 進迭時空 V8 RISC-V 后端優化
進迭時空 V8 RISC-V 后端優化

前 言
V8 是 Google 開發及開源的 JavaScript 和 WebAssembly 語言編譯引擎,是 Chromium 項目的一部分,主要應用于 Chrome 瀏覽器 和 Node.js 等項目,在瀏覽器生態中發揮著至關重要的作用。自 2020 年起,中科院軟件所 PLCT 實驗室等團隊開始為 V8 引擎開發 RISC-V 后端,并持續推動 V8 對 RISC-V 架構的支持,不斷完善功能完整性,持續優化性能表現。目前,V8 引擎的 RISC-V 后端已經完成了解釋器和 JIT 編譯器的開發,實現了基本功能的完整支持。全球 RISC-V 生態共建者正在積極推動更多高級特性的開發與完善,持續優化 V8 在 RISC-V 平臺上的性能與兼容性。
RISC-V 作為新興的架構,其后端仍有不少優化機會。本文將介紹一些進迭時空在 V8 JavaScript 引擎 RISC-V 后端的優化工作,并說明這些優化如何提升 JavaScript 在 RISC-V 架構上的執行效率和整體性能表現。
R I S C - V 后 端 優 化
Load/Store 地址計算優化
V8 的 LoadStoreSimplificationReducer Pass 會將 LoadOp(Load Operation)和 StoreOp(Store Operation)的地址計算規約為 Base + Index 的形式,Base 表示基地址,Index 表示索引偏移,比如指令 ld t3, 8(t1) 中 Base 為 t1,Index 為 8,加載地址為 t1 + 8。
·使用 Shift And Add 指令計算 Base
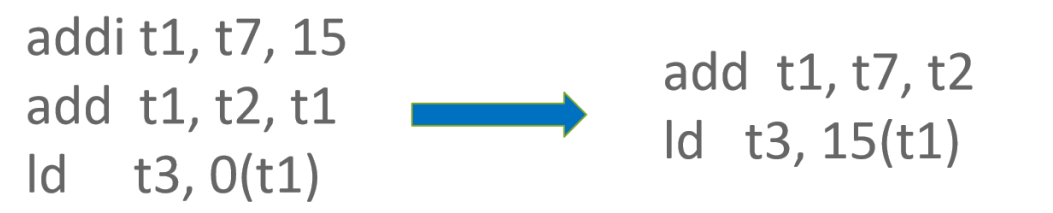
RISC-V Zba Extension 提供了 shift and add 系列指令來快速完成地址計算,使用該系列指令可在地址計算過程省去 1 條指令。以如下代碼為例,在計算 Base 過程中使用了 slli + add 來完成對 Base 的計算,可被 shift and add 指令替換。

