 中文分詞在2007-2017十年間的技術進展
中文分詞在2007-2017十年間的技術進展

本文回顧了中文分詞在2007-2017十年間的技術進展,尤其是自深度學習滲透到自然語言處理以來的主要工作。我們的基本結論是,中文分詞的監督機器學習方法在從非神經網絡方法到神經網絡方法的遷移中尚未展示出明顯的技術優勢。中文分詞的機器學習模型的構建,依然需要平衡考慮已知詞和未登錄詞的識別問題。
盡管迄今為止深度學習應用于中文分詞尚未能全面超越傳統的機器學習方法,我們審慎推測,由于人工智能聯結主義基礎下的神經網絡模型有潛力契合自然語言的內在結構分解方式,從而有效建模,或能在不遠將來展示新的技術進步成果。
1
背景
中文分詞是中文信息處理的一個基礎任務和研究方向。十年前,黃和趙(2007)接受《中文信息學報》委托,針對自20世紀末以來的中文分詞的機器學習方法做了十年回顧,發表了《中文分詞十年回顧》一文。 該文的基本結論是中文分詞的統計機器學習方法優于傳統的規則方法,尤其在未登錄詞(out-of-vocabulary words, OOV)即訓練集之中未出現的詞的識別上,具有無可比擬的優勢。這一基本結論隨后得到全面證實。現在10年過去,截至2017年3月, Google Scholar顯示該文被引用166次,而中國知網記錄其引用為483次。
今天看來,使用機器學習方法在具有切分標記的分詞語料上學習或訓練出高效能中文分詞器是自然而然的想法,然而十年前的情形大不相同。首先,直到20世紀的最后十年,中文信息處理界才意識到分詞可以作為真實標注語料上的機器學習任務進行操作。其次,充足的語料準備也并非一蹴而就。兩個早期的語料來自賓州大學中文樹庫(Chinese Penn Treebank, CTB) 和北京大學計算語言所標注的人民日報語料。在各類切分語料齊備的基礎上, SIGHAN才得以組織第一次國際性的中文分詞評測SIGHANBakeoff-2003。
語料準備之外,還有兩個歷史性的因素,遲滯了中文分詞這一中文信息處理基礎子任務走向徹底的機器學習。其一,長期以來,中文分詞的經典方法,即最大匹配算法,在合適的詞典搭配下,通常能夠取得一定程度上頗可接受的性能。以F值度量,最大匹配分詞一般情況下約能獲得80%甚至更高的成績。這類簡單有效的規則方法的存在,極大降低了研發先進機器學習技術的迫切性。其二,機器學習方法的計算代價巨大,在必要硬件條件尚未普及或者成本仍過于高昂的情況下,機器學習方法的優勢得不到體現。 2005年,典型的分詞學習工具條件隨機場(conditional random field, CRF)在百萬詞語料庫上的訓練,需要12-18小時的單線程CPU時間,占用內存2-3G,遠超當時個人計算機的一般硬件配置水準。
因此,我們在2017年的今天回顧10年前的學術狀態,必須歷史性地考慮當時當地的具體情形,才能理解當時以及后來那些理所當然的技術進步有其內在而特殊的合理性和必然性。最近10年機器學習領域最為顯著的技術井噴,顯然是深度學習方法的崛起和全面覆蓋。因而,我們下面將技術總結分為兩大部分,即中文分詞的傳統機器學習模型和最近的深度學習(神經網絡)模型。本文對技術論文的最新引用截止至ACL-2017會議的部分已錄用論文。但由于篇幅所限,我們僅關注嚴格意義上的監督機器學習模式下的相關工作,而對于非監督學習、半監督學習、領域遷移學習以及其它分詞方法和應用等,則尚付闕如,有待日后或各路高賢的努力。我們冒昧以此相對狹窄的視角,回顧我們力所能及范圍內的一些當時及當今相對前沿的研究工作,旨在拋磚引玉,以供借鑒。
