") 基于瑞薩RA8M1 MCU的高性能語(yǔ)音控制應(yīng)用方案
基于瑞薩RA8M1 MCU的高性能語(yǔ)音控制應(yīng)用方案

瑞薩電子面向語(yǔ)音AI,基于VK-RA8M1開(kāi)發(fā)套件,集成多種智能語(yǔ)音處理功能,實(shí)現(xiàn)了無(wú)需云端的高性能語(yǔ)音控制的應(yīng)用。
功能介紹
目前語(yǔ)音控制技術(shù)已廣泛應(yīng)用于家電、車(chē)載、智能家居等領(lǐng)域,但仍面臨兩個(gè)核心問(wèn)題:
環(huán)境噪聲干擾。當(dāng)嘈雜環(huán)境或多人講話時(shí),語(yǔ)音識(shí)別準(zhǔn)確率會(huì)大幅下降。
對(duì)云連接的依賴。離線狀態(tài)下,通常只能識(shí)別少量、固定順序的關(guān)鍵詞,實(shí)現(xiàn)功能有限。
瑞薩推出的集成式語(yǔ)音應(yīng)用場(chǎng)景,將多種語(yǔ)音控制功能集成一體,以應(yīng)對(duì)這些問(wèn)題。
基于RA8M1的語(yǔ)音應(yīng)用包括如下功能:
APF(Audio Processing Front)。音頻處理前端,可將語(yǔ)音與背景噪音分離,提高語(yǔ)音識(shí)別準(zhǔn)確率。
NLU(Natural Language Understanding)。自然語(yǔ)言理解,允許用戶用自然口語(yǔ)發(fā)出指令,系統(tǒng)自動(dòng)提取關(guān)鍵詞識(shí)別命令。
CNSV(Cyberon Speaker Verification )。Cyberon語(yǔ)音驗(yàn)證,將關(guān)鍵詞檢測(cè)提升到更高層次,將語(yǔ)音識(shí)別升級(jí)為語(yǔ)音身份驗(yàn)證。
VAS(Voice Anti-Spoofing)。語(yǔ)音防偽技術(shù),使系統(tǒng)能夠區(qū)分真人語(yǔ)音和錄音。

