") 自動駕駛中提到的WEWA架構(gòu)是個啥?
自動駕駛中提到的WEWA架構(gòu)是個啥?

[首發(fā)于智駕最前沿微信公眾號]最近有小伙伴在留言區(qū)留言,想讓我聊聊現(xiàn)在非常火熱的WEWA架構(gòu),相較于VLA,WEWA有何區(qū)別,今天就簡單聊聊這個內(nèi)容,也期待大家在評論區(qū)留言討論。
什么是WEWA?
WEWA全稱可以理解為“World Engine+World Action”。它把實現(xiàn)自動駕駛的思路拆成兩層,一層在云端,負責“造世界、訓練模型、把難題推演透”;另一層在車端,負責“看世界、理解世界、直接下決定并把車開出去”。云端是大腦的訓練工廠,車端是實時決策與執(zhí)行的現(xiàn)場指揮。這樣做有一個好處,那就是可以把稀有但危急的邊緣場景用數(shù)據(jù)和模型在云端“補齊”,把實力更強的行為模型蒸餾、裁剪后放到車上,讓車能用盡可能低的延遲、盡可能接近人類的方式去處理突發(fā)狀況。
WEWA的“World Engine”其實更側(cè)重生成和仿真,尤其是長尾和“難例”場景的合成;“World Action”則是車端的行為模型,依賴多模態(tài)感知(攝像頭、毫米波/雷達/激光雷達、車內(nèi)外麥克風等),并通過一種多專家(Mixture of Experts,MoE)機制在運行時選擇或組合最佳決策路徑。訓練在云,推理在車,這是它最核心的運作節(jié)奏。

