 Pedro Domingos教授的研究論文匯集機器學習研究人員的經驗教訓
Pedro Domingos教授的研究論文匯集機器學習研究人員的經驗教訓

機器學習算法被認為能夠通過學習數據來弄清楚如何執行重要任務。
這意味著數據量越大,這些算法就可以解決更加復雜的問題。然而,開發成功的機器學習應用程序需要一定的“民間技巧”,這在教科書或機器學習入門課程中很難找到。
Pedro Domingos教授的一篇很好的研究論文,該論文匯集了機器學習研究人員和從業者的經驗教訓。
1.學習=表示+評估+優化
你有一個應用程序,你認為機器學習可能是一個很好的選擇。現在,在機器學習領域,每年都會有大量的機器學習算法可供選擇,有數百種機器學習算法問世。應該使用哪一個?
在這個巨大的空間中不迷失的關鍵是要明白所有機器學習算法的都由三個核心要素組成:
表示:輸入數據,即要使用的特征,學習器和分類器必須以計算機可以理解的語言表示。學習器可以學習的分類器集稱為學習器的假設空間。如果分類器不在假設空間中,則無法進行學習。
澄清說明:分類器與學習器的含義是什么?假設你有訓練數據,并使用你構建另一個程序(模型)的程序處理這些數據,例如決策樹。學習器是從輸入數據構建決策樹模型的程序,而決策樹模型是分類器(能夠為每個輸入數據實例提供預測輸出的東西)。
評估:需要評估函數來區分好的分類和壞的分類。算法內部使用的評估函數可能與我們希望分類器優化的外部評估度量不同(為了便于優化,并且與后面討論的問題有關)
優化:最后,我們需要一種方法來在分類器中進行搜索,以便我們可以選擇最佳的分類器。學習器效率的關鍵是選擇優化技術。通常從使用現成的優化器開始。如果需要,以后你可以用自己的設計替換它們。
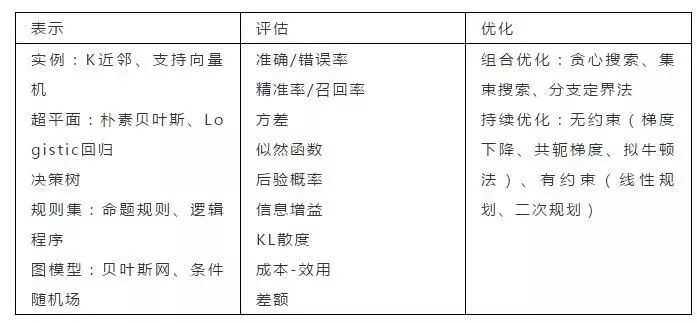
下表顯示了這三個組件中每個組件的一些常見示例。
2.泛化才有用
機器學習的基本目標是概括超出訓練集中的例子。因為,無論我們擁有多少數據,我們都不太可能在測試時再次看到這些確切的示例。在訓練集上做得很好很容易。初學者中最常見的錯誤是測試訓練數據并得到成功的假象。如果所選分類器隨后在新數據上進行測試,則通常不會比隨機猜測更好。因此,從一開始就設置一些數據,并且僅使用它來測試最終選擇的分類器,然后在整個數據上學習最終分類器。
當然,保留數據會減少可用于訓練的樣本數。這可以通過交叉驗證來緩解:比如,將你的訓練數據隨機分成十個子集,在訓練其余部分時保持每個子集,在其未使用的示例上測試每個學習的分類器,并對結果求平均值,來看特定參數設置的效果如何。
3.只有數據還不夠
當泛化是目標時,我們會遇到另一個主要后果:僅憑數據是不夠的,無論你擁有多少數據。假設我們想學習一百萬個例子中100個變量的布爾函數(0/1分類)。這意味著2 ^100-10^6個例子,你不知道它們的類。如果手頭沒有更多信息,這怎么能優于隨機猜測呢?
