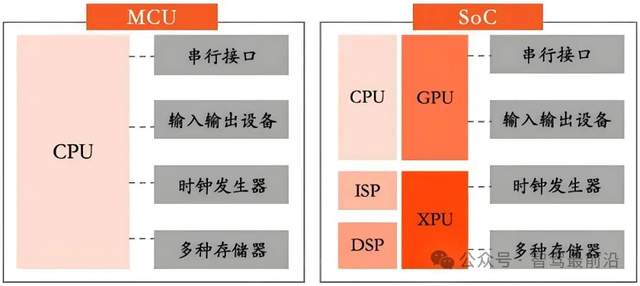
 車載計算平臺SoC:采用CPU+GPU+NPU+MCU+VPU異構設計
車載計算平臺SoC:采用CPU+GPU+NPU+MCU+VPU異構設計

電子發燒友網報道(文/李彎彎)車載計算平臺是智能網聯汽車的核心部件,承擔著車輛感知、決策、控制等關鍵任務,相當于汽車的“大腦”。隨著汽車智能化和自動駕駛技術的發展,車載計算平臺的重要性日益凸顯,其性能直接決定了自動駕駛的等級和安全性。
車載計算平臺的核心功能:感知與融合,通過攝像頭、激光雷達、毫米波雷達、超聲波雷達等傳感器獲取環境信息,并對多源數據進行融合處理,實現對車輛周圍環境的精準感知;決策與規劃,基于感知數據,進行路徑規劃、行為決策(如變道、超車、避障等),并生成控制指令;控制與執行,將決策結果轉化為具體的控制信號,控制車輛的轉向、加速、制動等執行機構,實現自動駕駛功能;通信與網聯,支持車與車(V2V)、車與基礎設施(V2I)、車與云端(V2C)的通信,實現信息共享和協同控制。
車載計算平臺的技術架構——硬件和軟件
車載計算平臺的硬件架構需滿足高算力、低功耗和冗余安全的需求,通常采用異構計算單元和高帶寬通信的組合。
異構計算單元包括CPU、GPU、FPGA、ASIC、NPU等。CPU,負責通用計算任務,如系統調度、通信協議處理等。通常采用多核ARM架構(如高通驍龍、瑞薩R-Car),兼顧性能與功耗。GPU,擅長并行計算,加速深度學習模型推理(如目標檢測、語義分割),NVIDIA Orin、特斯拉FSD等芯片集成高性能GPU。
FPGA,可編程硬件,靈活適配算法優化,常用于傳感器數據預處理或低延遲任務。ASIC,針對特定算法(如Transformer模型)定制化設計,提供極致能效比(如特斯拉FSD芯片)。NPU,專為AI計算優化,支持高吞吐量的矩陣運算,是當前主流AI芯片的核心組件。
高帶寬通信包括車載以太網、PCIe接口、TSN(時間敏感網絡)等。車載以太網,支持1Gbps甚至10Gbps傳輸速率,替代傳統CAN總線,滿足傳感器數據的實時傳輸需求。PCIe接口,連接GPU、FPGA等加速卡,提供低延遲、高帶寬的擴展能力。TSN(時間敏感網絡),確保關鍵任務(如制動控制)的確定性時延,避免網絡擁塞導致的安全隱患。
冗余與安全設計,如雙系統冗余、硬件安全模塊(HSM)、隔離設計等。雙系統冗余,主計算單元與備份單元并行運行,故障時無縫切換(如英偉達DRIVE AGX Orin支持雙Orin芯片冗余)。硬件安全模塊(HSM),獨立芯片存儲密鑰和加密算法,防止數據篡改或惡意攻擊。隔離設計,通過虛擬化技術將安全關鍵任務與非關鍵任務隔離。
軟件架構需支持多任務并行、低延遲通信和持續迭代,通常采用分層解耦的設計模式。
操作系統層,如實時操作系統(RTOS)、通用操作系統(GPOS)、混合架構。實時操作系統(RTOS),如QNX、VxWorks,用于安全關鍵任務(如剎車控制),確保毫秒級響應。通用操作系統(GPOS),如Linux、Android,用于非關鍵任務(如導航、娛樂),支持豐富的應用生態。混合架構,通過Hypervisor(如ACRN、KVM)實現RTOS與GPOS的協同運行,兼顧安全與靈活性。
中間件層,包括通信中間件、調度中間件、安全中間件。通信中間件,如SOME/IP、DDS,支持服務發現、數據分發和QoS控制,實現模塊間高效通信。調度中間件,如AUTOSAR Adaptive Platform,動態分配計算資源,優化任務時序。安全中間件,集成加密庫、入侵檢測系統(IDS),保障數據傳輸和存儲安全。
應用算法層,如感知算法、決策算法、控制算法。感知算法,包括攝像頭視覺處理(如YOLO、Faster R-CNN)、激光雷達點云分割(如PointPillars)、多傳感器融合(如卡爾曼濾波)。決策算法,基于規則的決策樹(如有限狀態機FSM)或基于學習的強化學習(如DQN),生成行駛策略。控制算法。模型預測控制(MPC)、PID控制等,將決策轉化為具體的車輛控制指令。
