放局部變量和實現函數調用。
環境變量和參數字符串的存儲區。
文件區間映射到虛擬地址空間的內存映射區域。
其中Data Segment、BSS segment、Heap段統稱為數據點。
幾種地址的概念
介紹完虛擬內存地址空間,澄清幾種地址的概念:物理地址、線性地址、邏輯地址三種地址的含義。
物理地址
每片物理內存存儲實際地址,例如一個8GB的內存,0x00000000表示第一個byte的地址,而0xFFFFFFFF表示的是最后一個byte的地址;物理地址的值與實際的內存條上的地址一一對應,物理地址的大小與cpu訪問物理內存的總線寬度有一定的關系。
線性地址
為了保證系統多任務運行的安全性和可靠性(防止一個任務篡改系統或者其他任務的內存),CPU增加段頁式內存管理;段基地址+段內偏移構成的地址就是線性地址;如果開啟的分頁內存管理,線性地址還要通過MMU計算才能轉換出物理地址。
邏輯地址
每個進程運行時CPU看到的地址就是邏輯地址,實際上也是線性地址中的段內偏移地址,邏輯地址與段基地址可以計算出線性地址。
進程在訪問虛擬地址空間的任意合法地址時,都要按照邏輯地址->線性地址->物理地址的順序換算才能找到對應的物理地址;由于段式內存管理存在性能、訪問效率的問題,以及Linux要兼容各種CPU,在Linux內核中所有的用戶態進程使用的同一個段,且段基地址都是0,如此既可以兼容的傳統的段式內存管理,又可以通過頁式內存映射更靈活的管理內存。由于同一個段基地址都是0,對每個進程來說,邏輯地址和線性地址是一樣的;同時每個進程的PGD是不一樣的,從而保證每個進程之間隔離,不同進程同一個虛擬地址映射的物理地址就不一樣了。
Linux系統采用延遲分配物理內存的策略,用戶態進程每次分配內存時分配的都是虛擬內存,表示一段地址空間已經分配出來供進程使用;當進程第一次訪問虛擬地址時,才會發現虛擬地址沒有對應的物理內存,系統默認會觸發缺頁異常,從內核物理內存管理系統中分配物理頁,建立頁表中把虛擬地址映射到物理地址。對于缺頁異常處理流程,頁表創建/建立/銷毀等操作在以后文章中介紹。
分配內存的系統調用
在Linux系統中,虛擬內存和物理內存都是由kernel管理的,當進程需要分配內存時,都需要通過系統調用陷入到內核空間分配,再虛擬內存起始地址返回到用戶態;內核提供了多個系統調用來分配虛擬內存,包括brk、mmap和mremap等。
brk系統調用
brk是傳統分配/釋放堆內存的系統調用, 堆內存是由低地址向高地址方向增長;
分配內存時,將數據段(.data)的最高地址指針_edata往高地址擴展;
