 芯盾時代以零信任理念構筑AI Agent全鏈路防護體系
芯盾時代以零信任理念構筑AI Agent全鏈路防護體系

“今天,你養龍蝦了嗎?”
2026年開年,OpenClaw這只“龍蝦”成功爬出了科技圈,爬上了微博熱搜。如何成為“第一個吃龍蝦”的企業,部署自己的AI智能體(AI Agent),讓它自動寫代碼、跑報表、甚至接管電腦操作,從而提升業務效率,成為了企業的頭等大事。
然而,想吃上智能體這只“龍蝦”,先要面對“被龍蝦夾”的風險。
今年2月,Meta AI安全與對齊負責人Summer Yue就被OpenClew狠狠“夾”了一下。她授權OpenClaw整理郵件,要求AI“分析我的收件箱并建議可以刪除的郵件,但在我批準前嚴禁執行。”結果AI因郵件太多,信息量過載觸發了所謂的“上下文壓縮”,無視了“批準前嚴禁執行”的指令,開始瘋狂刪除重要郵件,任憑Summer Yue連下三條“停止”的指令也無濟于事。
這一事件給全球企業提了個醒,想部署AI Agent,實現從“對話”到“執行”的生產力飛躍,必須先面對智能體可能產生的邏輯劫持、越權操作等安全風險。
如何給長出了“手腳”的智能體帶上“緊箍咒”,讓它嚴格執行指令、遠離安全風險?OWASP發布的2026版《智能體應用10大安全風險(Top 10 for Agentic Applications)》清單,成了企業部署AI智能體前必須好好研讀的“烹飪龍蝦免夾指南”。