2
傳統的機器學習模型
分詞作為字符串上的切分過程,是一種相對簡單的結構化機器學習任務。根據所處理的結構分解單元,大體可以將用于分詞的傳統機器學習模型分為兩大類,即基于字標注的和基于詞(相關特征)的學習。
基于字標注學習的方法始于Xue (2003)。該工作使用一個字在詞中的四種相對位置標簽(tag),即B、M、 E和S等字位(如表1所示),來表達該字所攜帶的切分標注信息,從而首次將分詞任務形式化為字位的串標注學習任務。串標注學習是自然語言處理中最基礎的結構化學習任務,在串標注的概率圖模型中, 兩個串的各個節點單元需要嚴格一一對應, 非常方便于使用各種成熟的機器學習工具來建模和實現。Xue (2003)的首次實現其實尚未充分使用串標注結構學習,而是直接應用了字位分類模型。 Ng & Low(2004)和Low et al. (2005)才是第一次將嚴格的串標注學習應用于分詞, 用的是最大熵(Maximum Entropy,ME) Markov模型。而Peng et al. (2004)和Tseng et al. (2005)則自然地將標準的串標注學習工具條件隨機場引入分詞學習。隨后, CRF多個變種構成了深度學習時代之前的標準分詞模型。

中文分詞任務是切分出特定上下文環境下正確的詞,因此,所謂基于詞的分詞學習建模需要解決一個“先有雞還是先有蛋”的問題。基于詞的隨機過程建模引致一個CRF變種,即semi-CRF(半條件隨機場)模型的直接應用。基于字位標注的分詞學習通常用到的是線性鏈條件隨機場(linear chain CRF),它是基于Markov過程建模,處理過程中的每步只對輸入序列的一個文本單元進行標注。而semi-CRF則基于semi-Markov過程建模,它在每步給序列中的連續單元標注成相同標簽。這一特性和分詞處理步驟高度契合,使其可以直接用于分詞處理。
Andrew (2006)發表semi-CRF的第一個分詞實現。然而, 即使以當時的標準, 號稱直接建模的semi-CRF模型的分詞性能卻不甚理想。通常來說,直接建模會獲得更好的機器學習效果,然而在semi-CRF直接應用于分詞時,卻一直很難兌現。之后,Sun et al. (2009)和Sun et al. (2012)將包含隱變量的semi-CRF學習模型用于分詞,才將其分詞性能提升到前沿水平:前者是首個隱變量semi-CRF模型的工作,聲稱能夠同時利用基于字序列和基于詞序列的特征信息,并經驗證明引入隱含變量能通過有效捕捉長距信息來提升長詞的召回率;后者額外引用了新的高維標簽轉移Markov特征,同時針對性地提出了基于特征頻數的自適應在線梯度下降算法,以提升訓練效率。值得注意的是,線性鏈CRF模型的訓練時間比對應的最大熵Markov模型會慢數倍,因為最大熵模型訓練時間正比于需要學習的標簽數量,而CRF訓練時間則正比于標簽數量的平方,但semi-CRF的訓練比標準的CRF還要緩慢,因此極大地限制了該類模型的實際應用。
傳統的字標注模型方法在進一步發展之后, 也引入部分標志性的已知詞信息(即詞表詞, in-vocabularywords, IV)。 Zhang et al. (2006)提出了一種基于子詞(subword)的標注學習,基本思路是從訓練集中抽取高頻已知詞構造子詞詞典。然而,該方法單獨使用效果不佳,需要結合其他模型,其性能才能和已有方法進行有意義的比較。 Zhao&Kit(2007a)大幅度改進了這個策略,通過在訓練集上迭代最大匹配分詞的方法,找到最優的子詞(子串)詞典,使用單一的子串標注學習即可獲得最佳性能。
