 基于DPU的Ceph存儲解決方案
基于DPU的Ceph存儲解決方案

1. 方案背景和挑戰
Ceph是一個高度可擴展、高性能的開源分布式存儲系統,設計用于提供優秀的對象存儲、塊存儲和文件存儲服務。它的幾個核心特點是:
彈性擴展:Ceph能夠無縫地水平擴展存儲容量和性能,只需添加新的存儲節點即可,無需重新配置現有系統,非常適合云環境的動態需求;
自我修復:通過副本或糾刪碼技術,Ceph能夠自動檢測并修復數據損壞或丟失,保證數據的高可用性和持久性;
統一接口:Ceph提供RADOS GW(對象存儲網關)、RBD(塊設備映射)和CephFS(文件系統)三種接口,滿足不同存儲需求,且這些接口可以同時在一個集群中使用。
在Kubernetes(K8s)架構下,Ceph可以作為一個強大的存儲后端,為容器化的應用提供持久化存儲解決方案。Kubernetes通過存儲卷插件與外部存儲系統集成,Ceph正是通過這樣的插件(如RBD插件)與K8s集成,實現存儲資源的動態分配和管理。
架構如下圖所示:
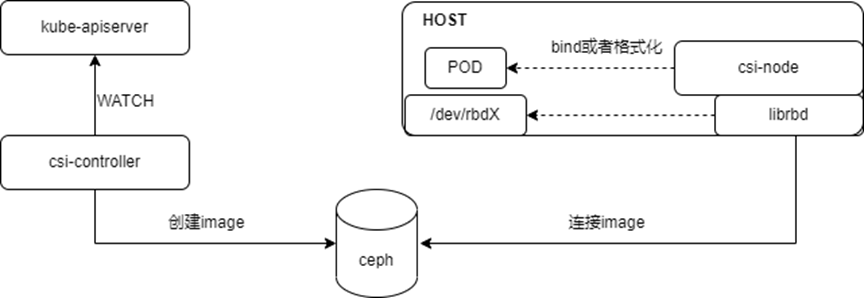
在傳統方式下使用Ceph作為存儲解決方案,會遇到一些局限性和挑戰,尤其是在與現代云原生環境如Kubernetes集成時,這些問題可能會更加突出,具體表現為以下幾個方面:
RBD客戶端運行于Host,消耗計算資源:傳統部署模式下,Ceph的RBD(RADOS Block Device)客戶端運行在宿主機(Host)層面,而非直接在容器內部。這意味著所有與Ceph交互的計算任務,包括I/O請求處理、錯誤恢復等,都需要宿主機的CPU資源來完成。在高負載情況下,這些額外的計算需求可能會對宿主機的資源分配產生壓力,影響到運行在相同宿主機上的其他容器應用的性能。
使用RBD協議連接后端存儲,性能受限:RBD協議雖然成熟且穩定,但在某些場景下,其性能表現可能不盡人意,尤其是在需要大量小I/O操作或高帶寬傳輸的情況下。這是因為RBD協議在設計上更多考慮了數據的可靠性和一致性,而非極致的性能。這導致數據傳輸延遲較高,影響到依賴快速存儲響應的應用性能,如數據庫服務或大數據處理系統。
在Kubernetes架構下,無法直接利用DPU實現卸載和加速:隨著DPU(Data Processing Unit)等硬件加速技術的興起,其在數據處理、網絡和存儲任務中的加速能力備受矚目。然而,在傳統的Ceph與Kubernetes集成方案中,缺乏直接利用DPU卸載存儲相關處理的能力,導致無法充分利用DPU提供的硬件加速優勢,限制了存儲性能的進一步提升和資源的高效利用。