釋放內存時,把_edata向低地址收縮。
可以看出brk系統調用管理的始終是一片連續的虛擬地址空間,而且起始地址一經設定就默認不變,只是高地址按需變化。
mmap系統調用
mmap系統調用是在進程堆和棧中間(稱為Memory Mapping Segment)找一塊空閑的虛擬內存,mmap可以進行匿名映射和文件映射,文件映射即把磁盤存儲設備上面的文件映射的內存中,然后訪問內存就是訪問文件,文件映射的物理頁是可以通過kswapd或者direct reclaim回收的;匿名映射即沒有映射任何文件。
由于brk系統調用分配內存存在內存碎片化線性,例如先分配100MB的內存,然后再分配4KB內存,再把100MB內存釋放掉,此時由于4KB內存還沒有釋放,_edata就不能收縮,導致100MB內存不能及時操作系統;反之先分配4KB,在分配100MB,則存在內存碎片化的問題。另外由于_edata上面是mmap區域,_edata與最近的mmap內存很接近,則會導致brk系統調用極容易分配失敗,即使memory mmap區域還有大量可用內存。Brk分配管理的實際上就是一塊匿名映射的內存,所以實際上可以通過mmap匿名映射來滿足malloc的內存分配。在Linux操作系統標準libc庫中,malloc函數的實現中會根據分配內存的size來決定使用哪個分配函數, 當size小于等于128KB,調用brk分配, 當size大于128KB時,調用mmap分配內存。
這兩種方式分配的都是虛擬內存,沒有分配物理內存。在第一次訪問已分配的虛擬地址空間的時候,發生缺頁中斷,操作系統負責分配物理內存,然后建立虛擬內存和物理內存之間的映射關系。
分配器
如果進程每次分配內存都通過brk和mmap系統調用分配的話,存在兩個致命的問題:
碎片化的問題,從內核分配虛擬內存都是按照page(默認是4KB)對齊來分配的,如果進程分配8byte,實際從內核分配的內存是4096byte,這樣就存在4088byte的浪費;同時進程的內存分配需求存在隨機性,如果不同大小的內存交替分配,當部分內存釋放后,整個內存空間嚴重碎片化,導致最后分配大片內存時高概率會失敗。
性能問題,系統調用從用戶態陷入到內核態都是通過中斷來實現的,在進程從內核態返回到用戶態時,任務有可能被調度出cpu;另外,對于多線程的進程,所有的線程共享同一個mm,如果多個線程同時分配內存,則在內核空間存在競爭關系,所有的線程分配請求都要排隊處理;如果頻繁系統調用分配內存,分配內存的效率會降低。
