") DeepSeek V3昇思MindSpore版本上線開源社區(qū)
DeepSeek V3昇思MindSpore版本上線開源社區(qū)

近日,基于昇騰AI硬件與昇思MindSpore AI框架版本的DeepSeek-V3完成開發(fā)支持并上線昇思開源社區(qū),面向開發(fā)者提供開箱即用的預(yù)訓(xùn)練和推理能力,并已成功在大規(guī)模集群上預(yù)訓(xùn)練和部署。
應(yīng)用昇思MindSpore大模型使能套件,依托昇思多維混合分布式能力、自動(dòng)并行、Dryrun集群內(nèi)存仿真等技術(shù),天級(jí)快速適配DeepSeek V3新增模型結(jié)構(gòu)和分布式并行訓(xùn)練能力。同時(shí),昇思MindSpore通過深度優(yōu)化MLA、DeepSeekMoE等網(wǎng)絡(luò)結(jié)構(gòu)的推理,實(shí)現(xiàn)了高效的推理部署性能。
當(dāng)前,通過獲取昇思MindSpore版DeepSeek V3開源鏡像,開發(fā)者可直接進(jìn)行DeepSeek-V3的預(yù)訓(xùn)練和推理部署。
開源鏈接
昇思MindSpore開源社區(qū)訓(xùn)練代碼:
https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
魔樂社區(qū)推理代碼:
https://modelers.cn/models/MindSpore-Lab/DeepSeek-V3
以下是完整的手把手教程,助力開發(fā)者開箱即用
預(yù)訓(xùn)練開箱流程
MindSpore Transformers支持對(duì)DeepSeek-V3進(jìn)行預(yù)訓(xùn)練。倉庫中提供了一份預(yù)訓(xùn)練配置文件供參考,該配置基于128臺(tái)Atlas 800T A2 (64G),使用Wikitext-2數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,可參考多機(jī)教程進(jìn)行使用:
https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
便于開發(fā)者上手體驗(yàn),本章節(jié)基于此配置進(jìn)行修改,縮小了DeepSeek-V3模型參數(shù)量,使其能夠在單臺(tái)Atlas 800T A2 (64G)上拉起預(yù)訓(xùn)練流程。
01環(huán)境介紹
準(zhǔn)備一臺(tái)Atlas 800T A2 (64G)訓(xùn)練服務(wù)器。MindSpore Transformers的環(huán)境依賴如下:

提供了DeepSeek-V3預(yù)訓(xùn)練專用Docker鏡像,通過如下步驟進(jìn)行使用。
1、下載Docker鏡像
使用如下命令下載DeepSeek-V3預(yù)訓(xùn)練專用鏡像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.4.10-train:20250209
2、基于鏡像創(chuàng)建容器
使用如下命令新建容器:
