 大數據助力精準扶貧
大數據助力精準扶貧

南京錄信數軟是研究針對大數據行業使用的數據庫產品,我們是做數據存儲的,比較常見的炫酷的查詢界面,比如說建立一些用戶畫像、人物畫像,我們是給他們提供快速的統計分析能力的。那么,今天主要講的是大數據在人車互聯時代的作用。
隨著汽車的數量越來越多,汽車成為我們生活中越來越不可缺少的一部分,汽車保有量已經達到2億左右。過去很長一段時間我們只是針對大數據對人的作用,如果2億左右的汽車個體能夠主動發送一些信息,這個數據量是非常可觀的,由此所產生的一些統計信息,也能反作用于車輛的生產和提高出行的質量。
隨著車聯網的迅速發展,基于OBD基礎上的車載信息采集終端技術日益成熟,汽車大數據應運而生。通過T-Box采集的數據可以應用于各個行業,通過對數據的統計和分析,可以應用于經銷商、主機廠商以及國家監管部門,最近熱門的話題是隨著國家國六標準的出臺,國家要對每臺汽車的尾氣排放進行監管,這也屬于T-Box數據采集的方向。包括車主和駕駛者,車主可以了解車輛的及時狀態。

我們主要是對T-Box的數據采集進行存儲的。T-Box將數據上傳到服務器或者云平臺,國家監管機構、車廠商、經銷商或者車主去里面獲取相關的信息,車主可以通過APP獲得數據,監管部門或者是廠商會通過web界面來獲取信息。
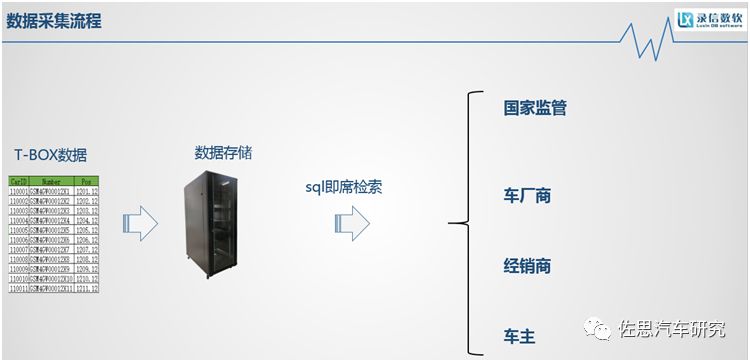
今天討論的是數據存儲和查詢界面使用的即席檢索。所謂即席檢索,就是想查什么就查什么,數據在入庫時不需要做預統計和預計算,預計算的缺點是沒有做預計算的維度是不能查詢的,而且預統計比較消耗系統資源。我們的產品可以實現對原始一份數據即席查詢,在千億級別上實現秒級響應。我們的產品定位是一款單機即可支撐500億條數據的秒級檢索分析響應型數據庫。特點:無限線性擴展、4臺可支撐千億條、百臺可支撐萬億條。
隨著汽車數量逐年增長,車載終端所產生的數據量是非常巨大的,我們通過一些合作的客戶來看,一個主機廠商一年所能達到的數據量在20萬億,數據可以達到PB級別,當前市場上流行的大數據框架,在這個數據級別上進行快速的統計分析是沒有完美解決方案的。如果對數據進行長久存儲,三年就要達到60萬億的數據量,傳統的數據庫已經吃不消了。萬億數據怎么存儲呢?可能在數據量比較大的時候,我們會想到Hadoop生態系統,它是開源的,它就是通過整合單機資源,堆積單節點的計算能力,達到比較好的整體算力。它的一個缺點就是它要對全量數據做掃描,全量掃描就會有一個問題,需要更多的硬件滿足算力的要求,所以它的硬件成本還是比較高的,雖然說每臺硬件成本是配置比較低的普通服務器,但是整體的成本還是比較高的。
有沒有這么一種可能性,在海量數據的基礎上,建立一層索引,可以減少掃描的數據量,從而降低硬件成本的要求。
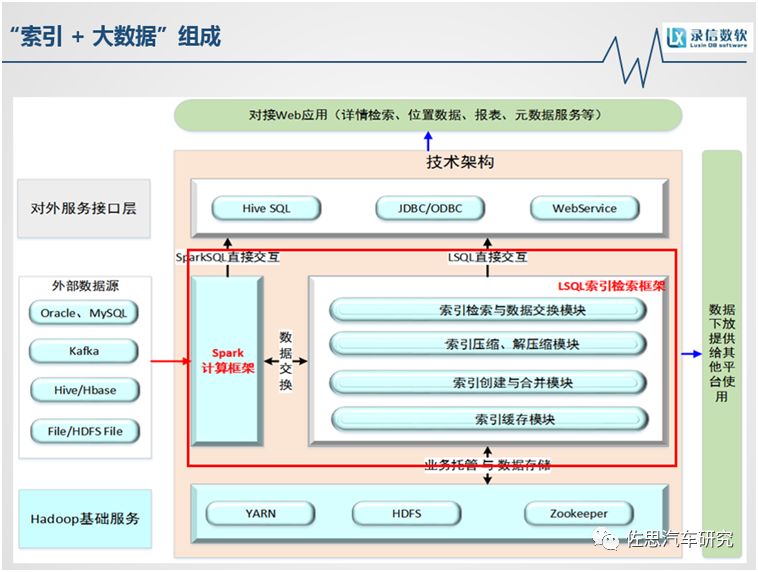
如上圖,這個框架大家比較熟悉,除了紅框里面的部分,我們現在把它改成我們自研的索引引擎,數據篩查的時候經過這個索引引擎,首先過濾掉一大部分數據量,是在很小的數據量中進行檢索,所需要的硬件資源已經少了很多。我們為了增加它在復雜統計場景下的性能,我們將spark框架集成在內,這是基于內存的一個計算框架。我們與開源的spark框架還不同,開源的spark框架對文本文件沒有過濾,優化過的spark框架最終是和索引引擎進行數據交換的。無論是通過索引引擎直接查,還是通過spark計算框架查,都比原生地要快很多,在某些場景上,已經快了幾百倍。它的底層還是建立在Hadoop基礎上。對外部的數據接入,可以傳統的關系型數據庫MySQL、Oracle,也可以通過Kafka實時消費。數據從產生到可查只需2-3分鐘。
我們對外提供的場景接口也很豐富,有HiveSQL,或者通過JDBC,或者通過Webservice的方式。
索引+大數據,由于在運算的時候可以減少掃描的數據量,進而可以減少機器臺數的要求,原生的架構大量的機器堆積不僅僅為了存儲,而是它的計算能力不夠,可能每臺機器存儲只用了一部分,但是每臺機器的計算能力已經用滿了。我們從減少數據加載量的角度優化,可以減少機器臺數。

