") 借助NVIDIA NIM加速AI應(yīng)用部署
借助NVIDIA NIM加速AI應(yīng)用部署

大語言模型(LLM)在企業(yè)組織中的應(yīng)用日益廣泛,許多企業(yè)都將其整合到 AI 應(yīng)用中。雖然從基礎(chǔ)模型著手十分高效,但需要花費一定的精力才能將它們整合到生產(chǎn)就緒型環(huán)境中。NVIDIA NIM簡化了這一過程,使企業(yè)能夠在數(shù)據(jù)中心、云、工作站和 PC 等任何位置運行 AI 模型。
專為企業(yè)設(shè)計的 NIM 提供一整套預(yù)構(gòu)建云原生微服務(wù),這些微服務(wù)能夠被輕松地整合到現(xiàn)有基礎(chǔ)設(shè)施中。這些微服務(wù)經(jīng)過精心的維護和持續(xù)的更新,具有開箱即用的性能,并確保您能夠獲得 AI 推理技術(shù)的最新進展。
適用于大語言模型的全新 NVIDIA NIM
基礎(chǔ)模型的增長源于其能夠滿足各種企業(yè)需求的能力,但沒有任何一個單一的模型能夠完全滿足企業(yè)的需求,企業(yè)通常會根據(jù)特定的數(shù)據(jù)需求和 AI 應(yīng)用工作流,在其用例中使用不同的基礎(chǔ)模型。
考慮到企業(yè)需求的多樣化,我們擴大了 NIM 的陣容,涵蓋了Mistral-7B、Mixtral-8x7B和Mixtral-8x22B,這三個基礎(chǔ)模型在特定任務(wù)中的表現(xiàn)都十分出色。
圖 1. 新的 Mixtral 8x7B Instruct NIM
可從 NVIDIA API 中獲取
Mistral 7B NIM
Mistral 7B Instruct 模型在文本生成和語言理解任務(wù)中表現(xiàn)出色。該模型可在單個 GPU 上運行,非常適合語言翻譯、內(nèi)容生成和聊天機器人等應(yīng)用。將 Mistral 7B NIM 部署至 NVIDIA 數(shù)據(jù)中心 GPU 后,開發(fā)者在內(nèi)容生成任務(wù)中可實現(xiàn)的開箱即用性能(token/秒),其性能最多可提升至沒有使用 NIM 時的 2.3 倍。