image_name=swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.4.10-train:20250209 docker_name=deepseek_v3 docker run -itd -u root --ipc=host --net=host --privileged --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /etc/localtime:/etc/localtime -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/bin/hccn_tool -v /etc/ascend_install.info:/etc/ascend_install.info -v /var/log85npu-smi:/usr/local/bin/npu-smi -v /etc/hccn.conf:/etc/hccn.conf --name "$docker_name" "$image_name" /bin/bash
3、進(jìn)入容器
使用如下命令進(jìn)入容器,并進(jìn)入代碼目錄:
docker exec -ti deepseek_v3 bash cd /home/work/mindformers
02數(shù)據(jù)集準(zhǔn)備
以Wikitext-2數(shù)據(jù)集為例,參考如下步驟將數(shù)據(jù)集處理成Megatron BIN格式文件。
1、下載數(shù)據(jù)集和分詞模型文件
o數(shù)據(jù)集下載:WikiText2數(shù)據(jù)集
(https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/dataset/wikitext-2/wikitext-2-v1.zip)
o分詞模型下載:DeepSeek-V3的tokenizer.json(https://huggingface.co/deepseek-ai/DeepSeek-V3/resolve/main/tokenizer.json?download=true)
2、生成Megatron BIN格式文件
將數(shù)據(jù)集文件wiki.train.tokens和分詞模型文件tokenizer.json放置在/home/work/dataset下。
使用以下命令將數(shù)據(jù)集文件轉(zhuǎn)換為
cd /home/work/mindformers/research/deepseek3 python wikitext_to_bin.py --input /home/work/dataset/wiki.train.tokens --output-prefix /home/work/dataset/wiki_4096 --vocab-file /home/work/dataset/tokenizer.json --seq-length 4096 --worker1
03單機(jī)配置樣例
基于預(yù)訓(xùn)練配置文件pretrain_deepseek3_671b.yaml按照如下步驟操作并保存為pretrain_deepseek3_1b.yaml。
1、修改模型配置
# model config model: model_config: type: DeepseekV3Config auto_register: deepseek3_config.DeepseekV3Config seq_length: 4096 hidden_size: 2048 # 修改為2048 num_layers: &num_layers 3 # 修改為3 num_heads: 8 # 修改為8 max_position_embeddings: 4096 intermediate_size: 6144 # 修改為6144 offset: 0 # 修改為0 ……
2、修改MoE配置
