 瑞芯微RKNPU開發全指南:從環境搭建到性能優化,一文搞定邊緣AI部署
瑞芯微RKNPU開發全指南:從環境搭建到性能優化,一文搞定邊緣AI部署

在邊緣AI領域,瑞芯微(Rockchip)的RKNPU憑借高性能、低功耗的特性,成為很多嵌入式開發者的首選。無論是RK3588的3核NPU(算力達6TOPS),還是RV1106的輕量化NPU,都需要通過RKNN SDK實現模型部署。今天這篇文章,我們就從SDK核心組件、開發全流程、進階優化到避坑指南,手把手教你搞定RKNPU開發!
一、先搞懂:RKNN SDK核心組件
RKNN SDK不是單一工具,而是一套“PC端工具鏈+板端運行時”的完整生態。先理清這3個核心組件的分工,后續開發才不會亂:
1.核心組件交互圖
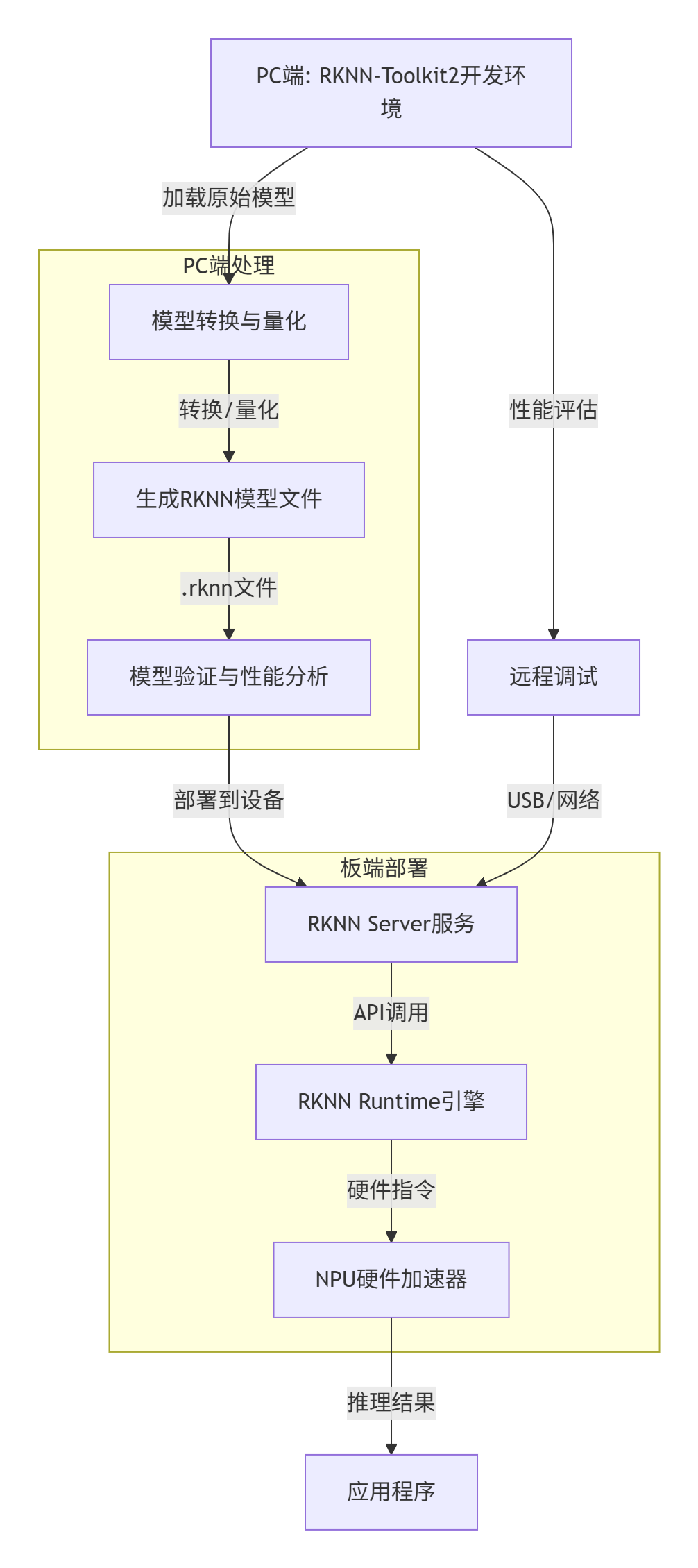
2.組件詳解
?RKNN-Toolkit2(PC端)
開發者的“模型加工廠”,主要負責:
?模型轉換:支持ONNX、PyTorch、TensorFlow等主流框架轉RKNN格式;
?量化優化:將FP32模型量化為INT8(支持Normal/KL-Divergence/MMSE三種算法),減小模型體積、提升推理速度;
?評估分析:在模擬器或連板狀態下,分析模型精度(余弦距離)、性能(單幀耗時)、內存(權重/中間Tensor占用)。
?RKNN Runtime(板端)
模型的“推理引擎”,分兩種API:
?通用API:易上手,數據預處理(歸一化、格式轉換)在CPU完成,適合快速驗證;
?零拷貝API:高性能,預處理在NPU完成,數據無需CPU-NPU拷貝(直接用物理地址/fd),適合攝像頭、視頻解碼等低延遲場景。
?RKNN Server(板端)
連板調試的“橋梁”,運行在開發板后臺,接收PC端Toolkit2的指令,轉發數據/推理結果,支持多設備管理。
二、開發全流程:從0到1部署一個模型
以“MobileNet圖像分類模型”為例,帶大家走一遍完整開發流程,關鍵步驟附實操代碼和注意事項:
1.開發全流程圖表

2. step 1:環境準備
(1)PC端:安裝RKNN-Toolkit2
推薦用Docker(避免環境沖突),命令如下:
# 1. 安裝Docker并添加用戶組sudo groupadd dockersudo usermod -aG docker$USERnewgrp docker# 2. 加載RKNN-Toolkit2鏡像(鏡像從瑞芯微網盤下載)docker load --input rknn-toolkit2-x.x.x-cpxx-docker.tar.gz# 3. 啟動容器(映射USB和示例代碼)docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /your/examples:/examples rknn-toolkit2:x.x.x-cpxx /bin/bash
(2)板端:確認NPU環境
開發板必須滿足3個條件:
?NPU驅動版本≥0.9.2(查詢命令:cat /sys/kernel/debug/rknn/driver_version);
?RKNN Server已啟動(查詢命令:ps | grep rknn_server,未啟動則執行restart_rknn.sh);
?Runtime庫版本與Toolkit2匹配(如Toolkit2 v2.0.0需librknnrt.so v2.0.0)。
3. step 2:模型轉換(核心步驟)
以ONNX模型為例,用Toolkit2的Python接口實現轉換:
fromrknn.apiimportRKNN# 1. 初始化RKNN對象rknn = RKNN(verbose=True)# 2. 配置轉換參數(目標平臺、均值/歸一化、量化)rknn.config(mean_values=[[103.94,116.78,123.68]], # 與訓練時一致std_values=[[58.82,58.82,58.82]],target_platform='rk3588', # 目標硬件(如rk3566、rv1106)quantized_algorithm='normal', # 量化算法do_quantization=True# 開啟量化)# 3. 加載ONNX模型ret = rknn.load_onnx(model='./mobilenet_v2.onnx')# 4. 量化構建(需準備校正集dataset.txt,每行1張圖片路徑)ret = rknn.build(do_quantization=True, dataset='./dataset.txt')# 5. 導出RKNN模型ret = rknn.export_rknn('./mobilenet_v2.rknn')# 6. 釋放資源rknn.release()