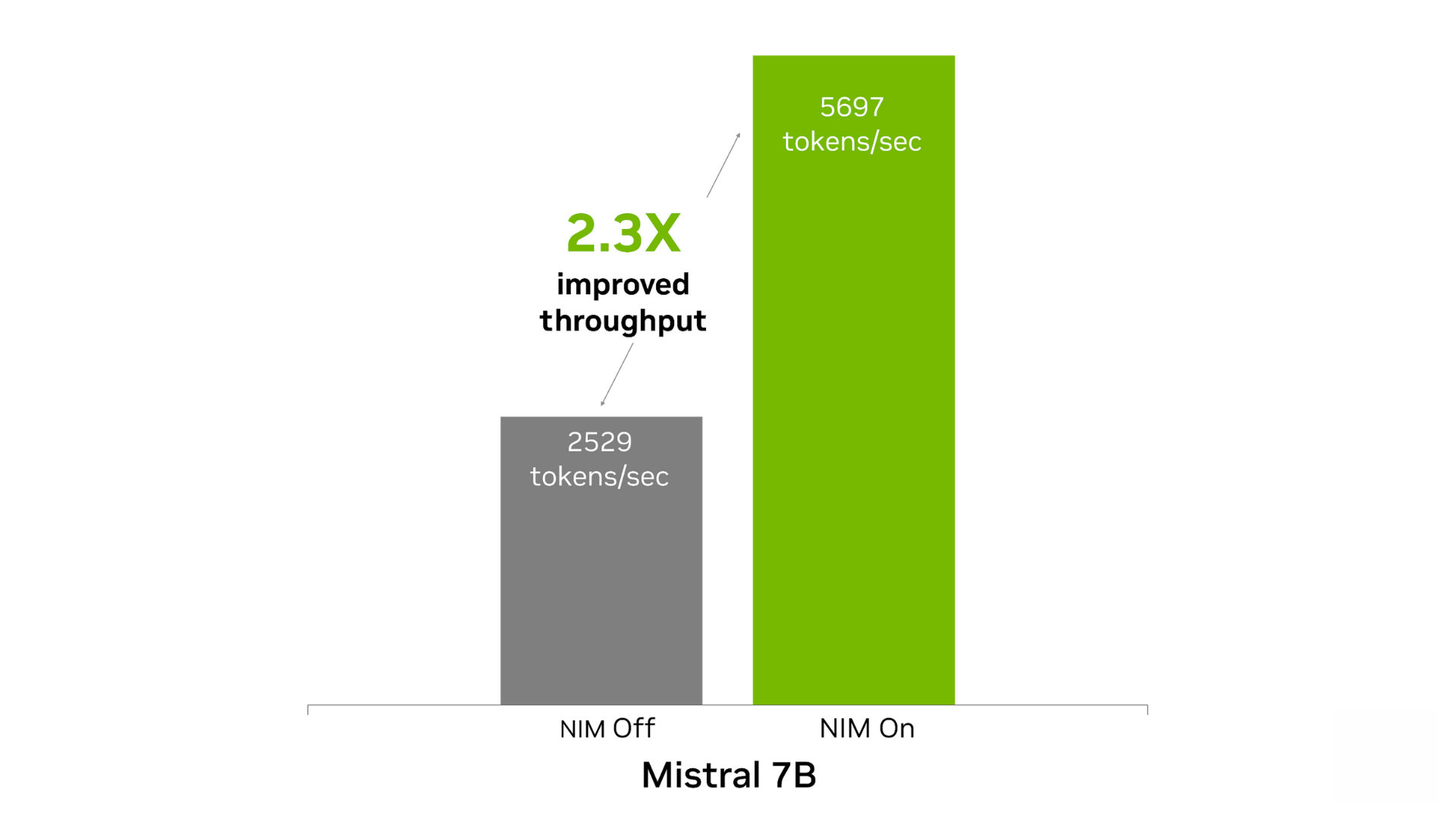
圖 2. Mistral 7B NIM 提高了內(nèi)容生成的吞吐量
基于 1 個 NVIDIA Tensor Core GPU,輸入 500 個 token,輸出 2,000 個 token。NIM 開啟時:FP8。吞吐量為 5,697 token/秒,TTFT 為 0.6 秒,ITL 為 26 毫秒。NIM 關(guān)閉時:FP16。吞吐量為 2,529 token/秒,TTFT 為 1.4 秒,ITL 為 60 毫秒。
Mixtral-8x7B和
Mixtral-8x22B NIM
Mixtral-8x7B 和 Mixtral-8x22B 模型采用混合專家(MoE)架構(gòu)提供快速且經(jīng)濟高效的推理。這兩個模型在總結(jié)、問題解答和代碼生成等任務(wù)中表現(xiàn)出色,非常適合需要實時響應(yīng)的應(yīng)用。
相較無 NIM 運行的情況,NIM 可以提高這兩種模型的開箱即用性能。當用于內(nèi)容生成且在 1 個 NVIDIA Tensor Core GPU 上運行時,Mixtral-8x7B NIM 的吞吐量最多可提高 4.1 倍。在內(nèi)容生成和翻譯用例中,Mixtral-8x22B NIM 的吞吐量最多可提高 2.9 倍。
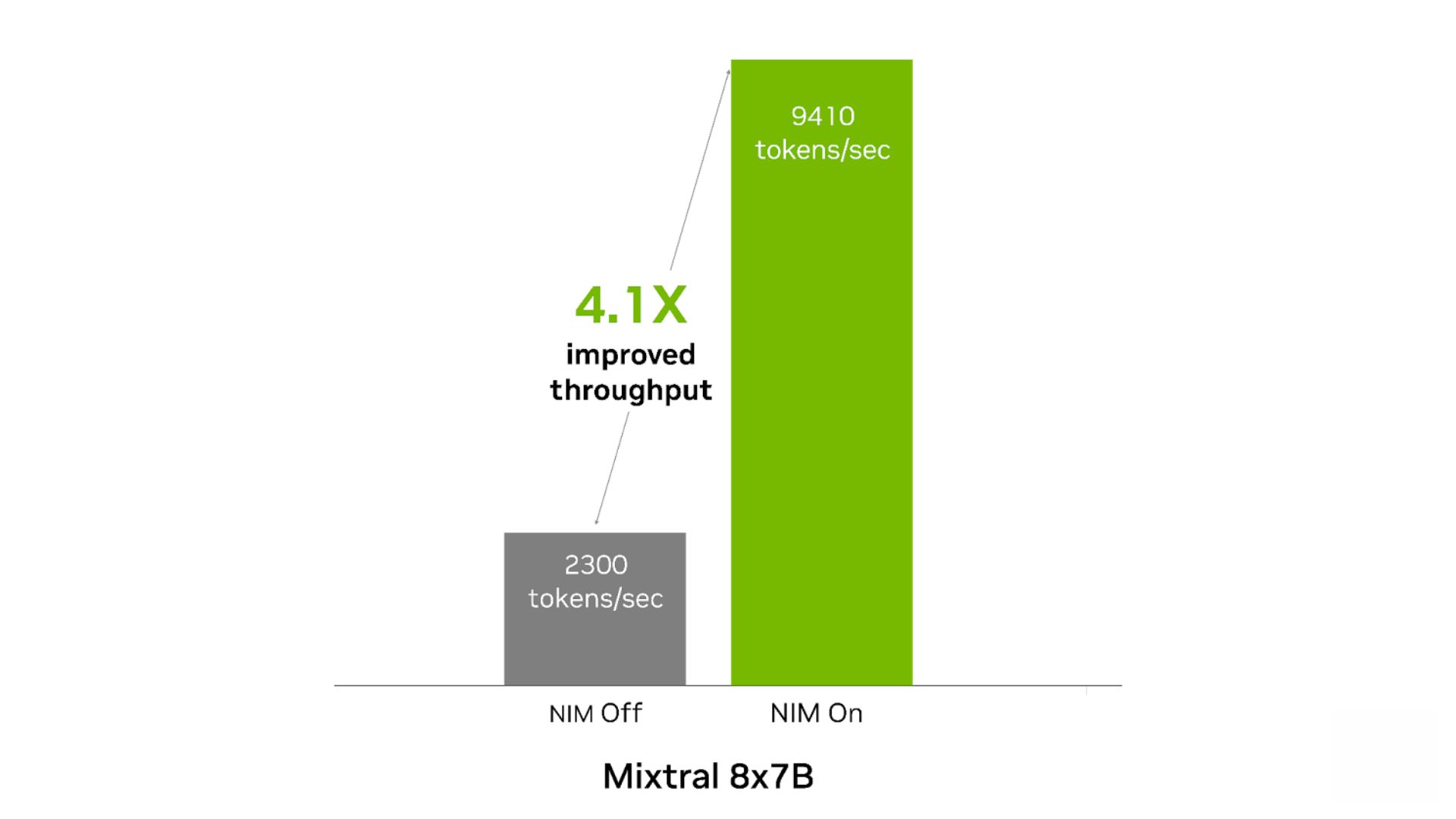
圖 3. Mixtral 8x7B NIM
提高了內(nèi)容生成的吞吐量
