") R480-X8面向下一代AI集群的高密度算力模塊:技術架構與應用分析
R480-X8面向下一代AI集群的高密度算力模塊:技術架構與應用分析


在當前AI算力需求高速增長且日趨多樣化的背景下,集中式、高密度的加速器解決方案成為提升數(shù)據(jù)中心計算效率的關鍵路徑之一。遵循OCP OAI開放標準的模塊化設計,正逐步成為行業(yè)構建大規(guī)模訓練與推理集群的重要技術選型。本文將以此類高密度加速器組的典型技術規(guī)格為切入點,分析其架構特點與潛在應用場景。
一、核心架構:開放標準下的高密度集成
此類加速器組通常基于UBB(Universal Baseboard)服務器基板設計,其核心特點在于對開放計算標準的采納。通過集成多個遵循OCP OAI(Open Accelerator Infrastructure)標準的計算模組,實現(xiàn)在單一節(jié)點內(nèi)匯聚大規(guī)模算力。
模塊化設計:支持搭載多個獨立的OAM(OCP Accelerator Module)模組。這種設計不僅提升了計算密度,也為后期維護、按需擴展與異構計算集成提供了靈活性。
標準化互聯(lián):采用業(yè)界開放的OAI標準,有助于降低硬件集成門檻,提高與不同服務器平臺的兼容性。
二、性能規(guī)格:為大規(guī)模負載設計的算力集群
從公開指標看,此類系統(tǒng)的設計目標明確指向云數(shù)據(jù)中心的大規(guī)模AI工作負載。
聚合算力分析
FP16精度:1 PetaFLOPS:該級別的浮點算力使其能夠高效處理大規(guī)模深度學習模型的訓練任務,尤其適用于大語言模型(LLM)、多模態(tài)模型的分布式訓練。
INT8精度:2 PetaOPS:極高的整數(shù)算力為超大規(guī)模模型的量化推理、推薦系統(tǒng)等高吞吐量場景提供了基礎。
算力跨度:從INT8到FP32的完整精度支持,顯示出其在從低精度推理到高精度訓練的全棧AI工作負載中具備的應用潛力。
內(nèi)存與互聯(lián)子系統(tǒng)
內(nèi)存配置:每個計算模組配置大容量GDDR6顯存,八模組聚合可提供總量可觀的高帶寬內(nèi)存池,能夠支持參數(shù)規(guī)模極大的模型或同時處理多個任務。
片間互聯(lián)帶寬:高達200GB/s的互聯(lián)帶寬是發(fā)揮多芯片協(xié)同計算效率的關鍵。高帶寬互聯(lián)能顯著減少模組間數(shù)據(jù)交換的延遲,對于模型并行等分布式計算策略至關重要。
三、關鍵技術考量與應用場景
對于技術決策者而言,評估此類高密度解決方案需關注以下幾個維度:
適用場景分析
大規(guī)模分布式訓練:是千億乃至萬億參數(shù)模型訓練集群的核心計算節(jié)點選擇。
高吞吐量推理服務:可部署于需要處理海量并發(fā)請求的在線推理平臺,如圖像識別、語音處理、內(nèi)容推薦等。
混合負載整合:在同一硬件平臺上整合訓練與推理任務,優(yōu)化數(shù)據(jù)中心整體資源利用率。
部署與運維考量
散熱與功耗:高密度集成對數(shù)據(jù)中心的散熱設計和供電系統(tǒng)提出了更高要求,需評估基礎設施的支撐能力。
軟件棧成熟度:硬件性能的充分發(fā)揮依賴于與之匹配的編譯器、運行時庫、集群調(diào)度軟件及主流深度學習框架的優(yōu)化支持。
總擁有成本(TCO):需綜合計算硬件采購、能源消耗、機房改造及軟件適配等方面的整體成本。
四、行業(yè)趨勢與選型建議
采用開放標準的高密度AI算力模塊,代表了數(shù)據(jù)中心算力基礎設施向模塊化、標準化和規(guī)模化發(fā)展的趨勢。它為企業(yè)和研究機構構建高效AI計算平臺提供了新的選項。
在技術選型過程中,建議決策者:
明確工作負載特征:首先精準分析自身業(yè)務負載的主要計算精度、通信模式和規(guī)模需求。
進行概念驗證(PoC):在實際的業(yè)務流水線中測試關鍵模型的性能與擴展性。
評估生態(tài)兼容性:確保其軟件生態(tài)能與現(xiàn)有的開發(fā)工具鏈和運維體系順暢集成。
規(guī)劃演進路徑:考慮未來1-3年內(nèi)模型規(guī)模與算力需求的增長,確保方案具備可擴展性。
總結(jié)
總體而言,基于開放標準的高密度AI加速器組,通過聚合大規(guī)模算力與高速互聯(lián),為應對下一代AI計算的挑戰(zhàn)提供了重要的硬件架構思路。它的出現(xiàn),豐富了市場在構建大規(guī)模AI算力基礎設施時的技術選項。最終,能否在具體業(yè)務中取得成功,取決于硬件性能、軟件生態(tài)、基礎設施與業(yè)務需求的深度匹配與持續(xù)優(yōu)化。
審核編輯 黃宇
-
服務器
+關注
關注
13文章
10117瀏覽量
91038 -
AI
+關注
關注
90文章
38414瀏覽量
297711 -
算力
+關注
關注
2文章
1409瀏覽量
16605
發(fā)布評論請先 登錄
茂睿芯推出新一代智能功率級產(chǎn)品MK684X系列