基于子串的直接標注模型事實上過強地應用了已知詞信息,因為所有子串都屬于已知詞,并且在模型一開始就不能再切分。這一缺陷后來得到修正,主要的工作包括Zhao&Kit(2007b;2008b;2008a;2011)。在這些工作中,對已有工作的改進主要有兩點:其一,所有可能子串按照某個特定的統計度量方式根據訓練集上的n-gram計數來進行打分;其二,基本模型還是字位標注學習,前面獲得的子串信息以附加特征形式出現。這一工作獲得了傳統標注模型下的最佳性能,包括囊括2008年SIGHAN Bakeoff-4的全部五項分詞封閉測試的第一名(Zhao&Kit, 2008b)。當子串的抽取和統計度量得分計算擴展到訓練集之外,Zhao&Kit(2011)實際上提出了一種擴展性很強的半監督分詞方法,實驗也驗證了其有效性。
和以上所有基于串標注,無論是線性鏈CRF標注還是semi-CRF標注的方法都不相同, Zhang & Clark(2007)引入了一種基于整句切分結構學習的分詞方法。雖然他們聲稱這是一種基于詞的方法,但是他們的方法不同于以往的最顯著點,是字和詞的n-gram特征,都以同等地位在整句的切分結構分解中進行特征提取。在細節上,他們采用了擴展的感知機算法進行訓練,在解碼階段則使用近似的定寬搜索(beam search)。盡管其模型具備理論上更廣泛的特征表達能力,但事實上該工作未能給出更佳的分詞性能(參見表6的結果對比)。
由于分詞是自然語言處理的一個起始任務,因此串標注學習下的可選特征類型相當有限。實際上,能選用的只是滑動窗口下的n-gram特征, n-gram單元為字或者詞。理論上,以單個n-gram特征為單位進行任意的特征模板選擇,在工程計算量上是可行的。實際的系統中,對于字特征多采取5字的滑動窗口,而Zhao et al. (2006a)及其后續工作則僅用3字窗口;對于詞,則多采取3詞的滑動窗口。然而,字位標注并非直接的切分點學習,從后者(切分點)到前者(字位標注系統)有著多種方案,而一旦字位標注發生改變,相應的優化n-gram特征集顯然會發生改變。這一現象的發現及其完整的經驗研究,發表在Zhaoet al. (2006b)和Zhao et al. (2010a)中。表2和表3分別列出了之前的標注集和Zhao et al. (2010a)考察過的完整標注集序列, 后者證明在6-tag標注集配合使用3字窗口的6個n-gram特征(分別是C-1, C0, C1, C-1C0, C0C1,C-1C1,其中C0代表當前字),即可獲得字位標注學習的最佳性能(默認使用CRF模型)。
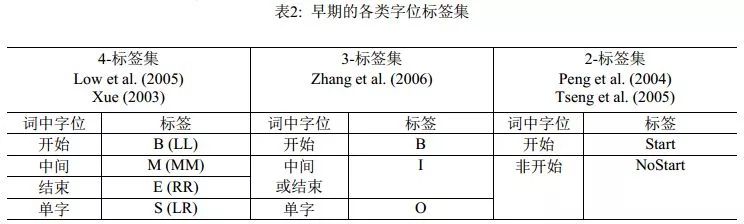
表3: 6-標簽以下所有可能的字標簽集及示例
3
深度學習:神經網絡分詞模型
自從詞嵌入(word embedding)表示達到了數值計算的實用化階段之后,深度學習開始席卷自然語言處理領域。原則上,嵌入向量承載了一部分字或詞的句法和語義信息,應該能帶來進一步的性能提升。如前所述,中文分詞任務中可用的特征僅限于滑動窗口內的n-gram特征。由此,雖然典型的深度學習模型皆以降低特征工程代價的優勢而著稱,但是對于分詞任務的特征工程壓力的緩解卻相當有限。因而,期望神經分詞模型帶來進一步性能改進的方向在于:一,有效集成字或者詞的嵌入式表示,充分利用其中蘊含的有效句法和語義信息;二,將神經網絡的學習能力有效地和已有的傳統結構化建模方法結合,如在經典的字位標注模型中用等價的相應網絡結構進行置換。
