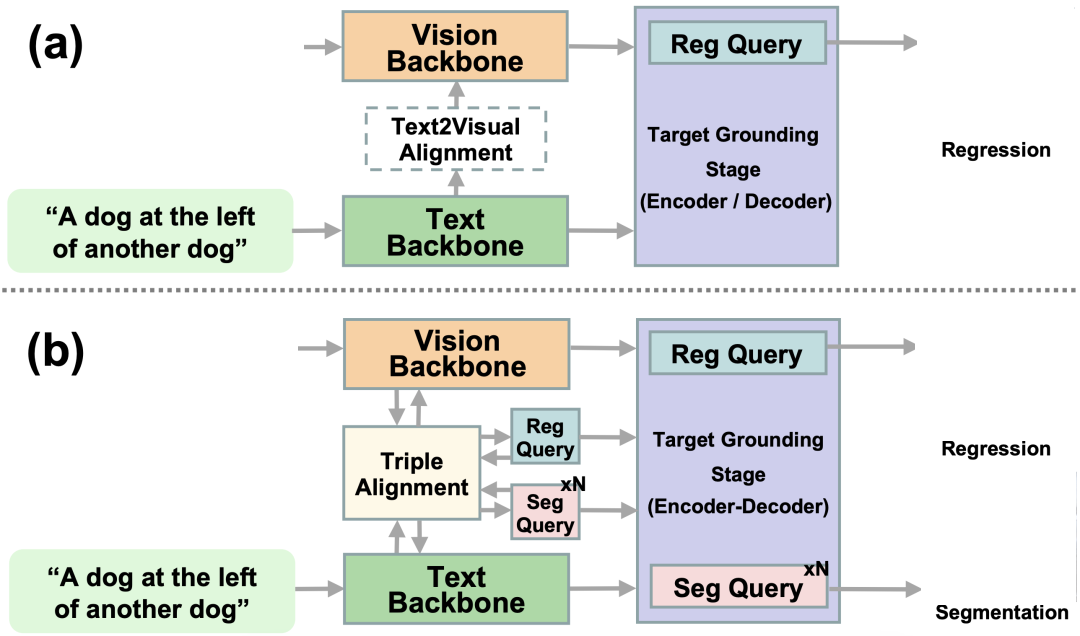
Vision Mamba:速度與內(nèi)存的雙重突破
為了進(jìn)一步評估研究方法在下游任務(wù)上(即分割、檢測和實例分割)的效率,本文將骨干網(wǎng)與常用的特征金字塔網(wǎng)....
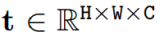
Adobe提出DMV3D:3D生成只需30秒!讓文本、圖像都動起來的新方法!
因此,本文研究者的目標(biāo)是實現(xiàn)快速、逼真和通用的 3D 生成。為此,他們提出了 DMV3D。DMV3D....

高分工作!Uni3D:3D基礎(chǔ)大模型,刷新多個SOTA!
我們主要探索了3D視覺中scale up模型參數(shù)量和統(tǒng)一模型架構(gòu)的可能性。在NLP / 2D vis....

ICLR 2024 清華/新國大/澳門大學(xué)提出一模通吃的多粒度圖文組合檢索MUG:通過不確定性建模,兩行代碼完成部署
如上圖所示,不再采用嚴(yán)格的一對一匹配,而是促使模型專注于一對多匹配,即從細(xì)粒度過渡到粗粒度。因此,首....

Harvard FairSeg:第一個用于醫(yī)學(xué)分割的公平性數(shù)據(jù)集
為了解決這些挑戰(zhàn),我們提出了第一個大規(guī)模醫(yī)學(xué)分割領(lǐng)域的公平性數(shù)據(jù)集, Harvard-FairSeg....

谷歌MIT最新研究證明:高質(zhì)量數(shù)據(jù)獲取不難,大模型就是歸途
另一個極端是,監(jiān)督學(xué)習(xí)方法(即SupCE)會將所有這些圖像視為單一類(如「金毛獵犬」)。這就忽略了這....

頂刊TIP 2023!浙大提出:基于全頻域通道選擇的的無監(jiān)督異常檢測
Density-based方法:基于密度的方法通常采用預(yù)訓(xùn)練的模型來提取輸入圖像的有意義嵌入向量,測....

北京大學(xué)提出Repaint123:紋理質(zhì)量、多視角一致性新SOTA!
之前,將圖像轉(zhuǎn)換為3D的方法通常采用Score Distillation Sampling (SDS....