·Index 立即數參數融合進 Load/Store 指令
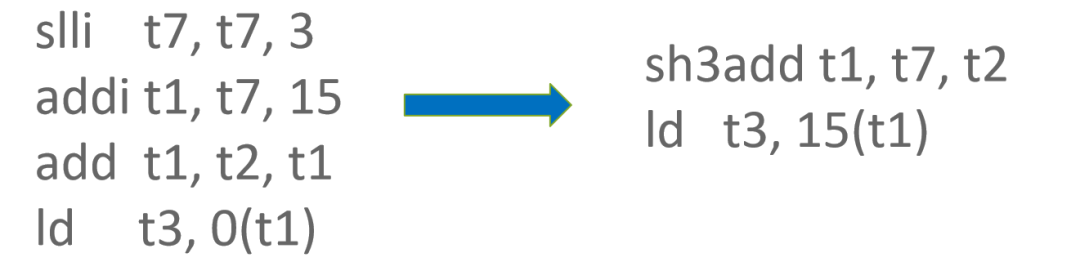
有時候 Index 并不一定是立即數,而是一個通過 WordBinopOp::Add 節點計算得到的寄存器值,并且該 WordBinopOp::Add 節點的參數中存在符合 RISC-V Load/Store 指令索引偏移范圍 [-2048, 2047] 的立即數,則可以將 Index 中的立即數參數融合進 Load/Store 指令中,從而節省 1 條指令。
更進一步地,如果上述兩種優化方法的條件都符合,則可以同時使用兩種優化方法,從而節省 2 條指令。
Comparison + Branch 優化
Comparison + Branch 一般位于 BasicBlock 結束處,用于條件分支跳轉。
MERGEB3<-?B2,B1? 21:Phi(#16,#19)[Tagged]? 22:Constant()[heap?object:?0x00ec00000011?? 23:Comparison(#4,#22)[Equal, Tagged]? 24:Branch(#23)[B319,B4,False]
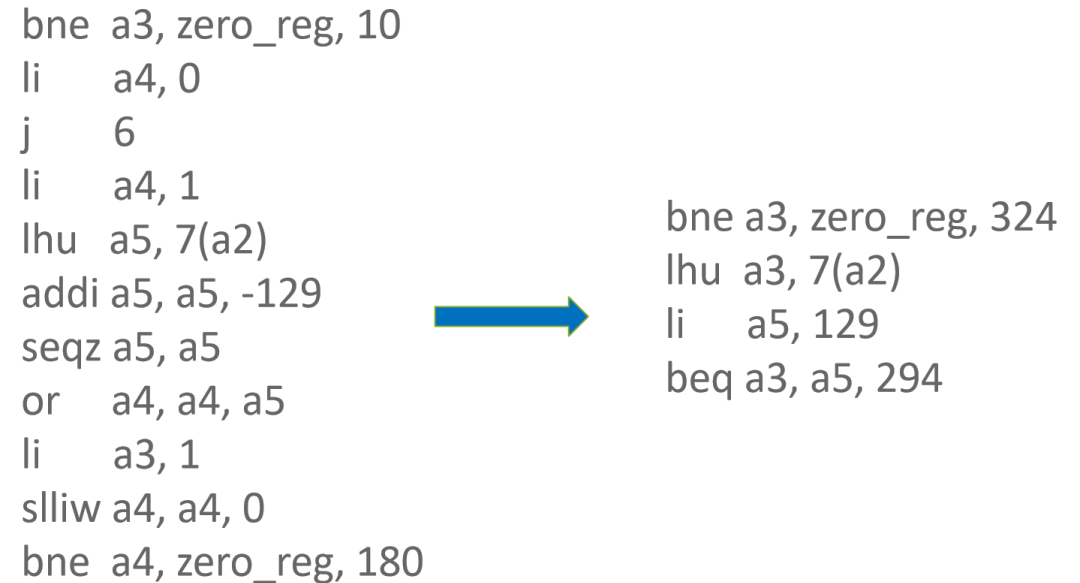
如果 ComparisonOp 的 RegisterRepresentation 是 Tagged 類型,則可以將 Tagged 類型映射為 Word32 或者 Word64 類型,如此便可在對 Branch 節點做指令選擇時,選擇 kRiscvCmp 虛擬指令而不是選擇 kRiscvCmpZero 虛擬指令,同時會將 ComparisonOp 的參數和 FlagsCondition(表示判斷條件)融合進 kRiscvCmp 虛擬指令中。因此 ComparisonOp 節點計算結果不再被直接使用,所以不會對 ComparisonOp 生成指令,從而達到節省指令的目的。
原來使用 kRiscvCmpZero 節點時,需要使用 xor + slt 指令來計算 ComparisonOp 的結果然后再傳給 Branch 指令。切換為 kRiscvCmp 節點后,可以將 ComparisonOp 操作融合進 Branch 指令中,從而省去 xor 和 slt 指令。

Load + ChangeUint32ToUint64 優化
在 Load + ChangeUint32ToUint64 匹配模式下,ChangeUint32ToUint64 用于將 LoadOp 加載出來的 uint32 類型數據轉化為 uint64 類型。
但當 LoadOp 需要加載的數據其符號類型為 unsigned,MachineRepresentation 類型為 Word32 時,會選擇 lwu 指令來進行加載,該指令加載數據時自身會進行零擴展,故不需要再額外使用 zext.w 指令來進行零擴展,從而省去 zext.w 指令。