提供了DeepSeek-V3預(yù)訓(xùn)練專用Docker鏡像,通過如下步驟進(jìn)行使用。
#moe moe_config: expert_num: &expert_num 16 # 修改為16 first_k_dense_replace:1#修改為1 ……
3、修改并行配置
# parallel config for devices num=8 parallel_config: data_parallel: 2 # 修改為2 model_parallel: 2 # 修改為2 pipeline_stage: 2 # 修改為2 expert_parallel: 2 # 修改為2 micro_batch_num: µ_batch_num 4 # 修改為4 parallel: parallel_optimizer_config: optimizer_weight_shard_size: 8 # 修改為8 ……
4、修改學(xué)習(xí)率配置
# lr schedule lr_schedule: type: ConstantWarmUpLR warmup_steps: 20 # 修改為20
5、修改數(shù)據(jù)集配置
配置數(shù)據(jù)集路徑:
# dataset
train_dataset: &train_dataset
data_loader:
type: BlendedMegatronDatasetDataLoader
config:
data_path:
- 1
- "/home/work/dataset/wiki_4096_text_document" # 修改此項(xiàng)為數(shù)據(jù)集路徑
……
配置數(shù)據(jù)集并行通信配置路徑:
# mindspore context init config
context:
ascend_config:
parallel_speed_up_json_path: "/home/work/mindformers/research/deepseek3/parallel_speed_up.json" # 修改此項(xiàng)為數(shù)據(jù)集并行通信配置路徑
04
拉起任務(wù)
進(jìn)入代碼根目錄并執(zhí)行以下命令拉起單臺(tái)Atlas 800T A2(64G)預(yù)訓(xùn)練任務(wù):
cd /home/work/mindformers bash scripts/msrun_launcher.sh "run_mindformer.py --register_path research/deepseek3 --configresearch/deepseek3/deepseek3_671b/pretrain_deepseek3_1b.yaml"
啟動(dòng)腳本執(zhí)行完畢會(huì)在后臺(tái)拉起任務(wù),日志保存在/home/work/mindformers/output/msrun_log下,使用以下命令查看訓(xùn)練日志(由于開啟了流水并行pipeline_stage: 2,loss只顯示在最后一張卡的日志worker_7.log中,其他日志顯示loss為0):
tail -f /home/work/mindformers/output/msrun_log/worker_7.log
訓(xùn)練loss的曲線圖如下:
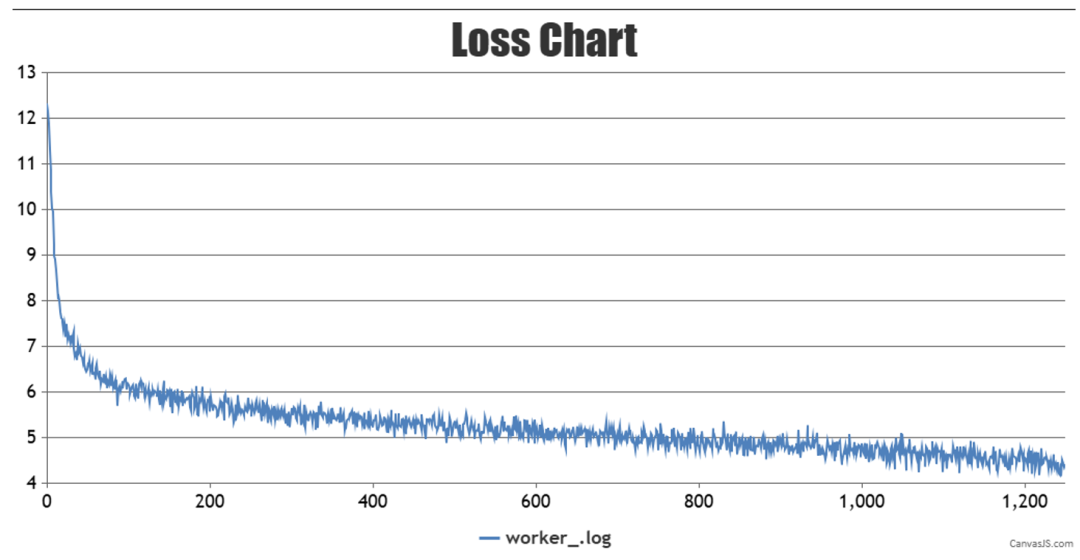
訓(xùn)練過程中的權(quán)重checkpoint將會(huì)保存在/home/work/mindformers/output/checkpoint下。
