文章
-
量子機(jī)器學(xué)習(xí)入門:三種數(shù)據(jù)編碼方法對(duì)比與應(yīng)用2025-09-15 10:27
 在傳統(tǒng)機(jī)器學(xué)習(xí)中數(shù)據(jù)編碼確實(shí)相對(duì)直觀:獨(dú)熱編碼處理類別變量,標(biāo)準(zhǔn)化調(diào)整數(shù)值范圍,然后直接輸入模型訓(xùn)練。整個(gè)過程更像是數(shù)據(jù)清洗,而非核心算法組件。量子機(jī)器學(xué)習(xí)的編碼完全是另一回事。傳統(tǒng)算法可以直接消化特征向量[0.7,1.2,-0.3],但量子電路運(yùn)行在概率幅和量子態(tài)的數(shù)學(xué)空間里。你的每個(gè)編碼決策——是用角度旋轉(zhuǎn)、振幅映射還是基態(tài)表示——都在重新定義信息在量子
在傳統(tǒng)機(jī)器學(xué)習(xí)中數(shù)據(jù)編碼確實(shí)相對(duì)直觀:獨(dú)熱編碼處理類別變量,標(biāo)準(zhǔn)化調(diào)整數(shù)值范圍,然后直接輸入模型訓(xùn)練。整個(gè)過程更像是數(shù)據(jù)清洗,而非核心算法組件。量子機(jī)器學(xué)習(xí)的編碼完全是另一回事。傳統(tǒng)算法可以直接消化特征向量[0.7,1.2,-0.3],但量子電路運(yùn)行在概率幅和量子態(tài)的數(shù)學(xué)空間里。你的每個(gè)編碼決策——是用角度旋轉(zhuǎn)、振幅映射還是基態(tài)表示——都在重新定義信息在量子 -
Imagination亮相汽車芯片產(chǎn)業(yè)大會(huì) 深入解讀高安全GPU+AI融合計(jì)算架構(gòu)2025-09-12 18:10
9月12日,由蓋世汽車主辦的2025第五屆全球汽車芯片產(chǎn)業(yè)大會(huì)在上海啟幕。本次大會(huì)以“芯”動(dòng)汽車智引未來為主題,圍繞車規(guī)級(jí)芯片標(biāo)準(zhǔn)與安全認(rèn)證、車企自研芯片、智能輔助駕駛芯片、高算力智能座艙SoC等熱門話題展開深度交流與探討。Imagination技術(shù)總監(jiān)艾克出席活動(dòng),發(fā)表了《驅(qū)動(dòng)未來:面向智能駕艙的高安全GPU+AI融合計(jì)算架構(gòu)》的主題演講。艾克首先介紹了目 -
小白學(xué)大模型:大模型加速的秘密 FlashAttention 1/2/32025-09-10 09:28
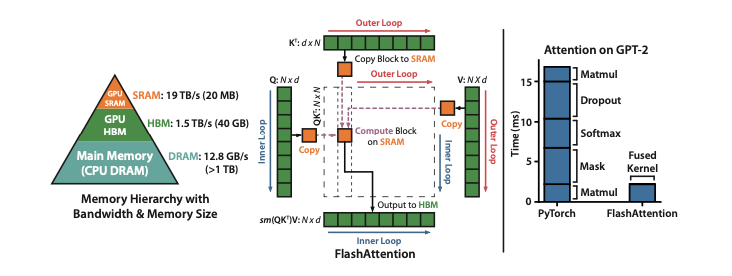 在Transformer架構(gòu)中,注意力機(jī)制的計(jì)算復(fù)雜度與序列長(zhǎng)度(即文本長(zhǎng)度)呈平方關(guān)系()。這意味著,當(dāng)模型需要處理更長(zhǎng)的文本時(shí)(比如從幾千個(gè)詞到幾萬(wàn)個(gè)詞),計(jì)算時(shí)間和所需的內(nèi)存會(huì)急劇增加。最開始的標(biāo)準(zhǔn)注意力機(jī)制存在兩個(gè)主要問題:內(nèi)存占用高:模型需要生成一個(gè)巨大的注意力矩陣(N×N)。這個(gè)矩陣需要被保存在高帶寬內(nèi)存(HBM)中。對(duì)于長(zhǎng)序列,這很快就會(huì)超出G
在Transformer架構(gòu)中,注意力機(jī)制的計(jì)算復(fù)雜度與序列長(zhǎng)度(即文本長(zhǎng)度)呈平方關(guān)系()。這意味著,當(dāng)模型需要處理更長(zhǎng)的文本時(shí)(比如從幾千個(gè)詞到幾萬(wàn)個(gè)詞),計(jì)算時(shí)間和所需的內(nèi)存會(huì)急劇增加。最開始的標(biāo)準(zhǔn)注意力機(jī)制存在兩個(gè)主要問題:內(nèi)存占用高:模型需要生成一個(gè)巨大的注意力矩陣(N×N)。這個(gè)矩陣需要被保存在高帶寬內(nèi)存(HBM)中。對(duì)于長(zhǎng)序列,這很快就會(huì)超出G -