圖1 RA8M1語(yǔ)音應(yīng)用場(chǎng)景
功能演示
APF噪聲抑制演示
A8M1開(kāi)發(fā)板已預(yù)先加載語(yǔ)音組合程序,通過(guò)USB 連接電腦,作為立體聲麥克風(fēng)使用。
通常,我們會(huì)在理想安靜的環(huán)境中錄制視頻,但為了演示降噪的功能,在演示用例中,刻意引入了環(huán)境噪音。如圖2所示。
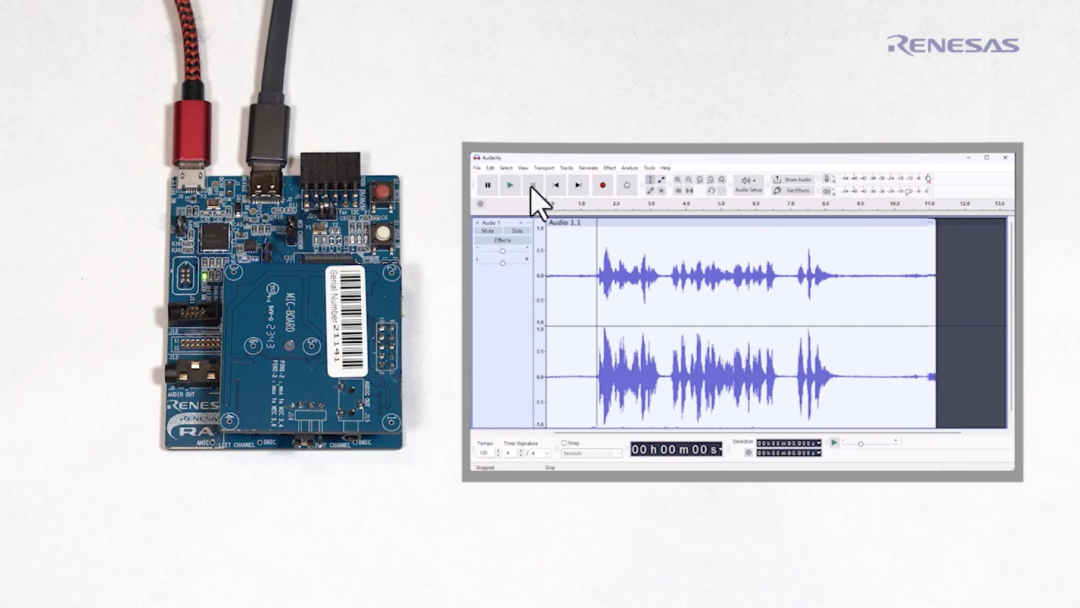
圖2 左/右聲道波形對(duì)比
在演示用例中,采用立體聲軌來(lái)直觀呈現(xiàn)APF的處理效果。其中,左聲道顯示的是未處理音頻,右聲道顯示的是經(jīng)過(guò)APF處理后的音頻。如圖3所示。
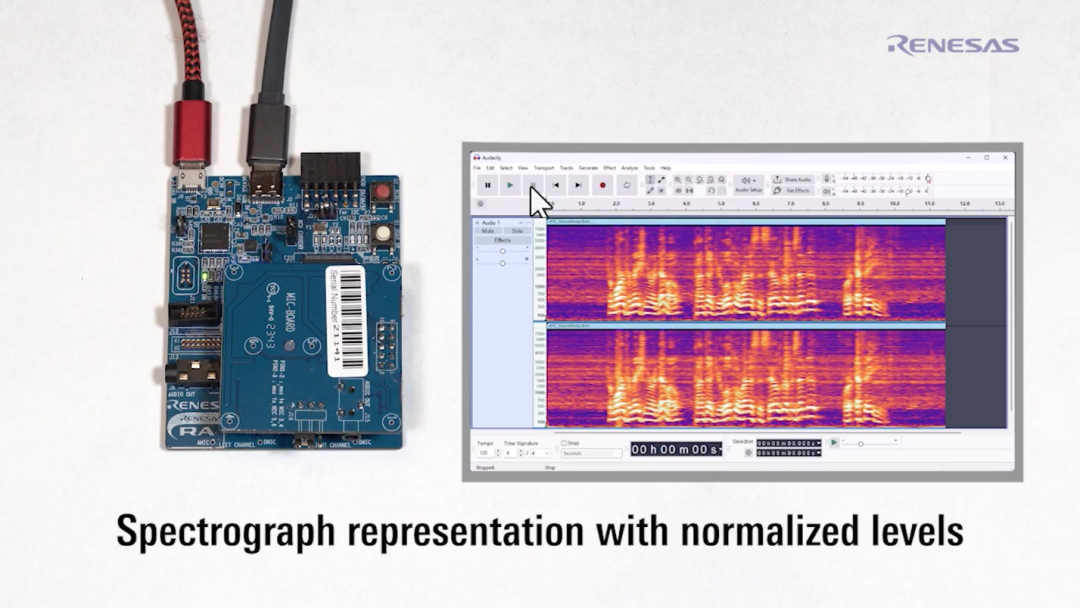
圖3 聲譜圖對(duì)比
從圖3中可以看到:
上方的左聲道展現(xiàn)了未經(jīng)過(guò)APF處理的原始音頻波形。噪音和語(yǔ)音混雜,語(yǔ)音信號(hào)不明顯。
下方的右聲道展現(xiàn)了經(jīng)過(guò)APF處理后的音頻波形。背景噪音被明顯抑制,語(yǔ)音信號(hào)更加清晰。
NLU、CNSV、VAS綜合演示
在演示用例中,可以同時(shí)實(shí)現(xiàn)識(shí)別關(guān)鍵詞、語(yǔ)音身份認(rèn)證、真人語(yǔ)音識(shí)別的功能,通過(guò)下述操作,可逐個(gè)演示功能:
1注冊(cè)說(shuō)話人的語(yǔ)音信息。根據(jù)系統(tǒng)提示,重復(fù)說(shuō)三遍“Hi Renesas”,用于創(chuàng)建準(zhǔn)確的聲紋識(shí)別模型。注冊(cè)時(shí)的顯示信息如圖4所示。
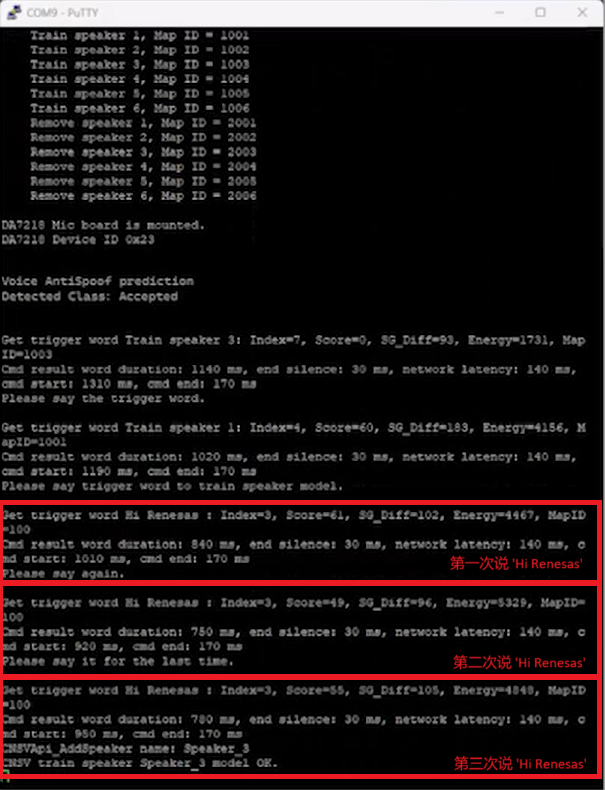
圖4 注冊(cè)說(shuō)話人的語(yǔ)音信息
2使用說(shuō)話人的聲音發(fā)出“Hi Renesas”的指令。系統(tǒng)顯示“Accepted”,表明成功識(shí)別說(shuō)話人聲音。如圖5所示。
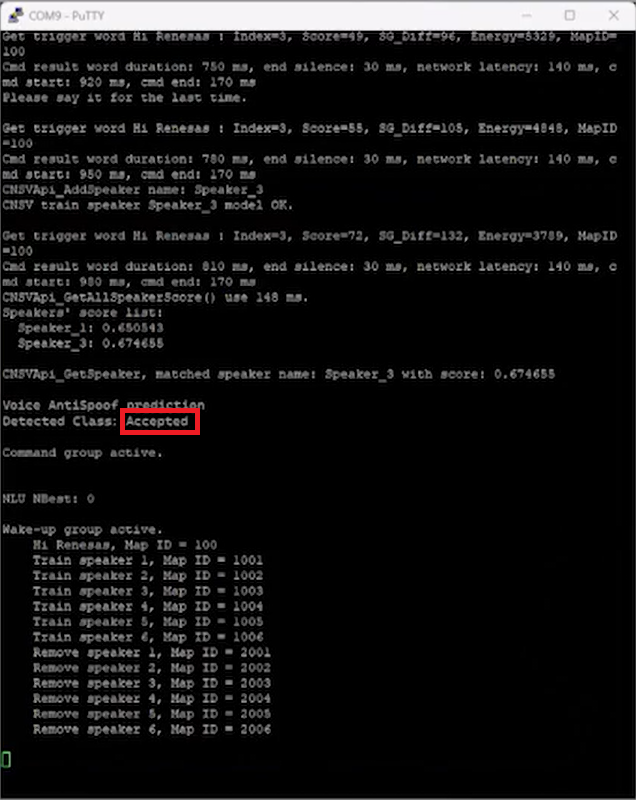
圖5 系統(tǒng)成功識(shí)別說(shuō)話人的聲音
3用手機(jī)錄制“Hi Renesas”的指令,如圖6所示。