推理部署開箱流程
采用BF16格式的模型權(quán)重文件,運(yùn)行DeepSeek-V3推理服務(wù),需要4臺(tái)Atlas 800I A2(64G)服務(wù)器。為縮短開發(fā)部署周期,昇思MindSpore此次提供了docker容器鏡像,供開發(fā)者快速體驗(yàn)。其主要操作步驟如下:
執(zhí)行以下Shell命令,下載昇思MindSpore DeepSeek-V3推理容器鏡像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.5.0-infer:20250209
執(zhí)行以下Shell命令,啟動(dòng)容器鏡像,后續(xù)操作將均在容器內(nèi)進(jìn)行:
docker run -itd --privileged --name=deepseek-v3 --net=host --shm-size 500g --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/hisi_hdc --device /dev/devmm_svm -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi -v /usr/local/sbin:/usr/local/sbin -v /etc/hccn.conf:/etc/hccn.conf deepseek_v3_mindspore2.5.0-infer:20250209 bash
執(zhí)行以下Shell命令,將用于下載存儲(chǔ)DeepSeek-V3權(quán)重文件的路徑(開箱示例中為./model_path),添加至白名單:
export HUB_WHITE_LIST_PATHS=./model_path
使用以下Python腳本,從魔樂社區(qū)下載昇思MindSpore版本的DeepSeek-V3權(quán)重文件至指定路徑。完整的權(quán)重文件約1.4TB,請(qǐng)確保指定路徑下有充足的可用磁盤空間:
from openmind_hub import snapshot_download snapshot_download( repo_id="MindSpore-Lab/DeepSeek-V3", local_dir="./model_path", local_dir_use_symlink=False )
將./model_path/examples/predict_deepseek3_671B.yaml文件中的load_checkpoint參數(shù)配置為權(quán)重文件夾絕對(duì)路徑,并將tokenizer_file參數(shù)和vocab_file參數(shù)配置為tokenizer.json文件絕對(duì)路徑。
在第1臺(tái)至第4臺(tái)服務(wù)器上,分別執(zhí)行以下Shell命令,通過msrun_launcher.sh啟動(dòng)單次推理測試腳本run_deepseekv3_predict.py,完成后將顯示“生抽和老抽的區(qū)別是什么?”的問題回復(fù)。其中,master_ip需修改設(shè)置為第1臺(tái)服務(wù)器的實(shí)際IP地址。
