") 谷歌大腦開發(fā)人類翻譯器 打破AI黑盒新方式
谷歌大腦開發(fā)人類翻譯器 打破AI黑盒新方式

如果一個醫(yī)生告訴你需要做手術(shù),你肯定會想知道為什么,進一步地,你會希望他給你一個就算沒學過醫(yī)也能聽得懂的明確解釋。谷歌大腦(Google Brain)的研究科學家Been Kim認為,我們應該對人工智能抱有同樣的期望。作為“可解釋”機器學習的專家,她希望構(gòu)建一個能夠向任何人解釋人工智能的軟件。
自從十年前人工智能興起以來,人工智能中的神經(jīng)網(wǎng)絡技術(shù)已經(jīng)從電子郵件滲透到了藥物研究等各個方面,它具有越來越強大的能力來學習和識別出數(shù)據(jù)中的模式。
但這種能力帶來了一個讓人頭疼的問題:現(xiàn)代深度學習網(wǎng)絡之所以能夠?qū)崿F(xiàn)自動駕駛和保險欺詐識別這樣的壯舉,主要原因在于網(wǎng)絡的復雜性,其復雜度之高讓神經(jīng)網(wǎng)絡專家也不能解釋清楚網(wǎng)絡內(nèi)部到底是怎么工作的。
如果一個神經(jīng)網(wǎng)絡被訓練來識別有患肝癌和精神分裂癥等疾病風險的患者,例如2015年紐約Mount Sinai醫(yī)院的“深度患者”系統(tǒng),我們無法得知網(wǎng)絡關(guān)注的是數(shù)據(jù)中的哪些特征,因為神經(jīng)網(wǎng)絡的層數(shù)太多了,每層中神經(jīng)元還有成百上千個連接。
越來越多的行業(yè)正在試圖通過人工智能實現(xiàn)自動化決策或增強他們的決策制定依據(jù),這個所謂的黑盒問題不是技術(shù)上的問題,而是神經(jīng)網(wǎng)路的根本性缺陷。
DARPA的“XAI”項目(針對“可解釋的人工智能”)正在積極鉆研這個問題,可解釋性在機器學習中的地位越來越高。Kim認為:“人工智能正處于發(fā)展的關(guān)鍵時刻,我們需要判斷這項技術(shù)是否對我們有益。如果我們不能解決可解釋性問題,人工智能的發(fā)展可能會受到阻礙甚至被放棄。”
Kim和她在Google Brain的同事最近開發(fā)了一個名為“概念激活向量測試”(TCAV)的系統(tǒng),她將該系統(tǒng)描述為“人類翻譯器”,允許用戶查詢黑盒人工智能工作過程,即一個特定的高級概念在其訓練中發(fā)揮了多大作用。例如,如果一個機器學習系統(tǒng)被訓練來識別圖像中的斑馬,那么人們可以使用TCAV來確定系統(tǒng)在做出決策時“條紋”特征起了多重要的作用。
TCAV最初是在用于識別圖像的機器學習模型上進行測試的,但它也適用于文本和某些特定類型圖形數(shù)據(jù)(如腦電圖波形)的模型。 Kim表示,TCAV的通用性讓它能夠解釋許多不同的模型。
在Quanta雜志的采訪中Kim討論了可解釋性意味著什么,以及它為什么現(xiàn)在受到了這么多的關(guān)注。下面是一個經(jīng)過編輯和濃縮的采訪版本。
Q:你的職業(yè)生涯專注于機器學習的“可解釋性”,但那個詞究竟意味著什么呢?
A:可解釋性有兩個重要意義。對于科學研究來說:如果你把神經(jīng)網(wǎng)絡作為研究對象,那么你就可以進行科學實驗來真正理解模型的訓練過程、神經(jīng)元是如何反饋信息等各種細節(jié)。
而對于實際應用來說:用戶不必了解模型的每一個細節(jié),只要用戶能夠正確地使用該工具即可。這個方面是我最關(guān)注的,也是我們最終想要達到的目標。
Q:你為什么會對一個你不完全理解運作細節(jié)的系統(tǒng)有信心?
A:我給你打個比方。假設我后院有一棵樹,我想砍掉它,我可能會選擇使用電鋸去鋸樹。雖然現(xiàn)在,我不太了解電鋸的工作原理是什么,但電鋸的使用手冊上說明了使用步驟等信息,我可以安全地使用它。所以,有了這本手冊,我更愿意使用省時省力的電鋸,而不是更安全的手鋸。
就好像你知道怎么運用神經(jīng)網(wǎng)絡,但是你不完全知道這個機制是如何實現(xiàn)的?
對。這就是第二個可解釋性的目標是:我們能充分理解一個工具,以便安全地使用它。我們可以通過確認工具中反映出的有用的人類知識來形成理解。
Q:“反映人類知識體系”為什么會使黑盒子AI變得更容易理解?
A:再舉個例子解釋一下,如果醫(yī)生使用機器學習模型來進行癌癥診斷,那么醫(yī)生會想確認,該模型沒有關(guān)注不必要的數(shù)據(jù)點。確保這一點的一種方法就是確認機器學習模型會做一些醫(yī)生想要做的事情,換句話說,就是證明模型學習到了醫(yī)生的診斷知識。
因此,如果醫(yī)生正在使用一個細胞標本來診斷癌癥,他們是為了在標本中尋找一種叫做“融合腺”的東西。同時,他們還需要考慮患者的年齡,以及患者過去是否接受過化療等情況。這些都是醫(yī)生診斷癌癥時關(guān)心的因素,如果我們能證明機器學習模型也注意到了這些因素,那么模型就更容易被理解了,因為它反映了醫(yī)生的知識體系。
Google Brain的Been Kim正在研究如何讓我們理解機器學習系統(tǒng)做出的決定。
Q:那這就是TCAV的作用嗎?是為了揭示機器學習模型正在使用哪些高級概念來做出決策嗎?
A:對。在此之前,可解釋性方法只解釋了神經(jīng)網(wǎng)絡在“輸入特征”方面所做的工作。簡單來說,如果你有一張圖像,每個像素都作為一個輸入特征。事實上,Yann Lecun(一位早期的深度學習先驅(qū),目前是Facebook的人工智能研究主管)認為,神經(jīng)網(wǎng)絡模型已經(jīng)具有可解釋性,因為你可以查看神經(jīng)網(wǎng)絡中的每個節(jié)點,并查看每個輸入功能的數(shù)值。這對計算機來說沒問題,但人類的思維表示不是這樣的。我不會跟你說圖像的 100到200像素的RGB值是0.2和0.3,我會告訴你照片中狗的毛發(fā)特別蓬松,這就是人類描述的方式,我們是通過概念來溝通的。
Q:TCAV如何把輸入特征轉(zhuǎn)換為概念?
