 處理器架構的性能特點及如何正確的選擇編譯器與仿真工具
處理器架構的性能特點及如何正確的選擇編譯器與仿真工具

處理器架構的一個主要性能特點是單位時間內能執行多少專用工作。EEMBC (嵌入式微處理器基準協會)基準與Dhrystone MIPS (每秒百萬次指令) 評分不同,它描述了在嵌入式系統應用中執行任務的處理器性能。EEMBC 基準的1.0版本并未涉及對處理器性能系統級的影響,如內存子系統,因為該基準經常在處理器的第一緩存內起作用。但EEMBC的第二代針對網絡與數字娛樂的系統級基準,更實際地強調具有較大緩存內存的處理器。
處理器內存子系統的系統級影響越來越重要,因為內存類型和大小及系統中的存取方式規定了處理器內核性能的上限。據 ARM處理器部門的Gerard Williams III認為,理 想內存系統的處理器必然要采用緩存,并有理想的存取總線的方式。芯片設計師必須首先了解處理器的IPC (每周期指令)能力,然后嘗試實現能將性能損失降到最低的內存架構。這種性能損失可能來自緩存或內存存取影響,如由于容量損失、緩存大小或沖突失效形成的丟失率。
匹配良好的內存子系統可以保持處理器的最大IPC 率,而匹配不好的內存子系統會空置內核的執行單元,而大大地降低處理器的性能。雖然構建與實現內存子系統不會影響處理器內核的性能,但還是具有很大的挑戰性,因為在處理器邏輯與內存間存在的性能差異正隨著每次工藝技術的變化而逐步增大。實際上,內存存取延遲的改進及每個工藝技術步驟接收內存請求的時間都比處理器內核邏輯的同量時鐘速率提高要少。
同樣,軟件開發人員通過有預見性地在內存子系統中安置編程指令與數據,可實現的最佳性能影響,就是保持處理器的最大IPC率。然而,在設備使用情況下,內存子系統中匹配不當的程序指令和數據,會極大地降低處理器的性能。Freescale關于防止M1存儲沖突的應用注釋提供了一個范例,說明了由于存儲沖突會造成54% 處理器性能下降,開發人員可通過更好地安置數據緩沖器來避免發生這種情況(參考文獻1)。
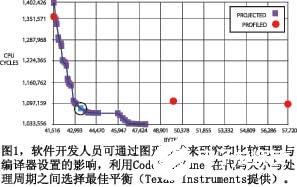
一般而言,編譯器與仿真工具以全局的優化對在內存中放置指令和數據可提供有限的幫助。Green Hills的優化編譯器支持內存中的功能重新安排,以優化緩存命中率。Texas Instruments的CodeSizeTune 基于仿真的編譯工具可幫助開發人員探索配置,采用影響代碼大小和執行速度的不同的編譯器設置自動構建和仿真不同版本軟件(圖1)。一般來說,對許多高效和實時約束系統來說,軟件開發人員的困難就是要了解內存子系統以避免由于系統不能有效地使用處理與內存資源,而承擔不必要的BOM (物料清單)成本。
延遲容差
在實現內存架構時最主要的擔心就是使處理器能夠對系統使用的內存的存取延遲實現容差。設計合理的內存子系統可以掩藏系統多數的內存存取延遲,并能提供足夠的讀/寫吞吐速率,即相同數據模塊中隨后發生的數據內存存取時間,以支持連續存取。這種情況避免了空置處理器的執行單位的指令和數據。內存設計人員必須根據內存的芯片面積、內存消耗的總功率、軟件開發人員對內存使用的方便性及工具等因素對內存存取延遲進行權衡(參見附文1“方便使用”)。