4DGen:基于動態(tài)3D高斯的可控4D生成新工作
盡管3D和視頻生成取得了飛速的發(fā)展,由于缺少高質(zhì)量的4D數(shù)據(jù)集,4D生成始終面臨著巨大的挑戰(zhàn)。
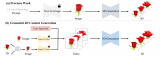
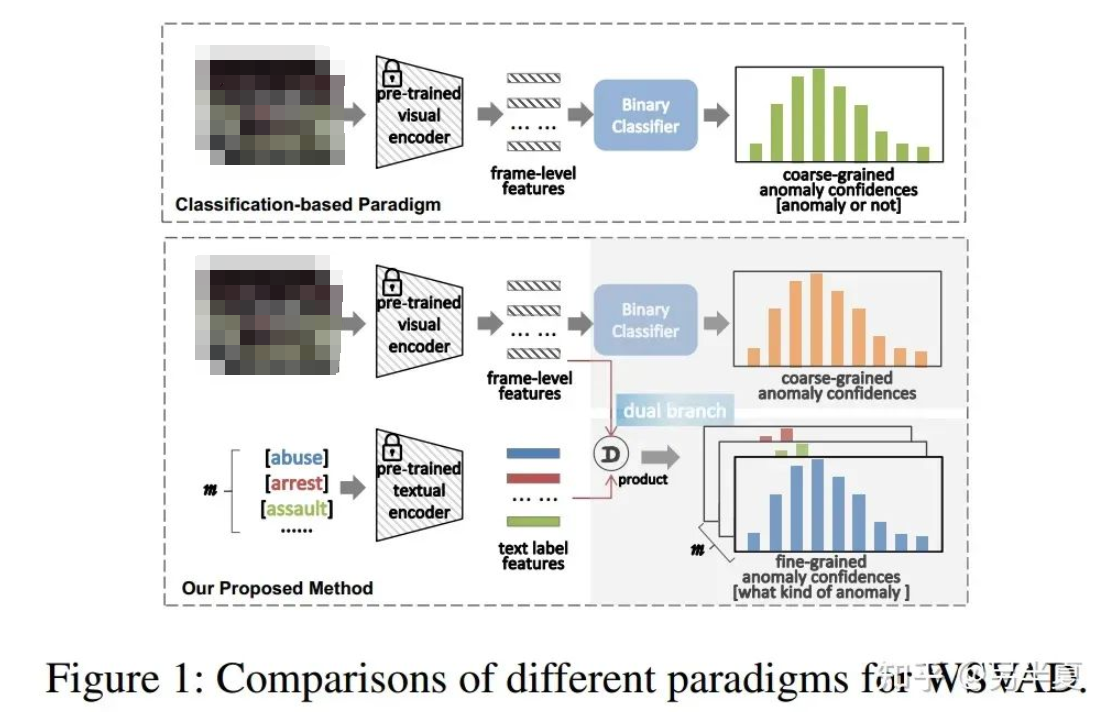
語言模型的弱監(jiān)督視頻異常檢測方法
LGT Adapter由局部關(guān)系Transformer和全局關(guān)系圖卷積串聯(lián)組成。考慮到常規(guī)的Tran....

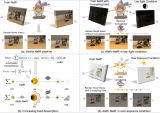
Aleth-NeRF:低光增強與曝光糾正的新方向!不良光照場景下的新視角合成
最經(jīng)典的原始NeRF為例,局部隱蔽場通過NeRF的MLP網(wǎng)絡(luò)產(chǎn)生,與原始NeRF的兩個輸出color....

更強!Alpha-CLIP:讓CLIP關(guān)注你想要的任何地方!
然而CLIP必須以整張圖片作為輸入并進(jìn)行特征提取,無法關(guān)注到指定的任意區(qū)域。然而,自然的2D圖片中往....

何愷明新作RCG:無自條件圖像生成新SOTA!與MIT首次合作!
它有望超越條件圖像生成,并推動諸如分子設(shè)計或藥物發(fā)現(xiàn)這種不需要人類給注釋的應(yīng)用往前發(fā)展(這也是為什么....
計算機視覺迎來GPT時刻!UC伯克利三巨頭祭出首個純CV大模型!
在損失函數(shù)上,研究者從自然語言社區(qū)汲取靈感,即掩碼 token 建模已經(jīng)「讓位給了」序列自回歸預(yù)測方....

超分畫質(zhì)大模型!華為和清華聯(lián)合提出CoSeR:基于認(rèn)知的萬物超分大模型
一是缺乏泛化能力。為了實現(xiàn)更好的超分效果,通常需要針對特定場景使用特定傳感器采集到的數(shù)據(jù)來進(jìn)行模型訓(xùn)....

低成本擴大輸入分辨率!華科大提出Monkey:新的多模態(tài)大模型
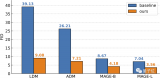
下圖展示了Monkey的卓越性能,在 18 個不同的數(shù)據(jù)集上進(jìn)行測試的結(jié)果表明,Monkey能夠很好....



小模型也能進(jìn)行上下文學(xué)習(xí)!字節(jié)&華東師大聯(lián)合提出自進(jìn)化文本識別器
場景文本識別(Scene Text Recognition)的目標(biāo)是將圖像中的文本內(nèi)容提取出來。實際....

通過擴散模型理解不可學(xué)習(xí)樣本對于數(shù)據(jù)隱私保護(hù)的脆弱性
一個直接的解決方案是設(shè)計一個特定的訓(xùn)練方案,可以在不可利用的數(shù)據(jù)上進(jìn)行訓(xùn)練。這是不太理想的,因為它只....
通過擴散模型理解不可學(xué)習(xí)樣本對于數(shù)據(jù)隱私保護(hù)的脆弱性
在深度學(xué)習(xí)領(lǐng)域,網(wǎng)絡(luò)上充斥著大量可自由訪問的數(shù)據(jù),其中包括像ImageNet和MS-Celeb-1M....
哈工大提出Myriad:利用視覺專家進(jìn)行工業(yè)異常檢測的大型多模態(tài)模型
最近,大型多模態(tài)(即視覺和語言)模型(LMM)在圖像描述、視覺理解、視覺推理等多種視覺任務(wù)上表現(xiàn)出了....

谷歌新作UFOGen:通過擴散GAN實現(xiàn)大規(guī)模文本到圖像生成
擴散模型和 GAN 的混合模型最早是英偉達(dá)的研究團(tuán)隊在 ICLR 2022 上提出的 DDGAN(《....


RayDF:實時渲染!基于射線的三維重建新方法
在機器視覺和機器人領(lǐng)域的許多前沿應(yīng)用中,學(xué)習(xí)準(zhǔn)確且高效的三維形狀表達(dá)是十分重要的。然而,現(xiàn)有的基于三....




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)