分配器的出現就是為了解決上述問題,例如我們熟悉的libc庫,調用malloc的時候并不是每次都會通過系統調用從內核分配內存的,而是分配器相當于在malloc和系統調用之間插入一層中間件。分配器首先通過系統調用從內核批發大塊內存,然后切成不同大小的內存片緩存起來,例如8/16/24/32/64byte等,當調用malloc的時候,直接從cache的空閑小內存片分配;同時為了解決性能問題,分配器對每個線程或者每個cpu預留單獨的cache,每個線程從自己的cache中分配,可以減少線程之間的鎖競爭。
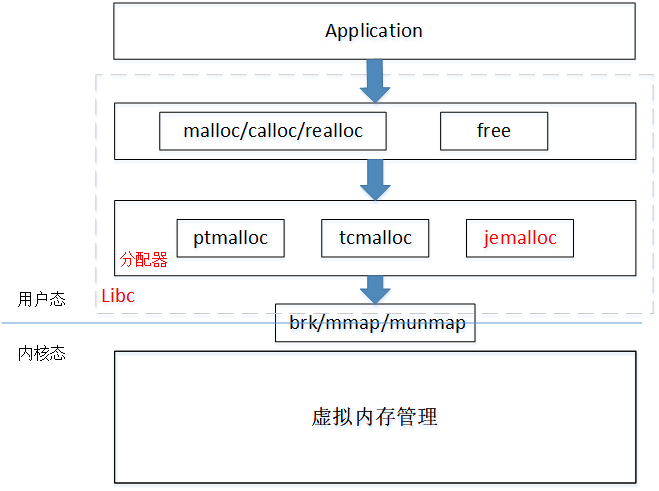
現在業界主流的分配器有ptmalloc、tcmalloc、jemalloc、scudo等。在Android系統中,為例提高兼容性和性能,malloc函數的實現,默認都是通過mmap系統調用分配內存,不再使用brk系統調用(部分三方APP自帶SDK可能會用brk)。Android現在用的分配器是jemalloc或者scudo,關于分配啟動實現本文不再贅述。
進程分配內存核心函數
本節介紹brk、mmap、munmap函數的實現所用到的幾個核心函數。
幾個關鍵的數據結構
在介紹進程如何分配到虛擬內存之前,先了解幾個進程內存管理相關的數據結構。
struct mm_struct
每個進程或內核線程都由一個任務描述數據結構(task_struct)來管理,每個task_struct中有個struct mm_strcut數據結構指針,用來管理任務的虛擬地址空間;而內核線程是沒有用戶態虛擬地址空間,所以其mm字段為NULL;mm的數據結構如下:



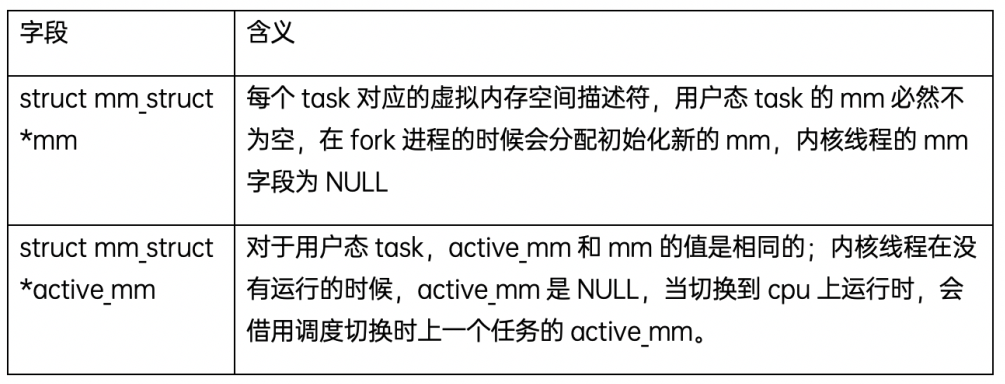
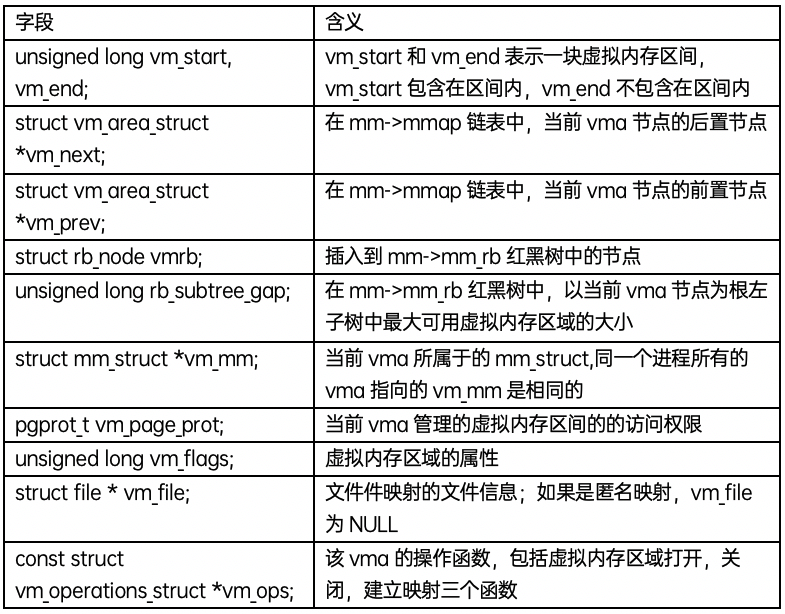
struct mm_struct是每個task的虛擬內存空間的描述符,例如用戶態進(線)程棧區間,堆區間的地址和大小等;每個進程只有一個mm,即使是多個線程的進程,所有的線程都是共享同一個mm,mm_struct數據結構中幾個關鍵字段的含義如下:
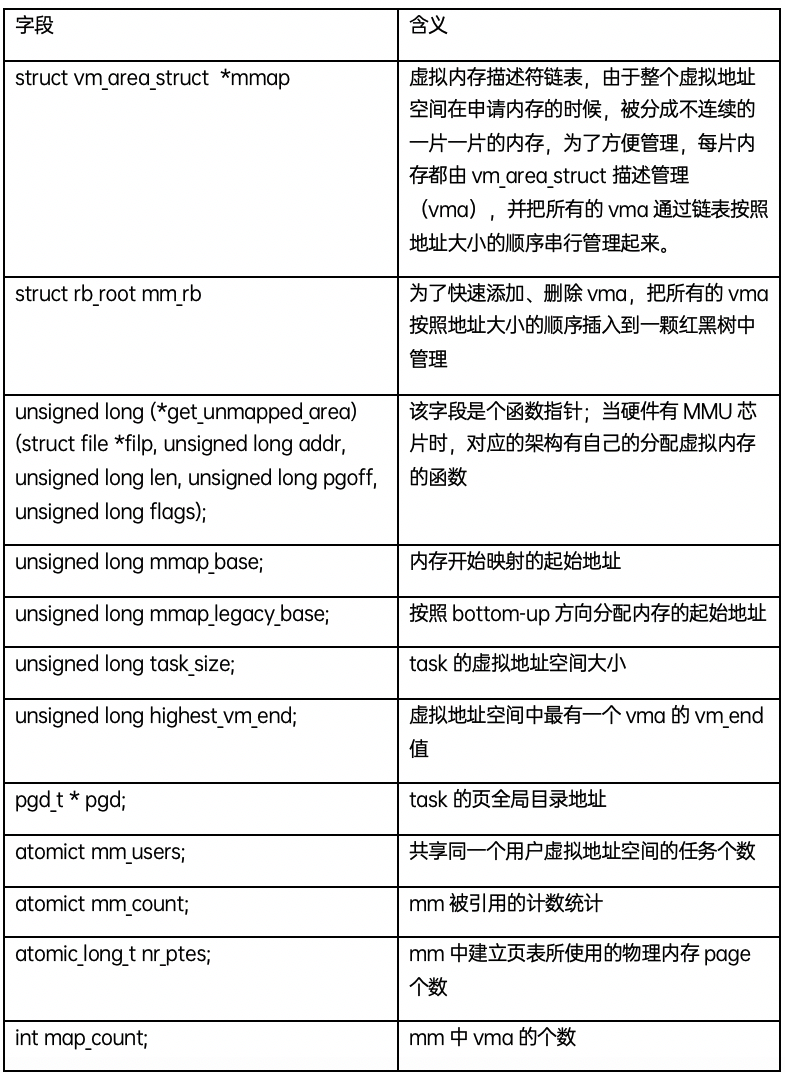
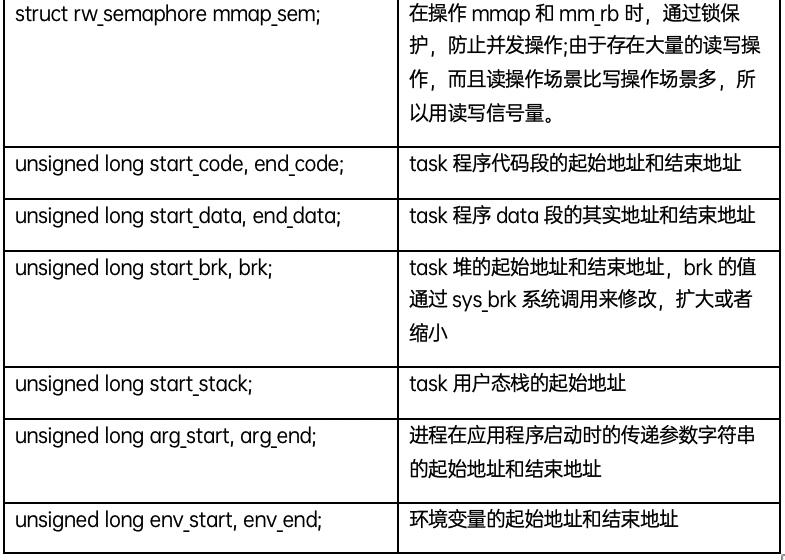
struct vm_area_struct
分配的每個虛擬內存區域都由一個vm_area_struct 數據結構來管理,包括虛擬內存的起始和結束地址,以及內存的訪問權限等,通常命名為vma;vm_area_struct 數據結構的定義如下:

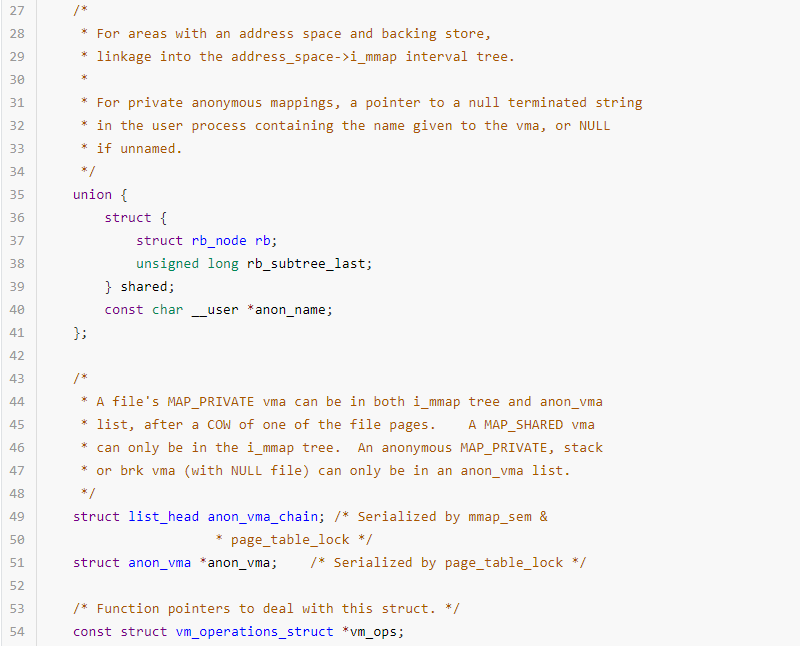

mm_struct和vm_area_struct描述的都是進程的虛擬地址空間,所謂的“虛擬”,意思是指進程有相應大小內存需求,一個虛擬內存地址區域表示該段內存已經分配出去,但是并不保證該地址空間已經映射物理內存,也不保證相應的物理頁在內存中。例如分配2MB的內存后,自始至終沒有訪問過這片內存,所以這2MB的內存只是占用了虛擬地址空間,沒有使用相應大小的物理內存。
當訪問一個未經映射的虛擬地址時,就會產生一個“Page Fault”事件(通常叫做缺頁異常),當前進程會被缺頁異常打斷而進入異常處理函數,在處理函數中,會從伙伴系統中分配一個page,與相應的虛擬地址建立映射,這個映射關系需要通過頁表來管理;同時頁表也需要單獨分配內存來保存,所以在計算一個進程使用的物理內存時,也要算上頁表的內存。
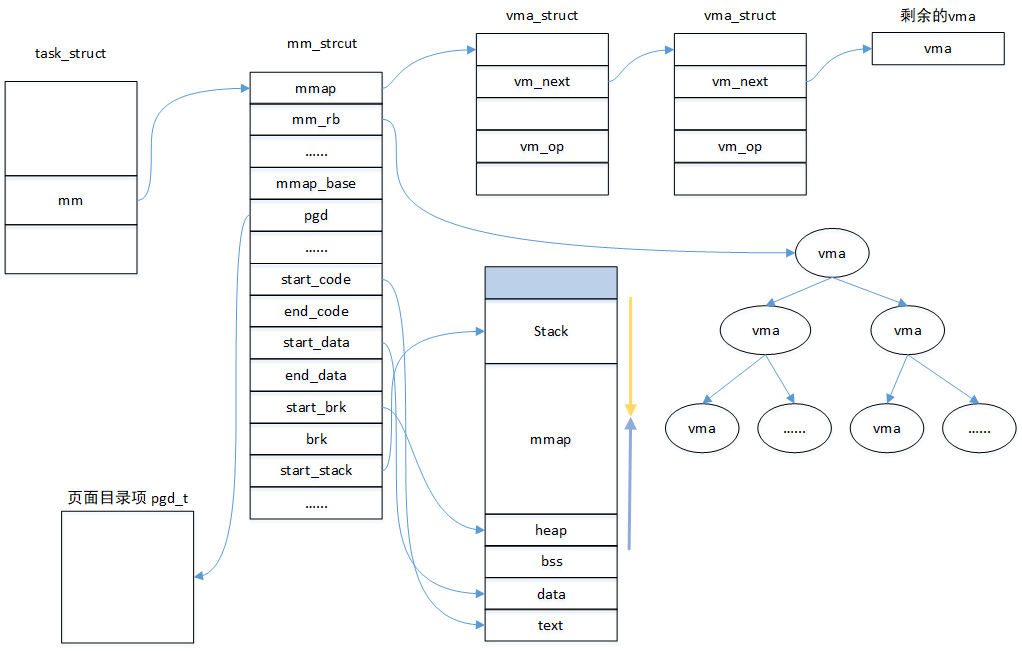
在一個mm中,所有的vma通過兩種結構管理一起來,一個是雙向鏈表,一個是紅黑樹。當遍歷這個虛擬地址空間時,通過雙向鏈表是常用的方法;當在虛擬地址空間查找vma是,通過紅黑樹查找是更便捷的方法。通常兩種方法會結合起來使用,例如通過紅黑樹查找到某個vma,后要找到該vma的前置,則直接通過vma->vm_prev就可以直接獲取。通過一個圖表展示一下幾個數據結構之間的關系:
幾個關鍵的函數
arch_pick_mmap_layout
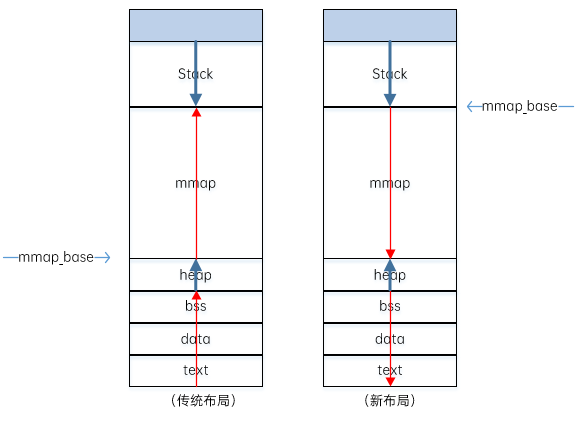
進程虛擬內存映射存在兩種布局方式,主要區別是mmap_base值和分配虛擬內存增長方向。
傳統布局
映射區域自底向上增長,mmap_base的值是TASK_UNMAPPED_BASE,ARM64架構中定義為TASK_SIZE/4。內核默認啟用內存映射區域隨機化,在該起始地址加上一個隨機值。傳統布局的缺點是堆的最大長度受到限制,例如_edata的值增長會受到mmap_base的限制,在32位系統中影響比較大,在64位系統中則不是緊急的問題。
新布局
內存映射區域自頂向下增長,mmap_base的值是(STACK_TOP – STACK_GAP)。默認啟用內存映射區域隨機化,需要把起始地址再減去一個隨機值。
兩種布局如下圖所示:
開啟地址隨機化
