 占用網絡是怎么讓自動駕駛識別異形障礙物的?
占用網絡是怎么讓自動駕駛識別異形障礙物的?

[首發于智駕最前沿微信公眾號]感知系統對于自動駕駛來說,就像是眼睛和翻譯官的角色。這套系統不僅要捕捉到周圍環境的光影信號,更需要將這些支離破碎的像素點轉化為計算機能夠理解的物理實體。
在過去很長一段時間里,行業內主流的感知方案是基于目標檢測的思維方式,也就是在三維空間中尋找特定的物體,并用一個緊湊的長方體框將它們圈定出來。這種被稱為“3D目標檢測”的方法在處理常見的汽車、行人和自行車時表現得非常高效,它能告訴車輛前方有一輛多少米長、多少米寬的小轎車。
然而,現實交通環境的復雜程度遠超實驗室里預定義的標簽庫。當道路上出現一輛側翻的油罐車、一個散落的紙箱,或者是一個伸出吊臂的起重機時,傳統的畫框式算法就會顯得捉襟見肘,因為這些東西的形狀極不規則,很難用一個標準的方盒子去準確描述。
為了解決這些“不在名單上”的風險,占用網絡應運而生。它不再嘗試去辨認每個物體的具體身份,而是將整個物理世界切分成無數個微小的、邊長通常只有十幾厘米的立方體,這些小方塊被稱為“體素”。
占用網絡只需要判斷每一個體素是否被物理實體所占據。這種從“物體檢測”到“空間占據預測”的邏輯轉變,讓自動駕駛系統具備了識別任何形狀障礙物的能力。
傳統視覺感知有何痛點?
在深入探討占用網絡之前,有必要先厘清下傳統感知方案在面對異形物體時的痛點。早期的自動駕駛算法高度依賴“分類”邏輯,也就是系統必須先知道一個東西是什么,才能確定它在哪。這種邏輯在處理“本體裂紋”或“語義裂縫”時非常脆弱。
舉個例子,如果一個算法的訓練集里全都是標準的貨車,當它在路上遇到一輛拉著長木材、木材向后延伸出車廂數米的拖掛車時,系統可能只會把車頭和車廂識別為一個長方體,而忽略掉那些向外延伸的木材。
對于自動駕駛汽車來說,這種對空間理解的缺失是非常致命的,因為這意味著規劃器可能會認為車后方的空間是空的,從而在變道時發生碰撞。
此外,傳統3D目標檢測還存在著形狀剛性的挑戰。它嘗試用一個長、寬、高固定的立方體去套住所有物體,但在現實中,很多障礙物是可變形的或者是中空的。
像是一輛正在施工的灑水車,它噴出的水霧在視覺上可能很模糊,或者一輛造型奇特的工程車,其吊臂懸浮在半空中。傳統的方盒子無法描述這種“懸空”或“非連續”的物理占據,就會將吊臂下方的空地也標記為不可通行,或者干脆完全漏掉懸空的吊臂。
這種對空間細節的粗糙處理,使得車輛在復雜的城市窄路或施工區域行駛時,表現得畏首畏尾或者極度危險。
視覺感知還有一個固有缺陷是深度信息的缺失。雖然我們可以通過算法將二維圖像轉化為三維坐標,但在遠距離場景下,這種轉化的誤差會呈指數級增長。僅靠幾個像素點的變化來推斷地平線上一個物體的距離是非常不可靠的。激光雷達雖然能通過物理反射解決距離問題,但其成本限制了自動駕駛的大規模普及。
在這種背景下,如何用廉價的攝像頭實現媲美激光雷達的空間建模能力,成為了感知技術演進的核心驅動力。占用網絡正是在這種需求下,通過將感知空間從二維平面提升到三維體素,為純視覺方案補齊了最后一塊短板。
占用網絡的是如何實現場景理解的?
占用網絡的核心理念是將車輛周圍的物理空間徹底“數字化”。它不再嘗試去理解具體的物體語義,而是將感知的焦點回歸到最原始的問題,這個點上到底有沒有東西。
為了實現這一點,系統會通過環視攝像頭捕獲360度的圖像數據,然后利用特征提升,將這些二維的像素特征映射到一個三維的向量空間中。
在這個過程中,Transformer架構起到了至關重要的作用。它像是一組敏銳的探測波,在三維空間中進行“位置查詢”,通過注意力機制去尋找不同視角的圖像中哪些像素點指向了同一個物理空間點,從而在系統內部構建起一個密集的、充滿了特征信息的立體網格。
這種體素化的表示方法與傳統的點云數據有著異曲同工之妙,但它比點云更進一步。點云僅僅是物體的表面反射點,而占用網絡生成的體素網格是連續的、稠密的。它不僅記錄了物體的表面,還隱含了空間的占據狀態。

