") 什么是網(wǎng)絡(luò)大模型技術(shù)
什么是網(wǎng)絡(luò)大模型技術(shù)

作者簡介:黃玉棟,北郵博士,研究方向時(shí)敏確定性網(wǎng)絡(luò)與網(wǎng)絡(luò)智能
當(dāng)前,生成式人工智能被認(rèn)為是21世紀(jì)最重要的技術(shù)突破之一,其為人類社會(huì)帶來了工作范式的轉(zhuǎn)變,極大地提高了人類生產(chǎn)力。比如,2022年12月ChatGPT橫空出世,以火箭般的流行速度短短五天吸引了超過100萬用戶,兩個(gè)月后月活用戶達(dá)到1億,其為代表的對(duì)話系統(tǒng)達(dá)到接近人類水平,不僅能幫助人類完成寫郵件、寫代碼、撰寫報(bào)告、生成圖像、生成視頻等工作,甚至在AlphaCode程序設(shè)計(jì)競賽中擊敗了45.7%的程序員,通用人工智能被認(rèn)為有望重塑或取代當(dāng)前80%的人類工作。
2023年1月,生物界首次實(shí)現(xiàn)從零合成全新蛋白,2023年2月,Meta開源LlaMA模型,2023年3月,谷歌打造出PaLM-E具身智能機(jī)器人,此外,生成式人工智能已被全面用于分子結(jié)構(gòu)預(yù)測、芯片設(shè)計(jì)、蛋白質(zhì)生成、通信信道預(yù)測等生物、醫(yī)療、材料、機(jī)器人、信息科學(xué)領(lǐng)域。
那么,生成式人工智能可否用于網(wǎng)絡(luò)領(lǐng)域?有哪些場景和關(guān)鍵技術(shù)?跟以前的智能有什么區(qū)別?前沿進(jìn)展如何?怎么實(shí)現(xiàn)?這是大家關(guān)心和熱議的話題。本文作為科普入門資料,將以通俗易懂的方式,以基于Transformer架構(gòu)的大模型技術(shù)為主線,分析“網(wǎng)絡(luò)大模型”的核心原理、關(guān)鍵技術(shù)、場景應(yīng)用和發(fā)展趨勢。
什么是網(wǎng)絡(luò)大模型技術(shù)?
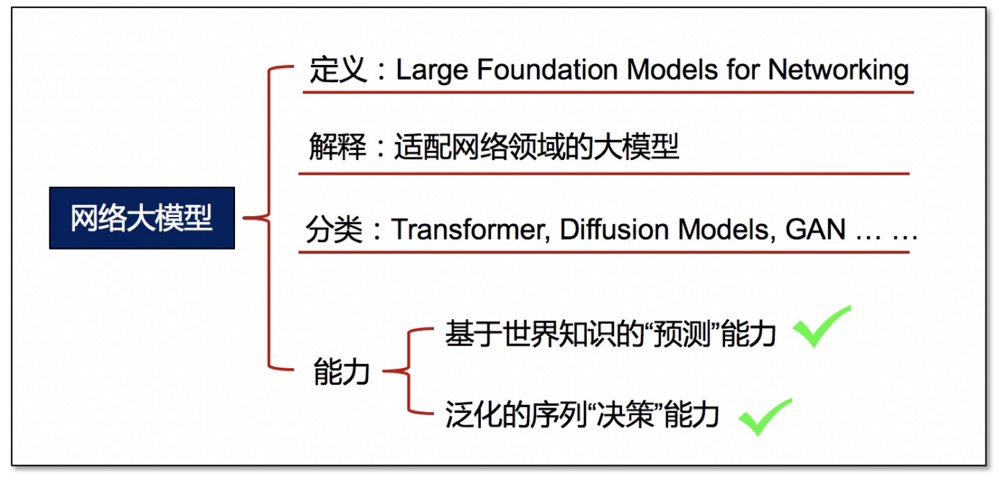
本文將適配網(wǎng)絡(luò)領(lǐng)域的大模型技術(shù)稱為“網(wǎng)絡(luò)大模型“技術(shù),即“Large Foundation Models for Networking”。其中,基礎(chǔ)模型有很多種,比如Transformer,Diffusion Models, GAN,以及它們的衍生改進(jìn)版本,不同基礎(chǔ)模型服務(wù)于不同的模態(tài)(即輸入數(shù)據(jù))和任務(wù)場景。縱然模型千變?nèi)f化,其本質(zhì)卻始終如一。本文將網(wǎng)絡(luò)大模型的主要能力分為兩種,第一種是基于世界知識(shí)的“預(yù)測”能力,第二種是泛化的序列“決策”能力。接下來首先介紹第一種能力。
基于世界知識(shí)的預(yù)測能力
什么是預(yù)測?