在進程調用execve以裝載ELF文件的時,load_elf_binary會創建進程的用戶虛擬地址空間。如果進程描述符的成員personality沒有設置標志位ADDR_NO_RANDOMIZE(該標志位表示禁止虛擬地址空間隨機化),并且全局變量randomize_va_space是非零值,那么給進程設置標志PF_RANDOMIZE,允許虛擬地址空間隨機化。

不同CPU架構內存映射區域的布局可能不一樣,所以不同arch都要實現自己的arch_pick_mmap_layout函數。ARM64架構定義的函數arch_pick_mmap_layout如下:
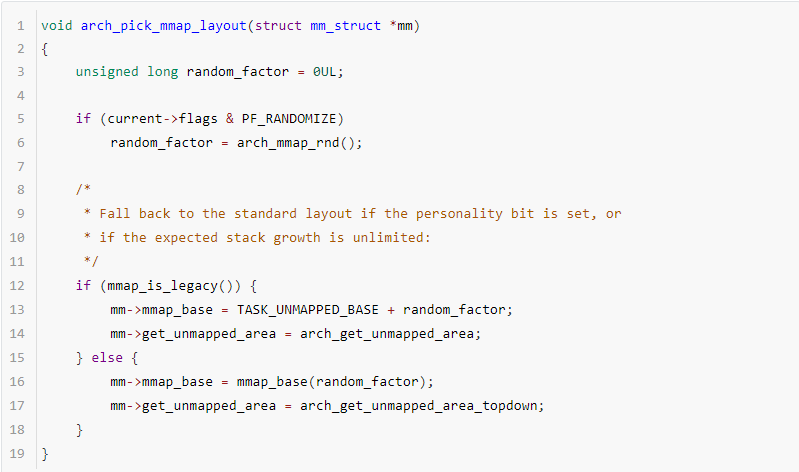
如果開啟了地址隨機化,則通過arch_mmap_rnd計算獲取一個隨機值;計算隨機值是有范圍的:
在傳統布局中,隨機范圍是[0, ((1UL << mmap_rnd_compat_bits) - 1)<
在新布局中,隨機值范圍[0,((1UL << mmap_rnd_bits) - 1)<
arch_get_unmapped_area 和 arch_get_unmapped_area_topdown函數都用到一個核心數據結構struct vm_unmapped_area_info,這個數據結構用于管理分配內存請求。
傳統布局,查找空閑內存的范圍是[mm->mmapbase, TASKSIZE],實現該功能的函數arch_get_unmapped_area代碼如下:
1.如果是文件映射分配內存,filp指向對應打開的文件描述數據結構,如果是匿名映射,filp為NULL。addr是建議分配內存起始地址,如果以addr開始的地址恰好是空閑的,且滿足本次分配需求則返回成功,參考15~22行代碼;如果不滿足需求,則初始化info,調用vm_unmapped_area函數來掃描mmap映射區域來查找滿足請求的內存。
2.len表示本次請求分配內存的長度。pgoff表示分配的內存映射到filp描述的文件中的偏移,如果是匿名映射,該參數是忽略的。flags表示本次分配內存的屬性和權限信息。
新布局中,遍歷內存的方法稍微不同,先看下代碼:
1.參數的含義與arch_get_unmapped_area相同
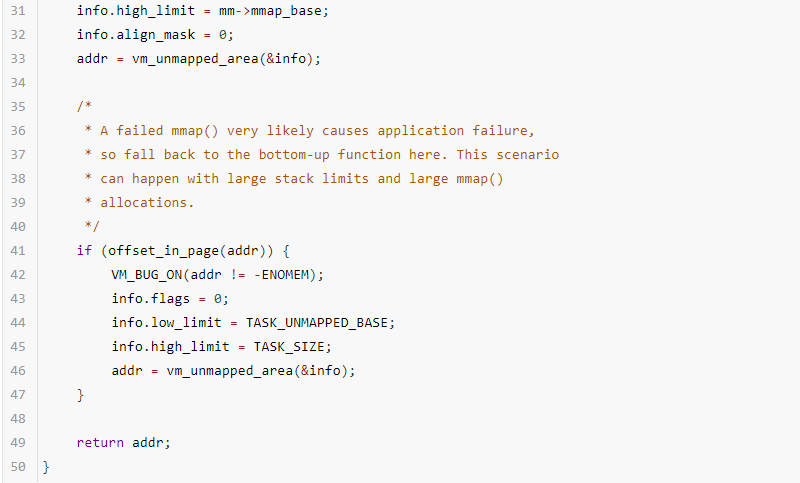
2.新的布局與傳統布局分配新內存的行為有差異,當從高到低的方向分配內存失敗的情況下,會再次從低到高的方向分配一次。28~32行代碼,設置flag為VM_UNMAPPED_AREA_TOPDOWN,并從mm->mmap_base到max(PAGESIZE, mmap_min_addr)從高地址向低地址分配一次,用offset_in_page判斷分配是否成功,由于在分配成功的情況下,分配的addr是page對齊的,所以addr的低12bit都是0,而如果addr的低12bit的值不是0,則說明分配失敗。