特斯拉的占用網絡可以在大約10毫秒內完成一次全局的空間預測,這個速度遠超人類的反應極限。它會將世界劃分為一個個極小的立方體,并為每個立方體賦予一個“占據概率”。如果某個位置的占據概率超過了設定的閾值,規劃器就會將其視為障礙物,從而在路徑搜索中自動繞開該區域。
值得一提的是,占用網絡在提升空間分辨率方面也有一套精妙的算法。由于車載芯片的內存和算力是有限的,系統不可能對所有的空間都進行同樣精細的劃分。
因此,先進的算法會采用“按需分配”的策略,在靠近車輛行駛路徑的區域,體素劃分得非常細致,足以看清路面上一個小小的路障;而在遠離車輛或者天空中不影響行駛的區域,則使用較粗的網格以節省計算資源。
這種“分辨率在關鍵處發力”的設計,使得占用網絡能夠在實時性與準確性之間找到完美的平衡點。
為了確保預測的準確性,現代占用網絡還會引入時序融合機制。它不只是根據當前的一幀畫面做判斷,還會參考過去幾十毫秒甚至幾百毫秒的特征流。這種跨時間的特征比對,不僅能過濾掉單幀圖像中可能出現的噪點,還能讓系統感知到物體是如何在三維空間中移動的。
這種時空的交織,讓車輛不僅擁有“立體感”,還擁有了某種程度上的“物理常識”。如當系統看到一組體素正在向前快速移動時,它能通過歷史數據的一致性判斷出這大概率是一個動態的交通參與者,而不是路邊靜止的建筑殘骸。
占用網絡如何解決“看不見的風險”?
占用網絡最引以為傲的能力,就是它對“長尾障礙物”或異形物體有極高魯棒性。在傳統的自動駕駛邏輯中,異形物體幾乎就是“無法識別”的。但是因為占用網絡本質上是在做三維空間的幾何重構,它對物體的外觀、顏色或者類別完全不敏感。它只關心一點,如果在一個特定的空間坐標上,攝像頭觀察到了持續的視覺遮擋和特征反饋,那么這個空間就是“被占據”的。
這就好比在黑夜中用手摸索前方的障礙。傳統算法像是必須通過手感猜出摸到的是椅子還是桌子才能避開,而占用網絡則只要發現手伸不過去,就立刻認定那里有東西。
這種“幾何優先”的思維方式徹底解決了語義裂縫問題。無論障礙物是一輛翻倒的灑水車、一堆凌亂的建筑材料,還是一棵橫在路中央的斷樹,占用網絡都能精準地描繪出它們在三維空間中的實際輪廓,而不會像傳統算法那樣,試圖用長方體去強行套住這些形狀奇詭的東西。
此外,占用網絡對于處理“懸空障礙物”具有天然的優勢。這是BEV(鳥瞰圖)技術在升維過程中最容易遺失的信息。在傳統的BEV架構下,所有東西都被壓扁到了一個二維的地平面上,系統很難區分一個物體到底是長在地上,還是懸在空中。
而占用網絡通過在Z軸(高度軸)上的多層體素劃分,可以清晰地識別出路面上的隔離帶和橫跨路面的限高桿之間的空間差異。它能告訴車輛,底盤可以安全通過某些低矮的坑洼,但車頂可能會撞上前方低垂的樹枝。這種全方位的幾何理解,讓自動駕駛汽車在應對復雜的施工現場或不規則的立交橋下空間時,具備類似人類駕駛員的直覺。
此外,占用網絡還具備卓越的“腦補”能力,這在處理遮擋問題時尤為關鍵。當一輛大貨車遮擋住了后方的部分視野時,傳統的點云方案只能看到貨車的側面,而無法知道貨車后面是否還藏著其他東西。
占用網絡通過深度學習積累的幾何先驗,可以在一定程度上預測被遮擋區域的占據狀態,并將這些預測信息提供給下游的避障算法。這種對未知空間的防御性建模,極大地提升了車輛在十字路口或視線受阻區域行駛時的安全性。
占用流如何實現預測能力?
如果說三維體素解決了空間識別的問題,那么“占用流”(Occupancy Flow)則賦予了系統對動態世界的預測能力。
占用流不僅能告訴我們哪些空間被占用了,還能給出每一個被占用體素的運動矢量。通過分析這些矢量的顏色和方向,規劃算法可以清晰地預判周圍物體的運動軌跡。
占用流的引入,本質上是引入了物理世界的守恒定律。它意識到,一個體素如果現在被占據了,它下一刻要么留在原地,要么會移動到相鄰的體素位置。這種局部的連貫性約束,使得系統在處理行人鬼探頭、車輛緊急加塞等高風險場景時,能夠比傳統基于目標追蹤的方法更快地做出反應。
系統不再需要經歷“識別物體-關聯歷史幀-計算速度-生成預測軌跡”的長鏈條,而是直接觀察體素占據狀態的流轉趨勢。這種毫秒級的響應速度提升,往往就是避免一場碰撞的關鍵。
在模型訓練中,占用網絡也利用了許多前沿的技術手段來提升自身的進化速度。由于人工標注三維體素是一項幾乎不可能完成的任務,行業內普遍采用“NeRF(神經輻射場)”等離線重建技術進行自動標注。
車輛在行駛過程中會通過眾包的形式收集海量的視覺數據,在云端通過NeRF技術還原出極其真實的3D場景,并以此作為真值來訓練車端的小模型。這種“云端重構、車端預測”的閉環,讓占用網絡能夠從全球數百萬輛車的日常行駛中不斷學習,從而持續增強其泛化能力。
最后的話
占用網絡不僅是感知的終點,更是實現“端到端”自動駕駛的重要基石。當感知系統輸出的是一幅連續的、帶有物理屬性的四維占用圖時,下游的規劃和控制模塊就可以尋找那些概率最低的空隙進行穿梭。
這種深度的集成,消除了模塊間由于信息壓縮導致的誤差,讓自動駕駛汽車的行為變得更加擬人、更加流暢。雖然目前占用網絡還面臨著遠距離精度不足、計算功耗高等挑戰,但隨著車載算力的爆發和算法的迭代,這種讓萬物皆可被感知的技術方法,必將徹底重塑人類出行的安全標準。
-
計算機
+關注
關注
19文章
7812瀏覽量
93252 -
網絡
+關注
關注
14文章
8285瀏覽量
95015 -
自動駕駛
+關注
關注
794文章
14897瀏覽量
180163
發布評論請先 登錄
自動駕駛占用網絡是依靠哪個傳感器實現的?

