 谷歌MIT最新研究證明:高質量數據獲取不難,大模型就是歸途
谷歌MIT最新研究證明:高質量數據獲取不難,大模型就是歸途

【導讀】數據獲取最新解,便是從生成模型中學習。
獲取高質量數據,已經成為當前大模型訓練的一大瓶頸。
前幾天,OpenAI被《紐約時報》起訴,并要求索賠數十億美元。訴狀中,列舉了GPT-4抄襲的多項罪證。
甚至,《紐約時報》還呼吁摧毀幾乎所有的GPT等大模型。

一直以來,AI界多位大佬認為「合成數據」或許是解決這個問題的最優解。

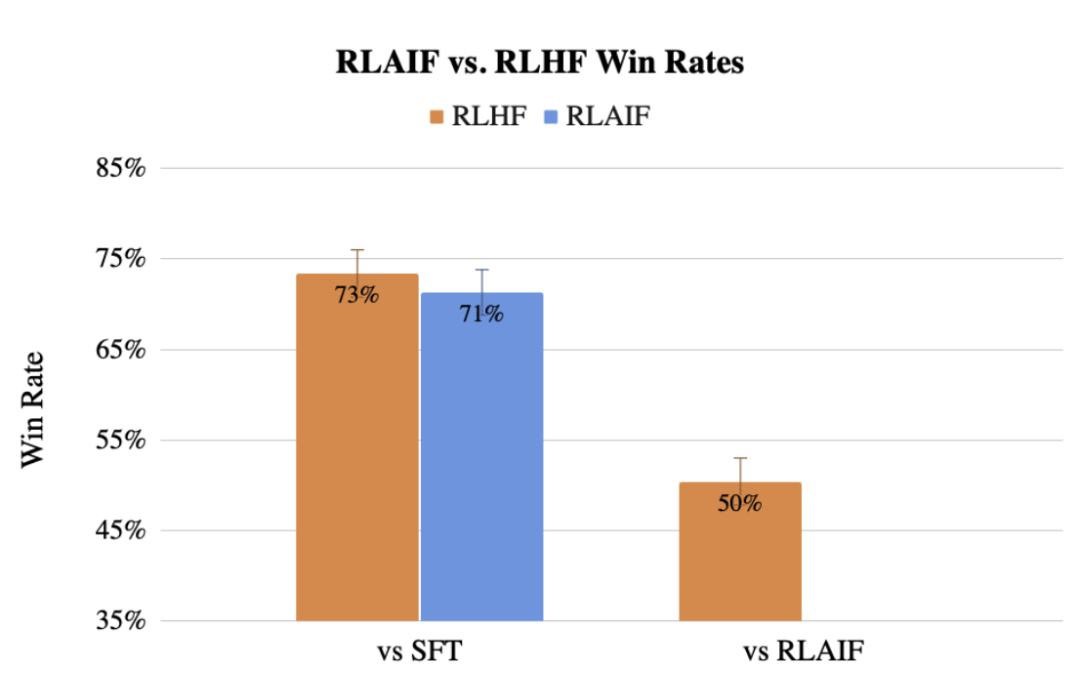
此前,谷歌團隊還提出了用LLM代替人類標記偏好的方法RLAIF,效果甚至不輸人類。
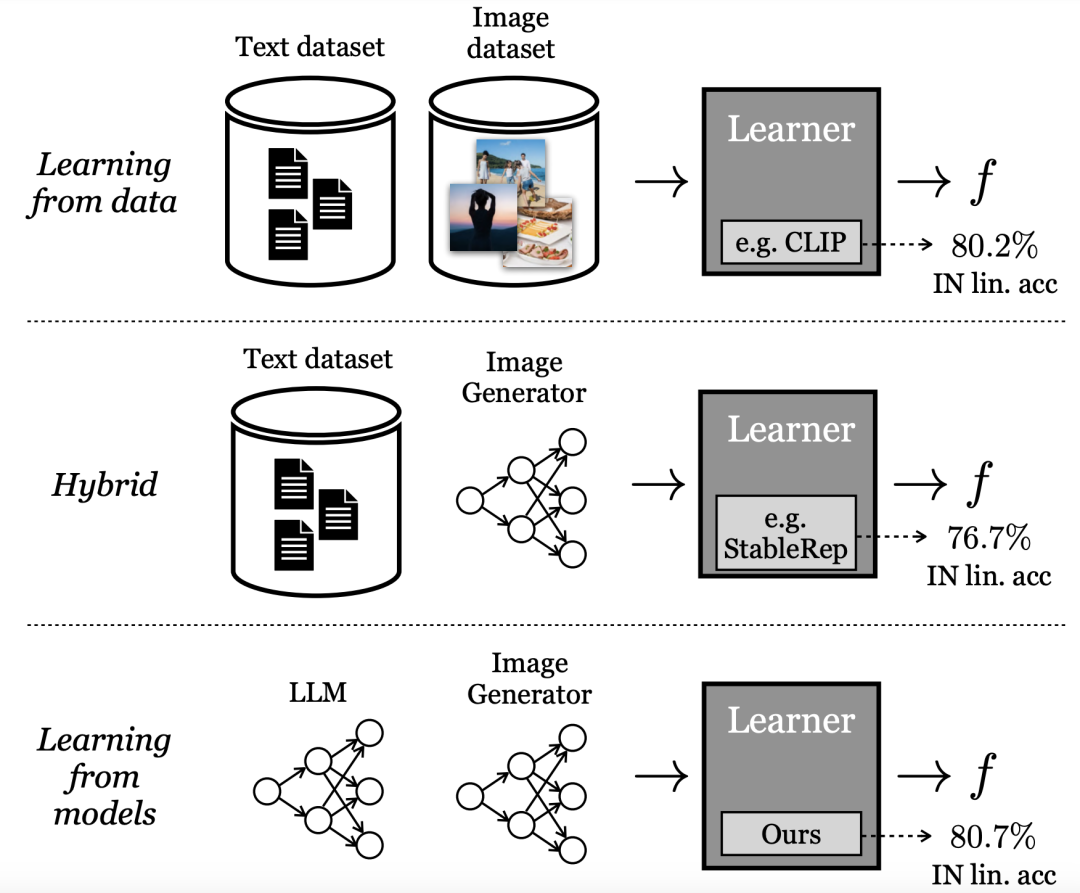
現如今,谷歌MIT的研究人員發現,從大模型中學習可以得到使用真實數據訓練的最佳模型的表征。
這一最新方法稱SynCLR,一種完全從合成圖像和合成描述學習虛擬表征的方法,無需任何真實數據。

論文地址:https://arxiv.org/abs/2312.17742
實驗結果表明,通過SynCLR方法學習到的表征,能夠與OpenAI的CLIP在ImageNet 上的傳輸效果一樣好。
從生成模型中學習
目前表現最好的「視覺表征」學習方法依賴于大規模的實際數據集。然而,真實數據的收集卻有不少的困難。
為了降低收集數據的成本,研究人員本文中提出了一個問題:
從現成的生成模型中采樣的合成數據,是否是一條通往大規模策劃數據集的可行之路,從而訓練出最先進的視覺表征?
