") 基于深度學(xué)習(xí)模型的點(diǎn)云目標(biāo)檢測及ROS實(shí)現(xiàn)
基于深度學(xué)習(xí)模型的點(diǎn)云目標(biāo)檢測及ROS實(shí)現(xiàn)

近年來,隨著深度學(xué)習(xí)在圖像視覺領(lǐng)域的發(fā)展,一類基于單純的深度學(xué)習(xí)模型的點(diǎn)云目標(biāo)檢測方法被提出和應(yīng)用,本文將詳細(xì)介紹其中一種模型——SqueezeSeg,并且使用ROS實(shí)現(xiàn)該模型的實(shí)時(shí)目標(biāo)檢測。
傳統(tǒng)方法VS深度學(xué)習(xí)方法
實(shí)際上,在深度學(xué)習(xí)方法出現(xiàn)之前,基于點(diǎn)云的目標(biāo)檢測已經(jīng)有一套比較成熟的處理流程:分割地面->點(diǎn)云聚類->特征提取->分類,典型的方法可以參考Velodyne的這篇論文:LIDAR-based 3D Object Perception
▌那么傳統(tǒng)方法存在哪些問題呢?
1.第一步的地面分割通常依賴于人為設(shè)計(jì)的特征和規(guī)則,如設(shè)置一些閾值、表面法線等,泛化能力差;
2.多階段的處理流程意味著可能產(chǎn)生復(fù)合型錯(cuò)誤——聚類和分類并沒有建立在一定的上下文基礎(chǔ)上,目標(biāo)周圍的環(huán)境信息缺失;
3.這類方法對于單幀激光雷達(dá)掃描的計(jì)算時(shí)間和精度是不穩(wěn)定的,這和自動(dòng)駕駛場景下的安全性要求(穩(wěn)定,小方差)相悖。
因此,近年來不少基于深度學(xué)習(xí)的點(diǎn)云目標(biāo)檢測方法被提出,本文介紹的SqueezeSeg就是其中一種,這類方法使用深度神經(jīng)網(wǎng)絡(luò)提取點(diǎn)云特征,以接近于端到端的處理流程實(shí)現(xiàn)點(diǎn)云中的目標(biāo)檢測。
論文:SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud,
https://arxiv.org/pdf/1710.07368.pdf
SqueezeSeg理論部分
▌概括
SqueezeSeg使用的是CNN(卷積神經(jīng)網(wǎng)絡(luò))+CRF(Conditional Random Field,條件隨機(jī)場)這樣的結(jié)構(gòu)。
其中,CNN采用的是Forrest提出的SqueezeNet網(wǎng)絡(luò)(詳情見論文:“SqueezeNet: Alexnet-level accuracy with 50x fewer
parameters and < 0.5mb model size”, https://arxiv.org/pdf/1602.07360.pdf ), 該網(wǎng)絡(luò)使用遠(yuǎn)少于AlexNet的參數(shù)數(shù)量便達(dá)到了等同于AlexNet的精度,極少的參數(shù)意味著更快的運(yùn)算速度和小的內(nèi)存消耗,這是符合車載場景需求的。
被預(yù)處理過的點(diǎn)云數(shù)據(jù)(二維化)將被以張量的形式輸入到這個(gè)CNN中,CNN輸出一個(gè)同等寬高的標(biāo)簽映射(label map),實(shí)際上就是對每一個(gè)像素進(jìn)行了分類,然而單純的CNN逐像素分類結(jié)果會(huì)出現(xiàn)邊界模糊的問題,為解決該問題,CNN輸出的標(biāo)簽映射被輸入到一個(gè)CRF中,這個(gè)CRF的形式為一個(gè)RNN,其作用是進(jìn)一步的矯正CNN輸出的標(biāo)簽映射。最終的檢測結(jié)果論文中使用了DBSCAN算法進(jìn)行了一次聚類,從而得到檢測的目標(biāo)實(shí)體。
下面我們從預(yù)處理出發(fā),首先理解這一點(diǎn)云目標(biāo)檢測方法。
▌點(diǎn)云預(yù)處理
傳統(tǒng)的CNN設(shè)計(jì)多用于二維的圖像模式識別(寬 × imes× 高 × imes× 通道數(shù)),三維的點(diǎn)云數(shù)據(jù)格式不符合該模式,而且點(diǎn)云數(shù)據(jù)稀疏無規(guī)律,這對特征提取都是不利的,因此,在將數(shù)據(jù)輸入到CNN之前,首先對數(shù)據(jù)進(jìn)行球面投影,從而到一個(gè)稠密的、二維的數(shù)據(jù),球面投影示意圖如下:
其中,?和θ分別表示點(diǎn)的方位角(azimuth)和頂角(altitude),這兩個(gè)角如下圖所示:
通常來說,方位角是相對于正北方向的夾角,但是,在我們Lidar的坐標(biāo)系下,方位角為相對于x方向(車輛正前方)的夾角,?和θ的計(jì)算公式為:
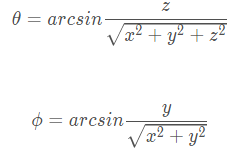
其中,(x,y,z) 為三維點(diǎn)云中每一個(gè)點(diǎn)的坐標(biāo)。所以對于點(diǎn)云中的每一個(gè)點(diǎn)都可以通過其 (x,y,z) 計(jì)算其 (θ,?) ,也就是說我們將三維空間坐標(biāo)系中的點(diǎn)都投射到了一個(gè)球面坐標(biāo)系,這個(gè)球面坐標(biāo)系實(shí)則已經(jīng)是一個(gè)二維坐標(biāo)系了,但是,為了便于理解,我們對其角度進(jìn)行微分化從而得到一個(gè)二維的直角坐標(biāo)系:

那么,球面坐標(biāo)系下的每一個(gè)點(diǎn)都可以使用一個(gè)直角坐標(biāo)系中的點(diǎn)表示,如下:
通過這么一層變換,我們就將三維空間中任意一點(diǎn)的位置(x,y,z) 投射到了2維坐標(biāo)系下的一個(gè)點(diǎn)的位置 (i,j) 我們提取點(diǎn)云中每一個(gè)點(diǎn)的5個(gè)特征: (x,y,z,intensity,range) 放入對應(yīng)的二維坐標(biāo) (i,j) 內(nèi)。從而得到一個(gè)尺寸為 (H,W,C) 張量(其中C=5),由于論文使用的是Kitti的64線激光雷達(dá),所以 H=64,水平方向上,受Kitti數(shù)據(jù)集標(biāo)注范圍的限制,原論文僅使用了正前方90度的Lidar掃描,使用512個(gè)網(wǎng)格對它們進(jìn)行了劃分(即水平上采樣512個(gè)點(diǎn))。所以,點(diǎn)云數(shù)據(jù)在輸入到CNN中之前,數(shù)據(jù)被預(yù)處理成了一個(gè)尺寸為 (64×512×5) 的張量。
▌CNN結(jié)構(gòu)
SqueezeSeg的CNN部分幾乎完全采用的SqueezeNet網(wǎng)絡(luò)結(jié)構(gòu),SqueezeNet是一個(gè)參數(shù)量極少但是能夠達(dá)到AlexNet精度的CNN網(wǎng)絡(luò),在對實(shí)時(shí)性有要求的點(diǎn)云分割應(yīng)用場景中采用頗有意義。其網(wǎng)絡(luò)結(jié)構(gòu)如下:
該網(wǎng)絡(luò)最大的特色為兩個(gè)結(jié)構(gòu),被稱為 fireModules 和 fireDeconvs,這兩種網(wǎng)絡(luò)層的具體結(jié)構(gòu)如下:
由于輸入的張量的高度(64)要小于其寬度(512),該網(wǎng)絡(luò)主要對寬度進(jìn)行降維,通過添加最大池化層(Max Pooling)降低數(shù)據(jù)的寬度。到Fire9輸出的是降維后的特征映射。為了得到一個(gè)完整的映射標(biāo)簽,還需要對特征映射進(jìn)行還原(即還原到原尺寸),conv14層的輸出即對每個(gè)點(diǎn)的分類概率映射。輸出最后被輸入到一個(gè)條件隨機(jī)場中進(jìn)行進(jìn)一步的矯正。
SqueezeSeg中采用的CRF
在深度學(xué)習(xí)技術(shù)不斷進(jìn)步的同時(shí),概率圖形模型已被開發(fā)為用于提高像素級標(biāo)記任務(wù)準(zhǔn)確性的有效方法。馬爾可夫隨機(jī)場(Markov Random Fields, MRF)及其變體——條件隨機(jī)場(Conditional Random Fields, CRF)已經(jīng)成為計(jì)算機(jī)視覺中最成功的概率圖模型之一。
由于CNN網(wǎng)絡(luò)的下采樣層(如最大池化層)的存在,使得數(shù)據(jù)的一些底層細(xì)節(jié)在CNN被拋棄,近而造成CNN輸出的預(yù)測分類存在邊界模糊的問題。高精度的逐像素分類不僅依賴于高層特征,也受到底層細(xì)節(jié)信息的影響,細(xì)節(jié)信息對于標(biāo)簽分類的一致性至關(guān)重要。打個(gè)比方,如果點(diǎn)云中兩個(gè)點(diǎn)相近,同時(shí)具有類似的強(qiáng)度值(intensity),那么它們就有可能屬于同一個(gè)目標(biāo)(即具有一樣的分類)。