從41~46行代碼看出,flag已經設置為0(方向變成由低到高),同時遍歷的區間變成了[TASK_UNMAPPED_BASE, TASK_SIZE]。
unmapped_area
從vm_unmapped_area函數看出,unmapped_area實現由低到高的方向分配內存的方法,unmapped_area_topdown實現由高到低的方向分配內存的方法。
回顧一下,進程虛擬地址空間中所有vma按照地址從小到大的順序,分別記錄在一個雙向鏈表和一個紅黑樹里面,通過鏈表可以快速遍歷所有分配的內存信息,例如proc/$pid/maps和/proc/$pid/smaps兩個節點的實現;通過遍歷紅黑樹可以快速查找到包含指定地址的vma,例如分配內存時查找到空閑內存。
在vma的紅黑樹中,每個節點的左子樹上所有內存地址都小于其右子樹上的所有內存地址,傳統布局中采用中序遍歷的方式從根開始遍歷所有vma查找空閑內存,先從左子樹開始遍歷,直到找到最左邊的滿足分配需求的內存;如果在根的左子樹上面沒有找到,則開始遍歷右子樹,以右子樹為根遞歸遍歷;為了提高效率,每個vma的rb_subtree_gap值表示該樹最大的空閑內存大小,如果連根節點的rb_subtree_gap都不滿足分配需求,則說進程已經OOM;如果滿足需求,則開始遍歷找到滿足請求的空間并返回起始地址。
16~27行代碼首先對入參進行合法性判斷,其中16行代碼info->length + info->align_mask在length的基礎上加上對齊的mask,防止執行到最后由于對齊的問題導致分配失敗,但是此處也存在缺陷:空閑內存的長度和對齊方式恰好都滿足需求,而此處加上mask導致提前分配失敗,這是個極端情況,即使出現也說明空閑內存已經不充足。
30~31行代碼,當進程第一次進行內存分配時,紅黑樹最開始原本就是空的,說明此時空閑內存是充足的,所以直接跳到84行開始分配內存。
32~34行,獲取根節點的vma,并判斷rb_subtree_gap是否滿足分配需求,如果不滿足需求則只能查看最后一個vma->vm_end到虛擬地址空間最大值之間的內存是否滿足需求;由于從低向高方向分配內存時,紅黑樹最右側vma的結束地址與虛擬地址空間最大值之間的這段內存在紅黑樹中是沒有統計的,所以需要判斷一下。
