 Google翻譯出現“水逆”,是員工的惡作劇?
Google翻譯出現“水逆”,是員工的惡作劇?

最近,一些網友使用的 Google 翻譯“水逆”了。
在Reddit上,有網友截圖顯示,在 Google 翻譯中當某些語種的詞匯翻譯成英語時,輸出的卻是毫無由頭的宗教語言。比如鍵入 19 個 dog,將其從毛利語翻譯成英語時,輸出的卻是“距離十二點的世界末日時鐘還差三分鐘,我們正在經歷世界上的人物和戲劇性發展,這預示著我們正在無線接近末日,耶穌回歸時日將近。”
但這只是眾多無厘頭翻譯的其中之一。還有網友放出了很多“不詳”的翻譯內容。例如,在索馬里語中,“ag”這個詞被翻譯成了“Gershon 的兒子(sons of Gershon)”,“耶和華的名字(name of the LORD)”,并且會引用圣經里的“cubits”(計量單位)和Deuteronomy(《申命記》)。
有網友留言稱其為“惡魔”或者“幽靈”,猜測這是 Google 員工的惡作劇,也有人建議設置“建議編輯”功能,讓用戶可以進行修改為正確內容。Google 發言人 Justin Burr 在一封電子郵件中稱:這只是一個將無意義的話語輸入系統然后產生無意義輸出的功能。
不過 Justin Burr 并未透露 Google 翻譯使用的訓練數據是否有宗教文本。但上述詭異輸出內容很可能已被 Google 翻譯修正,AI科技大本營編輯輸入上述相同內容后也并未發現異常。
但人們對探討 Google 翻譯出現如此結果的背后原因熱情不減,更專業的聲音在不斷發出。哈佛大學助理教授 Andrew Rush 認為,這很可能與 2 年前 Google 翻譯技術的改變有關,它目前使用了的是“神經機器翻譯(NMT)”的技術。
BBN Technologies 的科學家 Sean Colbath 從事機器翻譯工作,他同意奇怪的輸出可能是由于 Google 翻譯的算法試圖在混亂中尋找秩序。他還指出,索馬里語、夏威夷語以及毛利語等產生最奇怪結果的語言,它們用于訓練的翻譯文本比英語或漢語等更廣泛使用的語言要少很多。所以他認為,Google 可能會使用像圣經等被翻譯成多種語言的宗教文本來訓練小語種的模型,這也解釋了為什么會最終輸出宗教內容。
前 Google 員工 Delip Rao 在其博客上則指出,當談到平行語料庫時,宗教文本是最低層次的共同標準資源,像“圣經”和“古蘭經”這樣的主要宗教文本有各種語言版本。
比如,如果你為政府部署一個 Urdu-to-English (烏爾都語——英語)的機器翻譯系統,那么很容易將一堆已經翻譯成烏爾都語的宗教文本組合在一起。因此,可以合理地假設 Google 的平行語料庫中包含所有的宗教文本,而對于許多資源不足的語言,它們不只是訓練語料庫中微不足道的部分。
那么,為什么我們看到 Google 翻譯會輸出宗教文本,尤其是以那些資源不足的語言對作為輸入時 ,如上文中的毛利語?一種解釋是,因為宗教文本包含許多只會在宗教文本中出現的罕見詞,而這些詞在其他任何地方都不會出現。因此,罕見的詞語可能會觸發解碼器中的宗教情境,尤其是當這些文本的比例很大時。另一種解釋是該模型對輸入的內容沒有太多的統計支持,而輸出也只是解碼器模型的無意義采樣。
更重要的是,他想要指出現在的神經機器翻譯 (NMT) 真正存在的問題。
他特意總結了2017 年 Philipp Koehn 和 Rebecca Knowles 撰寫的一篇論文,內容如下:
1.NMT 在域外數據上表現很差:像 Google 翻譯這樣的通用 MT 系統在法律或金融等專業領域的表現尤其糟糕。此外,與基于短語的翻譯系統等傳統方法相比,NMT 系統的效果更差。到底有多糟糕?如下圖所示,其中非對角線元素表示域外結果,綠色是 NMT 的結果,藍色是基于短語的翻譯系統的結果。
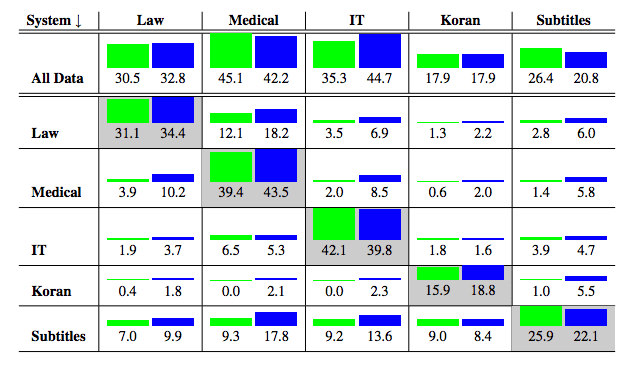
