 谷歌提出MorphNet:網絡規模更小、速度更快!
谷歌提出MorphNet:網絡規模更小、速度更快!

一直以來,深度神經網絡在圖像分類、文本識別等實際問題中發揮重要的作用。但是,考慮到計算資源和時間,深度神經網絡架構往往成本很高。此次,谷歌研究人員提出一種自動化神經網絡架構的新方法 MorphNet,通過迭代縮放神經網絡,節省了資源,提升了性能。
深度神經網絡(DNN)在解決圖像分類、文本識別和語音轉錄等實際難題方面顯示出卓越的效能。但是,為給定問題設計合適的 DNN 架構依然是一項具有挑戰性的任務。考慮到巨大的架構搜索空間,就計算資源和時間而言,為具體應用從零開始設計一個網絡是極其昂貴的。神經架構搜索(NAS)和 AdaNet 等方法使用機器學習來搜索架構設計空間,從而找出適合的改進版架構。另一種方法是利用現有架構來解決類似問題,即針對手頭任務一次性對架構進行優化。
谷歌研究人員提出一種神經網絡模型改進的復雜方法 MorphNet。研究人員發表了論文《MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks》,MorphNet 將現有神經網絡作為輸入,為新問題生成規模更小、速度更快、性能更好的新神經網絡。研究人員已經運用該方法解決大規模問題,設計出規模更小、準確率更高的產品服務網絡。目前,MorphNet 的 TensoreFlow 實現已開源,大家可以利用該方法更高效地創建自己的模型。
MorphNet 開源項目地址:https://github.com/google-research/morph-net
MorphNet 的工作原理
MorphNet 通過收縮和擴展階段的循環來優化神經網絡。在收縮階段,MorphNet 通過稀疏性正則化項(sparsifying regularizer)識別出效率低的神經元,并將它們從網絡中去除,因而該網絡的總損失函數包含每一神經元的成本。但是對于所有神經元,MorphNet 沒有采用統一的成本度量,而是計算神經元相對于目標資源的成本。隨著訓練的繼續進行,優化器在計算梯度時是了解資源成本信息的,從而得知哪些神經元的資源效率高,哪些神經元可以去除。