36~82是核心代碼,首先從紅黑樹的根得知在樹種是可以找到滿足分配需求的內存的;從39行看出,vma->vm_rb.rb_left先從根的左子樹找起,gap_end >= low_limit說明空閑內存是在分配請求內存上下限之間的,那么繼續找左子樹,直到找到不滿足需求的vma,即(gap_end >= low_limit && vma->vm_rb.rb_left)條件不成立,有兩種情況,第一種,gap_end >= low_limit不成立說明現在vma已經超出需求上下限范圍;vma->vm_rb.rb_left不成立說明已經找到最左節點了,由于是由低到高的方向分配內存的,所以此時左邊沒有必要找了,接著判斷當前vma與vma->vm_prev之間的空間是否滿足需求(54~56行),如果當前vma不滿足則開始找當前vma的右子樹(59~67行),如果在當前vma子樹中沒有找到滿足需求的內存空間,則從上一層根子樹中查找。
84~89行代碼,當在紅黑樹中沒有找到滿足需求的內存時,判斷最后一個vma到虛擬地址空間最大值之間的空閑內存是否滿足需求,如果不滿足則說明oom了。92~101表示已經找到滿足需求的內存空間,其中97行堆起始地址進行對齊處理。
unmapped_area_topdown實現由高向低的方向分配內存,與unmapped_area區別是遍歷的方法變化了,先從右子樹遍歷查詢,再判斷根節點,最后從左子樹查詢,代碼不在這里介紹。
getunmappedarea
分配虛擬內存的時候,首先需要找到一塊空閑的滿足分配需求的內存空間,調用的函數是get_unmapped_area,代碼如下:
1.參數共5個
struct file *file,如果是匿名映射,file為NULL;如果是文件映射,file不能為空,則表示分配的內存即將映射file中的內容。
unsigned long addr,表示要分配內存的起始地址。
當addr為0時,在整個虛擬地址空間中找到滿足需求的空閑內存,對起始地址沒有特殊要求。
unsigned long len, 要分配內存的長度,長度單位是Byte,不足PAGE_SIZE按PAGE_SIZE處理。
unsigned long pgoff,分配的內存,映射文件內容在文件中的起點。
unsigned long flags, 指定映射對象的屬性,映射選項和映射頁是否可以共享,LOCKED等屬性。
2.代碼分析
第8行,arch_mmap_check是個各個架構實現的mmap校驗函數,主要是對固定映射,addr有大小限制,arm64架構定義為空。
13~14行,校驗len大小,如果超過TASK_SIZE則明顯溢出,直接返回。