關鍵注意點:
?校正集(dataset.txt)需覆蓋業務場景(如分類模型需包含所有類別圖片),數量建議20-200張;
?目標平臺(target_platform)必須與開發板一致,否則模型無法運行(RK3566/3568通用,RK3588/3588S通用)。
4. step 3:模型評估(避坑關鍵)
轉換后的模型,必須先評估再部署,避免“能跑但精度/性能不達標”:
# 1. 初始化運行時(連板評估,target設為開發板型號)ret= rknn.init_runtime(target='rk3588', device_id='515e9b401c060c0b')# 2. 精度分析(對比量化模型與浮點模型的每層誤差)ret= rknn.accuracy_analysis(inputs=['./test.jpg'], target='rk3588')# 3. 性能評估(輸出單幀耗時、FPS、每層算子耗時)perf_detail= rknn.eval_perf()# 4. 內存評估(輸出權重、中間Tensor內存占用)mem_detail= rknn.eval_memory()
評估結果解讀:
?精度:余弦距離越接近1(如0.999),誤差越小;
?性能:RK3588運行MobileNetV2,INT8量化后FPS可達100+;
?內存:權重內存≈3.5MB,總內存≈5.4MB(符合邊緣設備需求)。
5. step 4:板端部署(C/Python任選)
(1)Python部署(快速驗證,用RKNN-Toolkit Lite2)
from rknn.api import RKNNLite# 1. 初始化RKNNLite對象rknn_lite = RKNNLite(verbose=True)# 2. 加載RKNN模型ret = rknn_lite.load_rknn('./mobilenet_v2.rknn')# 3. 初始化運行時(多核配置:RK3588可設NPU_CORE_0_1_2)ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_ALL)# 4. 預處理輸入圖片img = cv2.imread('./test.jpg')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = np.expand_dims(img, 0)# 5. 推理outputs = rknn_lite.inference(inputs=[img])# 6. 后處理(輸出TOP5類別)show_top5(outputs)# 7. 釋放資源rknn_lite.release()
(2)C部署(高性能,用RKNN Runtime)
核心流程:初始化模型→設置輸入→推理→獲取輸出→釋放資源,關鍵代碼片段:
intmain(){rknn_context ctx;// 1. 初始化模型ret =rknn_init(&ctx, model_buf, model_len,0,NULL);// 2. 查詢輸入輸出屬性rknn_input_output_num io_num;rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num,sizeof(io_num));// 3. 設置輸入數據rknn_input inputs[io_num.n_input];inputs[0].index =0;inputs[0].type = RKNN_TENSOR_UINT8;inputs[0].fmt = RKNN_TENSOR_NHWC;inputs[0].buf = img_data;inputs[0].size = img_size;rknn_inputs_set(ctx, io_num.n_input, inputs);// 4. 推理rknn_run(ctx,NULL);// 5. 獲取輸出rknn_output outputs[io_num.n_output];rknn_outputs_get(ctx, io_num.n_output, outputs,NULL);// 6. 后處理post_process(outputs);// 7. 釋放資源rknn_outputs_release(ctx, io_num.n_output, outputs);rknn_destroy(ctx);return0;}
三、進階優化:讓模型跑更快、更省內存
掌握以下技巧,能讓RKNPU性能翻倍、內存占用減半,尤其適合邊緣設備:
1.性能優化
(1)NPU多核配置(RK3588/RK3576專屬)