回顧一個(gè)經(jīng)典的例子,給你三組數(shù)據(jù),第一組x=1,y=1.05,第二組x=2,y=4.17, 第三組x=4,y=15.99,請(qǐng)猜一下x=3時(shí),y應(yīng)該等于多少。
人們通過分析,可以得出數(shù)據(jù)滿足y=x*x的規(guī)律,因此x=3時(shí),y大約等于9。這就是一個(gè)最簡單的預(yù)測的過程,可以被描述為y=F(x),其中F是一個(gè)函數(shù)。但真實(shí)問題中很多輸入輸出關(guān)系是非線性的復(fù)雜映射,需要用海量數(shù)據(jù)來擬合,因此有了神經(jīng)網(wǎng)絡(luò)的概念,并用一個(gè)損失函數(shù)來最小化預(yù)測的誤差。
比如例子中實(shí)際采集的數(shù)據(jù)是x=3時(shí),y=9.01,那么輸出9就存在一定的誤差。一個(gè)神經(jīng)網(wǎng)絡(luò)模型包含輸入層、隱藏層和輸出層,訓(xùn)練的過程就是不斷的輸入x=3,讓模型調(diào)整隱藏層計(jì)算權(quán)重去猜y=9.8,y=9.5,直到猜到了y=9,就認(rèn)為模型學(xué)會(huì)了映射關(guān)系,訓(xùn)練停止。然后推理的過程就是輸入x=3,模型直接輸出y=9。
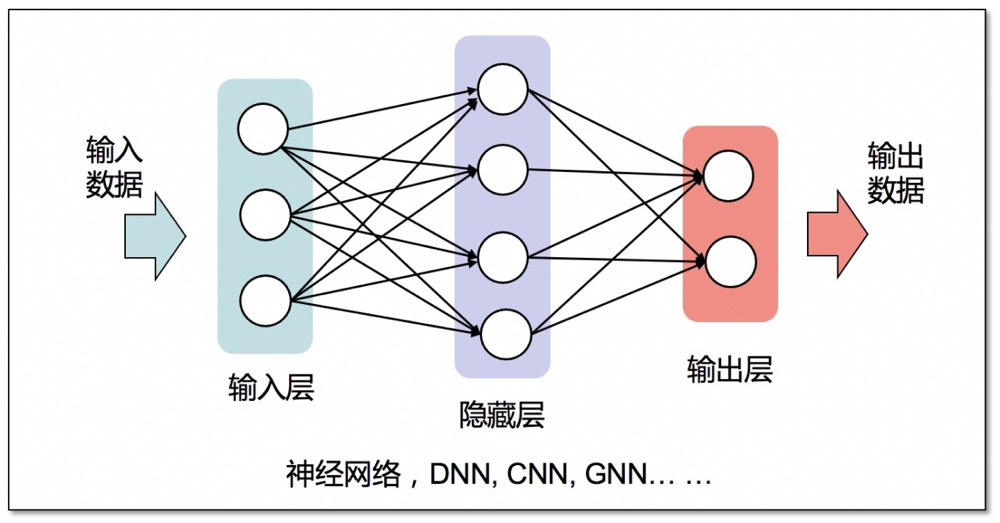
總結(jié)一下,本質(zhì)上模型是用來預(yù)測輸入數(shù)據(jù)和輸出數(shù)據(jù)之間的非線性關(guān)系的,包括訓(xùn)練和推理兩個(gè)步驟,有效數(shù)據(jù)量越多,模型的預(yù)測精度通常越高。其次,模型并不能脫離數(shù)據(jù)集“憑空產(chǎn)生結(jié)果”,要先在訓(xùn)練過程中通過已知的輸入-輸出對(duì)來學(xué)習(xí),即監(jiān)督學(xué)習(xí)。
此外,模型學(xué)習(xí)的是產(chǎn)生結(jié)果的概率,而非結(jié)果本身。雖然在示例中輸入和輸出只是簡單的數(shù)字,但在實(shí)際應(yīng)用中,輸入輸出可能是文本、圖像、拓?fù)洹⒁曨l等。針對(duì)不同的輸入數(shù)據(jù)結(jié)構(gòu)和特征,神經(jīng)網(wǎng)絡(luò)模型被不斷改進(jìn),例如,用于圖像處理的卷積神經(jīng)網(wǎng)絡(luò)(CNN)和用于處理拓?fù)涞膱D神經(jīng)網(wǎng)絡(luò)(GNN)等,在此按下不表。
Transformer的基本原理
Transformer是一種在2017年被提出的廣泛用于自然語言處理的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),即用來預(yù)測詞與詞之間的映射關(guān)系。舉個(gè)問答的例子,如下圖所示,輸入問題是“五月一日是什么節(jié)日?”我們希望輸出回答是“五月一日是勞動(dòng)節(jié)”。