MorphNet 的算法。
例如,考慮一下 MorphNet 如何計算神經網絡的計算成本(如 FLOPs)。為簡單起見,我們來思考一下被表示為矩陣乘法的神經網絡層。在這種情況下,神經網絡層擁有 2 個輸入(x_n)、6 個權重 (a,b,...,f) 和 3 個輸出(y_n)。使用標準教科書中行和列相乘的方法,你會發現評估該神經網絡層需要 6 次乘法。
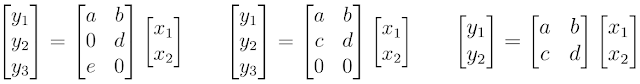
神經元的計算成本。
MorphNet 將其計算成本表示為輸入數和輸出數的乘積。請注意,盡管左邊示例顯示出了權重稀疏性,其中兩個權重值為 0,但我們依然需要執行所有的乘法,以評估該神經網絡層。但是,中間示例顯示出了結構性的稀疏,其中神經元 y_n 最后一行上的所有權重值均為 0。MorphNet 意識到該層的新輸出數為 2,并且該層的乘次數量由 6 降至 4。基于此,MorphNet 可以確定該神經網絡中每一神經元的增量成本,從而生成更高效的模型(右邊示例),其中神經元 y_3 被移除。
在擴展階段,研究人員使用寬度乘數(width multiplier)來統一擴展所有層的大小。例如,如果層大小擴大 50%,則一個效率低的層(開始有 100 個神經元,之后縮小至 10 個神經元)將能夠擴展回 15,而只縮小至 80 個神經元的重要層可能擴展至 120,并且擁有更多資源。凈效應則是將計算資源從該網絡效率低的部分重新分配給更有用的部分。
用戶可以在收縮階段之后停止 MorphNet,從而削減該網絡規模,使之符合更緊湊的資源預算。這可以在目標成本方面獲得更高效的網絡,但有時可能導致準確率下降。或者,用戶也可以完成擴展階段,這將與最初目標資源相匹配,但準確率會更高。
MorphNet 可提供以下四個關鍵價值
有針對性的正則化:MorphNet 采用的正則化方法比其他稀疏性正則化方法更有目的性。具體來說,MorphNet 方法用于更好的稀疏化,但它的目標是減少資源(如每次推斷的 FLOPs 或模型大小)。這可以更好地控制由 MorphNet 推導出的網絡結構,這些網絡結構根據應用領域和約束而出現顯著差異。
例如,下圖左展示了在 JFT 數據集上訓練的 ResNet-101 基線網絡。在指定目標 FLOPs(FLOPs 降低 40%,中間圖)或模型大小(權重減少 43%,右圖)的情況下,MorphNet 輸出的結構具有很大差異。在優化計算成本時,相比于網絡較高層中的低分辨率神經元,較低層中的高分辨率神經元會被更多地修剪掉。當目標是較小的模型大小時,剪枝策略相反。
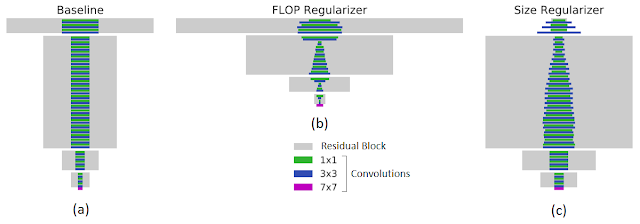
MorphNet 有目標性的正則化(Targeted Regularization)。矩形的寬度與層級中通道數成正比,底部的紫色條表示輸入層。左:輸入到 MorphNet 的基線網絡;中:應用 FLOP regularizer 后的輸出結果;右:應用 size regularizer 后的輸出結果。
MorphNet 能夠把特定的優化參數作為目標,這使得它可針對特定實現設立具體參數目標。例如,你可以把「延遲」作為整合設備特定計算時間和記憶時間的首要優化參數。
拓撲變換(Topology Morphing):MorphNet 學習每一層的神經元,因此該算法可能會遇到將一層中所有神經元全都稀疏化的特殊情況。當一層中的神經元數量為 0 時,它切斷了受影響的網絡分支,從而有效地改變了網絡的拓撲結構。例如,在 ResNet 架構中,MorphNet 可能保留殘差連接,但移除殘差模塊(如下圖左所示)。對于 Inception 結構,MorphNet 可能移除整個并行分支(如下圖右所示)。
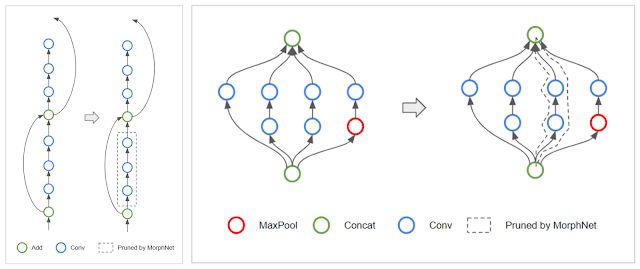
左:MorphNet 移除 ResNet 網絡中的殘差模塊。右:MorphNet 移除 Inception 網絡中的并行分支。
可擴展性:MorphNet 在單次訓練運行中學習新的網絡結構,當你的訓練預算有限時,這是一種很棒的方法。MorphNet 還可直接用于昂貴的網絡和數據集。例如,在上述對比中,MorphNet 直接用于 ResNet-101,后者是在 JFT 數據集上以極高計算成本訓練出的。
可移植性:MorphNet 輸出的網絡具備可移植性,因為它們可以從頭開始訓練,且模型權重并未與架構學習過程綁定。你不必復制檢查點或按照特定的訓練腳本執行訓練,只需正常訓練新網絡即可。
Morphing Network
谷歌通過固定 FLOPs 將 MorphNet 應用到在 ImageNet 數據集上訓練的 Inception V2 模型上(詳見下圖)。基線方法統一縮小每個卷積的輸出,使用 width multiplier 權衡準確率和 FLOPs(紅色)。而 MorphNet 方法在縮小模型時直接固定 FLOPs,生成更好的權衡曲線。在相同準確率的情況下,新方法的 FLOP 成本比基線低 11%-15%。
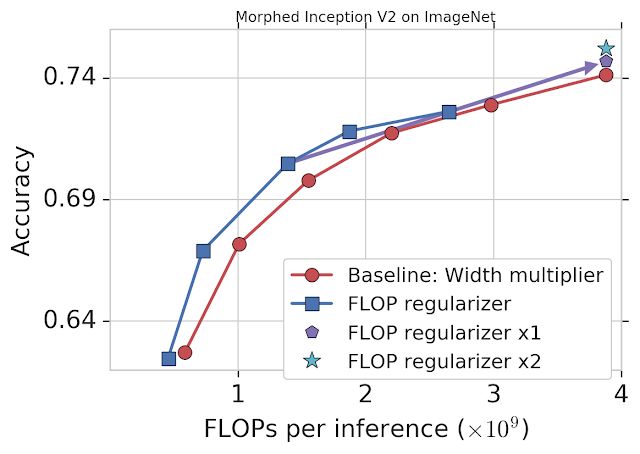
將 MorphNet 應用于在 ImageNet 數據集上訓練的 Inception V2 模型后的表現。僅使用 flop regularizer(藍色)的性能比基線(紅色)性能高出 11-15%。一個完整循環之后(包括 flop regularizer 和 width multiplier),在相同成本的情況下模型的準確率有所提升(「x1」,紫色),第二個循環之后,模型性能得到繼續提升(「x2」,青色)。
這時,你可以選擇一個 MorphNet 網絡來滿足更小的 FLOP 預算。或者,你可以將網絡擴展回原始 FLOP 成本來完成縮放周期,從而以相同的成本得到更好的準確率(紫色)。再次重復 MorphNet 縮小/放大將再次提升準確率(青色),使整體準確率提升 1.1%。
結論:谷歌已經將 MorphNet 應用到其多個生產級圖像處理模型中。MorphNet 可帶來模型大小/FLOPs 的顯著降低,且幾乎不會造成質量損失。
-
谷歌
+關注
關注
27文章
6254瀏覽量
111407 -
神經網絡
+關注
關注
42文章
4838瀏覽量
107784
原文標題:谷歌提出MorphNet:網絡規模更小、速度更快!
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

從“不確定”到“可預期”:TSN 交換機改變了什么?

漢得利產能擴展助力智能制造升級
新加坡服務器的網絡速度和延遲表現如何?
谷歌查找我的設備配件(Google Find My Device Accessory)詳解和應用
Arm 洞察與思考:為什么 AI 向邊緣遷移的速度超乎想象
無速度傳感器感應電機控制系統轉速辨識方法研究
從開關速度看MOSFET在高頻應用中的性能表現





 工商網監
工商網監
評論