# 第1臺(tái)服務(wù)器(Node 0) export PYTHONPATH=/root/mindformers/:$PYTHONPATH export HCCL_OP_EXPANSION_MODE=AIV export MS_ENABLE_LCCL=off master_ip=192.168.1.1 cd model_path/DeepSeek-V3/examples bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 0 output/msrun_log False 300 # 第2臺(tái)服務(wù)器(Node 1) export PYTHONPATH=/root/mindformers/:$PYTHONPATH export HCCL_OP_EXPANSION_MODE=AIV export MS_ENABLE_LCCL=off master_ip=192.168.1.1 cd model_path/DeepSeek-V3/examples bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 1 output/msrun_log False 300 # 第3臺(tái)服務(wù)器(Node 2) export PYTHONPATH=/root/mindformers/:$PYTHONPATH export HCCL_OP_EXPANSION_MODE=AIV export MS_ENABLE_LCCL=off master_ip=192.168.1.1 cd model_path/DeepSeek-V3/examples bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 2 output/msrun_log False 300 # 第4臺(tái)服務(wù)器(Node 3) export PYTHONPATH=/root/mindformers/:$PYTHONPATH export HCCL_OP_EXPANSION_MODE=AIV export MS_ENABLE_LCCL=off master_ip=192.168.1.1 cd model_path/DeepSeek-V3/examples bash msrun_launcher.sh "run_deepseekv3_predict.py" 32 8 $master_ip 8888 3 output/msrun_log False 300
此外,還可參考魔樂社區(qū)MindSpore-Lab/DeepSeek-V3模型倉的ReadMe指引,進(jìn)行推理服務(wù)化部署,然后通過訪問與OpenAI兼容的RESTful服務(wù)端口,體驗(yàn)多輪對(duì)話服務(wù)。
MindSpore支持DeepSeek V3增量模塊的快速開發(fā)
DeepSeek V3的關(guān)鍵網(wǎng)絡(luò)結(jié)構(gòu)的支持:
MTP:在MTP模塊中,MindSpore通過shard()接口對(duì)MTP入口處的激活融合結(jié)構(gòu)配置了序列并行,消除不必要的通訊重排。通過set_pipeline_stage()接口實(shí)現(xiàn)了embedding矩陣在first_stage 和last_stage間的參數(shù)共享,即由first_stage負(fù)責(zé)維護(hù)embedding的參數(shù)更新,訓(xùn)練前向時(shí)發(fā)送給last_stage,訓(xùn)練反向時(shí)從last_stage回收梯度。
AuxFree Balance:MindSpore的MoE模塊中已支持全局的Expert負(fù)載統(tǒng)計(jì), AuxFree Balance機(jī)制的實(shí)現(xiàn)是在callback中新增了根據(jù)全局專家負(fù)載而更新專家偏置的邏輯,從而達(dá)到在每個(gè)train step結(jié)束后做一次負(fù)載均衡調(diào)整的目的。