16~28行,給函數指針get_area賦值,初始值為current->mm->get_unmapped_area,當本次分配是文件映射分配內存,需要判斷file->f_op->get_unmapped_area是否為NULL,如果不為NULL則賦值給get_area,這么操作的原因是部分文件系統文件映射分配虛擬內存時有特殊的要求或操作,例如flags、len等客制化處理等;如果是匿名映射且配置了MAP_SHARED,則賦值shmem_get_unmapped_area給get_area。
30~37行,調用get_area分配新的映射空間,然后校驗分配的地址是否有效,其中offset_in_page函數判斷的原理是:如果分配成功,addr的值一定是PAGE_ALIGN的,如果addr低12bit不為0,則說明分配失敗。
39行,安全檢查addr,security_mmap_addr函數是Linux Security Module中函數,這里不詳細介紹。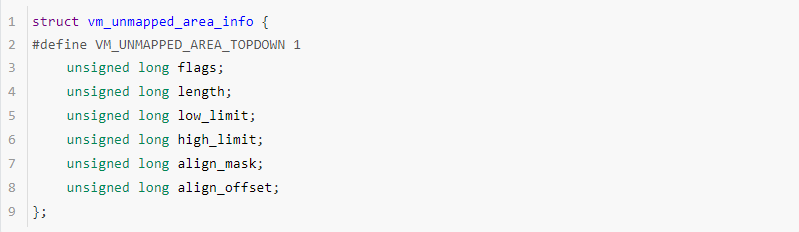







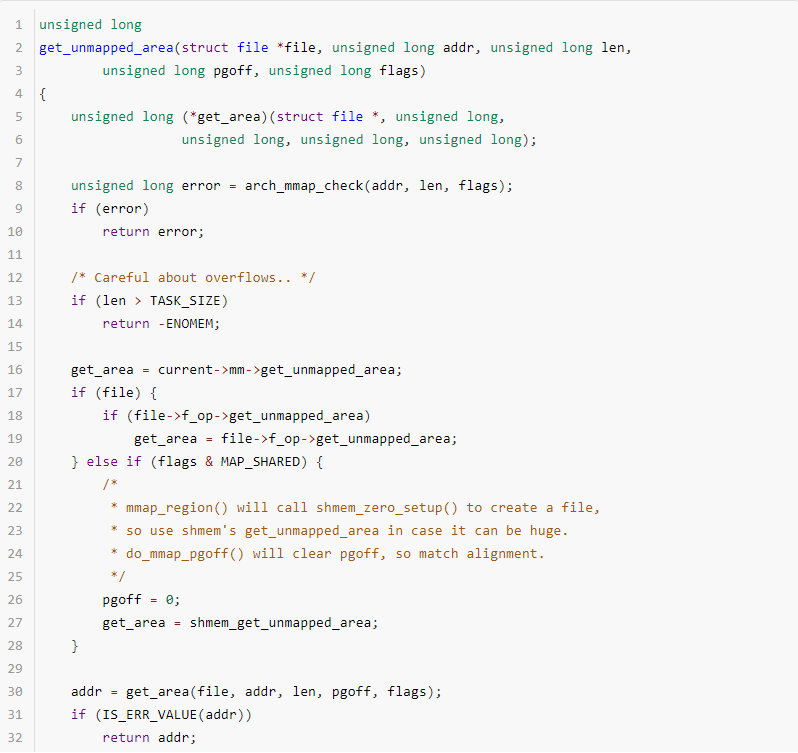
當addr不為0時,如果該地址起始的內存恰好滿足需求,返回addr;如果flasgs配置了MAP_FIXED,則不會判斷是否滿足直接返回addr;
-
Linux
+關注
關注
88文章
11758瀏覽量
219001 -
內存管理
+關注
關注
0文章
171瀏覽量
14878
原文標題:進程內存管理初探
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
飛凌嵌入式ElfBoard-進程之什么是進程
RDMA設計37:RoCE v2 子系統模型設計
【「Linux 設備驅動開發(第 2 版)」閱讀體驗】充分發揮硬件潛力
飛凌嵌入式ElfBoard-進程之什么是進程
keil中c語言的動態分配內存
【「Linux 設備驅動開發(第 2 版)」閱讀體驗】+讀深入理解Linux內核內存分配
進程概念和特征
解析Linux的進程、線程和協程
三種類型內存的使用
為什么單片機中很少使用malloc,而PC程序頻繁使用呢?
Perforce QAC 2025.2版本更新:虛擬內存優化、100%覆蓋CERT C規則、CI構建性能提升等

工業APP頻繁崩潰?聚徽廠家分享安卓工控機內存碎片化與進程管理優化指南
golang內存分配



 工商網監
工商網監
評論