WEWA和VLA有何區(qū)別?
與現(xiàn)在自動駕駛行業(yè)非常火熱的VLA相比,WEWA有什么區(qū)別?VLA的核心思想是把視覺理解和語言推理聯(lián)系起來,讓模型用類似“語言”的中間表示來解釋、推理世界,進而生成動作。這種方式的優(yōu)點是可解釋性更強,好的VLA系統(tǒng)在推理鏈路上能讓工程師更容易理解為什么會做出某個決策,也便于用文本/符號做高層規(guī)劃或嵌入人機交互。
WEWA則選擇跳過“語言”這一步,直接把世界狀態(tài)映射到動作。它不把感知到的信息先翻譯成符號化的語言再推理,而是把云端訓練出的世界模型(擅長物理推演與行為預(yù)測)蒸餾成車端可運行的行為模型,由多模態(tài)輸入直接驅(qū)動決策與軌跡輸出。這樣做的直接效果就是省去了從“感知→符號化語言→推理→動作”這段可能產(chǎn)生的精度損耗與時間延遲。
VLA路線通常更仰仗大規(guī)模真實路測數(shù)據(jù),把大量實車里程當作模型上限的重要組成部分;而WEWA更強調(diào)用高質(zhì)量的仿真與合成數(shù)據(jù)去補齊那些在現(xiàn)實中幾乎見不到但安全關(guān)鍵的邊緣場景。
WEWA的幾個技術(shù)優(yōu)勢
汽車是高實時性、高安全邊界的系統(tǒng),任何多一步的數(shù)據(jù)轉(zhuǎn)換或延遲都會放大風險。WEWA的設(shè)計選擇正是從這類工程約束出發(fā)的,因此它在幾個地方有明顯的工程優(yōu)勢。
1)低延時更利于“車端即時控制”
WEWA把訓練好的行為模型蒸餾到車端并與多模態(tài)感知直接聯(lián)動,避免了把信息先翻譯成語言符號再做二次推理的過程。少一次轉(zhuǎn)換,就少一次可能的精度損失和延遲。華為ADS4就是采用WEWA技術(shù)架構(gòu),據(jù)其官方介紹,這一架構(gòu)下的端到端時延降低了約一半,這種延時改進在高速與突發(fā)場景下直接等同于多一層安全緩沖。
2)更高效覆蓋長尾“難例”
真正危及安全的罕見場景在現(xiàn)實中其實非常稀少,單靠車隊跑數(shù)據(jù)很難在可接受的時間內(nèi)覆蓋所有會導致嚴重后果的邊緣場景。WEWA把“難例擴散生成模型”放在云端,通過合成與仿真生成高密度的極端場景用于訓練,云端能在短時間內(nèi)把非常多、非常罕見但具有代表性的危險場景喂給模型,提升模型在這些極端場景下的魯棒性。VLA路線雖也重視仿真,但往往更依賴真實路測去獲得臨界狀態(tài)數(shù)據(jù),這會受限于采集效率和時間窗口。
3)蒸餾與MoE帶來資源與性能的折衷
WEWA架構(gòu)下,云端可以訓練體量更大的“世界模型”,車端運行的是蒸餾后、經(jīng)過剪枝和專門優(yōu)化的“世界行為模型”。再結(jié)合MoE這種運行時只激活部分專家(而不是總調(diào)用全部模型)的策略,能在有限算力下實現(xiàn)接近大模型的決策能力。這能讓整套系統(tǒng)在車端對算力的需求更溫和,也讓軟硬件協(xié)同調(diào)優(yōu)的可能性變多。
4)端云協(xié)同提升迭代效率
WEWA把復雜訓練放在云端,更新和能力提升可以通過OTA把改進快速推到車上;同時,云端的仿真與真實回放能形成閉環(huán),理論上能更快把在車上發(fā)現(xiàn)的“新難例”補回到訓練集中去,這種端云的正反饋對能力加速很有幫助。
以上這些都是WEWA的技術(shù)賣點,但其也有一些潛在的問題。仿真生成的場景質(zhì)量決定了訓練結(jié)果的上限,如果生成模型沒把物理細節(jié)或光學特性還原好,訓練出的行為模型在現(xiàn)實會遭遇分布偏差。還有就是跳過“語言”層,所帶來的可解釋性劣勢也是必須面對的事實,沒有清晰的中間符號,工程師在調(diào)試復雜失敗案例時會更難定位問題根源。再者,蒸餾雖能壓縮模型,但在極端態(tài)下有可能喪失一些細微但關(guān)鍵的決策能力,如何在壓縮與安全之間做平衡,是需要解決的問題。
體驗才是檢驗一切的標尺
無論架構(gòu)上講得多漂亮,只有用戶體驗和道路實測才是判斷一個技術(shù)最好的場所。WEWA要保證的是在真實路況下“看起來順、開起來安全”。體驗好不好往往由系統(tǒng)在突發(fā)情境下反應(yīng)是否自然、是否能避免過度干預(yù)、能否在復雜場景下給出穩(wěn)定而可預(yù)測的行為等幾個直觀感受決定的。
VLA把語言中間表示作為橋梁,某些場景下能更容易解釋“為什么這么做”,這對用戶信任和工程調(diào)試有幫助。但解釋性并不等于效果好,解釋性強的推理若因延遲或精度損失導致決策遲鈍或不穩(wěn),用戶同樣不會買單。因此這兩條路線的終極較量,還是體現(xiàn)在“誰能在真實道路上、在成千上萬小時的運行中,把安全與舒適都做實”的能力。
其實用戶體驗是一個長期的迭代的過程。哪怕初期某個架構(gòu)在某些場景表現(xiàn)更優(yōu),持續(xù)的場景采集、仿真增強、模型更新和OTA能力同樣決定最終勝負。廠商之間或會越來越多地把注意力放在閉環(huán)能力上,車上出了事情是否能快速回傳并被云端吸收?云端又是否能快速把改進推回車上?這個循環(huán)的快慢直接影響能力演進速率。
最后的話
WEWA的思路是把有限的車端資源和高實時性需求放在首位,用云端補齊真實世界難以采集的長尾場景,通過蒸餾和MoE在車端做出及時且穩(wěn)健的決策。這樣做的好處在于延遲更低、能更系統(tǒng)地覆蓋難例、并且在量產(chǎn)與成本上有更現(xiàn)實的考量。VLA的長處在于解釋性、用真實數(shù)據(jù)打磨行為和把語言能力作為更高階的人機交互與推理工具。
其實對用戶而言真正有價值的,是在復雜路況下系統(tǒng)不會“慌”,在突發(fā)場景下決策既安全又合乎人的直覺。這意味著技術(shù)路線之爭的背后,本質(zhì)是對“可信賴體驗”的追求,系統(tǒng)不僅不能出錯,更要讓人安心。無論是WEWA的實時響應(yīng)還是VLA的行為可解釋,最終都是為了實現(xiàn)一種連貫、自然的駕駛風格,讓乘客在無意識中感受到技術(shù)的可靠性。也只有當系統(tǒng)能像人類一樣從容應(yīng)對不確定性,才能真正贏得用戶的長期信任,推動自動駕駛從功能走向陪伴。
審核編輯 黃宇
-
自動駕駛
+關(guān)注
關(guān)注
793文章
14883瀏覽量
179858
發(fā)布評論請先 登錄
自動駕駛中提到的“深度相機”是個啥?
自動駕駛中常提的“強化學習”是個啥?

自動駕駛中常提的“專家數(shù)據(jù)”是個啥?
自動駕駛中常提的ODD是個啥?
自動駕駛中常提的硬件在環(huán)是個啥?
自動駕駛中常提的RTK是個啥?
自動駕駛中常提的慣性導航系統(tǒng)是個啥?可以不用嗎?
自動駕駛中常提的高精度地圖是個啥?有何審查要求?
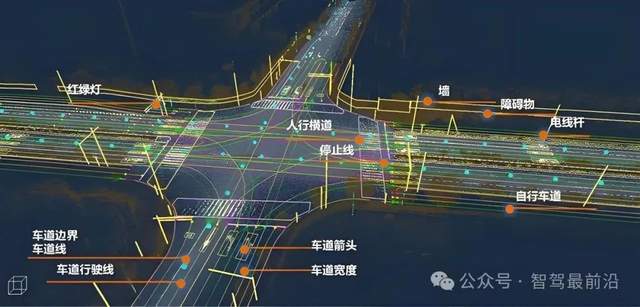
自動駕駛中常提的世界模型是個啥?
自動駕駛中常提的HMI是個啥?
自動駕駛中常提的“點云”是個啥?
自動駕駛行業(yè)常提的高階智駕是個啥?
自動駕駛中常提的“NOA”是個啥?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論