輸入 500 個 token,輸出 2,000 個 token。200 個并發(fā)請求。NIM 開啟時:FP8。吞吐量為 9,410 token/秒。TTFT 為 740 毫秒,ITL 為 21 毫秒。NIM 關(guān)閉時:FP16。吞吐量為 2,300 token/秒,TTFT 為 1,321 毫秒,ITL 為 86 毫秒。
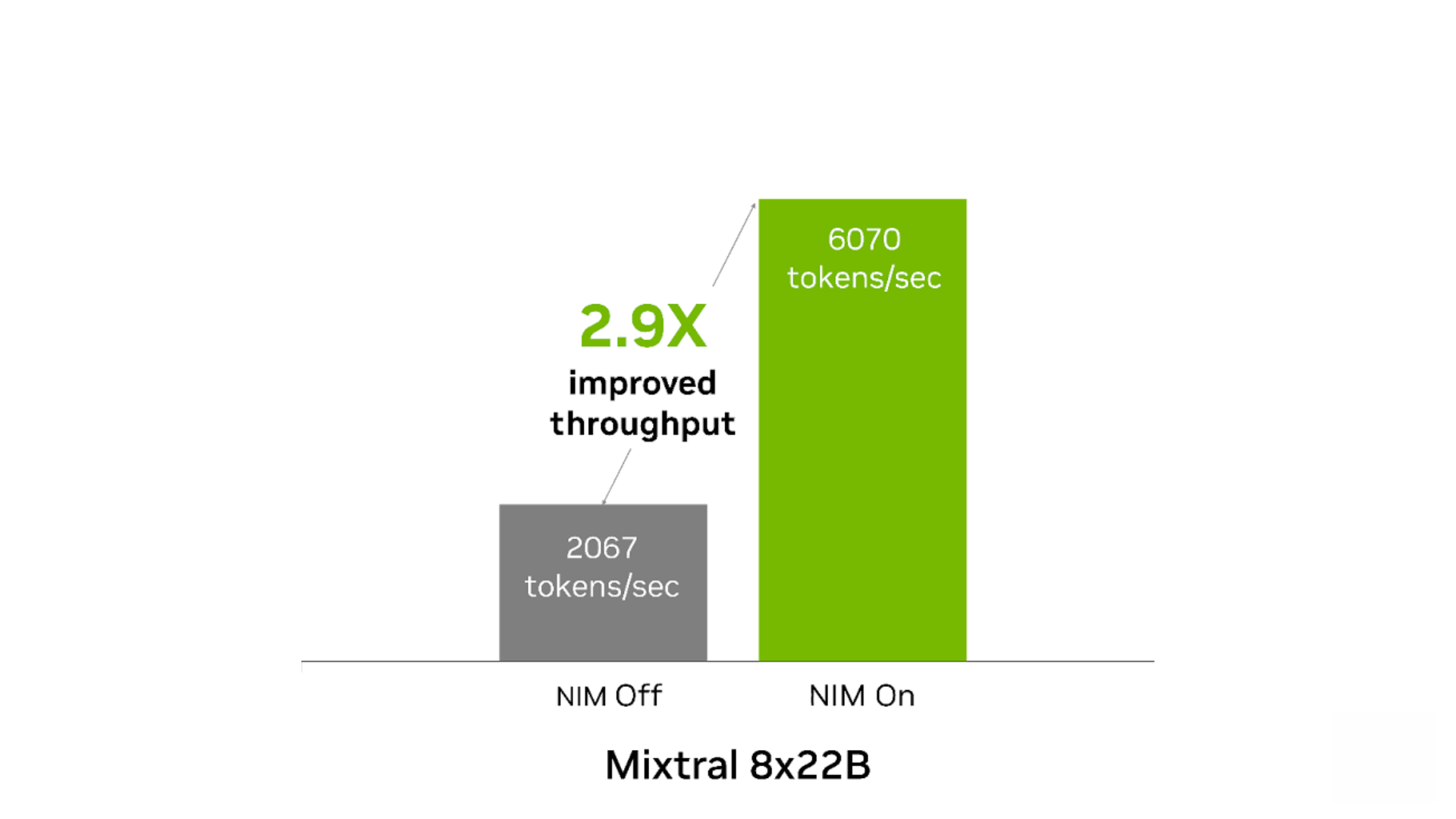
圖 4. Mixtral 8x22B NIM
提高了內(nèi)容生成和翻譯的吞吐量
輸入 1,000 個 token,輸出 1,000 個 token。250 個并發(fā)請求。NIM 開啟時:吞吐量為 6,070 token/秒,TTFT 為 3 秒,ITL 為 38 毫秒。NIM 關(guān)閉時:吞吐量為 2,067 token/秒,TTFT 為 5 秒,ITL 為 116 毫秒。
借助 NVIDIA NIM 加速 AI 應(yīng)用部署
開發(fā)者可以使用 NIM 縮短構(gòu)建適用于生產(chǎn)部署的 AI 應(yīng)用所需的時間,同時還能提高 AI 推理效率,并降低運營成本。借助 NIM,經(jīng)過優(yōu)化的 AI 模型實現(xiàn)了容器化,為開發(fā)者帶來了以下優(yōu)勢:
性能和規(guī)模
這些云驅(qū)動的微服務(wù)可提供低延遲、高吞吐量并可以輕松擴展的 AI 推理,使用 Llama 3 70B NIM,最多可將吞吐量提高 5 倍。NIM 還支持精確的微調(diào)模型,無需從頭開始構(gòu)建即可實現(xiàn)超高的準確性,進一步提高了 AI 推理性能。
易于使用
通過簡化與現(xiàn)有系統(tǒng)的整合來加快進入市場的速度,并在 NVIDIA 加速基礎(chǔ)設(shè)施上提供最佳性能。借助專為企業(yè)使用而設(shè)計的 API 和工具,開發(fā)者可以實現(xiàn)其 AI 能力的最大化。
安全性和易管理性