內存存取延遲的直接誘因為用來執行地址解碼、激活適當字線、檢測位線及驅動檢測放大器輸出的時間。地址解碼延遲為鎖定地址,確定哪個字線需要激活的時間,此過程將O(n log n) 時間作為內存行與列尋址大小的函數。因此,隨著內存結構的擴大,解碼與尋址所需的時間也相應增加。字線激活延遲是字線上升所需的時間,主要是與線長相關的RC 延遲,線長越長則延遲越長。位線檢測延遲是檢測放大器檢測單元內容所需的時間。位線架構、檢測驅動線的RC、單元與位的容量比、及檢測放大器拓撲等都會影響位線檢測延遲。輸出驅動延遲是一種RC 延遲,驅動從檢測放大器到輸出端傳送數據的時間。
內存與管理內存的邏輯占用了許多基于處理器設備的芯片面積。結果,內存可以是設備的芯片成本最大的部件,也是系統中消耗動態和靜態功率最大的部件。許多類型的易失與非易失內存各有好壞,系統設計人員必須要兼顧并管理重要的參數,以較低的成本和功耗來實現足夠好的內存性能。
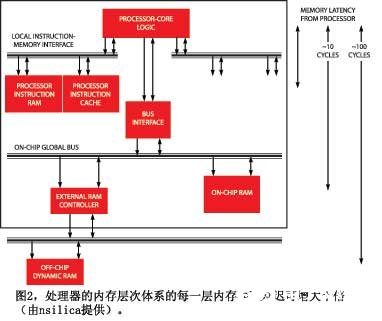
為了兼顧掩藏內存存取延遲、芯片成本及功耗,基于處理器的設備通常都依賴一個多層內存結構,將少量快速而昂貴的內存靠近處理器內核,而將大量慢速內存遠離處理器內核(圖2)。處理器寄存器是系統中最快且最難得的內存資源,內存體系還可以使用局部內存或TCM(緊密耦合的內存)、多階緩存、及易失性與非易失性片上內存與片外內存。
現代的優化編譯器在管理使用處理器寄存器方面很合適,但在管理與優化其它內存上則較差。這種情況部分是由于利用本地查看程序代碼,優化使用寄存器與戰術實施配合良好。為了在基于處理器的系統中優化使用其它內存結構,如TCM,需要更具全局性地查看系統,此功能正出現在多數的編譯器中。
局部內存或連接到處理器核的TCM通過局部或專門的內存總線來存取類似于緩存的性能。內存存取確定機制為TCM與緩存間的主要區別。人工暫時鎖定緩存線可在線級使能緩存,使其作為一個TCM。程序指令與通過TCM實施代碼存取具有確定的能力,但對于緩存,設計人員必須考慮緩存丟失的最壞情況。“對于緩存丟失處理的典型經驗法則是,存取延遲比前一級別增長一個數量級”Innovative Silicon的架構總監David Fisch 說。“L2 內存存取延遲是L1 緩存存取延遲的10 倍,而L3緩存存取延遲又是L2 內存存取延遲的10倍。”使用TCM將任務加給軟件開發人員手動的管理內存空間,通常是使用DMA 控制器,以便在處理器 需要時,使必要的代碼和數據在TCM 中。
緩存由速度稍慢的內存構成來掩藏大量速度較慢內存的延遲。較慢的內存密度更大,所以也更便宜。緩存依賴暫存的空間局部區域來掩藏較慢內存的存取延遲。“暫存局部性” 描述了這種區域特點:如果處理器請求一些數據,那么,處理器很快又需要相同的數據。通過在存儲中保留數據復本,緩存可以避免數據進入較慢的內存中。“空間局部性” 描述了區域的另一種特性:即處理器請求在某個內存位置的代碼,而下一處理器請求為下一內存位置或與其相近位置的代碼。利用在初始取數同時預取靠近當前請求數據的一定量的數據,緩存在其存儲中就可以有下幾個數據位置,而不會從較慢內存中發生另一取數的延遲。
較大緩存通常意味著犧牲更多芯片面積而實現較少的緩存丟失。提高表示特定的內存可存在于緩存中的位置數的緩存相關性,幾乎總能減少緩存丟失。緩存線長度可根據應用的特性作正向或反向變化。Tensilica首席架構師Bill Huffman告訴我們:“配置緩存是一項迭代任務,它高度依賴可在處理器中執行的應用集。”
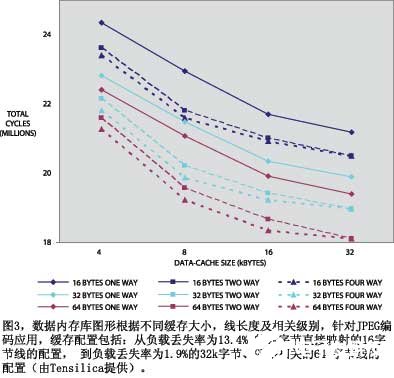
