 混合MI-SSVEP是否真的是更優的范式?
混合MI-SSVEP是否真的是更優的范式?

穩態視覺誘發電位是一種基于視覺刺激的腦機接口范式,當用戶注視以固定頻率(如6.67Hz或8.57Hz)閃爍的視覺刺激時,大腦枕區視覺皮層會產生相同頻率及其諧波的周期性電活動,通過檢測這些頻率成分即可識別用戶的注視目標,從而實現指令輸出。SSVEP范式具有識別速度快、解碼準確率高、可擴展指令類別多等優點,已被廣泛應用于外部設備控制和文本拼寫系統中。然而,該范式存在一個顯著弊端:用戶需要長時間持續注視屏幕上的閃爍刺激,這種高頻率的光學刺激容易引發視覺疲勞、注意力下降甚至頭暈等不適感,尤其當刺激頻率較低時閃爍感更為明顯,限制了其在需要長時間使用的實際應用場景中的推廣。

圖1:三種BCI模式示意圖
圖1展示了本研究所涉及的三種工作模式。左側為MI模式,受試者僅通過想象左手或右手運動產生腦電信號,無需外部視覺刺激。中間為SSVEP模式,受試者注視左側或右側以特定頻率(6.67Hz或8.57Hz)閃爍的刺激,誘發穩態視覺誘發電位。右側為混合模式,受試者在注視閃爍刺激的同時,想象與刺激方向一致的手部運動,兩種任務并行執行,系統同時采集MI和SSVEP信號進行聯合解碼。
HUIYING
運動想象(MI)范式概述
運動想象范式要求用戶在沒有任何實際肢體動作的情況下,想象特定肢體(如左手或右手)的運動過程,此時大腦運動皮層會被激活并產生與真實運動相似的神經放電模式,這些模式可通過腦電電極在感覺運動皮層區域(如C3、C4等導聯)記錄到。MI范式的最大優勢在于無需外部刺激,用戶僅憑意念即可控制外部設備,特別適用于運動功能障礙患者(如脊髓損傷或中風后遺癥)的康復訓練和輔助設備控制。然而,MI范式存在解碼準確率偏低和可識別指令類別較少的突出問題。論文數據顯示,傳統單流CNN在MI模式下的平均解碼準確率僅為70.4%,遠低于SSVEP模式的93.7%;同時,不同用戶之間的MI腦電特征差異較大,部分受試者甚至難以產生可辨識的運動想象模式,導致系統魯棒性不足。
HUIYING
混合MI-SSVEP范式概述
混合腦機接口范式是指將兩種或多種單一范式(如MI和SSVEP)進行融合,使用戶可以同時或先后執行不同類型的腦活動任務,系統綜合多種信號特征進行聯合解碼,以期提高整體識別性能。研究表明,混合范式能夠顯著提升解碼準確率,并且具備良好的用戶適應性——對MI不敏感的用戶可能在SSVEP上表現良好,反之亦然;即使某一用戶單獨使用MI或SSVEP均無法達到理想效果,混合模式下仍可能獲得可識別的神經模式。然而,傳統混合BCI方法通常需要為每種范式設計獨立的特征提取流程(如對MI使用公共空間模式CSP、對SSVEP使用典型相關分析CCA),再將提取的特征進行拼接或加權融合,這種分離處理方式不僅增加了系統復雜度,還降低了特征提取效率和模型的泛化能力,難以實現端到端的聯合優化。
HUIYING
實驗研究
研究方法
數據集來源:采用韓國大學腦與認知工程系公開數據集,共54名受試者,包含二分類MI任務和四分類SSVEP任務。本研究僅使用訓練階段數據,選取SSVEP中代表左右方向的兩種頻率(6.67Hz和8.57Hz)進行二分類。
電極選擇與預處理:MI任務選取20個運動皮層區域電極(FC-5/3/1/2/4/6、C-5/3/1/2/4/6、CP-5/3/1/2/4/6);SSVEP任務選取10個枕區電極(P-7/3/2/4/8、PO-9/10、O-1/2/2)。原始EEG信號經8~30Hz帶通濾波(5階Butterworth數字濾波器),并分割為0~4000ms的片段。整個預處理流程如圖2中的A和B部分所示。