確保您的 AI 應(yīng)用和數(shù)據(jù)具有強大的可控性和安全性。通過NVIDIA AI Enterprise,NIM 支持在任何基礎(chǔ)設(shè)施上的靈活自托管部署,提供企業(yè)級軟件、嚴格的驗證以及與 NVIDIA AI 專家的直接連線。
AI 推理的前景:
NVIDIA NIM 及其他延伸
NVIDIA NIM 代表了 AI 推理領(lǐng)域的重大進步。隨著各行各業(yè)對 AI 應(yīng)用需求的日益增長,高效部署這些應(yīng)用變得至關(guān)重要。想要利用 AI 變革力量的企業(yè)可以使用 NVIDIA NIM,將預(yù)構(gòu)建的云原生微服務(wù)輕松整合到現(xiàn)有系統(tǒng)中,以此加快產(chǎn)品推出速度,保持在創(chuàng)新領(lǐng)域的領(lǐng)先地位。
未來的 AI 推理將超越單個 NVIDIA NIM。隨著對先進 AI 應(yīng)用的需求不斷增長,連接多個 NVIDIA NIM 將變得至關(guān)重要。這種微服務(wù)網(wǎng)絡(luò)將帶來能夠協(xié)同工作和適應(yīng)各種任務(wù)的高度智能化應(yīng)用,從而深入改變我們使用技術(shù)的方式。如要在您的基礎(chǔ)設(shè)施上部署 NIM 推理微服務(wù),請查看“使用 NVIDIA NIM 部署生成式 AI 的簡單指南”:
NVIDIA 定期發(fā)布新的 NIM,為企業(yè)提供最強大的 AI 模型,助企業(yè)應(yīng)用一臂之力。請訪問API 目錄,查找適用于 LLM、視覺、檢索、3D 和數(shù)字生物學(xué)模型的最新 NVIDIA NIM。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5594瀏覽量
109743 -
AI
+關(guān)注
關(guān)注
91文章
39793瀏覽量
301427 -