Collobert et al. (2011)提出使用神經網絡解決自然語言處理問題,尤其是序列標注類問題的一般框架,這一框架抽取滑動窗口內的特征,在每一個窗口內解決標簽分類問題。在此基礎上, Zheng et al. (2013)提出神經網絡中文分詞方法,首次驗證了深度學習方法應用到中文分詞任務上的可行性。他們的工作直接借用了Collobert模型的結構,將字向量作為系統輸入,其技術貢獻包括:一,使用了大規模文本上預訓練的字向量表示來改進監督學習(開放測試意義);二,使用類似感知機的訓練方式取代傳統的最大似然方法,以加速神經網絡訓練。就結構化建模來說,該工作等同于Low et al. (2005)的字位標記的串學習模型,區別僅在于是用一個簡單的神經網絡模型替代了后者的最大熵模型,其模型框圖見圖1中的左圖。由于結構化建模的缺陷,該模型的精度僅和早期Xue (2003)的結果相當,而遠遜于傳統字標注學習模型的佼佼者。
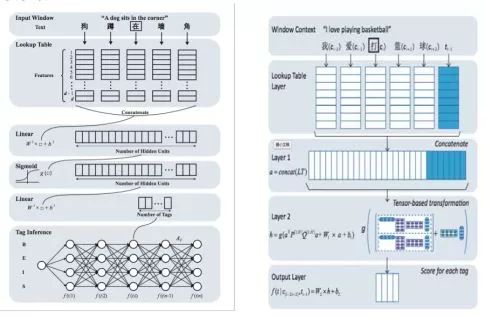
圖 1: Zheng et al. (2013) (左)和Pei et al. (2014) (右)的模型框架。
2014年,Pei et al. (2014)對Zheng et al. (2013)的模型做了重要改進,引入了標簽向量來更精細地刻畫標簽之間的轉移關系, 其改進程度類似于Low et al. (2005)首次引入Markov特征到Ng & Low (2004)的最大熵模型之中。Pei et al.提出了一種新型神經網絡即最大間隔張量神經網絡(Max-Margin Tensor NeuralNetwork, MMTNN)并將其用于分詞任務(見圖1右),使用標簽向量和張量變化來捕捉標簽與標簽之間、標簽與上下文之間的關系。另外,為了降低計算復雜度和防止過擬合(所有神經網絡模型的通病),該文還專門提出了一種新型張量分解方式。
隨后,為了更完整精細地對分詞上下文建模, Chen et al.(2015a)提出了一種帶有自適應門結構的遞歸神經網絡(Gated recursive neural network, GRNN)抽取n-gram特征, 其中的兩種定制的門結構(重置門、更新門)被用來控制n-gram信息的融合和抽取。與前述兩項研究中簡單拼接字級信息不同,該模型用到了更深的網絡結構,為免于傳統優化方法所受到的梯度擴散的制約,該工作使用了有監督逐層訓練的方法。
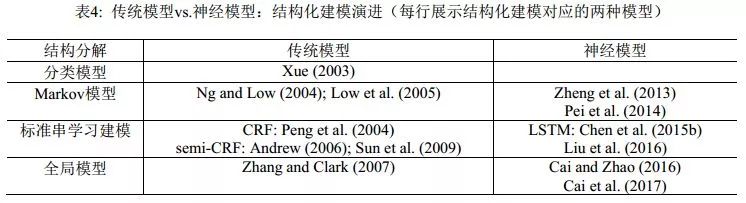
同年, Chen et al. (2015b)針對滑動窗口的局部性,提出用長短期記憶神經網絡(Long Short-TermMemory Neural Networks, LSTM)來捕捉長距離依賴, 部分克服了過往的序列標注方法只能從固定大小的滑動窗口抽取特征的不足。 Xu & Sun(2016)將GRNN和LSTM聯合起來使用。 該工作可以看作是結合了Chen et al. (2015a)和Chen et al. (2015b)兩者的模型。該模型中,先用雙向LSTM提取上下文敏感的局部信息,然后在滑動窗口內將這些局部信息用帶門結構的遞歸神經網絡融合起來,最后用作標簽分類的依據。 LSTM是神經網絡模型家族中和線性鏈CRF同等角色的結構化建模工具,隨著它被引入分詞學習,神經網絡模型在分詞性能上開始可以和傳統機器學習模型相抗衡。我們將結構化建模的傳統-神經模型的對照情況列在表4中。