似乎我們陷入了困境。幸運的是,我們想要在現實世界中學習的特性并不是從所有數學上可能的函數集中統一繪制的!實際上,非常一般的假設——就像具有相似類的類似示例——是機器學習如此成功的一個重要原因。
這意味著專業知識和對數據的理解對于做出正確的假設非常重要。對學習知識的需求應該不足為奇。機器學習并不神奇,它無法從無到有。它的作用是從更少的東西中獲得更多。與所有工程一樣,編程需要做很多工作:我們必須從頭開始構建所有東西。學習更像是農業,讓大自然完成大部分工作。農民將種子與營養物質結合起來種植農作物。學習者將知識與數據相結合以優化程序。
4.過擬合的多面性
過度擬合的問題是機器學習的問題。當你的學習器輸出一個對訓練數據100%準確但對測試數據只有50%準確的分類器時,實際上它可以輸出一個對兩者都準確度為75%的分類器,它已經過擬合。
機器學習中的每個人都知道過擬合,但它有多種形式,并不是很明顯。理解過擬合的方法之一是將泛化誤差分解為偏差和方差。
偏差是學習者一直學習同樣錯誤的傾向。與真實信號無關,方差是學習隨機事物的傾向。飛鏢圖比可以更好地理解這一點,如下圖所示:
例如,線性學習器具有較高的偏差,因為當兩個類之間的劃分不是明確的超平面時,學習器無法正確地判別關系。決策樹沒有這個問題,因為它們的學習方法很靈活。但另一方面,它們可能有高度差異——在同一任務的不同訓練數據集上學習的決策樹通常是非常不同的,而實際上它們應該是相同的。
現在,如何處理過擬合?
可以在此處使用交叉驗證,例如通過使用它來選擇要學習的決策樹的最佳大小。但請注意,這里還有一個問題:如果我們使用它來選擇太多參數,它本身就會開始過擬合,我們又回到了同樣的陷阱。
除了交叉驗證之外,還有許多方法可以處理過擬合。最受歡迎的是在評估函數中添加正則化項。另一個選擇是執行卡方等統計顯著性檢驗,以分析添加更多復雜性是否會對類分布產生任何影響。這里的一個重點是沒有特定的技術“解決”過擬合問題。例如,我們可以通過陷入欠擬合(偏差)的相反誤差來避免過度擬合(方差)。同時避免兩者都需要學習一個完美的分類器,并沒有一種技術總能做到最好(沒有免費的午餐)。
5.高維中的直覺失效
過擬合后,機器學習中最大的問題是維數的詛咒。這個表達式意味著當輸入是高維的時,許多在低維度下工作正常的算法變得難以處理。
由于固定大小的訓練集覆蓋了輸入空間的一小部分(可能的組合變得巨大),因此隨著示例的維度(即特征的數量)的增長,正確泛化的難度呈指數級增加。但這就是為什么機器學習既有必要又有難度。正如你在下圖所示,即使我們從1維過渡到3維,能夠分辨出不同示例的工作似乎開始變得越來越難——在高維度上,所有示例都開始相似。
這里的一般問題是,我們來自三維世界的直覺使我們在高維度上失敗。例如,高維度橙色的大部分體積都在外部,而不是內部!