RK3588有3個NPU核,RK3576有2個,通過core_mask設置多核運行:
# Python(Toolkit2)rknn.init_runtime(target='rk3588', core_mask=RKNN.NPU_CORE_0_1_2)# C APIrknn_set_core_mask(ctx, RKNN_NPU_CORE_0_1_2);
效果:MobileNetV2在RK3588上,多核運行比單核快2.5倍。
(2)零拷貝API(減少DDR帶寬消耗)
適合攝像頭、視頻解碼等場景,數據直接用物理地址:
// 1. 創建外部分配內存(用物理地址)rknn_tensor_mem* input_mem =rknn_create_mem_from_phys(ctx, phys_addr, virt_addr, size);// 2. 設置零拷貝輸入rknn_set_io_mem(ctx, input_mem, &input_attr);// 3. 推理rknn_run(ctx,NULL);
效果:數據拷貝耗時減少80%,端到端延遲降低30%。
2.內存優化
(1)RK3588 SRAM使用(減輕DDR壓力)
RK3588有956KB SRAM,可分配給NPU存中間Tensor:
// 初始化時開啟SRAMret =rknn_init(&ctx, model, size, RKNN_FLAG_ENABLE_SRAM,NULL);
查詢SRAM使用:cat /sys/kernel/debug/rknn/mm,可看到已用/剩余大小。
(2)動態Shape(單模型支持多分辨率)
無需生成多個模型,一個模型支持多種輸入尺寸(如224x224、192x192):
# 配置動態輸入dynamic_input = [[[1,3,224,224]],[[1,3,192,192]]]rknn.config(dynamic_input=dynamic_input)
場景:NLP模型(可變序列長度)、圖像分割(可變分辨率)。
3.模型優化
(1)混合量化(精度與性能平衡)
對精度敏感的層(如輸出層)用FP16,其他層用INT8:
# 混合量化配置文件custom_quantize_layers:Conv__350 float16 # 指定層用FP16quantize_parameters:FeatureExtractor/Convqtype: asymmetric_quantizeddtype: int8
(2)模型剪枝(無損減小體積)
開啟model_pruning,自動移除冗余權重:
rknn.config(model_pruning=True)
效果:MobileNetV2權重減少6.9%,運算量減少13.4%,精度無損失。
四、避坑指南:開發者常踩的5個坑
1.連板調試失敗
?原因:RKNN Server未啟動或版本不匹配;
?解決:執行restart_rknn.sh,確保Server版本與Toolkit2一致。
1.量化后精度下降嚴重
?原因:校正集不具代表性,或量化算法選擇不當;
?解決:更換KL-Divergence/MMSE算法,增加校正集數量(50-100張)。
1.模型轉換報錯“動態Shape不支持”
?原因:Toolkit2 < 1.5.2?不支持動態Shape;
?解決:升級Toolkit2到1.5.2+,用dynamic_input配置。
1.板端推理耗時比連板評估長
?原因:連板評估有數據傳輸開銷,板端推理更真實;
?解決:以板端C API的eval_perf結果為準。
1.NPU Hang住(推理耗時超20s)
?原因:驅動bug或模型超出FP16范圍;
?解決:升級NPU驅動到最新版,訓練時添加BN層限制數值范圍。
五、開發資源匯總
最后給大家整理了必備資源,收藏好少走彎路:
?RKNN Toolkit2:https://github.com/airockchip/rknn-toolkit2(含API文檔、示例);
?RKNN Model Zoo:https://github.com/airockchip/rknn_model_zoo(MobileNet、YOLOv5等預轉換模型);
?RGA庫:https://github.com/airockchip/librga(圖像縮放、旋轉加速,配合NPU使用);
?官方文檔:本文基于《RKNN SDK V2.0.0beta0用戶指南》,完整文檔可在瑞芯微官網下載。
總結
瑞芯微RKNPU開發的核心是“工具鏈熟練+優化技巧到位”:先用Toolkit2做好模型轉換與評估,再根據場景選擇通用/零拷貝API,最后通過多核、SRAM、動態Shape等技巧壓榨性能。邊緣AI部署不復雜,跟著這篇指南走,你也能快速搞定RKNPU!