與傳統方法中基于字的序列標注方案幾乎一統江湖的局面不同,神經網絡有相對更靈活的結構化建模能力,因而有別于序列標注的其他方法也相繼涌現出來。 Ma & Hinrichs (2015)提出了一種基于字的切分動作匹配算法,該算法在保持相當程度的分詞性能的同時,有著不亞于傳統方法的速度優勢。具體來說,該文提出了一種新型的向量匹配算法,可以視為傳統序列標注方法的一種擴展,在訓練和測試階段都只有線性的時間復雜度(見圖2左)。該工作有兩個亮點值得注意:一,首次嚴肅考慮了神經模型分詞的計算效率問題;二,遵循了嚴格的SIGHAN Bakeoff封閉測試的要求,只使用了簡單的特征集合,而完全不依賴訓練集之外的語言資源。
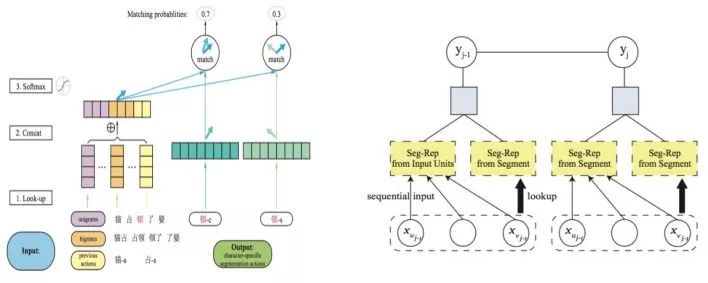
圖2: Ma & Hinrichs (2015) (左)和Liu et al. (2016) (右)的模型框圖
Zhang et al. (2016)提出了一種基于轉移的模型用于分詞,并將傳統的特征模版和神經網絡自動提取的特征結合起來, 在神經網絡自動提取的特征和傳統的離散特征的融合方法做了嘗試。結果表明,通過組合這兩種特征,分詞精度可以得到進一步提升。
Liu et al. (2016)首次將零階半馬爾可夫隨機場應用到神經分詞模型中,并分析了不同字向量和詞向量對分詞效果的影響。 此文基于semi-CRF建模分詞學習(見圖2右),用直接的切分塊嵌入表示和間接的輸入單元融合表示來刻畫切分塊,同時還考察了多種融合方式和多種切分塊嵌入表示。遺憾的是,該系統嚴重依賴傳統方法的輸出結果來提升性能。他們的具體做法是用傳統方法的分詞結果(在外部語料上)作為詞向量訓練語料,因此,該文所報告的最終結果應屬于開放測試范疇。而作為純粹的神經模型版本下的semi-CRF模型,在封閉測試意義下,該系統的效果和傳統semi-CRF(如Andrew (2006))同樣效果不佳(具體見表6的結果對照)。
Cai & Zhao(2016) 徹底放棄滑動窗口,提出對分詞句子直接建模的方法,以捕捉分詞的全部歷史信息, 提出了一個類似于Zhang & Clark (2007)的神經分詞模型, 同時充分吸收了前面一些工作的有益經驗,如門網絡結構等(圖3)。由于覆蓋了前所未有的特征范圍,該模型在封閉測試意義上取得了和傳統模型接近的分詞性能。 概括來說,該方法使用了一個帶自適應門結構的組合神經網絡,詞向量表示通過其字向量生成,并用LSTM網絡的打分模型對詞向量序列打分。這種方法直接對分詞結構進行了建模,能利用字、詞、句三個層次的信息,是首個能完整捕捉切分和輸入歷史的方法。與之前的無論傳統和還是深度學習的方法相比,該模型將分詞動作依賴的特征窗口擴張到最大程度(見表5)。該文所提的分詞系統框架可以分為三個組件:一個依據字序列的詞向量生成網絡組合門網絡 (gated combination neuralnetwork, GCNN,見圖4左);一個能對不同切分從最終結果(也就是詞序列)上進行打分的估值網絡;和一種尋找擁有最大分數的切分的搜索算法。第一個模塊近似于模擬中文造詞法過程,這對于未登陸詞識別有著重要意義;第二個模塊從全句的角度對分詞的結果從流暢度和合理性上進行打分,能最大限度地利用分詞上下文;第三個模塊則使在指數級的切分空間中尋找最可能的切分最優解。