令人難以置信的是:如果恒定數量的示例在高維超立方體中均勻分布,并且如果我們通過將其刻在超立方體中來近似超球面,則在高維度中,超立方體的幾乎所有體積都在超球面之外。這是個壞消息。因為在機器學習中,一種類型的形狀通常由另一種形狀近似。
澄清注意:如果你對所有“夸大其詞”感到困惑,超立方體內部的超球面看起來像是這樣的二維和三維:
因此,你現在可以理解,構建2維或3維分類器很容易,但在高維度上,很難理解發生了什么。反過來,這使得設計好的分類器變得困難。事實上,我們經常陷入這樣的陷阱:認為獲取更多特征不會帶來負面影響,因為在最壞的情況下,它們不會提供關于類的新信息。但事實上,維度的詛咒可能會超過它們的好處。
啟示:下次當你考慮添加更多特征時,請考慮當你的維度變得太大時可能出現的潛在問題。
6.特征工程是關鍵
當一天結束時,所有機器學習項目中有成功的,也有失敗的。它們之間有區別呢?這個不難想到,最重要的因素就是使用的特征。如果有許多獨立的特征,并且每個特征都與類的相關性很好,那么機器學習就很容易。相反,如果類是需要通過復雜方式處理特征后才能被使用,那么事情就變難了,這也就是特征工程——根據現在輸入的特征創建新的特征。
通常原始數據格式基本不能為建模所用。但你可以從中構建可用于學習的特征。事實上,這是機器學習項目中的最花精力的部分。但這也是最有趣的部分之一,在這里直覺、創造力和“小技巧”與技術是同樣重要的東西。
經常會有初學者驚訝一個機器學習項目中花費在訓練上的時間竟如此之少。但是,如果考慮收集數據,整合數據,清理數據并對其進行預處理的時間以及在特征選擇上的試錯次數,這個時間就相對合理。
更何況,機器學習在構建數據集和運行學習樣例上不是一次性的過程,而是一個迭代的過程,需要運行學習樣例,分析結果,修改數據或學習樣例,以及重復上述過程。訓練往往是最快的部分,但那是因為我們對這部分相當熟練!特征工程很難,因為它是專業領域的,不過學習器在很大程度上是通用的。當然,機器學習界的夢想之一就是提高特征工程的自動化程度。
7.豐富的數據勝過聰明的算法
假設你已經構建了一組最好的特征,但是你得到的分類器仍然不夠準確。你現在還可以做什么?有兩個主流的辦法:
設計更好的機器學習算法或者是收集更多數據(更多樣例,可能還有更多原始特征)。機器學習研究人員會去改進算法,但在現實中,通往成功的最快途徑往往是獲取更多數據。
根據經驗,具有大量數據的傻瓜算法勝過一個具有適度數量的聰明算法。
在計算機科學中,通常情況下,兩個主要的資源限制是時間和內存。但在機器學習中,還有第三個約束:訓練數據。在這三個中,今天的主要瓶頸是時間,因為有大量的可用數據,但沒有足夠的時間來處理它們,所以數據被閑置了。這意味著在實踐中,更簡單的分類器會勝出,因為復雜的分類器需要很長的學習時間。
使用更聰明的算法并不會給出更好的結果,部分原因是在一天中它們都在做同樣的事情,將所有學習樣例基本上都是通過將相鄰的樣例分組到同一個類來工作的。關鍵的區別在于對“相鄰”的定義。
當我們有非均勻分布的數據時,即使復雜的學習樣例也可以產生非常不同的邊界來對結果進行分類,最終它們仍然在重要區域做出相同的預測(具有大量訓練樣例的區域,因此也可能出現大多數文本樣例)。正如下圖所示,無論是花式曲線,直線還是逐步邊界,我們都可以得到相同的預測:
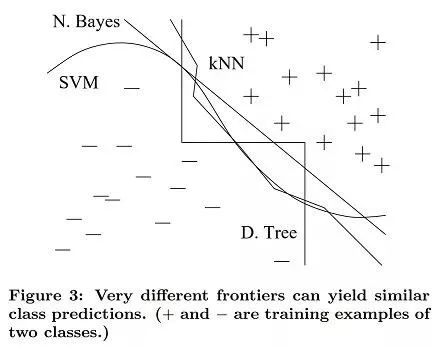
通常,首先嘗試最簡單的學習器(例如,邏輯回歸前的樸素貝葉斯,支持向量機之前的鄰近算法)。復雜的學習器很吸引人,但它們通常很難使用,因為它們需要控制更多的旋鈕以獲得好的結果,并且因為它們的內部更像是黑箱。
8.組合多個模型,而非只用一個
在機器學習的早期階段,努力嘗試使用多種學習器的各種變形,并選擇最好的那個。但是研究人員發現,如果不是選擇其中最好的單一模型,而是結合各種變形會得到更好的結果,建模者只需稍加努力就可以獲得顯著提升的效果。現在建這種模型融合非常普遍:
在最簡單的技術稱為bagging算法,我們使用相同的算法,但在原始數據的不同子集上進行訓練。最后,我們取均值或通過某種投票機制將它們組合起來。
Boosting算法中學習器按順序逐一訓練。隨后的每一個都將其大部分注意力集中在前一個錯誤預測的數據點上。我們會一直訓練到對結果感到滿意為止。
Stacking算法中,不同獨立分類器的輸出成為新分類器的輸入,該分類器給出最終預測。
在Netflix算法大賽中,來自世界各地的團隊競相建立最佳的視頻推薦系統。隨著比賽的進行,發現將學習器與其他團隊相結合可以獲得了最佳成績,并且合并為越來越大的團隊。獲勝者和亞軍都是超過100個學習器的疊加集成,兩個集成的結合進一步改善了結果。算法組合將更好!