IsNumeric 優化
IsNumeric(value) 用于判斷給定的 JavaScript 值是否是一個 Number 類型或 BigInt 類型:
Number:表示浮點數和整數(如 42,3.14)
BigInt:表示任意精度的大整數(如 123456789012345678901234567890n)
在 IsNumberic 函數實現中,需要對 IsHeapNumber 和 IsBigInt 函數返回值進行 or 運算,而因為 IsBigInt 函數需要數條指令完成,所以如果 IsHeapNumber 返回值為 1,則兩者 or 運算的結果可以直接用 1 來表示,避免通過 IsBigInt 函數引入較多的指令。
同理,IsSharedStringInstanceType 函數也可以照此修改優化。
DecompressTagged 優化
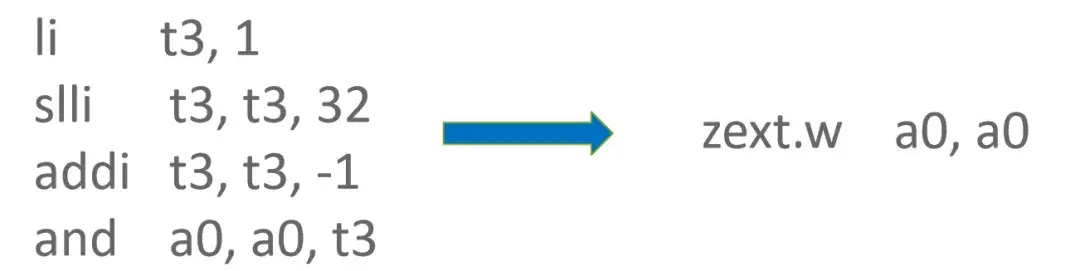
RISC-V Zba Extension 中提供了 zext.w 偽指令可用于零擴展。當使能 V8 Compress pointer 機制時,需要通過DecompressTagged 函數對 Tagged 類型數據進行解壓縮。DecompressTagged 函數實現中,存在對 source register 上的數據執行 And 0xFFFFFFFF 的操作,而 0xFFFFFFFF 需要使用 3 條 RISC-V 基礎指令來構造。當存在 RISC-V Zba Extension 時,可以使用 zext.w 指令來替換 And 0xFFFFFFFF 操作,從而節省 3 條指令。
AssembleReturn 優化
V8 中 AssembleReturn 用于對 ArchRet 節點生成指令,當符合下列條件時:
frame_access_state()->has_frame(),即表示當前是否正在使用棧幀。
call_descriptor->IsJSFunctionCall(),即表示當前是否為 JavaScript 函數調用。
parameter_slots != 0,即表示當前被調用函數的函數定義中參數數量不為 0
則需要將 JavaScript 函數參數從棧幀中移出。因實際傳入參數的數量和函數定義中參數的數量不一定相同,因此需要取兩者之中較大值來進行棧幀調整。
RISC-V Zbb Extension 提供了 max 指令來獲取兩個參數的較大值,既減少 1 條指令,又能避免產生分支指令導致分支預測失敗時需要清空流水線。
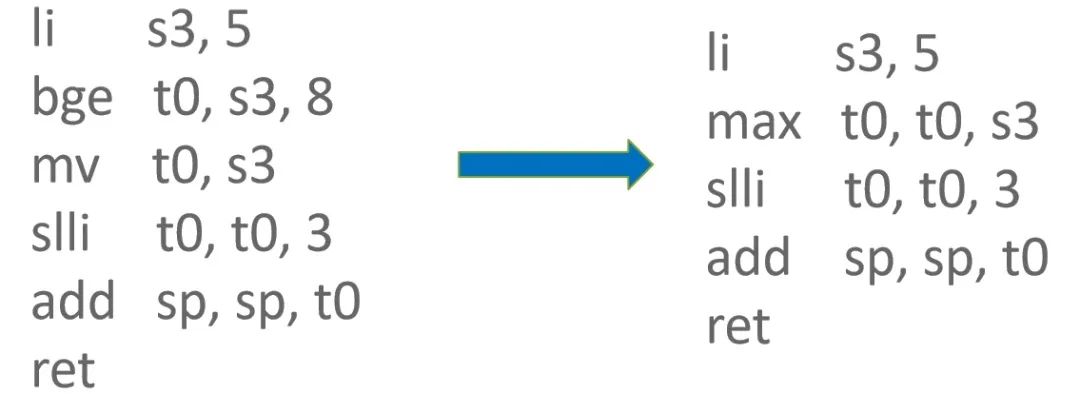
TaggedIsSmi 優化
在 V8 中,為了提高性能和減少內存使用,小整數被直接編碼到 Tagged 類型值中,這種編碼方式使得小整數無需分配額外的內存即可存儲,并且可以直接在寄存器中傳遞,從而提高了運算速度。
TaggedIsSmi 函數用于判斷 Tagged 類型值是否為 Smi(Small Integer)數據,在 V8 中屬于高頻使用函數。對于 Smi 類型,最低位通常設置為 0;而對于指向堆對象的 Tagged 類型值,最低位則設置為 1。TaggedIsSmi 源碼如下:
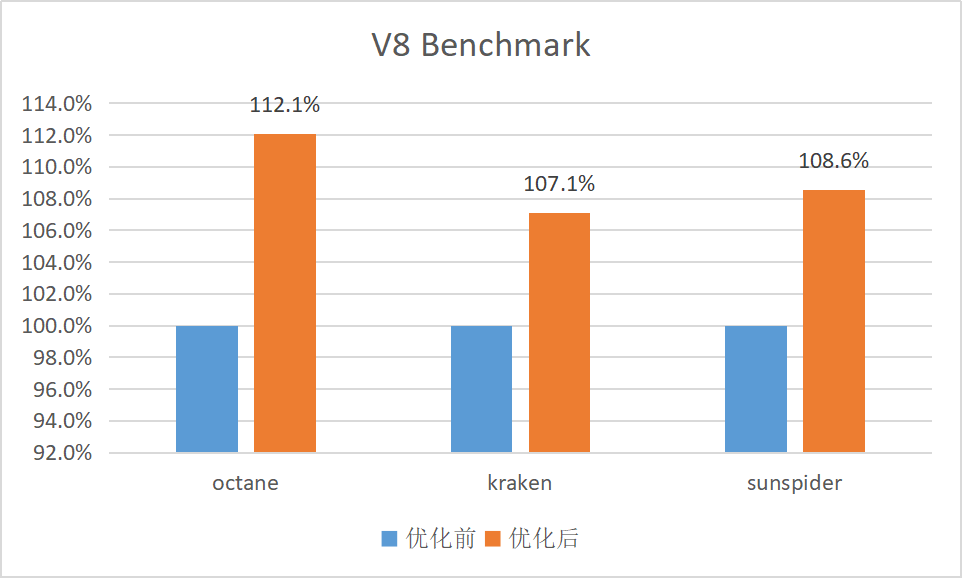
TNode 對應的 IR 節點則如下圖所示: 25:TaggedBitcast(#0)[Compressed, Word32, TagAndsmiBits]26:Constant()[word32:1]27:Change(#25)[Truncate, NoAssumption, Word64, Word32]28:WordBinop(#27,#26)[BitwiseAnd,Word32]29:Branch(#28)[B5,B4,None] 此處的 BitwiseAnd 運算是與常數 1 進行 And 運算,必然是在 Word32 數據表示范圍內,故并不需要進行擴展操作。經過優化后,TaggedIsSmi 函數生成的指令序列可節省 2 條指令。 SwitchTable 二分查找優化 AssembleArchBinarySearchSwitch 是用于為 switch-case 語句(特別是 case 值為整數時)生成高效匯編代碼的方法。它通過使用二分查找算法來優化 switch-case 結構的執行效率,從而減少條件分支的數量,提高性能。當使能 Compress pointer 時,會在二分查找比較時將輸入值進行符號擴展操作,然而實際上,輸入值在整個二分查找階段并不會發生變化,可以對其做循環不變量提升,減少符號擴展操作的數量。 CompareTaggedAndBranch 優化 CompareTaggedAndBranch 是用于比較兩個值,并根據比較結果執行條件跳轉的函數。當使能 Compress pointer 時,兩個值需要進行符號擴展之后才能比較。但是如果一個參數為立即數并在 [0, 0x7FFFFFFF] 范圍內,實際上并不需要進行符號擴展。 性 能 測 試 經過進迭時空的多項優化,包括但不限于上述改進,V8 基準性能測試的各項指標均取得了不同程度的提升。 結 束 語 秉承著以 RISC-V 架構數智未來的使命,進迭時空將持續關注和支持 RISC-V 生態的發展,下一步會陸續將優化成果向 V8 開源社區貢獻,并與開源社區伙伴一起繼續努力,共建 RISC-V 生態。