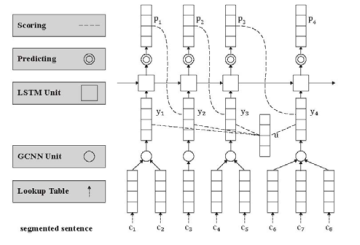
圖 3: Cai & Zhao (2016)的模型框圖
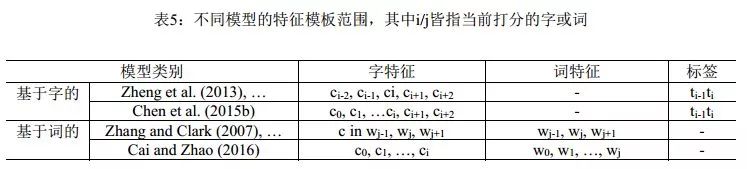
表6列出了近10年來主要的分詞系統在SIGHAN Bakeoff-2005語料上的分詞性能比較。神經分詞系統短短數年間取得了長足進步,但整體上仍然不敵傳統模型。此外,盡管神經網絡方法在知識依賴和特征工程方面有著巨大優勢,也取得了一定的進展,但模型的計算復雜度也大幅提高,因為成功的神經分詞器往往建立于更加精巧、更復雜的網絡結構之上。事實上,經歷五年,深度學習方法在最終模型的性能上,無論是分詞精度還是計算效率上,和傳統方法相比并都不具有顯著優勢。
Cai et al. (2017)在Cai & Zhao (2016)的基礎上,通過簡化網絡結構,混合字詞輸入以及使用早期更新(early update)等收斂性更好的訓練策略, 設計了一個基于貪心搜索(greedy search)的快速分詞系統(見圖4右)。該算法與之前的深度學習算法相比不僅在速度上有了巨大提升,分詞精度也得到了進一定提高。實驗結果還表明,詞級信息比字級信息對于機器學習更有效,但是僅僅依賴詞級信息不可避免會削弱深度學習模型在陌生環境下的泛化能力。表7列舉了最近3年和速度相關的神經分詞系統的結果。從中可見,Cai et al. (2017)首次使神經模型方法在性能與效率上同時取得了和傳統方法相當的成績。
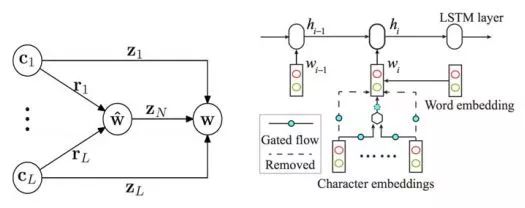
圖4: Cai & Zhao (2016) (左)和Cai et al. (2017) (右)的組合門網絡模塊
4
封閉及開放測試
SIGHAN Bakeoff的分詞評測定義了嚴格的封閉測試條件,要求不得使用訓練集之外的語言資源,否則相應結果則算開放測試類別。區分封閉和開放測試的一個主要目的,是分辨機器學習的性能提升的確是模型自身的改進,而非其它。
不管是傳統模型還是深度學習模型,可選的分詞用外部資源都可以包括各類詞典和切分語料(不一定和已有切分語料屬于同一個分詞規范)。外部資源的使用,可以通過額外標記特征的形式引入,早期的開放測試系統包括Low et al. (2005)。 Zhao et al. (2010a)系統考察了多種外部資源,包括詞典、命名實體識別器以及其他語料上訓練的分詞器,統一用于字標注模型下的附加標記特征,所提的具體做法很簡單:在主切分器上加入其它分詞器(或命名實體識別器)給出的輔助標記特征即可。結果表明,該策略在所有分詞規范語料上都能顯著提升性能,特別是在SIGHAN Bakeoff-2006的兩個簡體語料上可以帶來額外的2個百分點的性能增益。表6展示的結果顯示, Zhao et al. (2010a)報告的開放測試結果目前為止依然為業界最高的分詞性能。該組結果實際上在Bakeoff-2006語料上給出,因而缺乏PKU上的結果,所用的附加資源則來自其它公開的Bakeoff語料。最后,該工作還經驗性暗示,如果可用的額外切分語料可以無限制擴大,則分詞精度也可以無限制提升,雖然代價是切分速度會急劇下降。