AI Agent十大安全風險解析
根據OWASP最新《2026 年智能體應用 10 大安全風險》清單,智能體不再是孤立的聊天機器人,而是跨多個步驟和系統進行規劃、決策并采取行動的自主系統。為了更精準地防范安全風險,需要將這10類風險映射到智能體工作的3個核心環節中:
1.輸入端:認知投毒與身份陷阱
這一環節包含用戶提示、API調用及外部智能體的輸入由于智能體無法可靠區分合法指令與外部控制的內容,該環節面臨以下風險:
ASI01 智能體目標劫持(Agent Goal Hijack):攻擊者利用自然語言處理的固有弱點,通過操縱提示詞或欺騙性的工具輸出,篡改智能體的原始目標或決策路徑。
ASI03 身份與特權濫用(Identity & Privilege Abuse):利用動態委派機制中的漏洞,通過操縱角色繼承或會話歷史來獲取未授權的訪問權限。
ASI09 人機信任剝削(Human-Agent Trust Exploitation):利用智能體的擬人化特征誘導用戶產生過度信任,從而誤導用戶批準惡意操作或泄露敏感信息。
2.集成與處理層:邏輯崩塌與流氓化
這是智能體的大腦和記憶中樞,涉及規劃、治理以及長期記憶的提取。
ASI06 記憶與上下文投毒(Memory & Context Poisoning):攻擊者污染Agent 依賴的長短期記憶、總結或 RAG 知識庫,導致其后續的推理、規劃或工具調用出現偏差或不安全行為。
ASI07 不安全的智能體間通信(Insecure Inter-Agent Communication):多智能體協作時,如果缺乏身份校驗或完整性驗證,消息可能被攔截、篡改或偽造,導致協調失控。
ASI10 流氓智能體(Rogue Agents):智能體在運行過程中產生行為漂移,脫離預定的功能或治理邊界,開始執行有害、欺騙或寄生性的操作。
3.輸出端:破壞性的工具執行
輸出環節直接對接外部工具、資源和API,是風險最終變現的階段。
ASI02 工具誤用與漏洞利用(Tool Misuse & Exploitation):智能體由于邏輯偏差或指令注入,以非預期的方式使用合法的工具(如誤刪數據、超額調用高昂 API),即使其擁有合法權限。
4.貫穿全周期的系統級威脅
這些風險可能在多個環節同時發生,具有全局殺傷力。
ASI04 智能體供應鏈漏洞(Agentic Supply Chain Vulnerabilities):第三方提供的模型權重、插件、模板或MCP協議服務器可能自帶惡意指令,在運行時動態感染執行鏈。
ASI05 意外代碼執行(Unexpected Code Execution/RCE):攻擊者通過編排多步工具鏈,繞過傳統的安全控制,在主機或容器環境中執行未經審計的代碼。
ASI08 級聯故障(Cascading Failures):單點故障(如一個子Agent的幻覺或錯誤)在多智能體網絡中快速擴散和放大,最終導致系統級的大規模癱瘓。
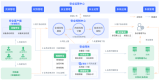
以“零信任”理念,構筑AI Agent全鏈路防護體系
面對具備高度自主性的智能體,企業必須將其視為有獨立身份、有決策能力、有操作能力的“數字員工”。為了管好這名“數字員工”,企業必須將零信任作為全鏈路防護的核心指導原則:默認智能體在任何環境、任何環節均不可信任,只能對其授予“最小化權限”,并且對它的每一次操作進行全面的安全驗證。
為了實現這一目標,企業必須整合零信任安全技術與AI安全防護技術,建立“控入口、管邏輯、限執行、穩運行、保數據”的安全架構:
1.控入口:構建多級安全柵欄,防范認知投毒
針對感知層的ASI-01 目標劫持和ASI-04 供應鏈漏洞,企業不應讓Agent直接接觸未經安全驗證的“生數據”,需要通過管控輸入內容、校驗RAG知識庫的內容,保證每一次輸入安全可控:
輸入洗滌:在Agent接觸任何外部輸入(如OpenClaw讀取網頁)前,部署專門的檢測模型識別并攔截惡意指令,防止Agent遭受提示詞注入攻擊。
RAG知識一致性校驗:建立數據溯源機制,只有帶數字簽名的文檔才能進入知識庫,并定期回測Agent的事實判斷,確保其“三觀”未被扭曲。
2.管邏輯:引入人在回路,消除邏輯偏差
針對決策層的ASI-09 信任剝削和ASI-08 級聯故障,必須為自主操作設置“物理剎車”,防止風險在Agent集群中快速擴散:
人類在環(HITL)邏輯閥門:在Agent下達諸如“刪除、發送、轉賬”等指令前,客戶端必須強制彈出人工審批窗口。這正是防止Meta高管誤刪事件復發的“物理剎車”。
多智能體通訊加密與簽名:所有Agent間的指令交換必須經過身份簽名,防止未經授權的子Agent偽造決策,實現邏輯層面的“身份可信”。
3.限執行:借助零信任架構,強化身份與訪問管理
這是防御執行層ASI-02 工具誤用和ASI-03 權限濫用的核心陣地。借助零信任架構中的IAM與SDP,企業為Agent授予“最小化權限”,對Agent實施動態訪問控制,杜絕“執行濫用”
智能體身份與訪問管理:將Agent視為“非人類實體(NHE)”,納入用戶身份與訪問管理平臺(IAM)的管理范疇,實現對Agent身份、權限、行為、日志的閉環管理。借助IAM,Agent不再共享員工賬號,而是擁有獨立的身份標識與對應的訪問權限。系統采用動態令牌,僅在Agent執行瞬間授予其最小權限,杜絕其越權操作。
實施動態訪問控制:利用零信任安全網關(SDP)代理Agent訪問流量。SDP基于Agent的身份、權限、行為、時間、環境等風險因素,對Agent進行持續的監控。一旦發現Agent有可疑行為,如處理報表的Agent嘗試掃描內網端口,SDP立即自適應執行訪問控制策略,實施權限收斂、人工確認、阻斷訪問等措施,杜絕Agent濫用權限,執行非法操作。
4.穩運行:部署安全沙箱與輸出校驗,封堵執行破壞
為了封堵為了封堵ASI-05 意外代碼執行帶來的直接破壞,企業需要對智能體實施物理隔離和意圖校驗:
執行環境沙箱化:將Agent調用工具的過程放置在隔離的容器(如Docker或Wasm)中。即使Agent被誘導執行“刪庫”指令,其破壞力也被限制在虛構環境內,無法觸及物理機。
動作意圖校驗:在指令下發前進行靜態規則掃描,限制單個Agent的API調用頻率,防止因邏輯死循環導致的資源耗盡。
5.保數據:部署內容感知型DLP,防范隱私泄露
對反饋層的ASI-10 流氓智能體,防護重點在于輸出端的審查:
智能泄露檢測:在Agent向外輸出信息前,由DLP引擎自動識別敏感數據并對其進行脫敏處理,杜絕Agent泄露企業敏感信息。
最少代理原則:企業應避免部署非必要的自主行為,通過減少Agent的自主權來直接縮減攻擊面,確保每一項功能都能對應到明確的業務價值。
在AI Agent重塑企業生產力的今天,安全不應成為創新的阻礙,而應成為其基石。通過將零信任融入智能體的每一處脈絡,用IAM管好身份,用SDP控好訪問,企業才能真正讓AI Agent從“不可控的黑盒”轉變為安全、合規、高效的“數字員工”。
-
AI
+關注
關注
91文章
40696瀏覽量
302328 -
智能體
+關注
關注
1文章
532瀏覽量
11639 -
芯盾時代
+關注
關注
0文章
367瀏覽量
2707
原文標題:想部署OpenClaw又擔心安全風險?AI智能體安全防護需要這么干
文章出處:【微信號:trusfort,微信公眾號:芯盾時代】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
芯盾時代助力中國電信某省分公司打造零信任業務安全解決方案



 工商網監
工商網監
評論