典型技術架構,以NVIDIA DRIVE AGX為例。硬件:雙Orin芯片(算力508TOPS),集成Ampere架構GPU、Arm Cortex-A78AE CPU、深度學習加速器(DLA)。軟件:底層是Linux + 安全內核(符合ISO 26262 ASIL-D);中間件是NVIDIA DRIVE OS(集成CUDA、TensorRT);應用層是DRIVE AV(自動駕駛)、DRIVE IX(智能座艙)。通信:支持PCIe Gen4、10G以太網、CAN-FD。
車載計算平臺芯片——SoC
目前市面上主要的車載計算平臺SoC芯片有英偉達Orin系列、華為昇騰系列、地平線征程系列、黑芝麻智能華山系列、高通驍龍Ride平臺、特斯拉FSD芯片等。
英偉達Orin系列,單顆芯片算力可達254TOPS,多顆組合可支持更高算力需求,如蔚來ET7和威馬M7搭載4顆Orin芯片,巔峰算力超過1000TOPS。其采用“CPU+GPU+ASIC”架構,適用于L3或L4級自動駕駛。
華為昇騰系列,包括昇騰310、昇騰610等,具有強大的AI計算能力,功能安全等級達到ASIL-D。昇騰610芯片在CPU、CV處理能力及內存帶寬方面業界領先,適用于自動駕駛應用負載。
地平線征程系列,包括征程2、征程3、征程5、征程6等,算力不斷提升,滿足不同等級自動駕駛需求。2025年4月18日,地平線征程6系列的旗艦產品征程6P(J6P)、征程6H(J6H)正式亮相,同時,基于J6P芯片和地平線自研端到端算法的軟硬一體全棧方案HSD(Horizon Super Driving)也一并推出,具備L2城區輔助駕駛能力。
J6P基于地平線最新的BPU“納什”架構,采用CPU+GPU+NPU+MCU+VPU的異構設計,具備三級存儲架構和數據變換引擎,專為Transformer、BEV等大模型優化。
黑芝麻智能華山系列,包括A500、A1000L、A1000、A1000 Pro以及A2000家族。基于A1000芯片,可提供單顆、雙顆、四顆芯片的組合方案,算力覆蓋從ADAS輔助駕駛到L4及以上自動駕駛需求。
2024年12月30日,黑芝麻智能宣布推出其專為下一代AI模型設計的高算力芯片平臺——華山A2000家族,包括A2000 Lite、A2000和A2000 Pro三款產品,分別針對不同等級的自動駕駛需求。A2000 Lite專注于城市智駕,A2000支持全場景通識智駕,而A2000 Pro則是為高階全場景通識智駕設計。
A2000家族的芯片集成了業界領先的CPU、DSP、GPU、NPU、MCU、ISP和CV等多功能單元,實現了高度集成化和單芯片多任務處理的能力。新一代ISP技術,具備4幀曝光和150dB HDR,在隧道和夜間等場景下表現更好,顯著提升了圖像處理能力。A2000家族算力最大是當前主流旗艦芯片的4倍,原生支持Transformer模型。
高通驍龍Ride平臺,巔峰算力預計在700-760TOPS,采用“CPU+GPU+ASIC”架構,為自動駕駛、ADAS、車載信息娛樂系統等領域提供強大的計算能力。
Mobileye EyeQ系列,如EyeQ6 Ultra,算力達到176TOPS,采用“CPU+ASIC”架構,為高階自動駕駛提供支持。不過,Mobileye在市場競爭中逐漸掉隊。
特斯拉FSD芯片,以NPU(ASIC)為計算核心,有三個主要模塊:CPU、GPU和Neural Processing Unit(NPU),總算力達到144TOPS,已廣泛用于特斯拉車型。
寫在最后
車載計算平臺的技術架構是硬件、軟件和系統集成的綜合體現,其核心在于異構計算的高效協同、實時性與安全性的平衡以及全生命周期的可持續性。SoC內部集成多個異構處理單元,結構設計復雜,處理和計算能力強,適用于多任務處理以及計算任務復雜的應用場景。隨著汽車智能化程度的提高,對高性能SoC芯片的需求也將不斷提升。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
soc
+關注
關注
40文章
4576瀏覽量
229127 -
異構設計
+關注
關注
0文章
3瀏覽量
5594
發布評論請先 登錄
相關推薦
熱點推薦
AI硬件全景解析:CPU、GPU、NPU、TPU的差異化之路,一文看懂!?
CPU作為“通用基石”,支撐所有設備的基礎運行;GPU憑借并行算力,成為AI訓練與圖形處理的“主力”;TPU在Google生態中深耕云端大模型訓練;NPU則讓AI從“云端”走向“身邊”(手機、手表