MoE Sigmoid激活:在Router score后的激活函數(shù)部分新增了可配置項(xiàng),用戶可以通過yaml文件靈活選擇softmax或sigmoid作為激活函數(shù),支持開發(fā)者靈活選擇。
MindSpore對(duì)于DeepSeek V3推理網(wǎng)絡(luò)的實(shí)現(xiàn)和優(yōu)化
MindSpore針對(duì)DeepSeek V3的網(wǎng)絡(luò)結(jié)構(gòu)特點(diǎn),高效地實(shí)現(xiàn)和優(yōu)化了更高效的推理網(wǎng)絡(luò),最大化地壓縮算子下發(fā)耗時(shí)和提升網(wǎng)絡(luò)推理性能。
MLA:將FC、MatMul等超過10個(gè)小算子,融合成單個(gè)InferAttention-MLA算子,然后將其與已有的PageAttention算子,組合實(shí)現(xiàn)MLA模塊功能。同時(shí),在InferAttention-MLA算子內(nèi),設(shè)計(jì)了Key-Value張量存儲(chǔ)復(fù)用機(jī)制,減少存儲(chǔ)資源占用。
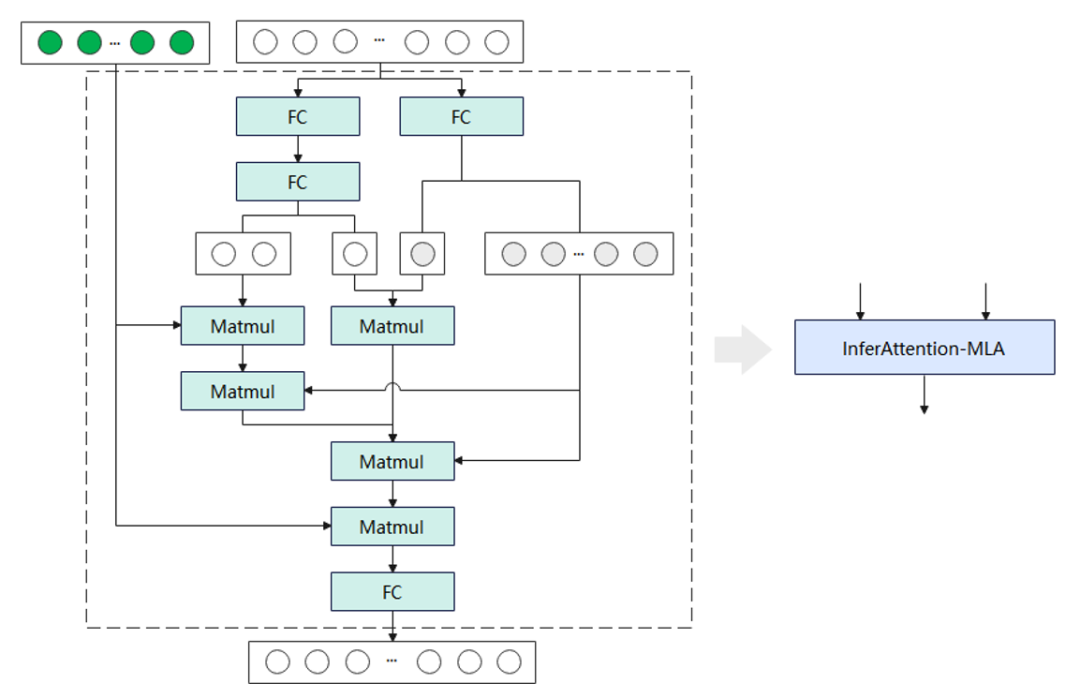
圖1 MLA推理網(wǎng)絡(luò)實(shí)現(xiàn)原理
DeepSeekMoE:MindSpore優(yōu)化精簡了MoE的推理代碼實(shí)現(xiàn),并新增實(shí)現(xiàn)MoeUnpermuteToken、MoeInitRouting等多個(gè)融合大算子,用于組合實(shí)現(xiàn)DeepSeek-V3的MoE單元,降低了單個(gè)MoE單元的推理時(shí)延。
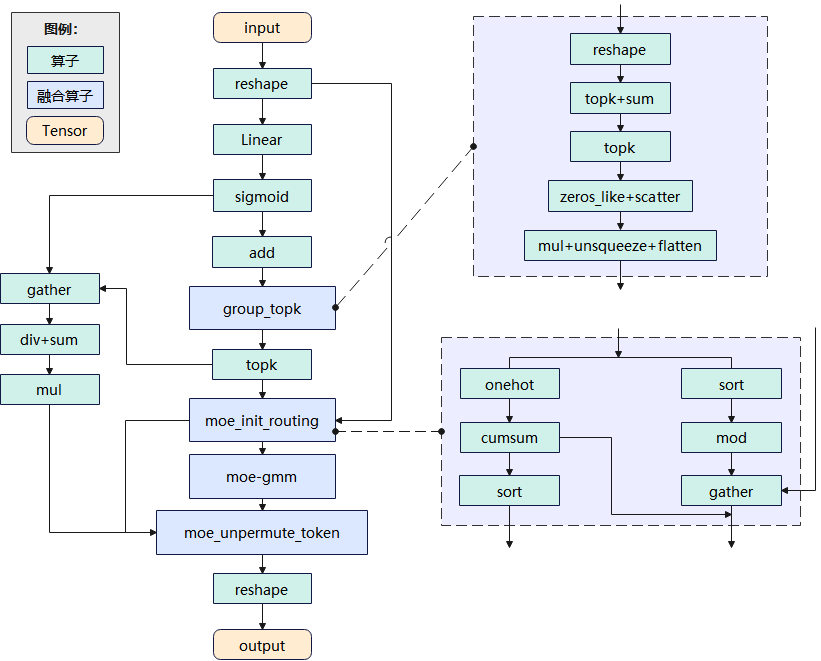
圖2 DeepSeekMoE推理網(wǎng)絡(luò)實(shí)現(xiàn)原理
圖編譯:MindSpore推理使用了圖編譯進(jìn)行加速,通過對(duì)整圖進(jìn)行Pattern匹配,無需修改模型腳本,即可實(shí)現(xiàn)整圖的通用融合。以DeepSeekV3為例,在圖編譯過程中實(shí)現(xiàn)了Add+RmsNorm、SplitWithSize+SiLU+Mul等眾多Pattern的自動(dòng)融合。
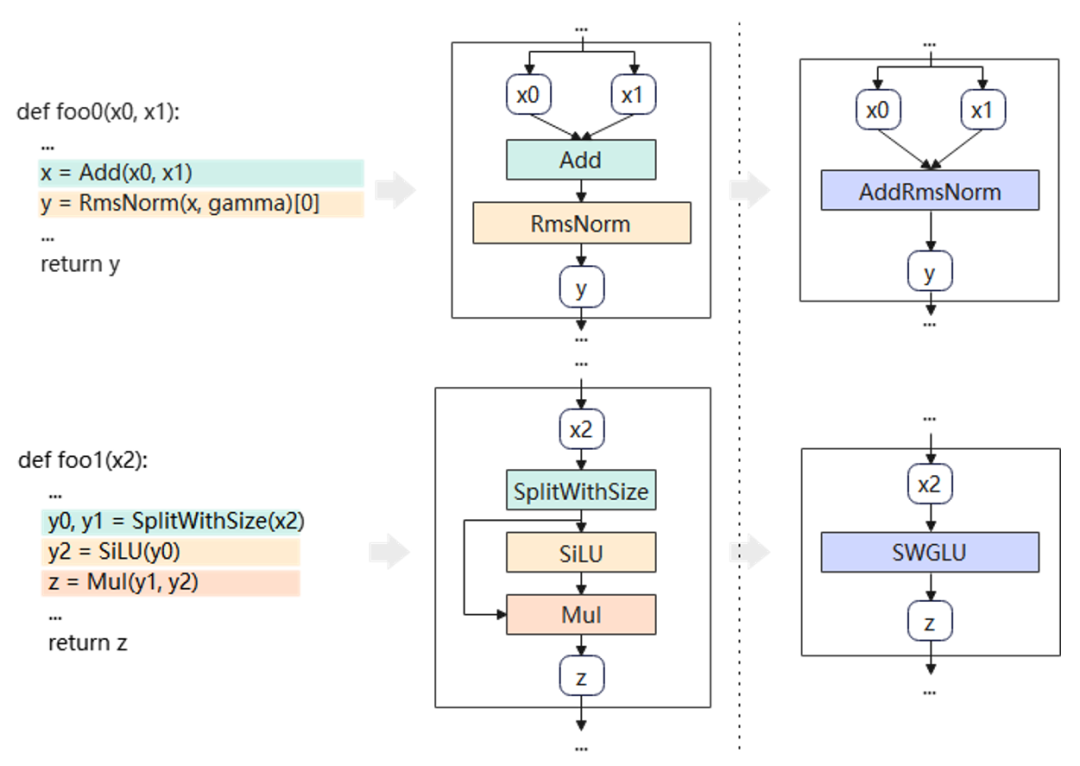 圖3 圖編譯原理
圖3 圖編譯原理
MindSpore框架特性助力DeepSeek V3訓(xùn)練性能提升
DeepSeek V3的訓(xùn)推適配過程中,通過MindSpore的MoE模塊優(yōu)化、Dryrun仿真等技術(shù),在優(yōu)化MoE的訓(xùn)練流程的同時(shí),還實(shí)現(xiàn)了更高效的多維混合并行。
MoE模塊優(yōu)化:在MoE模塊中可支持多種主流結(jié)構(gòu)可配置,如共享專家、路由專家個(gè)數(shù)、激活函數(shù)選擇等,極大地提升了模型的靈活性。在MoE并行方面支持TP-extend-EP、路由序列并行、MoE計(jì)算通訊掩蓋、分組AllToAll通訊等多種并行模式和并行優(yōu)化,用戶可在配置中更靈活地使用相關(guān)并行加速能力。