A:讓我們回到醫(yī)生使用機器學習模型的例子,例子中已經(jīng)訓練過的模型對細胞標本的圖像進行分類以確定潛在的癌癥。作為醫(yī)生,你可能想知道“融合腺體”的概念在預測癌癥時對模型的重要性。首先你要收集一些有融合腺體的圖像示例——假設你收集了20 幅。然后,你將這些帶標簽的示例輸入到模型中。
TCAV在模型內(nèi)部的作用被稱為“靈敏度測試”。當我們添加這些標記為融合腺體的圖片時,癌癥陽性預測的概率增加了多少,可以用0到1之間的數(shù)值來表示,那就是你的TCAV分數(shù)。如果概率增加,那么這是模型的一個重要概念。如果沒有,則不是一個重要概念。
Q:“概念”是一個模糊的術(shù)語。有沒有TCAV不起作用的時候?
A:如果你無法使用數(shù)據(jù)集的某些子集來描述你的概念,那么它就不起作用。如果你的機器學習模型是用圖像訓練的,那么這個概念必須得是可視化表達的。比方說我想在視覺上表達“愛情”的概念就真的很難。
我們也仔細驗證了這個概念。我們有一個統(tǒng)計測試程序,如果一個概念向量對模型的影響與隨機向量相同,那么這個概念向量就會被程序拋棄。如果你的概念沒有通過這個測試,那么TCAV會說:“我不知道。這個概念看起來不像對模型很重要的東西。”
Q:TCAV主要是用于在AI中建立信任,而不是真正理解它嗎?
A:不,不是這樣。接下來我會解釋原因,因為它很好區(qū)分。
我們從認知學和心理學的反復研究中得知人類非常容易上當受騙。這意味著,騙一個人相信任某些東西實際上很容易。而機器學習的可解釋性的目標正與此相反,它是要告訴你,使用某系統(tǒng)是否安全,并揭露背后的真相,所以“信任”這個詞的表達并不準確。
Q:所以“可解釋性”的意思是揭示AI推理中的潛在缺陷?
A:是的,正是這樣。
Q:它如何揭示這些潛在缺陷?
A:您可以使用TCAV向受過訓練的模型詢問不相關(guān)的概念。回到使用AI進行癌癥預測的醫(yī)生的例子,醫(yī)生可能會突然想到,“看起來機器對于許多帶藍色的圖像給出癌癥陽性預測。我們認為不應該考慮這個因素。”因此,如果TCAV對于“藍色”給出高評分,那么他們就發(fā)現(xiàn)了機器學習模型中的一個問題。
TCAV旨在找出現(xiàn)有不可解釋的AI系統(tǒng)。那為什么不從一開始就使用可解釋的系統(tǒng),而要使用黑盒呢?
可解釋性研究的其中一個方面是構(gòu)建反映人類理解過程的固有可解釋模型。但我認為:現(xiàn)在許多用于重要目的AI模型在一開始都沒有考慮可解釋性,這才是事實。比如,我們谷歌就有很多!你可以說,“既然解釋性是如此有用,那我為你建立另一個模型來取代你現(xiàn)有的模型吧。”好吧,那就祝你好運。
Q:那么你下一步要做什么?
決定這項技術(shù)是否對我們有利對我們來說仍然很關(guān)鍵。這就是我使用“事后可解釋性”方法的原因。如果某人給你一個模型并且你無法改變它,你如何為其行為生成解釋,以便你可以安全地使用它?這就是TCAV的工作。
Q:TCAV可以讓人類詢問AI某概念是否重要。但是如果我們不知道該問什么怎么辦?如果我們想讓AI系統(tǒng)自己給出解釋呢?
A:我們目前正在編寫的系統(tǒng)可以自動發(fā)掘概念。我們稱之為DTCAV——發(fā)掘型TCAV。但實際上,我認為增加人為操作,并實現(xiàn)機器與人之間的對話,是實現(xiàn)可解釋性的關(guān)鍵。
很多時候,在高風險的應用程序中,領(lǐng)域?qū)<乙呀?jīng)有了他們關(guān)心的概念列表。我們在Google Brain的醫(yī)療應用中不止一次看到這一點。他們不希望模型自己找出一系列概念——他們想要告訴模型他們感興趣的概念。我們與治療糖尿病視網(wǎng)膜病變(一種眼疾)的醫(yī)生一起工作,當我們告訴她什么是TCAV的時候她非常興奮,因為她已經(jīng)有很多關(guān)于這個模型可能做什么的假設,現(xiàn)在她正好可以驗證一下這些假設。TCAV實際上很有優(yōu)勢,因為它是一種以用戶為中心的協(xié)作機器學習方式。
Q:AI技術(shù)非常強大,你真的認為人們會因為其不具備可解釋性而放棄使用嗎?
A:是的,我認為是這樣。在專家系統(tǒng)上已經(jīng)發(fā)生過類似的事情了。20世紀80年代,使用專家系統(tǒng)執(zhí)行某些任務比雇傭人類操作員要便宜的多。但是現(xiàn)在誰還在使用專家系統(tǒng)?沒人。因此,很久以后我們也可能會放棄使用AI技術(shù)。
當然目前放棄AI不太可能,因為AI現(xiàn)在被炒的很熱,而且已經(jīng)投入了大量的資金。但從長遠來看,我認為人類可能會判定這種技術(shù)不適合我們,或許是出于恐懼,或許是因為其缺乏可解釋性,這都是有可能的。
-
谷歌
+關(guān)注
關(guān)注
27文章
6254瀏覽量
111407 -
AI
+關(guān)注
關(guān)注
91文章
39793瀏覽量
301431
原文標題:谷歌大腦開發(fā)機器思維的“人類翻譯器”,打破AI“黑盒”新方式
文章出處:【微信號:BigDataDigest,微信公眾號:大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
聲智科技AI翻譯耳機重塑智能聽覺體驗
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的科學應用
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+化學或生物方法實現(xiàn)AI
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+第二章 實現(xiàn)深度學習AI芯片的創(chuàng)新方法與架構(gòu)
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+可期之變:從AI硬件到AI濕件
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+內(nèi)容總覽
谷歌AI模型點亮開發(fā)無限可能
AI輸出“偏見”,人類能否信任它的“三觀”?

