 基于感知引導的多步驟精細操作任務與運動規劃
基于感知引導的多步驟精細操作任務與運動規劃

傳統的任務與運動規劃(TAMP)系統在機器人操作應用中通常依賴靜態模型運行,因此在面對新環境時往往表現不佳。將感知與操作相融合,是應對這一挑戰的有效途徑,使機器人能夠在執行過程中實時更新規劃,從而適應動態變化的場景。
在本期NVIDIA 機器人研發摘要 (R2D2)中,我們探討了如何利用基于感知的 TAMP 以及 GPU 加速的 TAMP 實現遠程操作。同時,我們將介紹用于提升機器人操作能力的框架,并展示如何結合視覺與語言信息,將像素轉化為子目標、任務負載以及可微分的約束條件。
子目標是較小的階段性目標,能夠引導機器人逐步達成最終目標。
Affordance 根據物體或環境的屬性及其所處的上下文,描述機器人可在其上執行的動作。例如,手柄可被“抓取”,按鈕可被“按壓”,杯子可被“傾倒”。
在機器人運動規劃中,可微分約束用于確保機器人的運動滿足物理限制,如關節角度范圍、避障要求或末端執行器的位置精度,同時仍支持通過學習進行調整。由于這些約束具備可微性,GPU 能夠在訓練或實時規劃過程中高效地計算并優化它們。
任務與運動規劃如何將視覺與語言信息轉化為機器人的具體動作
TAMP 涉及確定機器人應執行的任務以及實現這些任務所需的移動方式,需要將高層任務規劃(即執行什么任務)與底層運動規劃(即如何移動以完成任務)相結合。
現代機器人能夠結合視覺與語言信息(如圖像和指令),將復雜任務分解為若干較小的步驟,即子目標。這些子目標有助于機器人明確下一步應執行的動作、需要交互的對象以及如何實現安全移動。
該過程利用高級模型將圖像和書面指令轉化為機器人可在現實世界中執行的清晰計劃。遠程操作需要具備結構化意圖,且依賴規劃人員的有效參與。接下來,我們將探討 OWL-TAMP、VLM-TAMP 和 NOD-TAMP 如何助力解決這一問題:
OWL-TAMP:該工作流使機器人能夠執行以自然語言描述的復雜、長視距操作任務,例如“將橙色物體放到桌子上”。OWL-TAMP 是一種混合式工作流,將視覺語言模型(VLM)與任務與運動規劃(TAMP)相結合。其中,VLM 根據開放世界語言(OWL)指令生成約束條件,描述機器人動作空間中的操作要求。這些約束被整合進 TAMP 系統,并通過仿真反饋機制驗證其物理可行性和執行正確性。
VLM-TAMP:這是一種面向視覺信息豐富環境的機器人多步驟任務規劃工作流。VLM-TAMP 將視覺語言模型與傳統 TAMP 框架融合,能夠在現實場景中生成并優化高層行動計劃。該方法利用 VLM 解析圖像內容,并結合任務指令(如“做一鍋雞湯”)生成初步的高級任務規劃。隨后,通過仿真驗證和運動規劃進行迭代優化,以確保每一步操作的可行性。在涉及 30 至 50 個連續動作、并操作多達 21 個不同物體的長視距廚房任務中,該混合方法的表現優于純 VLM 或純 TAMP 的基準方案。該工作流使機器人能夠綜合利用視覺與語言上下文信息,有效應對任務描述中的模糊性,從而提升在復雜操作任務中的整體性能。
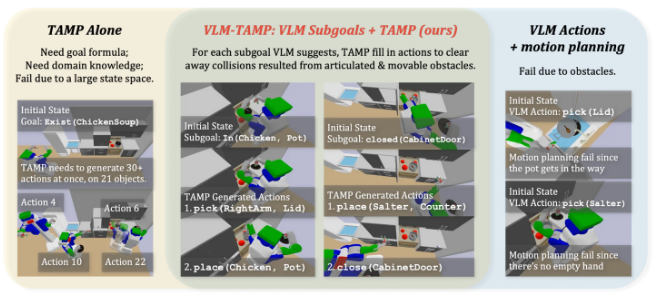
圖1展示了VLM-TAMP如何克服單獨使用TAMP或僅依賴VLM進行任務與運動規劃在解決長視距機器人操作問題時所面臨的局限性。