MT 系統在一個域 (行) 上訓練并在另一個域 (列) 上進行測試。藍色表示基于短語翻譯系統的表現,而綠色表示 NMT 的表現。
2.NMT 在小數據集上的表現很差:雖然這算是機器學習的通病,但這個問題在 NMT 中體現尤其明顯。相比基于短語的 MT 系統,雖然 NMT 隨著數據量的增加能進行更好地概括 ,但在小數據量情況下 NMT 的表現確實更糟糕。
引用作者的話來說,“在資源較少的情況下,NMT 會產生與輸入無關的輸出,盡管這些輸出是流暢的。”這可能也是 Motherboard 那篇文章中探討 NMT 表現怪異的另一個原因。
3.Subword NMT 在罕見詞匯上的表現很糟糕:雖然它的表現仍然要好過基于短語的翻譯系統,但對于罕見或未見過的詞語,NMT 的表現不佳。例如,那些系統只觀察到一次的單詞就會被 drop 掉。像 byte-pair encoding 這樣的技術對解決這個問題有所幫助,但我們有必要對此進行更詳細的研究。
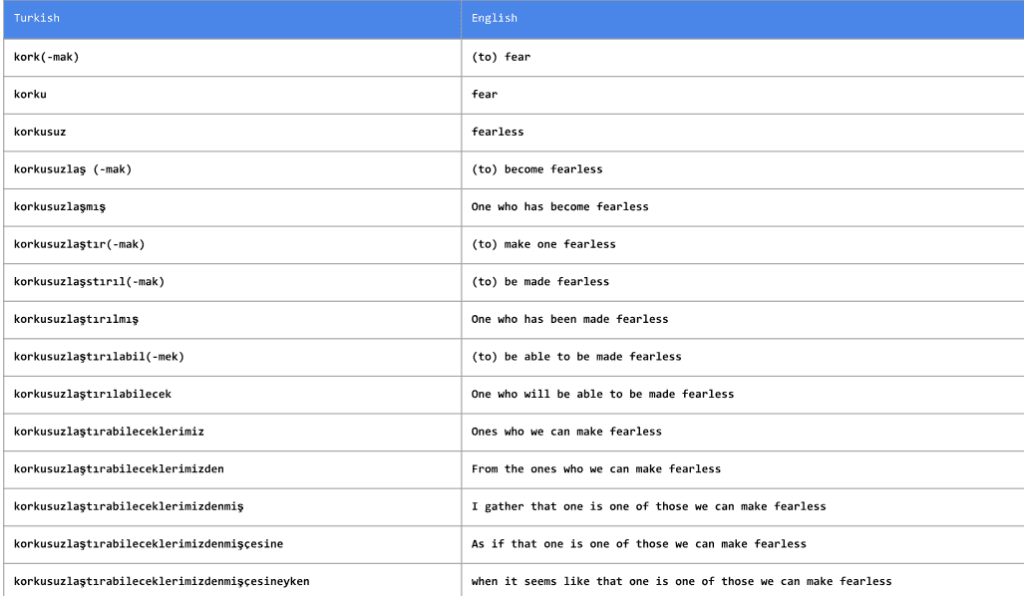
我們可以看到圖中像土耳其語 (Turkish) 這樣的語言,遇到詞的變形形式是很常見的。
4.長句:以長句編碼并產生長句,這仍然是一個開放的、值得研究的話題。在法律等領域,冗長復雜的句子是很常見的。MT 系統的性能將隨句子長度而降級,而 NMT 系統亦是如此。引入注意力機制可能會有所幫助,但問題還遠未解決。
5.注意力機制 != 對齊:這是一個非常微妙但又很重要的問題。在傳統的 SMT 系統中,如基于短語的翻譯系統,語句對齊能夠提供有用的調試信息來檢查模型。但即便論文中經常將軟注意力機制視為“軟對齊”,注意力機制并不是傳統意義上的對齊。在 NMT 系統中,除了源域中的動詞外,目標中的動詞也可以作為主語和賓語。
6.難以控制翻譯質量:每個單詞都有多種翻譯,并且典型的 MT 系統對源句的翻譯好于lattice of possible translations。為了保持后者的大小合理,我們使用集束搜索 (beam search)。通過改變波束的寬度,來找到低概率但正確的翻譯。而對于 NMT 系統,調整集束尺寸似乎沒有任何不利影響。
當你擁有大量數據時,NMT 系統的翻譯性能依然還是難以被擊敗的,而且它們仍然在大量地被使用。關于通常我們所說的神經網絡模型的黑盒性,也有待進一步說明,如今的 NMT 模型 (基于 LSTM 和 Transformer 模型) 也都受此影響。
-
Google
+關注
關注
5文章
1807瀏覽量
60519 -
翻譯
+關注
關注
0文章
47瀏覽量
11175
原文標題:輸出不詳宗教預言,Google翻譯為何“水逆”了?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
谷歌推出TranslateGemma全新開放翻譯模型系列
Ubuntu下使用NucleiStudio IDE進行編譯時出現問題,怎么解決?
使用RT-thread studio 編譯vision board ,出現了8個錯誤,怎么解決?
當翻譯失去網絡,時空壺新T1翻譯機開創首個離線模型賦能全球溝通新體驗

谷歌查找我的設備配件(Google Find My Device Accessory)詳解和應用
求助,關于STM32H743使用DSP進行矩陣求逆計算出現的問題求解
無線水浸傳感器? 的完整解決方案設計

人臉識別門禁一體機,如何解決員工宿舍區安全混亂問題?

Google Fast Pair服務簡介
手動添加cubeMX的軟件自動生成代碼后,編譯出現’rtthread.elf’:No Such File 的錯誤怎么解決?
使用rt-thread構建openmv的固件工程,出現編譯錯誤的原因?
瑞薩RA單片機在e2 studio環境下printf編譯出錯的問題解析



 工商網監
工商網監
評論