還有一個就是數據熱點的問題,很多場景下都會對最近幾天的數據比較關注,比如說最近幾天的消費數據、新聞、網頁瀏覽,都屬于熱點數據,查詢頻率比較高,針對這樣的數據特點,我們采用了冷熱數據分離。冷熱數據分離可以做到什么好處呢?查詢頻率比較高的數據,我把它放到SSD固態硬盤上,可以提升數據加載的速度,過一段時間之后,這個數據查詢沒那么高了,可以把它放到機械硬盤上。這樣可以既兼顧了查詢的速度,也兼顧了成本。
還有我們針對每個數據類型,有專門的壓縮格式,可以減少硬盤的存儲。

上圖是我們在一個真實的項目遇到的情況,它的數據量也是達到萬億級別。這是對開源系統和索引+大數據系統的對比。首先是硬件成本,很明顯機器臺數已經降到之前的1/5,對硬件配置的要求也有很大的下降。還有就是人力成本,之前有三套系統,有做統計分析的mapreduce集群、有做實時檢索的hbase、還有建立二級索引的ES,三套系統保存三份數據,數據膨脹率很高,而且三套集群,4種完全不同的風格的API,對開發的要求很高。索引+大數據的架構,它對外是統一的SQL接口,通過sql語句來進行交互,極大的減少人力成本。