基于嵌入表示的深度學習模型對于分詞的封閉和開放測試區分帶來了新的挑戰。顯然,在外部預訓練的字或者詞嵌入向量屬于明顯的外部資源利用,因為字向量預訓練可以直接借用外部無標記語料,典型如維基百科數據,而詞向量的預訓練則需要使用一個傳統分詞模型在外部語料上作預切分,這會同步地引入外部資源知識并隱性集成傳統分詞器的輸出結果。但是,相當部分的神經分詞的工作有意無意地忽略了以上做法的角色區分,實際上等于混淆了開放和封閉測試,更不用說很多神經模型系統甚至再次使用額外的詞典標注來強化其性能。這些做法嚴重干擾了對于當前神經分詞模型的分析和效果評估:到底這些模型聲稱的性能提升,是來自新引入的深度學習模型,還是屬于悄悄引入的外部資源的貢獻?從表6中所比對的神經分詞器的開放和封閉測試效果可以看出,大部分神經分詞系統引入外部輔助信息,才能再獲得1-2個百分點的性能提升(已經屬于開放測試范疇),才能和嚴格封閉測試意義上的傳統模型抗衡。如果嚴格剝離掉所有額外預訓練的字或詞嵌入、額外引入的詞典標注特征以及隱性集成的傳統分詞器的性能貢獻,可以公正地看出,直至2016年底,所有神經分詞系統單獨運行時,在性能(更不用說在效率上)都不敵傳統系統。
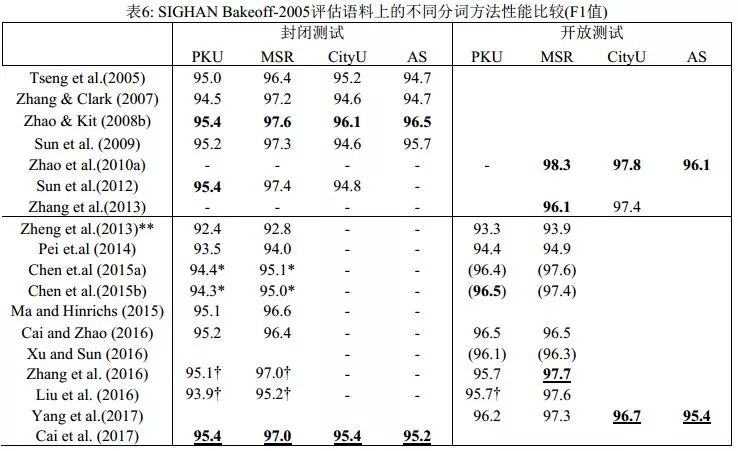
說明:表格上部展示的是傳統方法,下部是深度學習方法。標有雙星號(**)的是來自Pei et al. (2014)的再運行結果;標有星號(*)的是來自Cai & Zhao (2016)的再運行結果;帶有? 是指使用了或者可能使用了預訓練的字向量;帶有? 側是依賴傳統模型(在大規模未標注語料上使用傳統切分的結果進行預訓練);而括號(…)里的結果使用了成語表。
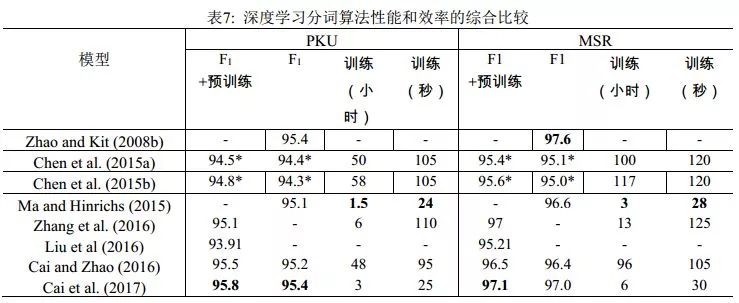
說明:標有星號(*)的數據來自Cai and Zhao (2016)再運行的結果。此表列出的是Zhang et al. (2016)與Liu et al. (2016)中神經網絡模型單獨工作的結果。注意大多數深度學習方法使用的字向量可以事先在大規模無標記的語料上進行預訓練。嚴格來說,這類結果需歸于SIGHAN Bakeoff開放測試的類別。
Yang et al. (2017)專門調查分析了外部資源對中文分詞效果的影響,包括預訓練的字/詞向量、標點符號、自動分詞結果、詞性標注等,他們把每一種外部資源當作一個輔助的分類任務,使用多任務神經學習方法預訓練了一組對漢字上下文建模的共享參數。大量的實驗表明了外部資源對神經模型的性能的提升同樣具有重要意義。
如果把外部資源的貢獻進行量化,或者簡化一些,是否能夠給出機器學習的語料規模和學習性能的增長之間的聯系規律?其實,這方面的經驗工作已在Zhao et al. (2010b)之中完成,基本結論是統計機器學習系統給出的分詞精度和訓練語料規模大體符合Zipf律,即:語料規模指數增長,性能才能線性增長。而和統計分詞不同,更傳統的規則分詞,例如最大匹配法,其精度和所用的詞典(即所收錄的詞表詞)的規模成線性關系,因為分詞錯誤主要是未登錄詞導致的。這一結論意味著統計方法,無論是傳統的字標注還是現代的神經模型,仍有著巨大的增長空間。
5
結論