平衡各種緩存參數是一個復雜的過程,涉及到在芯片面積與丟失率間的取舍(圖3)。圖中列出了JPEG編碼應用的緩存配置范圍:從負載丟失率為13.4% 的4k字節直接映射的16 字節線的配置,到負載丟失率為1.9%的32k字節、四路相關的64 字節線的配置(參考文獻2)。盡管緩存越大越好,但對32k字節緩存有優勢收益遞減的趨勢。提高緩存線大小所具有的性能優勢比緩存大小增加一倍所提高的性能更多,緩存線越長,芯片成本越小。盡管大緩存相關性越高越好,但在此例中,從兩路到四路相關性能產生的優勢很少。簡而言之,對于配置緩存并沒有明確的經驗法則。
決策驅動器
處理器內核架構為內存架構選項中設計人員的第一選擇。原因是設計人員構建內核時假定了內存組件與內核如何接口并對其如何補充。Von Neumann 和Harvard 架構為兩種常見的處理器架構,分別模仿并實施不同的方法來查看和存取內存。基于von Neumann 架構模型的處理器將系統內存建模成保存程序指令和數據的單一存儲結構,并有單一總線接口服務所有程序和數據存取。基于Harvard 架構的處理器對系統內存建模,程序指令和數據作為物理和邏輯分離存儲結構,以不同的總線接口,一個用于指令,另一個用于數據。Harvard 架構支持同時存取程序指令與數據,而von Neumann 架構則不會。
為了選擇一個優化的內存設計 ,設計人員還必須了解應用的特點和要求。對內存設計的考慮有: 應用的數據如何進出系統,處理器能否直接加載數據或外部代理,DMA控制器能否將數據載入處理器的局部RAM中?同時也必須對輸出提出類似的問題:處理器會不會直接驅動輸出端口?或由外部代理,如DMA 控制器來驅動,能否將數據從處理器的局部RAM 傳輸到I/O 接口中?其它問題包括:什么是應用的啟動過程?系統能否有效地利用特殊內存接口?片上內存資源能否容納所有的代碼與應用數據,還是僅能容納性能敏感的代碼與數據?
應用啟動要求從何處存儲初始化代碼,以及系統通過什么接口進行存取。片上OTP(一次性可編程)ROM很小且具有較高的芯片密度,所以對于儲存啟動代碼非常有用。它支持快速啟動,因為在啟動后到開始執行不需要等待時間。初始化代碼可能在閃存中的某個位置駐存并執行,也可以存在于芯片外內存中,也可映射到片上指令RAM中,這可造成系統啟動時間較長。如果應用代碼和數據能駐存于片上內存中,就沒有必要支持片外內存接口。如果性能敏感的程序代碼可載入局部內存中,設計人員就不需要實施緩存了。
設計人員可根據已知應用的約束條件調整處理器,這些處理器僅包括應用所需的隨機和非易失性內存量。TCM的大小和參數、緩存或特殊內存都是針對應用而設計的。針對較寬應用的處理器通常實施一個普通的內存架構,這些架構包括應用的最大資源要求,以提供較少資源的各種設備來滿足較低的成本要求。對于采用類似處理器核架構的系統,內存子系統成為更高級的驅動器,以提供系統可交付的處理性能、功耗及價格(參見附文2“多種選擇”)。
內存控制器對所服務的內存模塊的實現進行抽象處理,使其成為對處理器系統的數據管道。它們包含讀取內存模塊所必須的邏輯,根據所服務內存的類型,還包括寫入、刷新、測試與校正錯誤內存等。對于片上內存,內存控制器能夠顯示公司的專有發明,它的處理器設備不同于競爭者的類似設備。結果,多數的處理器廠商不愿過于詳細地討論其內存控制器。他們指出了一種用于內存控制器的技術,包括使用寬數據總線,多路復用或交錯式存取內存庫、緩沖、流水線、交易記錄以及專門和不確定的存取模式等。