CRF推理應(yīng)用于語義標(biāo)記的關(guān)鍵思想是將標(biāo)簽分配(對于像素分割來說就是像素標(biāo)簽分配)問題表達(dá)為包含類似像素之間具有一定標(biāo)簽協(xié)議的假設(shè)的概率推理問題。CRF推理能夠改進(jìn)像素級標(biāo)簽預(yù)測,以產(chǎn)生清晰的邊界和細(xì)粒度的分割。因此,CRF可用于克服利用CNN進(jìn)行像素級標(biāo)記任務(wù)的缺點(diǎn)。為了彌補(bǔ)下采樣過程中細(xì)節(jié)信息的損失,SqueezeSeg在最后使用RNN實(shí)現(xiàn)一個(gè)CRF推理,以對label map進(jìn)行進(jìn)一步精煉,這里作者參考了論文: Conditional Random Fields as Recurrent Neural Networks ,該論文提出了mean-field 近似推理,以帶有高斯pairwise的勢函數(shù)的密集CRF作為RNN,在前向過程中對CNN粗糙的輸出精細(xì)化,同時(shí)在訓(xùn)練時(shí)將誤差返回給CNN。結(jié)合了CNN與RNN的模型可以正常的利用反向傳播來端對端的訓(xùn)練。SqueezeSeg的CRF部分結(jié)構(gòu)如下圖所示:
我們將CNN的輸出結(jié)果作為CRF的輸入,根據(jù)原始點(diǎn)云計(jì)算高斯濾波器,其有兩個(gè)高斯核,如下所示:
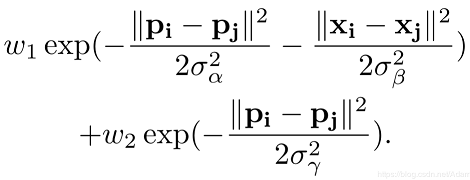
其中x為點(diǎn)的三維坐標(biāo) (x,y,z) ,p為點(diǎn)經(jīng)過球面投影得到的方位角和頂角 (θ,?),其他參數(shù)為經(jīng)驗(yàn)性閾值。該高斯核衡量了兩點(diǎn)之間特征的差異,兩點(diǎn)之間差異越大( x xx 和 p pp 相差越多),高斯核的值就越小,兩點(diǎn)之間的相關(guān)性也就越小。在輸入圖像使用該高斯濾波器的過程稱為message passing,可以初步聚合鄰域點(diǎn)的概率。接著,通過1x1大小的卷積核去微調(diào)每一個(gè)點(diǎn)的概率分布權(quán)重,這一個(gè)過程稱為re-weighting and compatibilty transformation,卷積核的值是通過學(xué)習(xí)得到。最后,以殘差方式將最初的便簽映射加到re-weighting的輸出結(jié)果并用softmax歸一化。在實(shí)際操作中,整個(gè)CRF以RNN層重復(fù)循環(huán)三次,并得到最終精煉后的標(biāo)簽映射。
使用SqueezeSeg實(shí)現(xiàn)一個(gè)ROS節(jié)點(diǎn)進(jìn)行點(diǎn)云目標(biāo)識別與分割
SqueezeSeg的模型訓(xùn)練代碼在本文中不在贅述,感興趣的同學(xué)可以直接去看作者的開源代碼:
SqueezeSeg作者開源的模型訓(xùn)練代碼:
https://github.com/BichenWuUCB/SqueezeSeg
上面的代碼為TensorFlow實(shí)現(xiàn),基于上述倉庫,我們實(shí)現(xiàn)一個(gè)ROS節(jié)點(diǎn),調(diào)用一個(gè)已經(jīng)訓(xùn)練好的SqueezeSeg模型,對輸入的點(diǎn)云進(jìn)行目標(biāo)識別和分割。所以在運(yùn)行下述實(shí)例代碼之前,需要自行安裝好TensorFlow-GPU版本(CPU版本亦可,但是運(yùn)行速度相對要慢一些),本文假定大家已經(jīng)安裝好TensorFlow環(huán)境,我們來繼續(xù)關(guān)注基于SqueezeSeg的ROS應(yīng)用開發(fā),我們采用論文作者公開的數(shù)據(jù)(來源于Kitti,采集自HDL-64雷達(dá),同時(shí)已經(jīng)完成了前向90度的切割,并且被保存成了npy文件)。
數(shù)據(jù)下載地址:
https://www.dropbox.com/s/pnzgcitvppmwfuf/lidar_2d.tgz?dl=0
國內(nèi)讀者如無法訪問,可以使用此地址下載:
https://pan.baidu.com/s/1kxZxrjGHDmTt-9QRMd_kOA
將數(shù)據(jù)下載好以后解壓到ROS package的 script/data/ 目錄下,解壓以后的目錄結(jié)構(gòu)為:
squeezeseg_ros/script/data/lidar_2d/
完整代碼見文末github倉庫。
采用作者開源的數(shù)據(jù)的一個(gè)很重要的原因在于手頭沒有64線的激光雷達(dá),首先我們看看launch文件內(nèi)容:
npy_path參數(shù)即為我們的數(shù)據(jù)的目錄,我們將其放在package的script/data目錄下,npy_file_list是個(gè)文本文件的路徑,它記錄了驗(yàn)證集的文件名,pub_topic指定我們最后發(fā)布出去的結(jié)果的點(diǎn)云topic名稱,checkpoint參數(shù)指定我們預(yù)先訓(xùn)練好的SqueezeSeg模型的目錄,它是一個(gè)TensorFlow 的checkpoint文件,gpu參數(shù)指定使用主機(jī)的那一快GPU(即指定GPU的ID),通常我們只有一塊GPU,所以這里設(shè)置為0,如果主機(jī)沒有安裝GPU(當(dāng)然TensorFlow-gpu也就無法工作),則會(huì)使用CPU。squeezeseg_ros_node.py即為我們調(diào)用模型的接口,最后我們在啟動(dòng)Rviz,加載設(shè)定好的Rviz配置文件,即可將模型的識別結(jié)果可視化出來。
具體到squeezeseg_ros_node.py中,首先加載參數(shù)并且配置checkpoint路徑:
rospy.init_node('squeezeseg_ros_node')npy_path=rospy.get_param('npy_path')npy_file_list=rospy.get_param('npy_file_list')pub_topic=rospy.get_param('pub_topic')checkpoint=rospy.get_param('checkpoint')gpu=rospy.get_param('gpu')FLAGS=tf.app.flags.FLAGStf.app.flags.DEFINE_string('checkpoint',checkpoint,"""Pathtothemodelparamterfile.""")tf.app.flags.DEFINE_string('gpu',gpu,"""gpuid.""")npy_tensorflow_to_ros=NPY_TENSORFLOW_TO_ROS(pub_topic=pub_topic,FLAGS=FLAGS,npy_path=npy_path,npy_file_list=npy_file_list)
循環(huán)讀取npy數(shù)據(jù)文件,讀取文件的代碼如下:
#Readall.npydatafromlidar_2dfolderdefget_npy_from_lidar_2d(self,npy_path,npy_file_list):self.npy_path=npy_pathself.npy_file_list=open(npy_file_list,'r').read().split(' ')self.npy_files=[]foriinrange(len(self.npy_file_list)):self.npy_files.append(self.npy_path+self.npy_file_list[i]+'.npy')self.len_files=len(self.npy_files)
調(diào)用深度學(xué)習(xí)模型對點(diǎn)云進(jìn)行分割和目標(biāo)檢測識別,并將檢測出來的結(jié)果以PointCloud2的msg格式發(fā)到指定的topic上:
#Readall.npydatafromlidar_2dfolderdefget_npy_from_lidar_2d(self,npy_path,npy_file_list):self.npy_path=npy_pathself.npy_file_list=open(npy_file_list,'r').read().split(' ')self.npy_files=[]foriinrange(len(self.npy_file_list)):self.npy_files.append(self.npy_path+self.npy_file_list[i]+'.npy')self.len_files=len(self.npy_files)defprediction_publish(self,idx):clock=Clock()record=np.load(os.path.join(self.npy_path,self.npy_files[idx]))lidar=record[:,:,:5]#toperformpredictionlidar_mask=np.reshape((lidar[:,:,4]>0),[self._mc.ZENITH_LEVEL,self._mc.AZIMUTH_LEVEL,1])norm_lidar=(lidar-self._mc.INPUT_MEAN)/self._mc.INPUT_STDpred_cls=self._session.run(self._model.pred_cls,feed_dict={self._model.lidar_input:[norm_lidar],self._model.keep_prob:1.0,self._model.lidar_mask:[lidar_mask]})label=pred_cls[0]#pointcloudforSqueezeSegsegmentsx=lidar[:,:,0].reshape(-1)y=lidar[:,:,1].reshape(-1)z=lidar[:,:,2].reshape(-1)i=lidar[:,:,3].reshape(-1)label=label.reshape(-1)cloud=np.stack((x,y,z,i,label))header=Header()header.stamp=rospy.Time().now()header.frame_id="velodyne_link"#pointcloudsegmentsmsg_segment=self.create_cloud_xyzil32(header,cloud.T)#publishself._pub.publish(msg_segment)rospy.loginfo("Pointcloudprocessed.Took%.6fms.",clock.takeRealTime())
不同于一般的PointCloud2 msg,這里的每一個(gè)點(diǎn)除了包含x,y,z,intensity字段以外,還包含一個(gè)label字段(即分類的結(jié)果),構(gòu)建5字段的PointCloud2 msg的代碼如下:
#createpc2_msgwith5fieldsdefcreate_cloud_xyzil32(self,header,points):fields=[PointField('x',0,PointField.FLOAT32,1),PointField('y',4,PointField.FLOAT32,1),PointField('z',8,PointField.FLOAT32,1),PointField('intensity',12,PointField.FLOAT32,1),PointField('label',16,PointField.FLOAT32,1)]returnpc2.create_cloud(header,fields,points)
使用launch文件啟動(dòng)節(jié)點(diǎn):
roslaunchsqueezeseg_rossqueeze_seg_ros.launch
彈出Rviz界面,識別分割如下:
在我的 CPU:i7-8700 + GPU:GTX1070的環(huán)境下,處理一幀數(shù)據(jù)的耗時(shí)大約在50ms以內(nèi),如下:
對于semantic segmentationz這類任務(wù)而言,其速度已經(jīng)比較可觀了,通常雷達(dá)頻率約為10HZ,該速度基本達(dá)到要求。
-
無人駕駛汽車
+關(guān)注
關(guān)注
18文章
151瀏覽量
38598 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5602瀏覽量
124567
原文標(biāo)題:無人駕駛汽車系統(tǒng)入門:基于深度學(xué)習(xí)的實(shí)時(shí)激光雷達(dá)點(diǎn)云目標(biāo)檢測及ROS實(shí)現(xiàn)
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【智能檢測】基于AI深度學(xué)習(xí)與飛拍技術(shù)的影像測量系統(tǒng):實(shí)現(xiàn)高效精準(zhǔn)的全自動(dòng)光學(xué)檢測與智能制造數(shù)據(jù)閉環(huán)
穿孔機(jī)頂頭檢測儀 機(jī)器視覺深度學(xué)習(xí)
【團(tuán)購】獨(dú)家全套珍藏!龍哥LabVIEW視覺深度學(xué)習(xí)實(shí)戰(zhàn)課(11大系列課程,共5000+分鐘)
【團(tuán)購】獨(dú)家全套珍藏!龍哥LabVIEW視覺深度學(xué)習(xí)實(shí)戰(zhàn)課程(11大系列課程,共5000+分鐘)
自動(dòng)駕駛模型是如何“看”懂點(diǎn)云信息的?
廣和通發(fā)布端側(cè)目標(biāo)檢測模型FiboDet
AI 輔助逆向抄數(shù):點(diǎn)云優(yōu)化工具與深度學(xué)習(xí)建模能力在消費(fèi)電子領(lǐng)域的應(yīng)用

AI 驅(qū)動(dòng)三維逆向:點(diǎn)云降噪算法工具與機(jī)器學(xué)習(xí)建模能力的前沿應(yīng)用
自動(dòng)駕駛中Transformer大模型會(huì)取代深度學(xué)習(xí)嗎?

基于LockAI視覺識別模塊:C++目標(biāo)檢測
提高IT運(yùn)維效率,深度解讀京東云AIOps落地實(shí)踐(異常檢測篇)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論