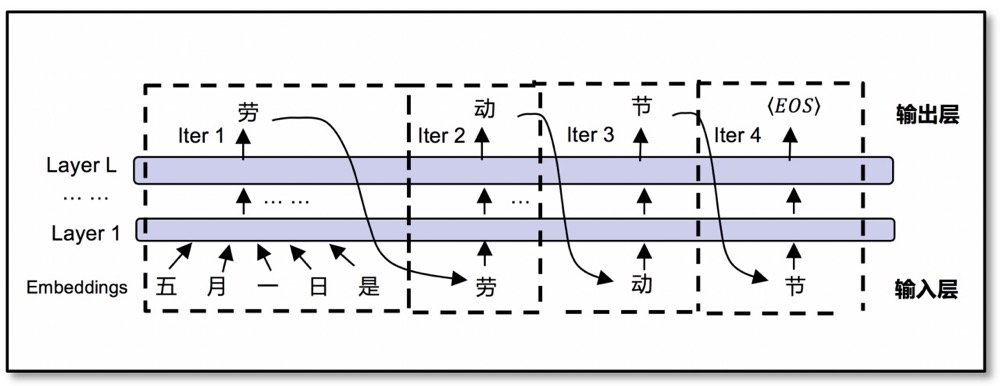
那怎么讓計(jì)算機(jī)理解語言和文字?首先,需要將每個(gè)詞作為一個(gè)最小處理單元,即token,然后把這些token轉(zhuǎn)換為向量,即embeddings。比如假設(shè)“月”字用向量[1,0,0,0]表示,“日”字用向量[0,1,0,0]表示。有了向量以后就可以進(jìn)行矩陣運(yùn)算,就可以被計(jì)算機(jī)所“理解”了。然后,Transformer里提出了一個(gè)attention注意力機(jī)制,用來計(jì)算一個(gè)輸入文本序列中每個(gè)詞與其他詞的相關(guān)性,并通過位置編碼來表明序列中詞的位置信息,也就是先看一下前面幾個(gè)詞是“五月一日是”,然后開始猜下一個(gè)詞概率最大可能是“勞”,再下一個(gè)詞是“動(dòng)”,再下一個(gè)詞是“節(jié)”。
Transformer的結(jié)構(gòu)優(yōu)勢在于具有特別好的可擴(kuò)展性,比如以前的自然語言處理模型很難捕捉長距離依賴,也就是句子長了就丟失了上下文關(guān)系信息,再比如attention能夠并行計(jì)算,大大提高了訓(xùn)練的速度。
此外,以前是每個(gè)任務(wù)都需要單獨(dú)訓(xùn)練一個(gè)模型,而Transformer架構(gòu)非常通用,能很好地適應(yīng)機(jī)器翻譯、文本生成、問答系統(tǒng)等各種任務(wù),這使得模型可以輕松地?cái)U(kuò)展到更大規(guī)模,并實(shí)現(xiàn)“one model for all”的效果。
基于世界知識(shí)的“大”模型
如果故事到這里結(jié)束,Transformer僅僅只會(huì)停留在自然語言處理領(lǐng)域。然而接下來,OpenAI大力出奇跡,開啟了大模型新紀(jì)元。試想一下,如果把所有已知的詞都作為token,那世界知識(shí)能否被編碼成能被計(jì)算機(jī)“理解”的詞典?神經(jīng)網(wǎng)絡(luò)模型能否誕生出類似人腦的理解能力甚至超越人類的智能?2018年OpenAI發(fā)布了首個(gè)GPT(Generative Pre-trained Transformer)模型,并提出了無監(jiān)督預(yù)訓(xùn)練+有監(jiān)督微調(diào)的訓(xùn)練方法。