與直接從數據中學習不同,谷歌研究人員稱這種模式為「從模型中學習」。作為建立大規模訓練集的數據源,模型有幾個優勢:
- 通過其潛在變量、條件變量和超參數,為數據管理提供了新的控制方法。
- 模型也更容易共享和存儲(因為模型比數據更容易壓縮),并且可以產生無限數量的數據樣本。
越來越多的文獻研究了生成模型的這些特性和其他優點和缺點,并將其作為訓練下游模型的數據源。
其中一些方法采用混合模式,即混合真實數據集和合成數據集,或需要一個真實數據集來生成另一個合成數據集。
其他方法試圖從純粹的「合成數據」中學習表征,但遠遠落后于表現最好的模型。
論文中,研究人員提出的最新方法,使用生成模型重新定義可視化類的粒度。
如圖2所示,使用2個提示生成了四張圖片「一只戴著墨鏡和沙灘帽的金毛獵犬騎著自行車」和「一只可愛的金毛獵犬坐在壽司做成的房子里」。
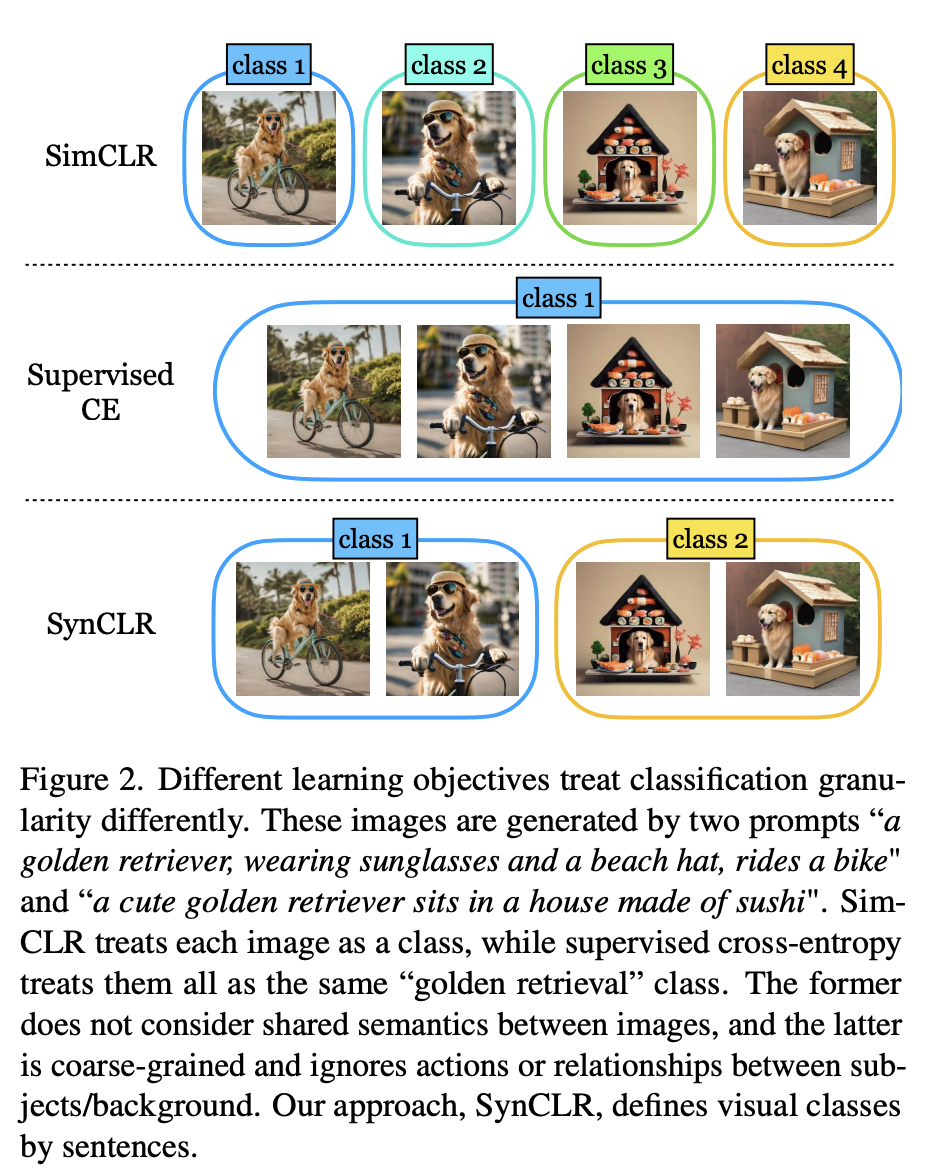
傳統的自監督方法(如Sim-CLR)會將這些圖像視為不同的類,不同圖像的嵌入會被分開,而不會明確考慮圖像之間的共享語義。
另一個極端是,監督學習方法(即SupCE)會將所有這些圖像視為單一類(如「金毛獵犬」)。這就忽略了這些圖像在語義上的細微差別,例如在一對圖像中狗在騎自行車,而在另一對圖像中狗坐在壽司屋內。