-
開源
+關注
關注
3文章
4290瀏覽量
46360 -
RISC-V
+關注
關注
49文章
2927瀏覽量
53412 -
進迭時空
+關注
關注
0文章
63瀏覽量
606
發布評論請先 登錄
Canonical 與進迭時空攜手:Ubuntu 全面支持 K3/K1 RISC-V AI CPU 計算平臺

Vol.4 | 進迭時空孫彥邦:RISC-V的答案,不是篩選“幸存者”,而是集結“共建者”

進迭播客 | Vol.3對話孫彥邦:用胡子賭一個未來,RISC-V是AI時代的“終極答案”

進迭時空參加2025 RISC-V北美峰會,披露第二代RISC-V AI CPU芯片 K3 進展


10萬獎金池,等你挑戰!CIE全國RISC-V創新應用大賽火熱報名中

進迭時空與青少年共赴RISC-V AI科技未來!
2025RISC-V中國峰會|進迭時空RISC-V AI CPU驅動智能化應用發展
迎接泛機器人時代:進迭時空如何以RISC-V架構數智未來
RISC-V架構下的編譯器自動向量化
進迭時空攜手珠海共建RISC-V生態應用中心
高校賽事 | 進迭時空攜手藍橋杯,誠邀全國高校學子共啟RISC-V人工智能應用創新賽道
大象機器人攜手進迭時空推出 RISC-V 全棧開源六軸機械臂產品
大象機器人×進迭時空聯合發布全球首款RISC-V全棧開源小六軸機械臂




 工商網監
工商網監
評論