最開始GPT-1具有1.17億個(gè)模型參數(shù),預(yù)訓(xùn)練數(shù)據(jù)量約為5GB,到2020年,GPT-3的模型參數(shù)量達(dá)到了驚人的1750億,預(yù)訓(xùn)練數(shù)據(jù)量增長到了45TB。在“大”模型背后,Scaling Law縮放法則指出,通過在更多數(shù)據(jù)上訓(xùn)練更大的模型,模型性能將不斷提升。且模型達(dá)到一定的臨界規(guī)模后,表現(xiàn)出了一些開發(fā)者最開始未能預(yù)測的、更復(fù)雜的能力特性,即“涌現(xiàn)”的能力。另外,GPT背后還有大量的工程考慮,比如基于任務(wù)的模型微調(diào)、提示詞工程、人類意圖對(duì)齊等等。
網(wǎng)絡(luò)大模型
網(wǎng)絡(luò)大模型的主要應(yīng)用
現(xiàn)今,開源和閉源的基礎(chǔ)大模型已經(jīng)觸手可及,將大模型適配網(wǎng)絡(luò)應(yīng)用的研究更是如火如荼。接下來,本文將從網(wǎng)絡(luò)領(lǐng)域已有數(shù)據(jù)的角度把大模型應(yīng)用分為六類,并簡要分析前沿研究進(jìn)展。
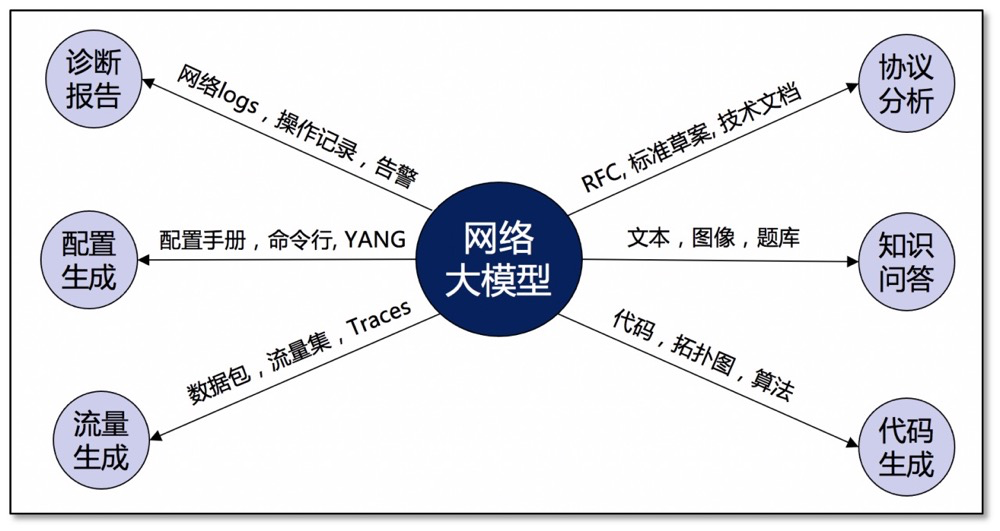
網(wǎng)絡(luò)知識(shí)問答:網(wǎng)絡(luò)知識(shí)也屬于世界知識(shí),網(wǎng)絡(luò)知識(shí)題庫是很好的已有的高質(zhì)量任務(wù)數(shù)據(jù)集,因此,一個(gè)直白的做法是,用多選題等方法對(duì)各種基礎(chǔ)模型進(jìn)行測評(píng),查看其是否掌握、掌握了多少的網(wǎng)絡(luò)領(lǐng)域知識(shí),以及探討如何通過微調(diào)、提示詞等方法釋放基礎(chǔ)模型在網(wǎng)絡(luò)領(lǐng)域的能力。
比如文獻(xiàn) ^[1]^ 中構(gòu)建了包含一萬條問答題的TeleQnA數(shù)據(jù)集來評(píng)估大語言模型對(duì)電信領(lǐng)域知識(shí)的掌握程度,文獻(xiàn) ^[2]^ 中,包含5732個(gè)多選題的NetEval數(shù)據(jù)集被用來評(píng)估比較了26種開源的大語言模型。此外,問答的能力還可被廣泛用于運(yùn)營商智能客服、以及網(wǎng)絡(luò)從業(yè)人員的教育培訓(xùn)。
網(wǎng)絡(luò)代碼生成:另一個(gè)直白的做法是用大模型來生成網(wǎng)絡(luò)領(lǐng)域的工程代碼,比如Python腳本以及linux命令行。此外,通過調(diào)用各種代碼庫,還能直接生成用于網(wǎng)絡(luò)拓?fù)洹⒕W(wǎng)絡(luò)算法等的基礎(chǔ)代碼。圖是網(wǎng)絡(luò)中十分標(biāo)準(zhǔn)的結(jié)構(gòu)化數(shù)據(jù),文獻(xiàn) ^[3]^ 中提出用大語言模型生成的代碼分析和管理網(wǎng)絡(luò)拓?fù)鋱D,比如添加鏈路或者節(jié)點(diǎn)地址分類。文獻(xiàn) ^[4]^ 還提出了利用大語言模型來復(fù)現(xiàn)網(wǎng)絡(luò)研究論文的代碼的想法,并在小規(guī)模的實(shí)驗(yàn)中證明了可行性。