NOD-TAMP: 傳統的TAMP框架在處理長視距操作任務時通常難以實現泛化,因其依賴于顯式的幾何模型和對象表示。NOD-TAMP通過引入神經對象描述符(NOD)來提升對不同對象類型的泛化能力。NOD是一種基于3D激光點云學習得到的表示形式,能夠編碼物體的空間特征與關系屬性。該方法使機器人能夠與新對象有效交互,并支持規劃器進行動態的操作調整。
cuTAMP 如何利用 GPU 并行化加速機器人規劃
經典 TAMP 首先分析任務的動作結構(稱為計劃骨架),再求解相應的連續變量。第二步通常是系統的計算瓶頸,而cuTAMP顯著加速了這一過程。對于cuTAMP中給定的計劃骨架,系統會采樣數千個初始解(粒子),隨后在 GPU 上執行可微分的批量優化,以滿足多種約束條件,例如逆運動學、避障、穩定性以及目標函數成本。
如果框架不可行,算法會進行回溯;如果可行,則會生成一個計劃。對于受限的打包或堆疊任務,該過程通常在幾秒鐘內完成,使機器人能夠在幾秒內找到包裝、堆疊或操作多個物體的解決方案,而無需花費幾分鐘甚至幾小時。
“矢量化滿意度”是實現在現實應用場景中長期解決問題的關鍵。
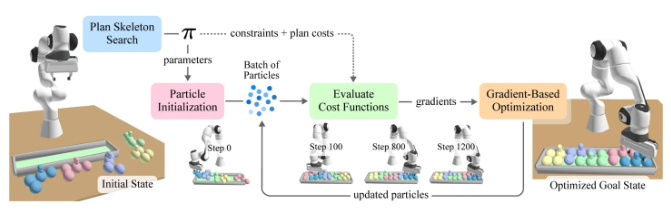
圖2展示了cuTAMP如何將TAMP幀化為一種回溯式的雙層搜索,以優化計劃骨架。
機器人如何利用Stein變分推斷從故障中學習
長距操作模型在面對訓練過程中未曾遇到的新條件時,可能會出現失效。Fail2Progress是一種使機器人能夠從自身失敗中學習并持續改進操作能力的框架。該框架通過數據驅動的校正與基于仿真的優化,將實際發生的故障整合進技能模型中。為了增強模型的魯棒性,Fail2Progress 利用 Stein 變分推斷生成與觀測到的故障相似的定向合成數據集,從而有效提升模型對異常情況的適應能力。
然后,這些生成的數據集可用于微調并重新調整技能效果模型,從而降低長視野任務中相同故障重復發生的次數。
入門指南
在這篇博客中,我們探討了基于感知的TAMP、GPU加速的TAMP,以及用于機器人操作的基于仿真的優化框架。我們分析了傳統TAMP中常見的挑戰,并介紹了這些研究工作為應對這些挑戰所提出的方法與思路。
本文是NVIDIA 機器人研發摘要(R2D2)系列的一部分,旨在幫助開發者深入了解NVIDIA Research在物理 AI 與機器人應用領域的最新突破。
-
機器人
+關注
關注
213文章
30491瀏覽量
219113 -
NVIDIA
+關注
關注
14文章
5480瀏覽量
108958 -
gpu
+關注
關注
28文章
5076瀏覽量
134285 -
仿真
+關注
關注
52文章
4393瀏覽量
137597
原文標題:R2D2:基于感知引導的多步驟精細操作任務與運動規劃
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
運動控制速度規劃
做個任務規劃大師來幫你!
近距輕掃和運動感知視頻展示雷達IC應用
分布式多步驟入侵場景建模及其抽象描述
鋅合金壓鑄機主機操作方法和步驟
STM32實現多步進電機的加減速運動控制

自動駕駛綜述之定位、感知、規劃常見算法匯總
基于邊界點優化和多步路徑規劃的機器人自主探索策略
基于感知質量的無人機ActiveSLAM解決方案
無引導線的左轉場景下,自動駕駛如何規劃軌跡?





 工商網監
工商網監
評論