9.理論保證和實際具有差異
機器學習論文充滿理論保證。我們應該對這些保證做些什么?歸納法傳統上與演繹法形成對比:在演繹法中,你可以保證結論是正確的,在歸納法中就很難說。最近幾十年的一個重要進展是我們認識到可以做歸納結果正確性的保證,前提是如果我們愿意接受概率保證。
例如,我們可以保證,給定一個足夠大的訓練集,在很大的概率上,學習器會返回一個成功泛化的假設或無法找到一個保持正確的假設。
另一種常見的理論保證是給定無窮的數據,學習器可以保證輸出正確的分類器。在實踐中,由于我們之前討論過的偏置-方差的權衡,如果在無窮數據情況下,學習器A比學習器B好,那么在有限數據的情況下B通常比A好。
理論保證在機器學習中的主要作用不是作為實際決策的標準,而是作為理解算法設計的起點。
10.簡單并不意味著準確
在機器學習中,奧卡姆剃刀原理通常被認為是給定兩個具有相同訓練誤差的分類器,兩者中較簡單的可能具有較低的測試誤差。
但事實并非如此,我們之前看到了一個反例:即使在訓練誤差達到零之后,通過添加分類器,一個boosted ensemble的泛化誤差也會繼續改善。與直覺相反,模型的參數數量與過擬合之間沒有必要的聯系。也就是說在機器學習中,一個更簡單的假設仍然應該是首選,因為簡單本身就是一種優勢,而不是因為它意味著準確性。
11.可表示不等于可學習
僅僅因為可以表示函數并不意味著可以學習它。例如,標準決策樹學習器無法學習葉子多于訓練樣例的樹木。
給定有限的數據、時間和內存,標準學習器只能學習所有可能功能的一小部分,并且這些子集對于不同表示的學習器是不同的。因此,這里的關鍵是嘗試不同的學習器(并可能將它們結合起來)是值得的。
12.相關性不意味著因果性
我們都聽說過相關性并不意味著因果性,但仍然有人常常傾向于認為相關性意味著因果關系。
通常,學習預測模型的目標是將它們用作行動指南。如果我們發現用戶在超市經常買了啤酒就會買尿不濕,那么也許把啤酒放在尿不濕部分旁邊會增加銷量。但除非我們進行真實的實驗,否則很難判斷這是否屬實。相關性標志著一個潛在的因果關系,我們可以將其作為進一步研究的方向,而非我們的最終結論。
結論
跟其他學科一樣,機器學習有很多“民間智慧”,很難獲得但對成功至關重要。
-
機器學習
+關注
關注
66文章
8553瀏覽量
136957
原文標題:關于機器學習實戰,那些教科書里學不到的12個“民間智慧”
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
西井科技攜手同濟大學 三篇AI研究成果入選頂會ICLR 2026

高華科技與東南大學機器人傳感與控制技術研究所簽署產學研合作協議

研究人員復興針孔相機技術以推動下一代紅外成像發展
EBSD制樣技術在材料微觀結構研究中的應用與經驗總結--鋯合金與高碳鋼

NVIDIA展示機器人領域的研究成果
中國科學院沈陽自動化研究所:研究基于石墨烯/PDMS封裝的醫用膠帶柔性傳感器,用于水下機器人運動檢測
無刷直流電機雙閉環串級控制系統仿真研究
后摩智能與高校合作研究成果榮獲ISCA 2025最佳論文獎
NVIDIA助力研究人員開發用于搜救任務的無人地面車輛
輪式移動機器人電機驅動系統的研究與開發
機器學習賦能的智能光子學器件系統研究與應用




 工商網監
工商網監
評論