相反,SynCLR方法將描述視為類,即每個描述一個可視化類。
這樣,我們就可以按照「騎自行車」和「坐在壽司店里」這兩個概念對圖片進行分組。
這種粒度很難在真實數據中挖掘,因為收集由給定描述的多張圖片并非易事,尤其是當描述數量增加時。
然而,文本到圖像的擴散模型從根本上就具備這種能力。
只需對相同的描述設定條件,并使用不同的噪聲輸入,文本到圖像的擴散模型就能生成與相同描述相匹配的不同圖像。
具體來說,作者研究了在沒有真實圖像或文本數據的情況下,學習視覺編碼器的問題。
最新方法依賴3個關鍵資源的利用:一個語言生成模型(g1),一個文本到圖像的生成模型(g2),以及一個經過整理的視覺概念列表(c)。
前處理包括三個步驟:
(1)使用(g1)合成一組全面的圖像描述T,其中涵蓋了C中的各種視覺概念;
(2)對于T中的每個標題,使用(g2)生成多個圖像,最終生成一個廣泛的合成圖像數據集X;
(3)在X上進行訓練,以獲得視覺表示編碼器f。
然后,分別使用llama-27b和Stable Diffusion 1.5作為(g1)和(g2),因為其推理速度很快。
合成描述
為了利用強大的文本到圖像模型的能力,來生成大量的訓練圖像數據集,首先需要一個不僅精確描述圖像而且展示多樣性的描述集合,以包含廣泛的視覺概念。
對此,作者開發了一種可擴展的方法來創建如此大量的描述集,利用大模型的上下文學習能力。