除了實現的內存的特性外,影響內存控制器設計和效率的系統級因素還包括物理尋址如何映射到內部演示內存系統上,尋址模式的類 型(如突發、隨機與并行存取模式)、混合讀寫、未使用的內存如何進入低功耗模式。其主要的使用模型通常確定了內存控制器的架構,以使圖形或多媒體控制器可優化進行序列存取,而嵌入式通訊系統的內存控制器可在較大的內存范圍內優化隨機存取。對于有系統級可靠性要求的嵌入式內存,針對額外的復雜性,內存控制器可提供ECC(錯誤糾正代碼)保護。
內存控制器的流量模式在單核處理器系統與多核處理系統之間有很大區別。單核系統的內存處理器可使用一個數據流,但在多核心系統中的共享內存,內存控制器需要有處理多個數據流及隨機流量的能力。對于多核設計,內存架構必須支持快速及有效的信息傳遞,以及處理器間的數據共享。盡管不同的方法可實現這些目標,但沒有單一配置對所有類型的通信都有效。快速的點對點通道及隊列,對交換短小且重要的信息非常重要,然而共享內存對于共享較大的數據結構更為有益。當使用共享內存時,用戶需要對同步和內存管理的編程支持。
隨著越來越多的嵌入式系統組合到多內核作為設計的一部分,特別的異構內核,開發工具的發展會更好地協助開發人員從空間和時間上安置代碼和數據,來實現更好的延遲容差,并使復雜性越來越高的設計發揮出最佳性能。開發工具必須可協助開發人員更好地了解系統的全局行為。并將該行為與系統中可用的內存子系統進行匹配。否則,內存和芯片設計人員必須繼續將更復雜的控制算法組合到內存控制器中,以明確地補償軟件設計人員和開發工具對內存系統的行為缺少可視性的缺點。
附文1:方便使用
編程的簡易性對軟件開發人員來說是一種十分重要的特性。可隱藏內存體系的平坦的地址空間,便于開發人員進行編程。Microchip Technology數字信號控制器部門的技術人員Brian Boles 說,“一般來講,將應用針對通用的內存架構而設計編譯器比較容易些。”要讓編譯器最佳地將代碼和數據分配到專用的內存結構,而對應用代碼的全局的動態特性沒有可視性是比較困難的。
對于操作系統的復雜應用,如Linux,內存架構需要支持虛擬尋址。然而,使用大型操作系統滿足上市時間表壓力的開發人員來說,可能會失去對如何分隔軟件利用片上資源來節能和節省成本的深入考慮。沖突的某些問題是權衡與確定有多少片上內存需要操作系統通過片上內存運行,以及這種方法留給應用的內存數量。“到目前為止,通用操作系統沒有什么虛假的連接規定完整的物理到內存系統的映射,促進基礎內存系統最佳使用。”Intel嵌入式與通訊集團營銷經理Phil Ames說。“然而,在嵌入式設計中采用手動調整軟件,使內存系統得到最佳使用是十分普遍的。”
管理各種不同類別的內存需要專門的軟件。例如,小容量NAND閃存(528 字節/每頁)與大容量 NAND 閃存(2112 字節/每頁)通常需要不同的閃存管理軟件。一個解決這種情況的方法是將軟件設計成模塊化嵌入層中,以使軟件開發人員在必須修改時,盡量減少重寫量。Toshiba內存產品集團的技術人員Doug Wong說:“NAND 閃存為最早的商品化內存,將重要的智能特性加入內存設備中,以使其更易使用。”Toshiba的LBA-NAND 與兼容eMMC的嵌入式NAND 中都含有可執行NAND管理功能的內置控制器,如模塊管理、損耗均衡、及邏輯到物理模塊的轉換及自動錯誤校正等。這種方法明顯地降低了系統架構師或軟件工程師在對FFS(閃存文件系統)或FTL(閃存轉換層)管理NAND閃存設備的負擔。