網(wǎng)絡(luò)協(xié)議分析:網(wǎng)絡(luò)協(xié)議是網(wǎng)絡(luò)設(shè)備研發(fā)和網(wǎng)絡(luò)系統(tǒng)運(yùn)行的基礎(chǔ),面對(duì)海量的錯(cuò)綜復(fù)雜的RFC文檔,亟需自動(dòng)化的協(xié)議理解能力。然而,不同于普通的文本,協(xié)議中包含了規(guī)則、狀態(tài)、通信流、數(shù)據(jù)流圖、消息結(jié)構(gòu)等協(xié)議實(shí)體,給模型推理的準(zhǔn)確度帶來很大的挑戰(zhàn)。文獻(xiàn) ^[5]^ 利用zero-shot和few-shot等方法評(píng)估了GPT-3.5-turbo從RFC文檔中提取有限狀態(tài)機(jī)的能力。
此外,當(dāng)前的協(xié)議設(shè)計(jì)流程極其緩慢,且涉及復(fù)雜的交互過程和配置參數(shù),比如MAC協(xié)議,必須針對(duì)具體目的和場景進(jìn)行定制,例如提高吞吐量、降低功耗、保證公平性等。特別是在異構(gòu)網(wǎng)絡(luò)部署場景下,每個(gè)無線接入網(wǎng),例如5G-NR、Wi-Fi、藍(lán)牙、Zigbee,甚至衛(wèi)星接入網(wǎng),都有自己的協(xié)議和屬性,例如考慮容量、延遲、覆蓋程度、安全性、功耗和成本等屬性。考慮到未來網(wǎng)絡(luò)更加復(fù)雜和多樣化的設(shè)置,每個(gè)設(shè)備上也許能部署一個(gè)網(wǎng)絡(luò)協(xié)議大模型,通過自適應(yīng)環(huán)境來自動(dòng)生成合適的協(xié)議,并將人類從繁重的協(xié)議設(shè)計(jì)工作中解放出來。
網(wǎng)絡(luò)配置生成:網(wǎng)絡(luò)中有大量異構(gòu)設(shè)備,例如交換機(jī)、路由器和中間件。由于廠商和設(shè)備型號(hào)各有不同,需要大量專業(yè)人員來學(xué)習(xí)設(shè)備手冊(cè)和用戶手冊(cè)、收集合適的命令、驗(yàn)證配置模板、以及將模板參數(shù)映射到控制器數(shù)據(jù)庫。在此過程中,即使是單個(gè)ACL配置錯(cuò)誤也可能導(dǎo)致網(wǎng)絡(luò)中斷。
