 想用RK3588在邊緣端跑大模型?你的算力還差多少?
想用RK3588在邊緣端跑大模型?你的算力還差多少?

在邊緣計算與嵌入式AI應用飛速發展的今天,瑞芯微RK3588平臺憑借其強大的多媒體處理能力和6TOPS的NPU算力,已成為高端AIoT項目的首選之一。然而,面對日益復雜的大模型(LLM)部署需求與高并發的視覺推理任務,單一的SoC算力往往面臨瓶頸。
為此,瑞芯微推出了專為算力擴展設計的RK1820 AI加速卡。本文將以EASY-EAI的MONSTER(RK3588)開發板為例,提供一份從硬件對接到模型部署的完整適配指南,并對其性能進行實測分析,為開發者實現算力升級提供切實可行的技術路徑。
PART.01
核心硬件:
RK1820加速卡與RK3588的協同架構
RK1820加速卡概覽
RK1820是一款采用PCIe接口的獨立AI加速卡,其核心設計目標是作為主控SoC的協處理器,專攻高強度、批量的AI推理任務。其關鍵特性如下:
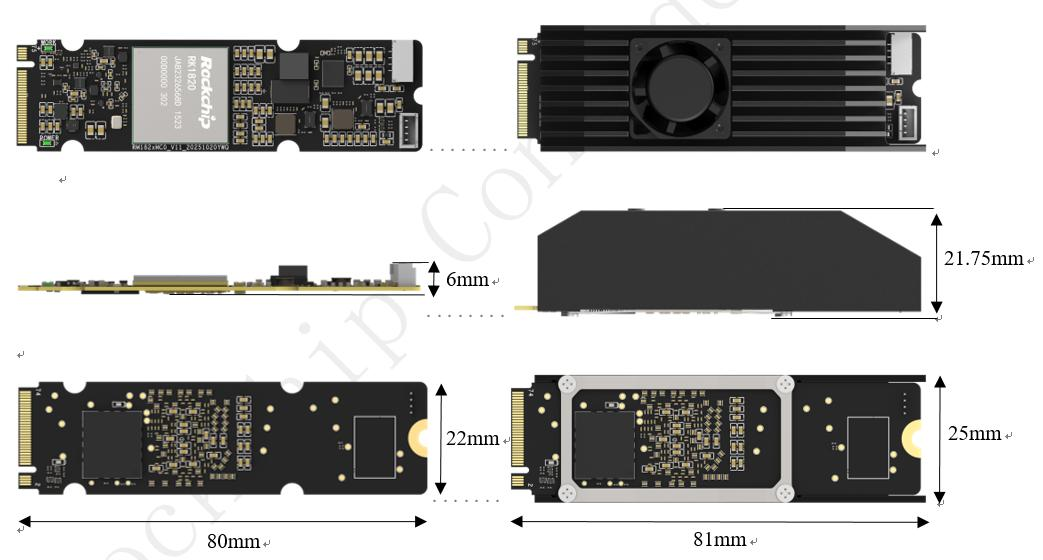
高密度算力:提供高達20 TOPS@INT8的峰值算力,足以應對大多數視覺大模型及十億參數級別的語言模型。
大容量板載內存:集成2.5GB專用內存,能夠將大型模型完全載入,避免頻繁通過PCIe總線與主機交換數據,從而顯著降低推理延遲。
標準接口:采用M.2 Key M接口,便于與具備PCIe通道的RK3588核心板或開發板快速集成。
RK3588 + RK1820的異構計算模式