圖6 錄制聲音
4用錄音發(fā)出“Hi Renesas”的指令讓系統(tǒng)識(shí)別。系統(tǒng)顯示“Dropped”,表明識(shí)別失敗并拒絕執(zhí)行,成功區(qū)分真人語(yǔ)音和錄音。如圖7所示。
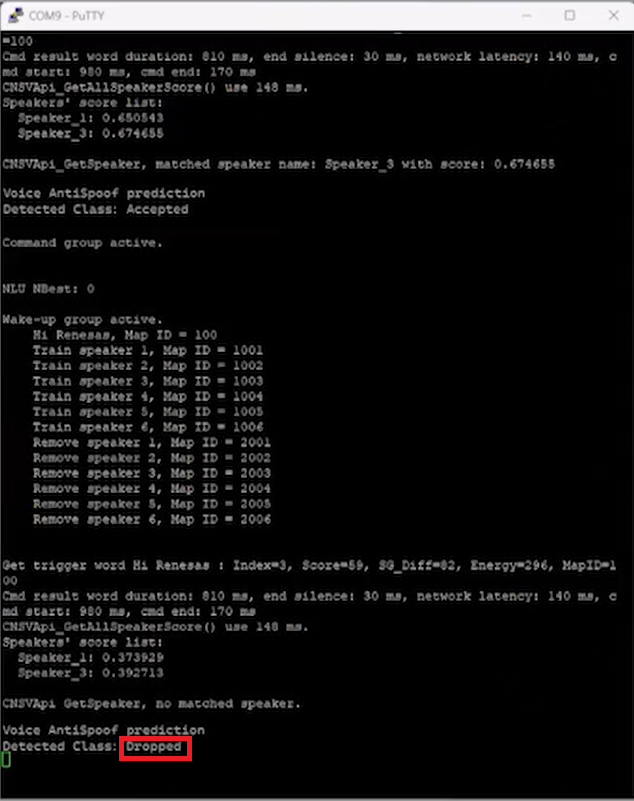
圖7 用錄音發(fā)出指令,系統(tǒng)識(shí)別失敗
總結(jié)
實(shí)現(xiàn)這些實(shí)時(shí)語(yǔ)音的AI功能,對(duì)MCU的性能要求非常高,而RA8M1搭載的Cortex-M85內(nèi)核支持Helium DSP加速技術(shù),能夠大幅提升語(yǔ)音算法的本地運(yùn)行性能,從而在無(wú)需接入云端的情況下完成這些處理。
-
mcu
+關(guān)注
關(guān)注
147文章
18990瀏覽量
399889 -
AI
+關(guān)注
關(guān)注
91文章
40201瀏覽量
301831 -
瑞薩電子
+關(guān)注
關(guān)注
39文章
2979瀏覽量
74435 -
語(yǔ)音控制
+關(guān)注
關(guān)注
5文章
513瀏覽量
29706
原文標(biāo)題:基于RA8M1的語(yǔ)音AI綜合應(yīng)用演示
文章出處:【微信號(hào):瑞薩嵌入式小百科,微信公眾號(hào):瑞薩嵌入式小百科】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
分享四款使用瑞薩RA8M1 MCU或RA8D1 MCU的成功產(chǎn)品組合解決方案