圖2:TSCNN整體框架圖
圖2分為A、B、C三個部分詳細展示了雙流卷積神經網絡的工作流程。A部分為EEG記錄與預處理,原始信號經8~30Hz帶通濾波后分割為4秒長度的片段。B部分為通道選擇,分別從運動皮層區域選取20個電極用于MI分支,從枕區選取10個電極用于SSVEP分支。C部分為分類網絡,MI分支和SSVEP分支各自包含空間卷積層(跨通道卷積)和時間卷積層,兩分支輸出的特征圖在融合層進行拼接,再經全連接層和Sigmoid函數輸出左右二分類結果
模型架構:提出雙流卷積神經網絡(TSCNN),包含MI分支和SSVEP分支,每個分支先進行空間卷積(跨通道)再進行時間卷積,兩個分支的輸出特征圖在融合層拼接后送入全連接層進行分類,如圖2中的C部分所示。
訓練策略:設置兩種訓練方式——TSCNN?僅使用混合模式EEG數據(40名受試者×50次試驗=2000樣本);TSCNN?聯合使用單模式與混合模式數據(40名受試者×100次試驗=4000樣本),其中單模式訓練時對未激活分支的輸入補零。采用10折交叉驗證,Adam優化器,學習率0.00025,dropout率50%。
評估指標:準確率、敏感度、特異度、均方誤差。測試集為剩余14名受試者的數據。對比模型為單流CNN(SCNN)。
研究結果
解碼性能對比:如表I所示,TSCNN?在混合模式下達到最高準確率95.6%(敏感度96.4%,特異度94.8%),相比MI單模式(70.2%)提升25.4%,相比SSVEP單模式(93.0%)提升2.6%。同時,TSCNN?在MI單模式(70.2%)和SSVEP單模式(93.0%)上的表現與SCNN(分別為70.4%和93.7%)相當,說明聯合訓練策略在提升混合模式性能的同時保留了單模式解碼能力。
超參數影響:全連接層維度為16時MI準確率最佳(70.4%);卷積核數量為(1,1)時整體性能最優;dropout率對MI模式影響顯著(50%時準確率最高),而對SSVEP和混合模式影響不明顯,如圖3所示;四種激活函數(ReLU、ELU、Softplus、LeakyReLU)在三種模式下均無顯著差異,如圖4所示。

圖3:不同Dropout率對解碼準確率的影響
圖3展示了在MI模式(左)、SSVEP模式(中)和混合模式(右)下,分別使用0%、25%、50% dropout率時的解碼準確率變化。結果顯示,在MI模式中,50% dropout率顯著提高了準確率;而在SSVEP和混合模式中,不同dropout率對準確率的影響不明顯。這表明較高的dropout率主要對特征相對較弱的MI任務起到防止過擬合、提升泛化能力的作用。

圖4:不同激活函數對解碼準確率的影響
圖4比較了ReLU、ELU、Softplus、LeakyReLU四種激活函數在MI模式(左)、SSVEP模式(中)和混合模式(右)下的解碼準確率。圖4中可以看出,四種激活函數在各模式下的準確率曲線高度接近,沒有顯著差異。這說明對于本研究的TSCNN架構和EEG解碼任務,激活函數的選擇不是影響性能的關鍵因素。
特征可視化:采用t-SNE對TSCNN?各層特征進行降維可視化(如圖5所示),結果顯示:MI分支輸入特征(圖5a)和SSVEP分支輸入特征(圖5d)中左右兩類數據點混合較為嚴重;經過空間和時間卷積層后,兩類點的分離程度逐漸提高;在融合層的全連接層輸出(圖5g)中,左右兩類數據點呈現清晰的簇狀分離,證明融合特征具有最強的判別能力。