考慮到不斷增長的異構(gòu)云網(wǎng)絡(luò)以及大量需要管理的計(jì)算和存儲(chǔ)設(shè)備,統(tǒng)一的自然語言配置界面對(duì)于簡化配置過程和實(shí)現(xiàn)自配置網(wǎng)絡(luò)至關(guān)重要。異構(gòu)的網(wǎng)絡(luò)配置數(shù)據(jù)包括低級(jí)別的ACL規(guī)則、CLI命令行,以及封裝的YANG Model、XML、JSON等數(shù)據(jù)格式規(guī)范,文獻(xiàn) ^[6]^ 中基于BERT模型實(shí)現(xiàn)了異構(gòu)廠商設(shè)備的自動(dòng)化管理,即直接從各類設(shè)備手冊(cè)中學(xué)習(xí)并生成統(tǒng)一的網(wǎng)絡(luò)配置數(shù)據(jù)模型。
網(wǎng)絡(luò)流量生成:網(wǎng)絡(luò)流量集對(duì)于網(wǎng)絡(luò)仿真、網(wǎng)絡(luò)測量、攻擊探測、異常流量檢測、逆向協(xié)議解析等任務(wù)至關(guān)重要,然而常常真實(shí)的流量因?yàn)殡[私問題無法獲得,而手動(dòng)構(gòu)造的流量集(比如泊松分布)又在保真度和多樣化方面有很大的欠缺。生成式AI具有很好的“泛化”能力,即能夠?qū)W到已有數(shù)據(jù)分布并生成相似分布的數(shù)據(jù),可以被用來生成具有不同特征(比如特定IP地址段、端口分布、不同協(xié)議類型、包大小分布、到達(dá)間隔、持續(xù)時(shí)間、流分布)的網(wǎng)絡(luò)流量集,文獻(xiàn) ^[7],[8],[9]^ 分別基于Transformer,GAN,和Diffusion Models架構(gòu)實(shí)現(xiàn)了上述目標(biāo)。
網(wǎng)絡(luò)診斷報(bào)告:故障排查對(duì)于網(wǎng)絡(luò)運(yùn)營商來說是一項(xiàng)繁瑣而繁重的工作。特別是在大規(guī)模廣域網(wǎng)絡(luò)中,需要跨地域的不同部門之間的協(xié)調(diào),而網(wǎng)絡(luò)用戶仍會(huì)遭受突然的網(wǎng)絡(luò)故障或性能下降,并面臨數(shù)億美元的經(jīng)濟(jì)損失。通過將大語言模型集成到網(wǎng)絡(luò)診斷系統(tǒng)中,大語言模型能夠根據(jù)網(wǎng)絡(luò)狀態(tài)信息生成故障報(bào)告,加速故障定位,并根據(jù)報(bào)告分析和歷史運(yùn)行數(shù)據(jù)給出合理的處理建議。
雖然網(wǎng)絡(luò)系統(tǒng)中有大量的Log日志、操作記錄和告警報(bào)錯(cuò)信息,但這些非結(jié)構(gòu)化的數(shù)據(jù)很難被直接用于訓(xùn)練。最近,文獻(xiàn) ^[10]^ 設(shè)計(jì)了從用戶到工作流(workflow)到數(shù)據(jù)的對(duì)話式網(wǎng)絡(luò)診斷系統(tǒng),能夠?qū)⒂脩粢鈭D映射到工作模板,并從網(wǎng)絡(luò)底層獲取網(wǎng)絡(luò)狀態(tài)信息來填充模板作為診斷反饋答案。此外,產(chǎn)業(yè)界中也有比如Juniper提出了Marvis虛擬網(wǎng)絡(luò)助手 ^[11]^ 來實(shí)現(xiàn)網(wǎng)絡(luò)自動(dòng)化運(yùn)維管理。