我們的數據存儲還是建立在HDFS上,實時檢索相比目前主流的檢索框架來說,它繼承了很多HDFS的特點,比如說磁盤容錯,某些情況下磁盤突然壞掉了,或者速度變慢,磁盤容錯能夠自動發現,自動遷移到速度比較快的副本上面,然后自動讀取。還有一個是IO管控,如果某個查詢需要的資源非常高,已經影響到服務的性能,可以隨時中斷這個任務,從而保證整個服務可查。還有比較重要的是數據快照,有時候數據不小心刪掉了,我們提供數據快照的功能,在短時間內可以對大量的數據創建快照,1P數據只需要2秒鐘創建。
檢索分析場景,基于車載T-Box產生的數據,對各個行業的統計是非常復雜的。國家監管機構可能要對尾氣排放進行監控,對車輛實時軌跡、位置進行監管,還有通過駕駛員的駕駛習慣,比如說急剎車、急轉彎,對駕駛員進行教導。對車廠商來說市場上車輛各組件性能損耗的多維分析,比如說汽車的每個功能組件損耗到什么程度,然后用于改善生產。經銷商可以建立用戶畫像,某一型號車輛在全國各個省的分布情況,可以用于精準營銷。對車主來說,需要掌握車輛的整體狀態。

對各個行業來說,數據的統計分析是非常復雜的,在大量的數據基礎上進行這么復雜的分析,是一個很大的挑戰。在索引+大數據的框架下,無論是檢索還是統計分析,查詢性相比較開源都有很大幅度的提升,但是在某些具體場景,我們也是有一些特定的優化的。比如說一些軌跡類的查詢,像軌跡回放,要求是在過去的某一段時間,對某一個車輛進行軌跡的檢索,將軌跡信息實時展示在地圖上面,用于一些軌跡監控之類的。
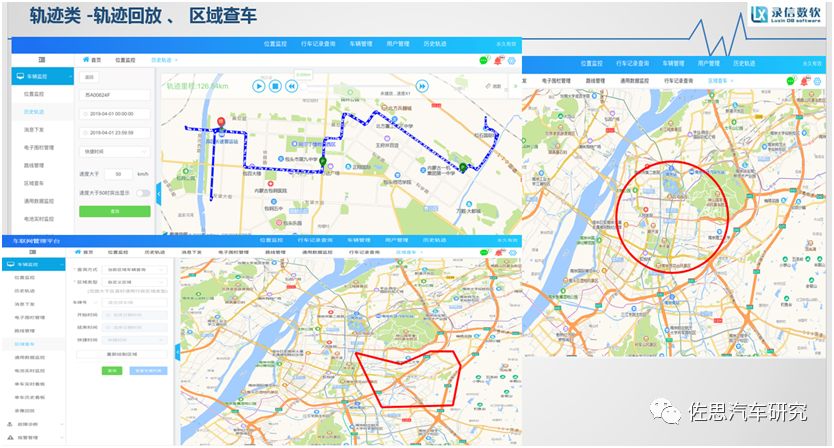
這個數據其實就是經緯度字段在界面上展示,至于這個界面做到多炫酷,那是界面的事情,我們是提供數據快速查詢的能力。還有就是區域查車,在地圖上可以人為圈定一個規則的圓形或者矩形,或者不規則的多邊形,可以監控這個圖形范圍內的車輛信息,出來的也是經緯度的信息。值得一提的是目前開源解決方案對不規則的多邊形支持并不友好,有些并不支持,我們通過改善空間地圖位置索引的結構,就能很好地支持這種不規則多邊形的索引。
其實這兩種軌跡類的查詢,只是對經緯度字段的查詢度比較高,其它的字段不查詢。針對一個表中某幾個字段查詢比較高的情況,是不是有其它的方案呢?列簇和異構是比較好的解決方法。列簇是說,一張表里面有幾個列,它的保存周期、存儲格式不同,就可以把相同生命周期的數據或者是相同存儲格式的數據保存在一個目錄里面,后期進行數據淘汰或者增加壓縮比。然后是異構,根據數據的重要程度,選擇在保存在不同的存儲介質上,如果使用頻率不高的,可以保存在機械硬盤上。那么軌跡類的查詢,就可以把經緯度字段放在比較好的硬盤上,獲得好的數據加載性能。等過了一段時間,數據會自動遷移到一些廉價的硬盤上。