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52111 -
微服務(wù)
+關(guān)注
關(guān)注
0文章
150瀏覽量
8103
原文標題:全新 NVIDIA NIM:可適用于 Mistral 和 Mixtral 模型并為您的 AI 項目賦能
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
NVIDIA AI微服務(wù)現(xiàn)已與AWS集成,加速藥物研發(fā)和數(shù)字醫(yī)療
NVIDIA NIM 革命性地改變模型部署,將全球數(shù)百萬開發(fā)者轉(zhuǎn)變?yōu)樯墒?AI 開發(fā)者

英偉達推出AI模型推理服務(wù)NVIDIA NIM
英偉達推出全新NVIDIA AI Foundry服務(wù)和NVIDIA NIM推理微服務(wù)
NVIDIA NIM:打造AI領(lǐng)域的AI-in-a-Box,提高AI開發(fā)與部署的高效性
借助NVIDIA NIM微服務(wù)助力可口可樂公司擴展生成式AI內(nèi)容
NVIDIA 攜手全球合作伙伴推出 NIM Agent Blueprints,助力企業(yè)打造屬于自己的 AI
NVIDIA NIM助力企業(yè)高效部署生成式AI模型
日本企業(yè)借助NVIDIA產(chǎn)品加速AI創(chuàng)新
NVIDIA推出適用于網(wǎng)絡(luò)安全的NIM Blueprint
全新NVIDIA NIM微服務(wù)實現(xiàn)突破性進展
NVIDIA 發(fā)布保障代理式 AI 應(yīng)用安全的 NIM 微服務(wù)
英偉達GTC2025亮點:Oracle與NVIDIA合作助力企業(yè)加速代理式AI推理




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論