Dryrun集群內(nèi)存仿真與自動(dòng)負(fù)載均衡:MindSpore的Dryrun工具可以根據(jù)訓(xùn)練任務(wù)模擬出集群中每卡的內(nèi)存占用情況,從而在不實(shí)際占用集群的情況下,為訓(xùn)練的分布式并行策略調(diào)優(yōu)提供快捷反饋。自動(dòng)負(fù)載均衡工具SAPP為DeepSeek V3通過精確建模內(nèi)存和計(jì)算負(fù)載,在內(nèi)存約束條件下,求解最優(yōu)的流水線并行的各Stage層數(shù)與重計(jì)算量,分鐘級(jí)開銷內(nèi)自動(dòng)獲得最優(yōu)流水線配置。
下一步,昇思MindSpore開源社區(qū)將上線DeepSeek V3微調(diào)樣例與R1版本鏡像,為開發(fā)者提供開箱即用的模型。未來,昇思開源社區(qū)將依托豐富的技術(shù)能力,持續(xù)優(yōu)化DeepSeek V3系列模型的性能,加速模型從訓(xùn)練到生產(chǎn)部署端到端的創(chuàng)新效率,為開源開發(fā)者進(jìn)行大模型創(chuàng)新提供了高效易用的基礎(chǔ)軟件與技術(shù)生態(tài),促進(jìn)千行萬業(yè)智能化轉(zhuǎn)型升級(jí)。
在使用模型中,有任何疑問和建議,均可通過社區(qū)進(jìn)行反饋。
-
華為
+關(guān)注
關(guān)注
218文章
36005瀏覽量
262117 -
開源
+關(guān)注
關(guān)注
3文章
4207瀏覽量
46150 -
昇騰
+關(guān)注
關(guān)注
1文章
181瀏覽量
7427 -
DeepSeek
+關(guān)注
關(guān)注
2文章
835瀏覽量
3271
原文標(biāo)題:訓(xùn)推全面支持、開箱即用!DeepSeek V3昇思MindSpore版本上線開源社區(qū)
文章出處:【微信號(hào):HWS_yunfuwu,微信公眾號(hào):華為數(shù)字中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
加速解鎖科學(xué)智能前沿,昇思MindSpore鑄就了一把“全能”鑰匙
了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
昇思MindSpore全場景AI框架1.6版本的關(guān)鍵特性
昇思MindSpore TechDay直播倒計(jì)時(shí)
全場景AI框架昇思MindSpore獲得國際認(rèn)可
凌智電子LockzhinerAI V1.0與華為技術(shù)有限公司AI框架昇思MindSpore完成兼容性測試

人工智能框架生態(tài)峰會(huì)2023丨軟通動(dòng)力成為昇思MindSpore開源社區(qū)理事會(huì)首批成員單位
凌智電子LockzhinerAI V1.0與華為技術(shù)有限公司AI框架昇思MindSpore完成兼容性測試

軟通動(dòng)力受邀參加“昇思MindSpore AI框架”主題論壇,持續(xù)探索大模型創(chuàng)新實(shí)踐
香橙派與昇思MindSpore合作提速,軟硬結(jié)合助力開發(fā)者構(gòu)建創(chuàng)新AI應(yīng)用

昇思MindSpore預(yù)測2024年中國AI框架市場份額將達(dá)30%
迅龍軟件受邀參加華為昇思人工智能框架峰會(huì),展示昇思X香橙派的創(chuàng)新AI案例




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論