從CPU、GPU到NPU,美格智能持續優化異構算力計算效能
的科技企業也在近期表示,將通過軟件層創新大幅提升算力資源利用率。作為高算力AI模組和端側AI領域的領先企業,美格智能長期專注于端側AI算力的優化與提升,通過深耕SoC架

蜂鳥內核VPU模塊設計分享
本項目在VPU部分添加了一個應用于嵌入式的輕量級向量協處理器,實現了部分的V型計算功能,滿足本情景下的使用要求。VPU和CPU之間有五個接口的數據交互,交互有握手的協議進行控制。接口分
發表于 10-23 06:02
車載360環視平臺:米爾RK3576開發板支持12路低延遲推流
采用 8nm 工藝,搭載 四核 Cortex-A72 + 四核 Cortex-A53,配合 Mali-G52 GPU 與 6TOPS NPU,為車載環視提供充足的算力與擴展空間。12
發表于 10-11 17:55
自動駕駛SoC芯片到底有何優勢?
的需求。于是,SoC(System on Chip,系統級芯片)作為新時代的核心硬件平臺,逐步取代了MCU,成為智能汽車計算的主力。這種芯片集成了C
360環視硬件平臺為什么推薦使用米爾RK3576開發板?
接收端解碼顯示,端到端延遲約 120~150ms(編碼側 80~100ms + 傳輸/解碼 40~50ms),滿足車載與安防對實時性的要求。資源均衡與穩定可靠:RGA、VPU、CPU、GPU
發表于 09-19 17:38
12路1080P高清視頻流,米爾RK3576 開發板賦能車載360環視
在智能視覺技術不斷發展的今天,多路攝像數據的處理與傳輸已成為眾多應用場景的核心需求。從智能安防監控領域的全面覆蓋,到工業視覺處理網關的精準檢測,再到車載環視融合平臺的實時駕駛輔助以及智慧社區AI防
發表于 08-14 14:01
異構計算解決方案(兼容不同硬件架構)
異構計算解決方案通過整合不同類型處理器(如CPU、GPU、NPU、FPGA等),實現硬件資源的高效協同與兼容,滿足多樣化計算需求。其核心技術
如何釋放異構計算的潛能?Imagination與Baya Systems的系統架構實踐啟示
查看完整報告。你是否正在設計多核或CPU/GPU混合系統,卻依然未能達成性能目標?你并不孤單。如今,系統架構師們不斷追求構建更強大的SoC,過于專注于計算能力的“

能效提升3倍!異構計算架構讓AI跑得更快更省電
電子發燒友網報道(文/李彎彎)異構計算架構通過集成多種不同類型的處理單元(如CPU、GPU、NPU、FPGA、DSP等),針對不同計算任務的
定制化SoC陣列設計
異構集成架構? 采用CPU+GPU+NPU+專用加速器的組合模式,支持動態資源分配與硬件虛擬化技術,例如芯原平臺支持多處理器協同工作并可選配ASIL D級功能安全島 模塊化擴展性?

超越CPU/GPU:NPU如何讓AI“輕裝上陣”?
電子發燒友網報道(文/李彎彎)NPU是一種專門為人工智能(AI)計算設計的處理器,主要用于高效執行神經網絡相關的運算(如矩陣乘法、卷積、激活函數等)。相較于傳統CPU/GPU,
RK3588核心板在邊緣AI計算中的顛覆性優勢與場景落地
框架部署需大量手動優化,延誤項目交付。
明遠智睿RK3588核心板的核心優勢
異構計算架構:
采用4×Cortex-A76(2.4GHz)+4×Cortex-A55(1.8GHz)設計,兼顧高性能
發表于 04-15 10:48
AI SoC# 奕斯偉EIC7700 全球首款基于RISC-V架構的邊緣計算SoC芯片
SoC ● 多計算加速單元 :包含NPU/GPU/DSP的CV與AI加速單元,支持多場景計算 ● 低功耗設計 :典型功耗8W(CNN場景)



 工商網監
工商網監
評論