附文2:多種選擇
以下的范例使用基于ARM7的NXP LPC2129 處理器內核,說明了某些處理器核架構對內存架構可能的第一決策影響(圖A)。ARM7 為三級流水線von Neumann架構機器,有一個端口通過AHB(高級高性能總線)橋連接到ARM 高性能總線。該橋是提供在處理器與外設頻率間同步的必要途徑。以容納處理器接口,或作為與多個主控設備總線的接口。盡管該橋非常必要,但當處理器通過AHB存取任何數據時,應用一個雙時鐘延遲處理,如果地址超出序列,則應用一個額外的性能處理。
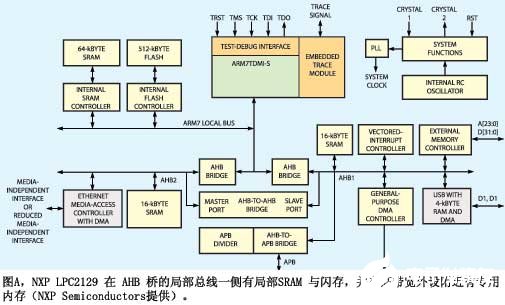
一個放置程序和數據內存的明顯位置是在AHB 一側的總線上,以便處理器可存取內存,且外設可直接存取內存數據。但是,AHB 橋還是應用了兩周期的延遲處理。為了優化 處理性能,設計人員將程序內存放置在AHB橋的處理器的局部總線一側。盡管這種結構提高了處理性能,但其它總線主控設備不能直接存取此內存,迫使設計人員將更多的內存放置在DMA 主控設備的AHB 一側。這種方法增加了舊工藝的成本,但在深亞微米工藝中,性能增加比成本增長更重要。
閃存比6T(6個三極管)SRAM 單元速度慢,但由于閃存具有非易失性、固態可靠性、較低的功耗及設計靈活性,所以在嵌入系統中使用閃存非常重要。在單一內存類型內的許多子體系結構允許你調整架構以滿足應用的需求。這些需求包括存取速度、編程速度、讀電壓功耗水平及成本等。其它對閃存的重要考慮有,使用年限及支持的擦除次數。
嵌入式閃存的隨機存取速度約為50 ns、商業閃存約85 ns,在針對速度超過100 MHz的處理器時就會出現問題。然而,因為存取嵌入式閃存并不受針腳限制,嵌入式閃存子系統可使用帶有某些接口邏輯的較寬的位寬來提高性能。在此例中,128 位的寬度允許系統同時存取四個處理器數據字,該數據字為線性碼提供了80 MHz 的有效存取頻率。將以可緩沖邏輯四字的存取與讀取結合,在以閃存執行時,可允許分支預測實現可接受的性能。這種方法實現了更為節省成本和功耗的SRAM 或閃存作為本地內存以隨機存取數據,多數為程序代碼的線性存取,而不僅是SRAM 實現。
有多種選擇可以實現總線架構來支持高帶寬外設。一種是使用多層總線,它是一種矩陣,允許多個主控設備以不同方式存取內存資源。另一種方法是設計一個AHB至AHB 橋,這樣就有兩個或更多的獨立總線。由于局部內存SRAM 并不支持DMA,不論選擇哪種方法,任何高帶寬外設(如以太網或USB)都應有專門的內存資源可直接存取內存。所存儲的數據包和幀的數量、數據速率及處理器速度決定著專用內存的大小。
責任編輯:gt
-
處理器
+關注
關注
68文章
20255瀏覽量
252325 -
仿真
+關注
關注
54文章
4483瀏覽量
138279 -
編譯器
+關注
關注
1文章
1672瀏覽量
51618
發布評論請先 登錄
SIMD計算機的優化編譯器設計
PortlandGroup推出PGI CUDA編譯器
全靠自家的編譯器 AMD的Ryzen處理器仍敵不過Intel處理器
最新版高性能計算編譯器PGI2012上市和體驗報告
MPLAB? XC8 C編譯器的架構特性

如何在Keil MDK中使用GCC編譯器工具鏈
你用的ARM處理器該選擇哪個編譯器?

編譯器的優化選項
TVM編譯器的整體架構和基本方法



 工商網監
工商網監
評論