如下展示了三個合成模板的示例。

如下是使用Llama-2生成上下文描述,研究人員在每次推理運行中隨機抽取三個上下文示例。
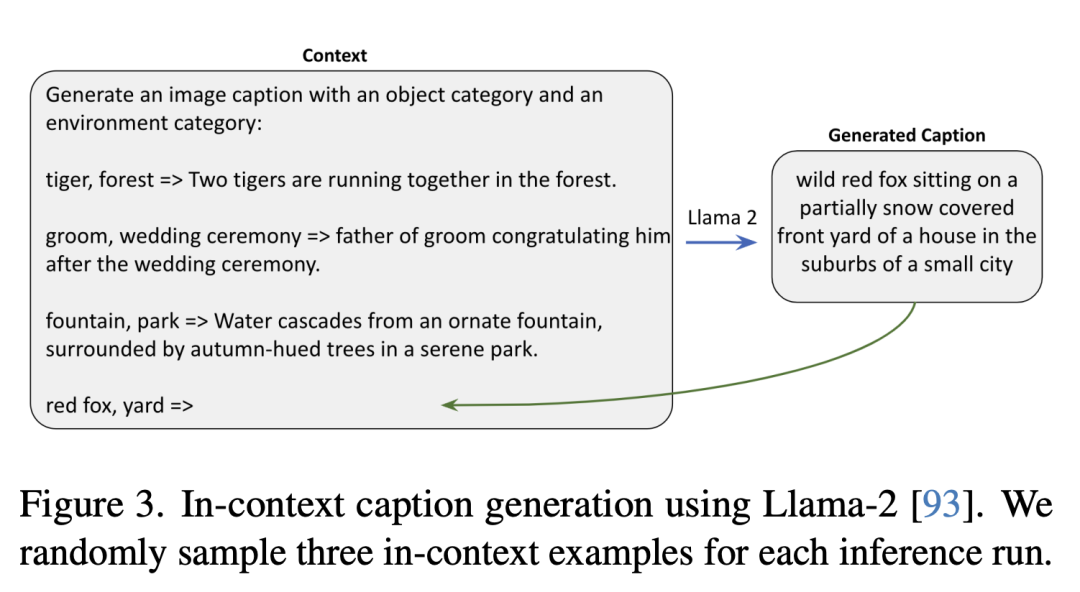
合成圖像
對于每個文本描述,研究人員都會用不同的隨機噪聲啟動反向擴散過程,從而生成各種圖像。
在此過程中,無分類器引導(CFG)比例是一個關鍵因素。
CFG標度越高,樣本的質量和文本與圖像之間的一致性就越好,而標度越低,樣本的多樣性就越大,也就越符合基于給定文本的圖像原始條件分布。

表征學習
論文中,表征學習的方法建立在StableRep的基礎上。
作者提出的方法的關鍵組成部分是多正對比學習損失,它的工作原理是對齊(在嵌入空間)從同一描述生成的圖像。
另外,研究中還結合了其他自監督學習方法的多種技術。
與OpenAI的CLIP相媲美
實驗評估中,研究人員首先進行消融研究,以評估管道內各種設計和模塊的有效性,然后繼續擴大合成數據的量。
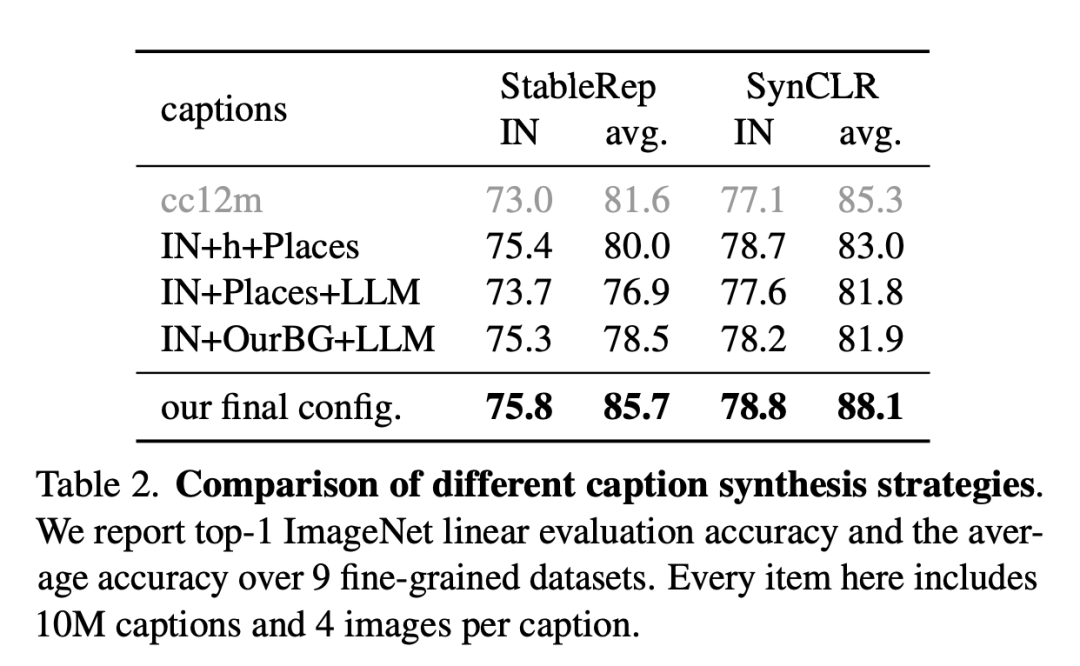
下圖是不同描述合成策略的比較。
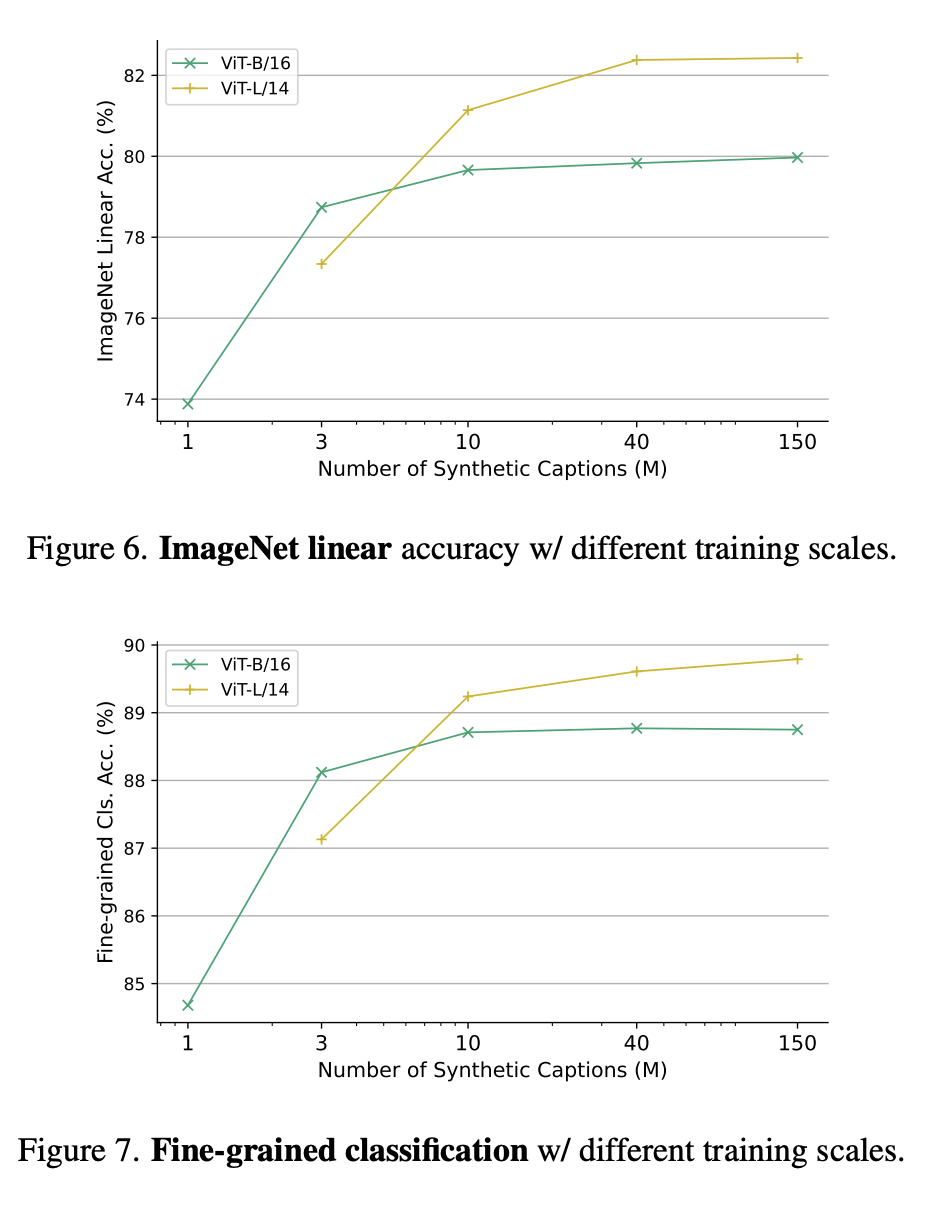
研究人員報告了9個細粒度數據集的ImageNet線性評估準確性和平均準確性。這里的每個項目包括1000萬個描述和每個描述4張圖片。