手把手教你設(shè)計(jì)Chiplet2025-09-04 11:51
我們正在參加全球電子成就獎(jiǎng)的評(píng)選,歡迎大家?guī)臀覀兺镀薄x謝支持來源:內(nèi)容由半導(dǎo)體行業(yè)觀察編譯自semiengineeringChiplet是一種滿足持續(xù)增長(zhǎng)的計(jì)算能力和I/O帶寬需求的方法,它將SoC功能拆分成更小的異構(gòu)或同構(gòu)芯片(稱為芯片集),并將這些Chiplet集成到單個(gè)系統(tǒng)級(jí)封裝(SIP)中,其中總硅片尺寸可能超過單個(gè)SoC的光罩尺寸。SIP不僅 -
從自然仿真到智能調(diào)度——GPU并行計(jì)算的多場(chǎng)景突破2025-09-03 10:32
我們正在參加全球電子成就獎(jiǎng)的評(píng)選,歡迎大家?guī)臀覀兺镀薄x謝支持隨著復(fù)雜計(jì)算問題的不斷涌現(xiàn),傳統(tǒng)的CPU串行計(jì)算在處理大規(guī)模數(shù)據(jù)與高并發(fā)任務(wù)時(shí)逐漸顯露瓶頸。GPU(圖形處理單元)憑借其高度并行的體系結(jié)構(gòu),成為科學(xué)仿真與智能調(diào)度的核心計(jì)算平臺(tái)。在自然現(xiàn)象模擬中,風(fēng)沙流、流體力學(xué)等問題往往涉及海量粒子間的相互作用,計(jì)算負(fù)擔(dān)極為沉重,而GPU的并行鄰居搜索與空間 -
3萬(wàn)字長(zhǎng)文!深度解析大語(yǔ)言模型LLM原理2025-09-02 13:34
我們正在參加全球電子成就獎(jiǎng)的評(píng)選,歡迎大家?guī)臀覀兺镀薄x謝支持本文轉(zhuǎn)自:騰訊技術(shù)工程作者:royceshao大語(yǔ)言模型LLM的精妙之處在于很好地利用數(shù)學(xué)解決了工業(yè)場(chǎng)景的問題,筆者基于過往工程經(jīng)驗(yàn)繼續(xù)追本溯源,與騰訊學(xué)堂合作撰寫本文,嘗試讓人人都能懂大語(yǔ)言模型的基礎(chǔ)原理。1、大語(yǔ)言模型簡(jiǎn)述截止到2025年“大模型”一般泛指“超大參數(shù)模型”,參數(shù)是指深度神經(jīng) -
從 CPU 到 GPU,渲染技術(shù)如何重塑游戲、影視與設(shè)計(jì)?2025-09-01 12:16
-
汽車傳感器融合技術(shù)的發(fā)展與挑戰(zhàn)2025-08-29 11:56
-
榮獲兩大獎(jiǎng)項(xiàng),Imagination新一代GPU引領(lǐng)端側(cè)AI新時(shí)代2025-08-28 11:26
2025年8月26日,在深圳會(huì)展中心舉辦的Elexcon2025深圳國(guó)際電子展“嵌入式AI、邊緣智能與AIoT生態(tài)會(huì)議“上,Imagination公司分享了在端側(cè)AI的技術(shù)創(chuàng)新與解決方案。同時(shí)“2025年半導(dǎo)體市場(chǎng)創(chuàng)新表現(xiàn)獎(jiǎng)”評(píng)選也正式揭曉,Imagination分別榮獲“年度AI市場(chǎng)領(lǐng)軍企業(yè)獎(jiǎng)”與“年度優(yōu)秀AIIP獎(jiǎng)”兩項(xiàng)大獎(jiǎng)。E-SeriesGPU引領(lǐng)端 -
小白學(xué)大模型:國(guó)外主流大模型匯總2025-08-27 14:06
數(shù)據(jù)科學(xué)AttentionIsAllYouNeed(2017)https://arxiv.org/abs/1706.03762由GoogleBrain的團(tuán)隊(duì)撰寫,它徹底改變了自然語(yǔ)言處理(NLP)領(lǐng)域。論文的核心是提出了一種名為Transformer的全新模型架構(gòu),它完全舍棄了以往序列模型(如循環(huán)神經(jīng)網(wǎng)絡(luò)RNNs和卷積神經(jīng)網(wǎng)絡(luò)CNNs)中常用的循環(huán)和卷積結(jié)構(gòu)