自動駕駛中常提的占用網絡檢測存在哪些問題?
自動駕駛端到端為什么會出現黑盒現象?

SLAM如何為自動駕駛提供空間感知能力?
Transformer如何讓自動駕駛大模型獲得思考能力?
占用網絡為什么讓自動駕駛感知更精準?
自動駕駛汽車如何檢測石頭這樣的小障礙物?
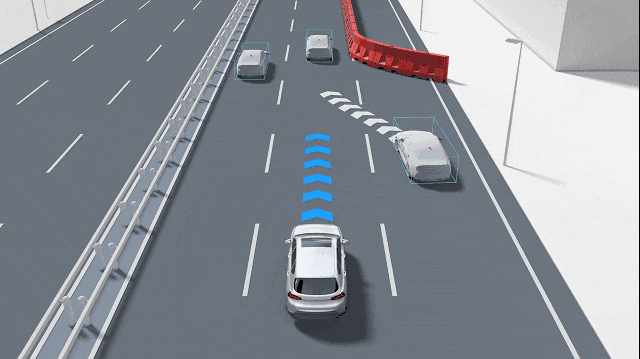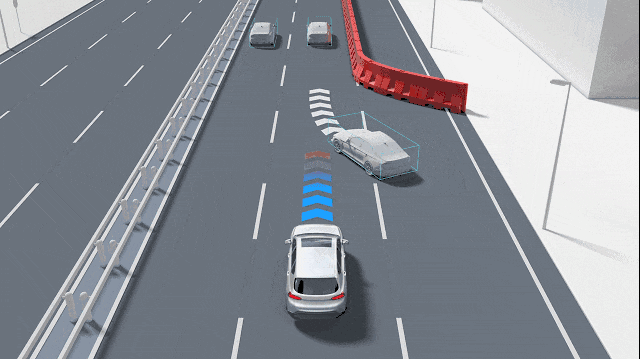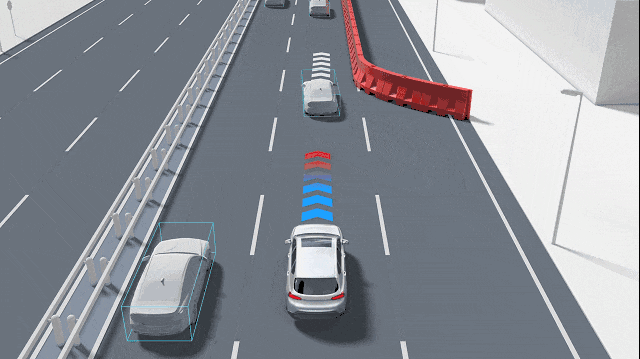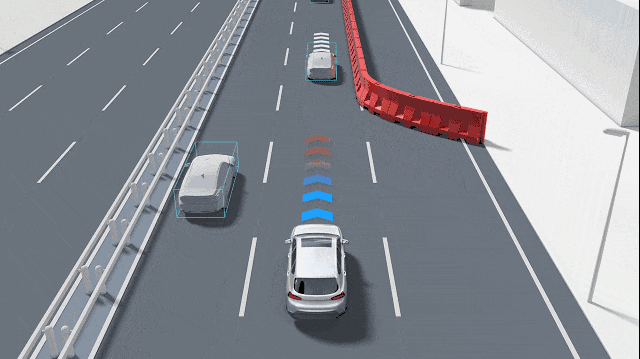
自動駕駛中常提的GOD有什么作用?

自動駕駛汽車如何處理“鬼探頭”式的邊緣場景?
自動駕駛汽車如何準確識別小物體?
Momenta飛輪大模型賦能輔助駕駛巧避障礙物
自動駕駛汽車如何正確進行道路識別?

卡車、礦車的自動駕駛和乘用車的自動駕駛在技術要求上有何不同?



 工商網監
工商網監
評論