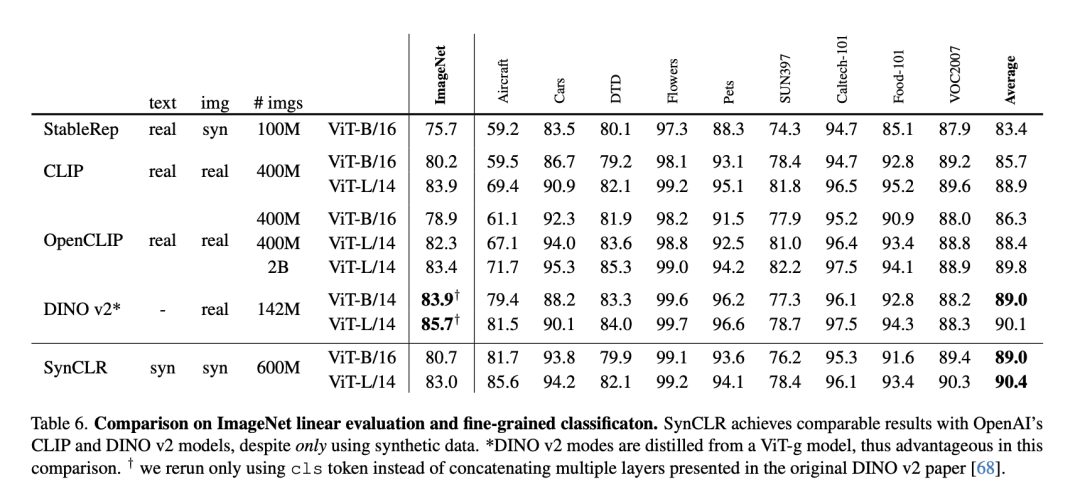
下表是ImageNet線性評估與細粒度分類的比較。
盡管只使用了合成數據,但SynCLR與OpenAI的CLIP和DINO v2模型取得了不相上下的結果。
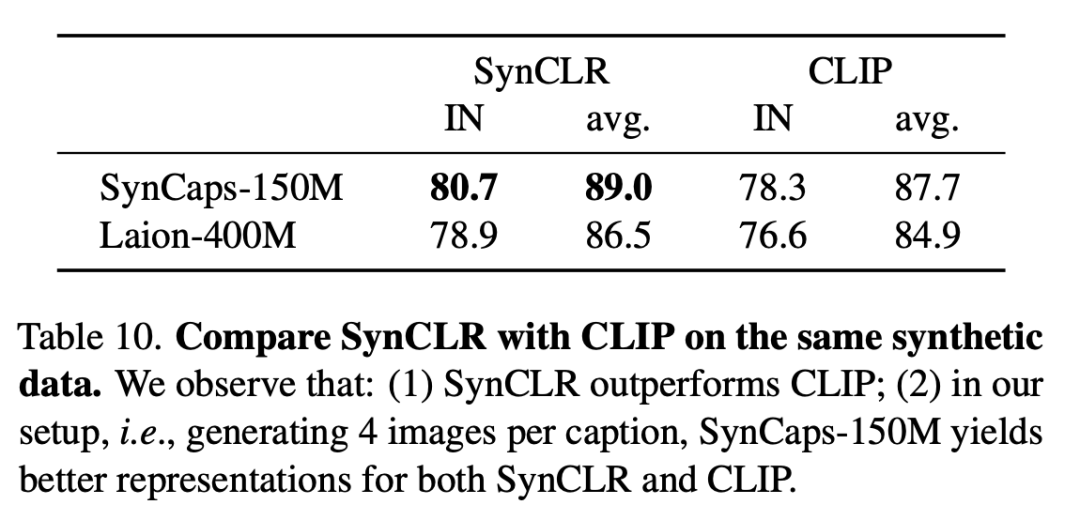
下表是在相同的合成數據上比較SynCLR和CLIP,可以看出,SynCLR明顯優于CLIP。
具體設置為,每個標題生成4個圖像,SynCaps-150M為SynCLR和CLIP提供了更好的表示。
PCA可視化如下。按照DINO v2,研究人員計算了同一組圖像的斑塊之間的PCA,并根據其前3個分量進行著色。
與DINO v2相比,SynCLR對汽車和飛機的繪制的圖更為準確,而對能繪制的圖則稍差一些。

圖6和圖7中,分別展示了不同訓練規模下的ImageNet線性準確率,以及不同訓練參數規模下的精細分類。
為什么要從生成模型中學習?
一個令人信服的原因是,生成模型可以像數百個數據集一樣同時運作,能夠為策劃訓練數據提供了一種方便有效的方法。
總而言之,最新論文研究了視覺表征學習的新范式——從生成模型中學習。