瑞薩RA8系列高性能MCU開(kāi)發(fā)上手體驗(yàn)

端到端語(yǔ)音解決方案的Renesas RA8M1語(yǔ)音套件

瑞薩面向電機(jī)控制應(yīng)用推出性能卓越的RA8 MCU

【野火啟明6M5開(kāi)發(fā)板體驗(yàn)】野火啟明開(kāi)發(fā)板和瑞薩RA MCU介紹
瑞薩RA系列MCU選型指南
RT-Thread支持瑞薩全新超高性能Arm? Cortex?-M85 MCU
業(yè)界首款基于Arm Cortex-M85的超高性能MCU
新品發(fā)布 | 瑞薩推出面向圖形顯示應(yīng)用和語(yǔ)音/視覺(jué)多模態(tài)AI應(yīng)用的全新RA8 MCU產(chǎn)品群
瑞薩電子宣布推出RA8D1微控制器(MCU)產(chǎn)品群

AMEYA360 | 皇華:瑞薩面向電機(jī)控制應(yīng)用推出性能卓越的RA8 MCU
瑞薩電子發(fā)布業(yè)界首款基于Cortex-M85處理器的全新超高性能MCU

貿(mào)澤電子開(kāi)售提供端到端語(yǔ)音解決方案的 Renesas Electronics RA8M1語(yǔ)音套件
簡(jiǎn)單認(rèn)識(shí)瑞薩RA8系列單片機(jī)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論