如果有疑問,歡迎在評論區交流,也可以關注瑞芯微官方GitHub獲取最新動態~
(附:全文核心腦圖)
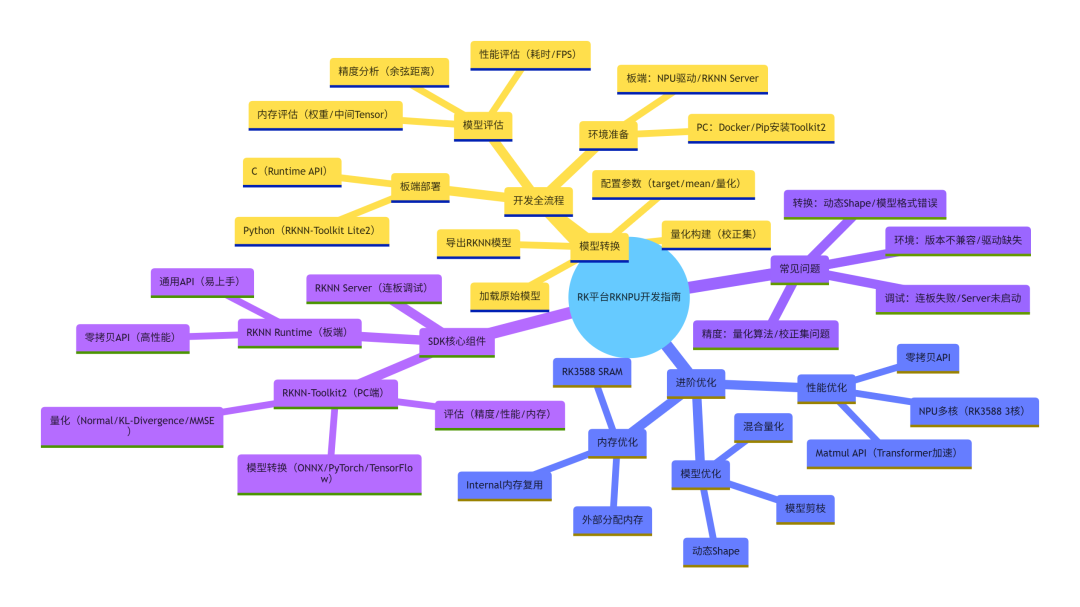
-
瑞芯微
+關注
關注
27文章
801瀏覽量
54502 -
環境搭建
+關注
關注
0文章
60瀏覽量
9478 -
邊緣AI
+關注
關注
0文章
251瀏覽量
6196
發布評論請先 登錄
瑞芯微NPU使用攻略

【飛凌嵌入式OK3576-C開發板體驗】RKNPU圖像識別測試
國產開發板的端側AI測評-基于米爾瑞芯微RK3576
基于米爾瑞芯微RK3576開發板的Qwen2-VL-3B模型NPU多模態部署評測
如何精準驅動菜品識別模型--基于米爾瑞芯微RK3576邊緣計算盒
【瑞芯微RK1808計算棒試用體驗】(1)------開發環境搭建和mobilenet_v1示例體驗
瑞芯微Toybrick AI開發平臺
【中獎公示】8.8瑞芯微RKNN系列直播一:RKNN Runtime部署指南
【中獎公示】8.11瑞芯微RKNN系列直播二:RKNN模型精度優化指南

迅為RK3568/RK3588開發板視頻教程 | RKNPU2 從入門到實踐一套搞定!




 工商網監
工商網監
評論