在沒有使用任何實際數據的情況下,SynCLR學習到的視覺表征,與最先進的通用視覺表征學習器學習到的視覺表征不相上下。
-
模型
+關注
關注
1文章
3752瀏覽量
52112 -
GPT
+關注
關注
0文章
368瀏覽量
16878 -
OpenAI
+關注
關注
9文章
1245瀏覽量
10077 -
大模型
+關注
關注
2文章
3650瀏覽量
5188
原文標題:谷歌MIT最新研究證明:高質量數據獲取不難,大模型就是歸途
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
聲智科技亮相2026海淀區經濟社會高質量發展大會
天合光能亮相2025光伏產業高質量發展與技術標準論壇

PCBA工程師必看:高質量BOM的5個‘隱形規則’
中科曙光入選信通院2025上半年度高質量數字化轉型十大典型案例
標貝科技參編《人工智能高質量數據集建設指南》
易華錄入選國家首批高質量數據集建設先行先試工作名單
索尼重載設備的高質量遠程制作方案和應用(2)

索尼重載設備的高質量遠程制作方案和應用(1)
大模型時代,如何推進高質量數據集建設?
從芯片到主板,科技創新實現高質量發展

賦能民營經濟 共促高質量發展

淺析:數字經濟時代,高質量數據集對AI產業帶來哪些新的變化
高質量 HarmonyOS 權限管控流程



 工商網監
工商網監
評論