【書籍評測活動NO.64】AI芯片,從過去走向未來:《AI芯片:科技探索與AGI愿景》
【開源獲獎案例】AI智能交互新方案:基于T5L智能屏的AI DeepSeek大模型

AI耳機變身翻譯官+會議總結(jié)大師?涂鴉AI音頻開發(fā)方案,讓耳機升級到下一個level

飛騰軟件支持平臺即將正式上線AI智能大腦

NanoEdge AI Studio 面向STM32開發(fā)人員機器學習(ML)技術(shù)
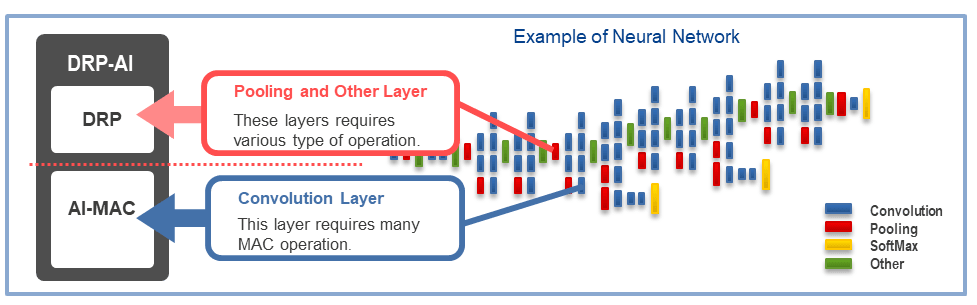
嵌入式AI加速器DRP-AI 詳細介紹



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論