網(wǎng)絡(luò)大模型的關(guān)鍵技術(shù)
實(shí)現(xiàn)以上應(yīng)用并非易事,從相關(guān)文獻(xiàn)可以看到,由于網(wǎng)絡(luò)領(lǐng)域存在區(qū)別于純文本的規(guī)則、公式、協(xié)議、約束、數(shù)學(xué)、符號(hào),直接使用基礎(chǔ)模型效果往往差強(qiáng)人意,需要很多額外的工程工作。
首先,部分網(wǎng)絡(luò)領(lǐng)域知識(shí)可能未被基礎(chǔ)模型學(xué)到,容易導(dǎo)致模型產(chǎn)生“幻覺”,比如某些網(wǎng)絡(luò)領(lǐng)域?qū)S忻~和協(xié)議規(guī)則,需要通過微調(diào)的方式,比如參數(shù)高效的部分微調(diào)方式和LoRA低秩矩陣,來增強(qiáng)模型對(duì)網(wǎng)絡(luò)知識(shí)的理解。微調(diào)的哲學(xué)在于既要為模型引入網(wǎng)絡(luò)領(lǐng)域知識(shí),又要保留模型原本學(xué)到的世界知識(shí)。
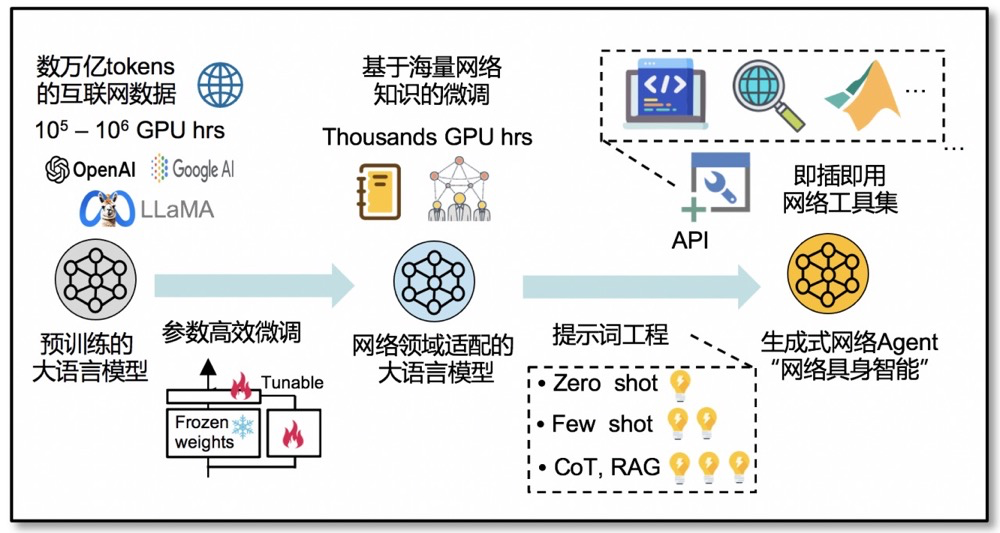
其次,用戶意圖模糊會(huì)導(dǎo)致輸入不準(zhǔn)確,且許多網(wǎng)絡(luò)任務(wù)很難用簡單的語言進(jìn)行表述,因此,需要基于提示詞工程,比如zero-shot, few-shot, 思維鏈,以及RAG檢索增強(qiáng)技術(shù),來構(gòu)合適的prompt和網(wǎng)絡(luò)任務(wù)基準(zhǔn)測試集;比如思維鏈可以鼓勵(lì)大模型采用逐步的推理過程來將復(fù)雜的問題拆解為多個(gè)簡單子問題,以及通過上傳相關(guān)技術(shù)文檔供模型檢索來縮小任務(wù)范圍并提高推理精度。除了推理精度和推理速度,為了量化網(wǎng)絡(luò)大模型的能力,相關(guān)的網(wǎng)絡(luò)任務(wù)層面的屬性和指標(biāo),比如回答正確率,任務(wù)完成度,生成結(jié)果與最優(yōu)結(jié)果之間的數(shù)學(xué)距離,也待被提出和研究。