在軌跡類查詢方面,比如說想查詢某個車牌號或者某個手機號今天的軌跡信息,一般的做法就是針對時間字段做排序,然后取最新的幾條,在萬億數據基礎上做排序,是一件很頭疼的事情,我們針對大數據量的TOP N的排序也做了優化,目前業界主要做的是一條一條暴力掃描,將數據加載之后再獲取TOPN。我們所做的針對排序的數據結構是叫tired tree,它是針對數值類型的排序,比如整型int是四個字節,那么,先根據第一個字節建立索引,然后再根據第一、二個字節建立索引,之后再根據第一、二、三個字節建立索引,最后對全量數據建立索引,通過對相同前綴建立索引,可以獲得較好的性能。比如要查詢423這個值,首先去查4,定位到4,之后5、6就不查了。然后定位42,44就不需要查詢了,之后再直接找到423,經過幾次的查詢,和全量掃描最底層所有的記錄來說,已經高效了不少,當然這里的數據量比較少,我們看不出來有多么高效。如果我要找TOP N,我可以直接定位到這個數值前面最大的前綴,這里是6,找到6之后,我可以找到64下面的,直接返回了。它可以通過索引直接定位到TOPN個結果,無序額外計算,只需作TOP N排序,避免讀取全量數據。通過這種高效排序和異構+索引在軌跡類的查詢,可以做到很好的性能提升。


在海量數據上進行多維的數據統計和分析,進而建立用戶畫像也是一個常用的業務場景,比如說可以根據車輛的報警信息,做出一個報警的分布圖,也可以根據用戶的急加速、急減速行為做出一個統計結果,根據用戶的屬性分類,建立一個用戶畫像。包括某個車輛在全國的銷售情況,后期用于精準營銷,提供一些判斷的依據,對各個維度的信息進行多維的統計分析,本來不是一件特別難的事情,當數據量小的時候,在Oracle、MySQL里面就可以做,如果放到千億級別、萬億級別就很頭疼。目前開源是怎么解決這個問題的呢?

它把過濾之后的數據全部加載到內存,通過拼I/O資源和CPU資源,人為地做一些聚合、分組統計,這個性能還是依賴硬件。我們對這個業務場景做的一個調優是我們在入庫的時候,就對我們所要統計的某些字段進行預排序,干預它的排序規則,比如要對一個表里面有三個字段city_id、age、score進行統計分析,數據存儲的時候,就是按照這種group by 的順序來存儲,那么遇到這種查詢的時候,就可以直接獲取到后面的數據,就不需要重新計算。如果某個統計分析后面加上檢索條件,也不需要做全列掃描,通過在真實數據基礎上創建一個二級的跳躍表結構,每一個節點上會記錄當前區域里面的最大值和最小值。通過第一層可以找到第二層,第二層縮小到更小的區間,在千億甚至萬億的數據里面,最后篩選的數據量就很少,可以極大地過濾掉數據,加載數據的內容很小,釋放很多的I/O資源。用戶可以根據需求自定義任意維度,快速統計。當然它和預計算、預統計是有區別的,預計算的容量更重,它需要占用的CPU資源更高。
在這種統計分析場景下,如果某一個時刻,入庫壓力比較大,而且查詢的頻率又比較高,這個時候一個進程既承擔讀也承擔寫就成為整個系統的瓶頸。那么一主多從可以實現讀寫分離,提高效率。