在此方案中,RK3588與RK1820構成了一個典型的異構計算系統:
RK3588(主機):負責運行完整的操作系統(如Ubuntu)、處理通用計算、多媒體編解碼、系統調度以及輕量級或實時性要求高的AI任務。
RK1820(設備):作為專用的AI推理加速器,接收來自主機的推理任務和數據,利用其高并行計算單元完成高效處理,并將結果返回。
這種分工實現了計算資源的優化配置,使RK3588平臺的能力邊界得以大幅擴展,尤其適合智能NVR(多路視頻結構化分析)、服務機器人、邊緣AI服務器及需要端側運行大語言模型的場景。
 PART.02
PART.02
軟硬件適配與驅動部署
*以下適配流程基于EASY-EAI-MONSTER開發板及配套的軟件包
硬件連接與準備
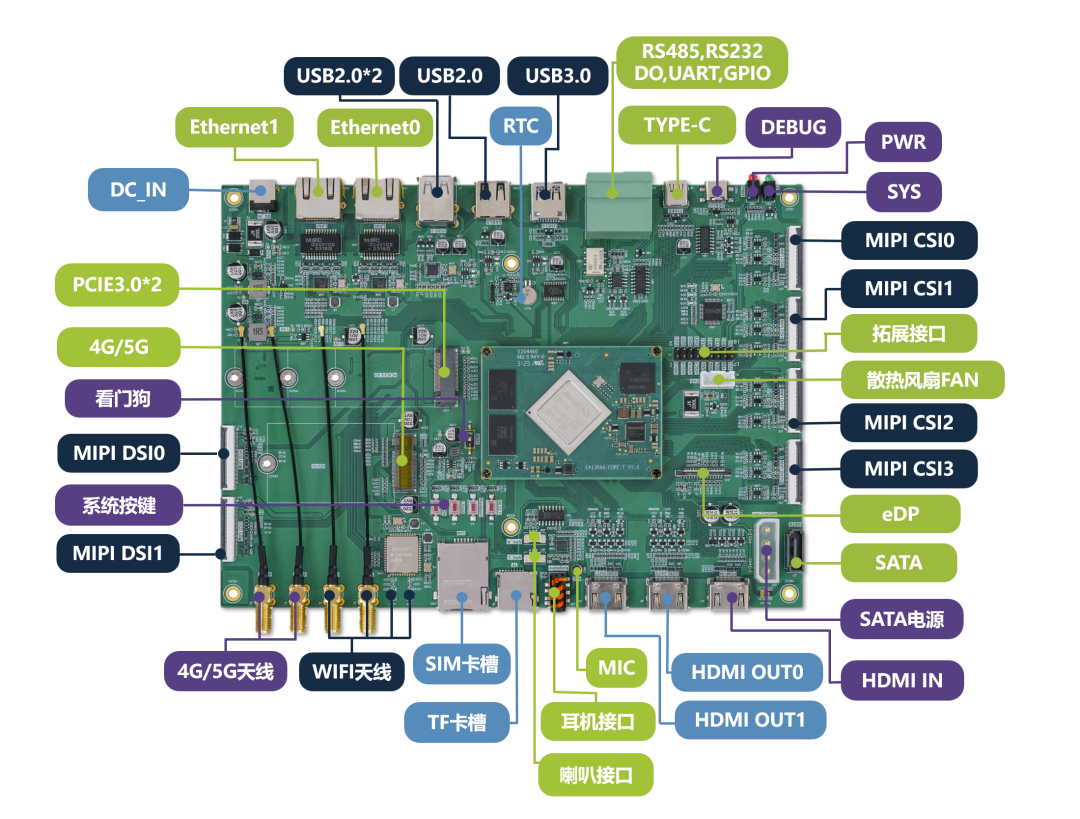
硬件:EASY-EAI-MONSTER開發板、RK1820 M.2加速卡、12V/3A電源(為算力卡獨立供電)。
連接順序:務必先將RK1820加速卡插入主板的M.2插槽并連接好12V供電,然后再為開發板上電。此順序可確保PCIe設備能被系統正確識別枚舉。
軟件基礎:開發板需預先燒錄適配后的固件(如EASY-EAI-Monster-Ubuntu 22.04-firmware_20260407或更新版本)。
驅動安裝與驗證
將提供的適配套件rknn3_rk182x_sodimm_installer_arm64.tgz拷貝至開發板,并按順序執行以下命令:

安裝腳本將自動部署PCIe驅動(pcie-rkep)、用戶態庫及相關服務。
設備驗證
重啟后,可通過以下命令驗證適配是否成功:
檢查PCIe設備識別:執行lspci,列表中應出現Rockchip Electronics Co., Ltd Device 182a的設備信息。

檢查驅動加載:執行dmesg | grep pcie-rkep,查看驅動加載日志,確認無錯誤信息。
檢查設備節點:執行ls -l /dev/pcie-rkep*,確認驅動已創建設備節點。
查看算力卡狀態:執行rknn-smi info,此命令可顯示RK1820的詳細信息,包括設備名稱、算力利用率和內存使用情況,是驗證加速卡是否就緒的最直接方式。
PART.03
模型部署與性能實測
適配成功后,即可利用RKNN工具鏈將模型部署到RK1820上運行。套件中提供了rknn3_model_test和rknn3_session_test兩個測試程序,分別用于傳統視覺模型和大語言模型。
視覺模型測試
(以YOLOv5s為例)
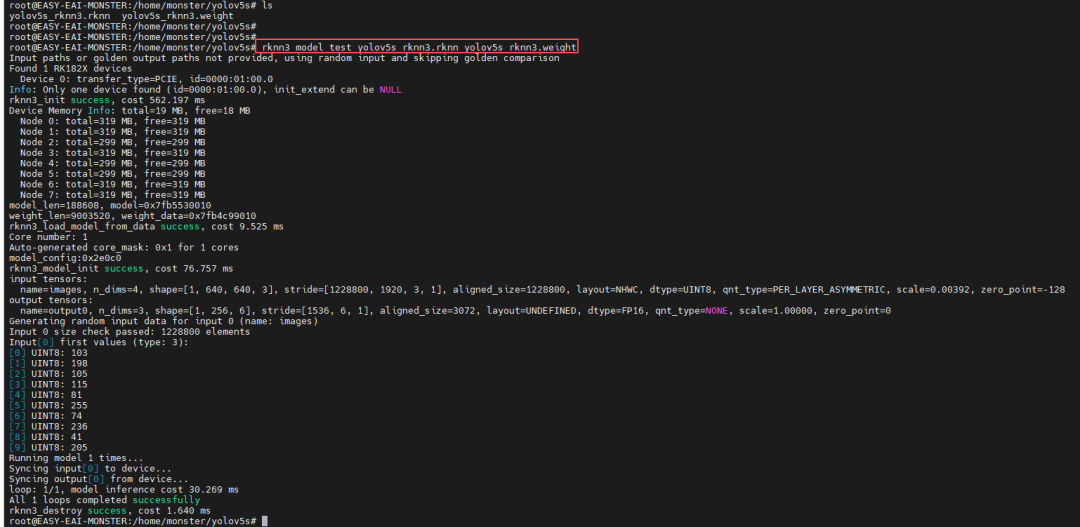
模型準備:使用RKNN-Toolkit2將訓練好的YOLOv5s模型轉換為RK1820支持的.rknn格式。
執行推理:將模型文件置于板端,運行以下命令:

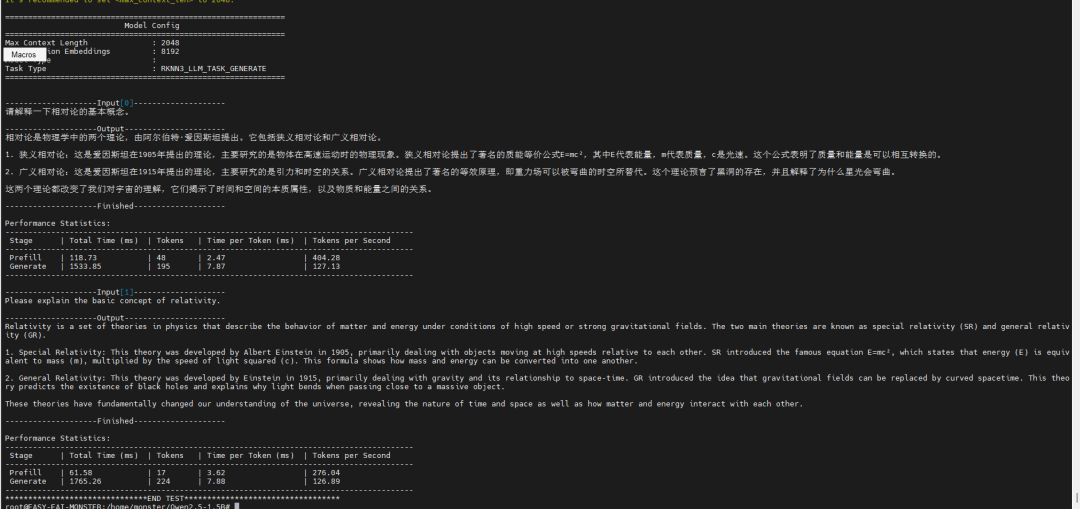
性能指標:在測試中,YOLOv5s模型在RK1820上的單次推理耗時約為30.27毫秒,展現了其處理實時視覺任務的高效能力。
大語言模型測試
(以Qwen2.5-1.5B為例)
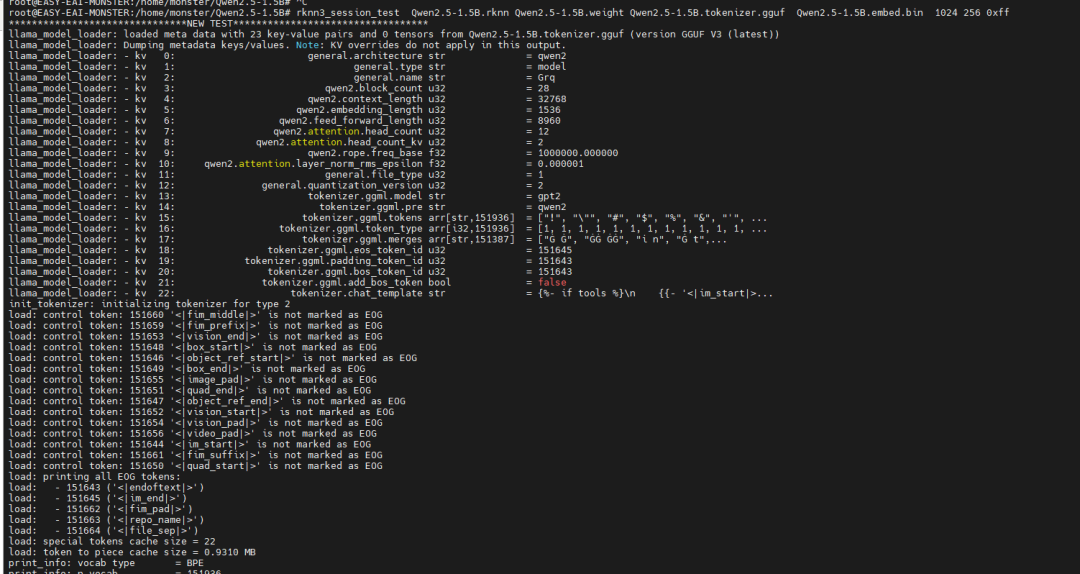
模型準備:需要準備轉換后的Qwen2.5-1.5B.rknn模型文件、權重文件(.weight)、分詞器文件(.tokenizer.gguf)和嵌入層文件(.embed.bin)。
執行推理:由于大模型運行通常需要獨立的模型服務,需先停止系統默認的rknpu服務,然后啟動會話測試:

能力驗證:此測試將啟動一個交互式會話,開發者可以直接輸入文本,模型將基于RK1820的算力進行生成式回復,直觀驗證了在邊緣端部署并運行十億參數級大模型的可行性。
 PART.04
PART.04
應用場景與開發建議
典型應用場景
多路高性能視頻分析:利用RK3588強大的解碼能力處理多路視頻流,將解碼后的畫面數據通過PCIe總線發送給RK1820進行高精度、高并發的目標檢測與識別。
邊緣AI服務器:在局域網內部署,為多個終端提供低延遲的AI服務,如智能客服、代碼輔助、文檔摘要等。
復雜環境下的機器人:同時處理激光雷達、視覺、語音等多模態傳感器的輸入,進行實時融合感知與決策。
開發建議
任務劃分:將時延敏感、控制相關的輕量模型放在RK3588 NPU上運行;將計算密集、允許微秒級延遲的批量推理任務卸載到RK1820。
數據傳輸優化:盡量減少主機與加速卡之間不必要的內存拷貝,利用零拷貝等技術優化PCIe數據傳輸效率。
功耗管理:在連續推理任務中,RK1820的功耗是需要考慮的因素。在間歇性工作場景,可通過驅動接口管理其工作狀態以實現能效平衡。
通過上述適配,RK3588平臺成功融合了RK1820加速卡的20TOPS算力,構建了一個總計超過26TOPS的強勁邊緣AI系統。本次實踐表明,該方案軟硬件集成度較高,驅動安裝便捷,為開發者提供了清晰的從驗證到部署的路徑。無論是提升現有視覺應用的性能密度,還是探索在邊緣設備運行大語言模型這一前沿領域,RK3588+RK1820的組合都提供了一個穩定而強大的硬件基礎。
-
EASY-EAI靈眸科技
+關注
關注
4文章
82瀏覽量
3709 -
算力
+關注
關注
2文章
1619瀏覽量
16817 -
RK3588
+關注
關注
8文章
582瀏覽量
7501 -
大模型
+關注
關注
2文章
3723瀏覽量
5254
發布評論請先 登錄
國產RK182X算力協處理器 + RK3588實測,大模型“極速流暢”

Hailo-8算力卡 + RK3588實測!26TOPS加持,助力AI視覺升級!

RK3588操控終端

RK3588平臺USB攝像頭調試實戰:從報錯到穩定運行
RK3588 6TOPS算力如何落地,鋇錸技術AXMxy BL450告訴您!
揭秘瑞芯微算力協處理器,RK3576/RK3588強大算力搭檔

RK這2款旗艦芯片RK3588 PK RK3576,誰是最優選
RK3576 vs RK3588:為何越來越多的開發者轉向RK3576?

RK3588S和RK3588S2差異說明



 工商網監
工商網監
評論