圖5:TSCNN?各層特征的t-SNE可視化
圖5對受試者20~30的數據在TSCNN?的不同網絡層進行二維t-SNE降維可視化,藍色和紅色分別代表左、右兩類。圖5(a)~(c)為MI分支:輸入層特征(a)中兩類混雜嚴重,空間卷積層(b)出現一定分離趨勢,時間卷積層(c)分離更明顯。圖5(d)~(f)為SSVEP分支:輸入層(d)已有一定區分度,空間卷積層(e)和時間卷積層(f)后兩類點呈現清晰的簇狀分離。圖5(g)為融合后的全連接層特征,左右兩類數據點被明顯劃分為兩個緊湊的簇,證明融合特征具有最強的判別能力。
權重解釋分析:通過統計全連接層中超過不同閾值的連接權重數量(如表IV和圖6所示),發現隨著閾值升高,TSCNN?的MI與SSVEP權重數量比值逐漸下降(從0.963降至0.667),而TSCNN?的比值則持續上升(從0.987升至1.439)。這表明聯合訓練策略顯著增強了模型對MI特征的表達能力,避免了SSVEP特征在融合中主導而掩蓋MI特征。

圖6:TSCNN?與TSCNN?中MI/SSVEP連接權重比例隨閾值變化曲線
圖6的橫軸為連接權重的閾值(從0.0025到0.0125),縱軸為MI分支連接權重數量與SSVEP分支連接權重數量的比值(ratio)。藍色曲線代表TSCNN?,紅色曲線代表TSCNN?。隨著閾值提高,TSCNN?的比值逐漸下降(從約0.96降至0.67),而TSCNN?的比值持續上升(從約0.99升至1.44)。這表明TSCNN?通過聯合訓練策略顯著增強了對MI特征的表達能力,避免了SSVEP特征在融合中占據主導地位而掩蓋MI特征。
統計檢驗:配對t檢驗顯示,TSCNN?在MI模式上顯著優于TSCNN?(p=2.94×10??),而在SSVEP和混合模式上無顯著差異(p=0.048和p=0.561,以α=0.01計);TSCNN?與SCNN在MI和SSVEP模式上均無顯著差異(p=0.598和p=0.008),證明TSCNN?是一種兼顧單模式和混合模式的高通用性模型。
HUIYING
總結
本文提出了一種基于雙流卷積神經網絡(TSCNN)的混合腦機接口系統,融合運動想象(MI)與穩態視覺誘發電位(SSVEP)兩種范式。該方法通過端到端的深度學習自動提取兩種范式的時空特征,避免了傳統方法中為不同范式分別設計特征提取器的低效問題。論文創新性地設計了聯合訓練策略(TSCNN?),使模型在混合模式下達到95.6%的高解碼準確率,同時保留MI模式(70.2%)和SSVEP模式(93.0%)的單模式可用性。通過t-SNE特征可視化(如圖5)和連接權重分析(如圖6)驗證了模型的可解釋性。該研究為腦機接口系統在實際應用中的靈活適配提供了新思路——不同殘障程度或不同神經活動特征的用戶可根據自身條件選擇單模式或混合模式使用,且模型具備跨受試者泛化能力。未來工作可探索更短時間窗口的實時解碼、引入半監督或無監督學習以降低標注依賴,以及集成更先進的單模式深度學習架構進一步提升混合解碼性能。
-
醫療電子
+關注
關注
31文章
1458瀏覽量
92215 -
腦機接口
+關注
關注
10文章
438瀏覽量
22551
發布評論請先 登錄
什么是編程范式?常見的編程范式有哪些?各大編程范式詳解
范式間區別
以DAC為例,介紹AMS-Design數模混合電路仿真的方法是什么?
HarmonyOS/OpenHarmony應用開發-ArkTS的聲明式開發范式
基于仿真的設計集成提高混合動力車輛的可靠性
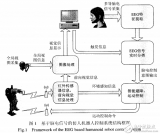
基于SSVEP方式的仿人機器人控制系統的設計
曦智研究院發布光電混合計算系列白皮書,以大規模光電集成構建算力網絡新范式
QT原生的QJson是否有更優雅的方法來封裝一些Json對象


變頻器是否真的省電?
編碼調制視覺誘發電位cVEP是否能解決疲勞的問題?




 工商網監
工商網監
評論