關于中文分詞的機器學習方法,長期以來一直存在著“字還是詞”的特征表示優越性之爭,這恰好和語言學界對于中文結構分析的“字本位”還是“詞本位”的爭議相映成趣。這一點早在黃和趙 (2006)中就給出了經驗性觀察結果:字、詞的特征學習需要在分詞系統中均衡表達,才能獲得最佳性能。實際上,所謂字、詞爭議的核心對應于分詞的兩個指標,已知詞(或詞表詞,即出現在切分訓練語料中的詞)的識別精度和未登錄詞的識別精度,前者識別精度很高、相對容易但所占百分比高,后者識別精度很低、難度較大但所占百分比較低。經驗性的結果表明,強調基于字的特征及其表示會帶來更好的未登錄詞的識別性能。原因無他,未登錄詞從未在訓練集出現,只能依賴于模型通過字的創造性組合才能識別。反過來,強調詞特征的系統,包括基于詞的切分系統,對于未登錄詞的識別效果通常略為遜色。最佳的分詞系統總是需要合理考慮字表示和詞表示的平衡問題。最近的兩個工作的改進點可以輔證這一結論: Caiet al. (2017)對于Cai & Zhao (2016)的一個關鍵性改進,是詞向量不再總是由字向量通過神經網絡計算得到,而是采取了兩種策略,即低頻或者未知詞繼續由字向量計算,而訓練集中的高頻詞(可以認為是更為穩定的已知詞)則進行直接計算。當系統由后者偏向字向量表示的模式轉向字-詞均衡的表示模式以后,確實帶來了額外的性能提升。
最近5年,基于神經網絡模型的分詞學習已經取得了一系列成果。就目前的結果來看,我們可以得出兩個基本結論:一,神經分詞所取得的性能效果僅與傳統分詞系統大體相當,如果不是稍遜一籌的話;二,相當一部分的神經分詞系統所報告的性能改進(我們謹慎推測)來自于經由字或詞嵌入表示所額外引入的外部語言資源信息,而非模型本身或字詞嵌入表示方式所導致的性能改進。如果說詞嵌入表示蘊含著深層句法和語義信息的話,那么,這個結論似乎暗示一個推論,即分詞學習是一個不需要太多句法和語義信息即可良好完成的任務。
現代深度學習意義下的神經網絡歸類于人工智能的聯結主義思潮,由于其帶有先天性的內在拓撲結構,如果能克服其訓練計算低效的弊病,它就應該是本身需要結構化學習的自然語言處理任務的理想建模方式。這是我們在深度學習時代看到更多樣化的結構建模方法用于中文分詞任務的主要原因。如果我們能有效平衡字-詞表示的均衡性,不排除將來深度學習基礎上的分詞系統能有進一步的成長空間。
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107854 -
機器學習
+關注
關注
66文章
8554瀏覽量
136991 -
自然語言處理
+關注
關注
1文章
630瀏覽量
14674
原文標題:深度長文:中文分詞的十年回顧
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
灌封膠如何通過抗老化技術實現十年如新的長效保護?| 鉻銳特實業

云天勵飛出席GAIR 2025 AI算力新十年專場
東風嵐圖與寧德時代正式簽署十年長期深化合作協議
技術為基,定義未來:廣東固特科技如何引領超聲切割行業十年?

意法半導體全新高g值加速度計IMU提升動態環境下的測量精度
華為五大創新開啟非洲移動產業黃金十年
深耕藍牙物聯網十年:北京桂花網 2015-2025 發展大事件全景
十年·NDI在中國|影像志:見證視頻IP化的成長與未來


十年積淀,DPVR AI眼鏡將正式亮相

統信Windows應用兼容引擎官網正式上線
BOE(京東方)“照亮成長路”公益項目新十年啟幕 科技無界照亮美好未來
10周年文章合集白皮書
如何應對邊緣設備上部署GenAI的挑戰
氣侯技術公司紛紛采用 NVIDIA Earth-2 用于高分辨率、高能效、更準確的天氣預報和備災工作



 工商網監
工商網監
評論