另外,考慮到網(wǎng)絡(luò)領(lǐng)域存在大量難以被直接用于訓(xùn)練的非結(jié)構(gòu)化數(shù)據(jù),引入Agent技術(shù)是一個(gè)當(dāng)前的熱門方向,即通過API等方式,將大語言模型與網(wǎng)絡(luò)工具(仿真軟件、監(jiān)測系統(tǒng)、安全工具、控制器、求解器、搜索引擎)做集成,讓網(wǎng)絡(luò)大模型學(xué)會(huì)使用網(wǎng)絡(luò)工具,彌補(bǔ)模型在規(guī)劃、計(jì)算、求解等方面的短板,最終實(shí)現(xiàn)“網(wǎng)絡(luò)具身智能”。更多技術(shù)細(xì)節(jié)可參考文獻(xiàn) ^[12]^ 。下一篇將介紹網(wǎng)絡(luò)大模型的第二種能力,即泛化的序列“決策”能力。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
31079瀏覽量
222258 -
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
8265瀏覽量
94757 -
人工智能
+關(guān)注
關(guān)注
1817文章
50098瀏覽量
265380 -
大模型
+關(guān)注
關(guān)注
2文章
3650瀏覽量
5183
原文標(biāo)題:秒懂網(wǎng)絡(luò)大模型之基于世界知識(shí)的預(yù)測能力
文章出處:【微信號(hào):SDNLAB,微信公眾號(hào):SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于卷積的基礎(chǔ)模型InternImage網(wǎng)絡(luò)技術(shù)分析
【大語言模型:原理與工程實(shí)踐】核心技術(shù)綜述
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
計(jì)算機(jī)與網(wǎng)絡(luò)技術(shù)基礎(chǔ)
基于網(wǎng)絡(luò)性能的VoIP語音質(zhì)量評(píng)價(jià)模型
網(wǎng)絡(luò)中心戰(zhàn)構(gòu)建模型是什么?
在現(xiàn)場總線中使用藍(lán)牙技術(shù)替代有線傳輸介質(zhì)的應(yīng)用模型
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
藍(lán)牙Mesh技術(shù)—邊緣網(wǎng)絡(luò)的成長
基于密罐技術(shù)的網(wǎng)絡(luò)安全模型研究與實(shí)現(xiàn)
一種工業(yè)通信網(wǎng)絡(luò)模型與網(wǎng)絡(luò)集成設(shè)計(jì)

探究Overlay網(wǎng)絡(luò)模型和Underlay網(wǎng)絡(luò)模型。



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論