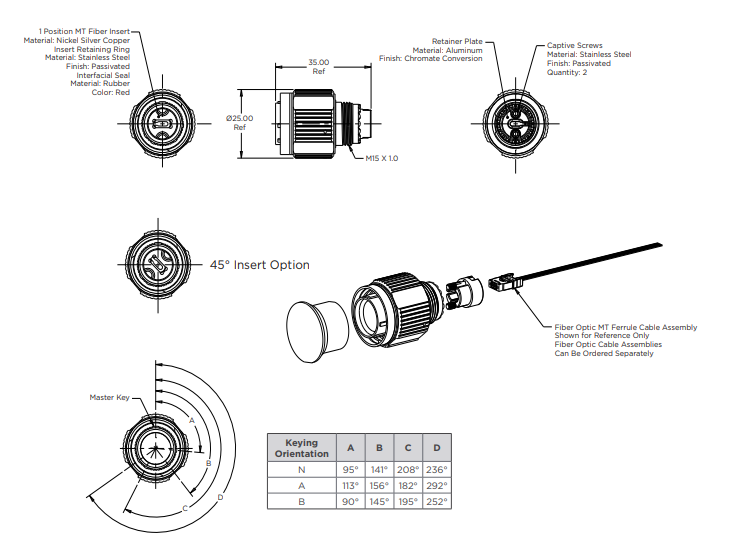
基于TE Connectivity VITA 87高密度圓形MT連接器的技術解析與應用指南
國產(chǎn)AI芯片真能扛住“算力內(nèi)卷”?海思昇騰的這波操作藏了多少細節(jié)?
睿海光電領航AI光模塊:超快交付與全場景兼容賦能智算時代——以創(chuàng)新實力助力全球客戶構建高效算力底座
液冷算力新標桿!科華數(shù)據(jù)聯(lián)合沐曦股份在世界人工智能大會首發(fā)高密度液冷算力POD


高密度配線架和中密度的區(qū)別
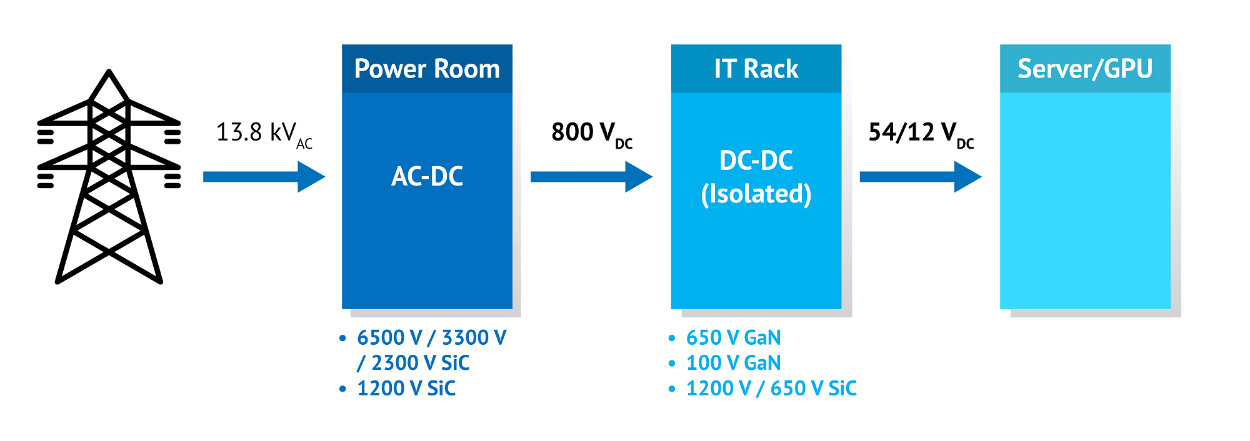
NVIDIA 采用納微半導體開發(fā)新一代數(shù)據(jù)中心電源架構 800V HVDC 方案,賦能下一代AI兆瓦級算力需求

施耐德電氣發(fā)布數(shù)據(jù)中心高密度AI集群部署解決方案
光纖高密度odf是怎么樣的
高密度、低功耗,關聯(lián)AI與云計算

DeepSeek推動AI算力需求:800G光模塊的關鍵作用
高密度封裝失效分析關鍵技術和方法







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論