主節點負責數據寫入,多個從節點承擔讀的壓力,它和我們熟知的My SQL主動復制有區別,MySQL主動復制是每個節點各保存一份數據,比如說一主三從,它有4份數據,而且主和從之間有數據同步的過程,也是存在延時的。上面的一主多從架構只保留一份數據,它沒有數據冗余,減少磁盤存儲。在大量的數據更新、新增時主節點和從節點沒有任何的延時。
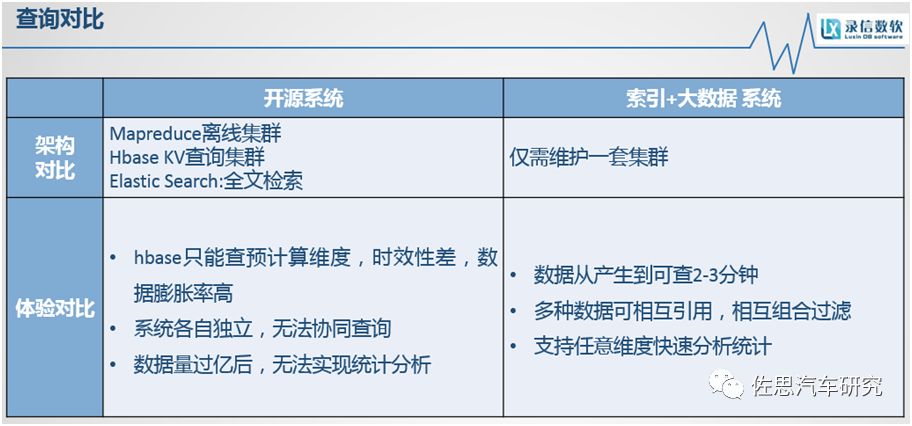
上表是開源系統和索引+大數據系統的在查詢方面一個直觀的對比圖。開源方案如果要實現多維統計,多個表的表關聯,或者一個表的多列的復雜的分組統計,需要使用離線集群跑MR任務,它的一份數據要存在三套系統里面,數據膨脹是很大的。索引+大數據的框架僅需要維護一套系統,這一套系統既可以用于檢索,也可以用于統計。體驗對比,Hbase只能查預計算維度,時效性差、數據膨脹率高。系統各自獨立,無法實現協同查詢,如果想要玩轉這三套系統,技術要求是比較高的,數據量過億后,無法實現統計分析。對比下來索引+大數據,數據從產生到可查只需要2到3分鐘,而且多種數據可以相互引用,相互組合過濾,并且支持任意維度的快速分析統計。
下面介紹一下錄信數軟的產品。我們的產品就是想解決當前大數據行業所存在的一些痛點。
第一是成本高。目前想要在純檢索的情況下,實現千億量級的統計分析,需要100臺SSD機器,在這種情況下,索引+大數據的框架可以節省60%-70%的硬件成本,包括機器臺數和硬件配置。
第二是時效性的問題,目前的行業現狀是進行大數據分析統計,數據量是T+1天可查,它有時間間隔,復雜業務可能要達到一到兩個小時甚至更長時間。索引+大數據從產生到可查詢只需要幾分鐘,多維多表的統計分析可以達到秒級。
第三是易用性比較差,目前大數據的框架一般Hadoop+hbase+ES,它需要多份數據、多種業務接口,上手復雜。索引+大數據是多種業務一套數據庫一站式解決。

我們不是提供通用的解決方案,我們是根據用戶的需求,解決具體的問題。今天介紹的是車聯網領域的應用,其實大數據是無處不在的,數據的價值也越來越被重視,尤其在當今的國際背景下,國產數據庫任重而道遠,感謝大家!
-
數據庫
+關注
關注
7文章
4020瀏覽量
68355 -
大數據
+關注
關注
64文章
9064瀏覽量
143762
原文標題:南京錄信數軟徐國信:大數據助力人車互聯
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大數據解決方案如何實施
大數據平臺運營的基礎是什么
精準測量,效率升級——測寬測厚儀為制造業品質保駕護航
大數據時代下的管理變革:勤哲EXCEL服務器助力企業高效運營
組態大數據平臺是什么?有什么功能?

能耗管理系統的數據精準度有多重要?這些誤區要避開
御控工業物聯網大數據解決方案:排水設備遠程監控與大數據統計系統
巧用蘇寧易購 API,精準分析蘇寧易購家電銷售大數據

還在憑感覺做畫像?GWI 利用大數據精準繪制核心客戶群
多摩川編碼器:助力自動化控制系統實現更精準的運動控制
物聯網的應用范圍有哪些?
更改最大數據包大小時無法識別USB設備如何解決?
研華工業主板AIMB-289精準提升內窺鏡性能,助力智慧醫療升級!




 工商網監
工商網監
評論