

State of GPT:大神Andrej揭秘OpenAI大模型原理和訓練過程
你可以看到,Llama 的參數(shù)數(shù)量大概是 650 億。現(xiàn)在,盡管與 GPT3 的 1750 億個參數(shù)....


大模型LLM領域,有哪些可以作為學術研究方向?
隨著全球大煉模型不斷積累的豐富經(jīng)驗數(shù)據(jù),人們發(fā)現(xiàn)大模型呈現(xiàn)出很多與以往統(tǒng)計學習模型、深度學習模型、甚....


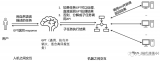
調(diào)教LLaMA類模型沒那么難,LoRA將模型微調(diào)縮減到幾小時
最近幾個月,ChatGPT 等一系列大語言模型(LLM)相繼出現(xiàn),隨之而來的是算力緊缺日益嚴重。雖然....

“AI教父”Geoffrey Hinton:智能進化的下一個階段
十年來,人工智能領域的眾多驚人突破背后都離不開深度學習,它是使得ChatGPT、AlphaGo等得以....


上交清華提出中文大模型的知識評估基準C-Eval,輔助模型開發(fā)而非打榜
首先,把一個模型調(diào)成一個對話機器人這件事情并不難,開源界已經(jīng)有了類似于 Alpaca, Vicuna....

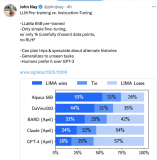
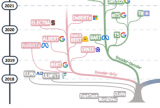



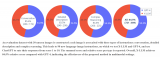
邱錫鵬團隊提出具有內(nèi)生跨模態(tài)能力的SpeechGPT,為多模態(tài)LLM指明方向
大型語言模型(LLM)在各種自然語言處理任務上表現(xiàn)出驚人的能力。與此同時,多模態(tài)大型語言模型,如 G....

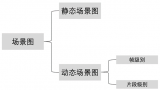
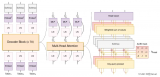

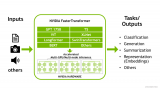
如何使用FasterTransformer進行單機及分布式模型推理
最近幾個月,隨著ChatGPT的現(xiàn)象級表現(xiàn),大模型如雨后春筍般涌現(xiàn)。而模型推理是抽象的算法模型觸達具....
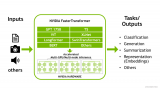
中科院針對NL2Code任務,調(diào)研了27個大模型,并指出5個重要挑戰(zhàn)
關于NL2Code的發(fā)展,其實和自然語言理解的發(fā)展類似,一開始,基本都是基于專家規(guī)則進行算法設計,但....





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)