鑒于以上挑戰,探索和實施針對Kubernetes環境優化的Ceph部署方案,如通過專門的Ceph CSI(Container Storage Interface)插件支持DPU卸載,或是利用Ceph的其他高級功能與現代硬件加速技術緊密結合,成為了提升云原生應用存儲性能和效率的關鍵方向。
2. 方案介紹
2.1. 整體架構
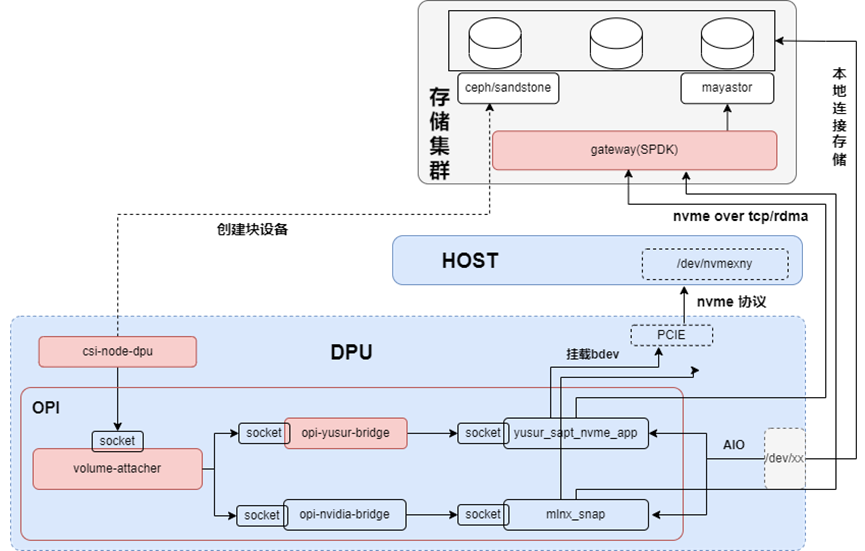
本方案采用云原生架構,引入DPU作為Kubernetes集群的Node,為集群之上的容器、虛機和裸金屬實例提供存儲服務的卸載和加速。整體架構如下所示:
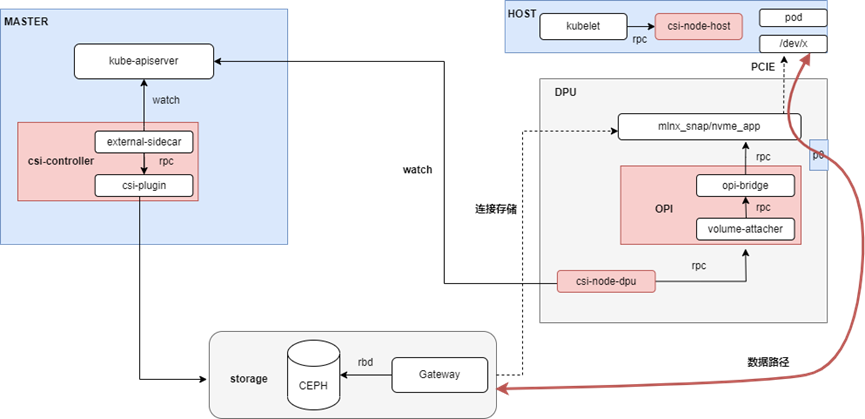
本方案將K8s node分為不同的角色(node-role),不同的組件分別部署在不同的node,主要包含:
Master Node上,部署csi的控制器csi-controller,用于創建volume和NVMe-oF target;
Host Node上,部署csi-node-host,配合csi-node-dpu,通過volumeattachment發現DPU掛載的NVMe盤,然后執行綁定或者格式化;裸機場景沒有這個組件;
DPU上,部署csi-node-dpu,volume-attacher和opi-bridge。opi-bridge是卡對opi-api存儲的實現,volume-attacher是對DPU存儲相關方法的封裝;csi-node-dpu 調用volume-attacher給host掛盤;
Storage上,部署Ceph和GATEWAY,GATEWAY是對SPDK封裝的一個服務,用于本地連接rbd image,暴露成NVMe-oF target。
2.2. 方案描述
本方案主要由csi-framework、opi-framework和storage三個部分組成,下面將對這三個部分進行介紹。
2.2.1. csi-framework
通過csi-framework我們能快速的接入第三方的存儲,讓第三方存儲很方便的使用DPU的能力。其包括csi-controller、csi-node-host和csi-node-dpu,主要職責是為K8s的負載提供不同的存儲能力。
2.2.1.1. csi-controller
Csi-controller以deployment的形式部署在master節點,其架構如下圖所示:
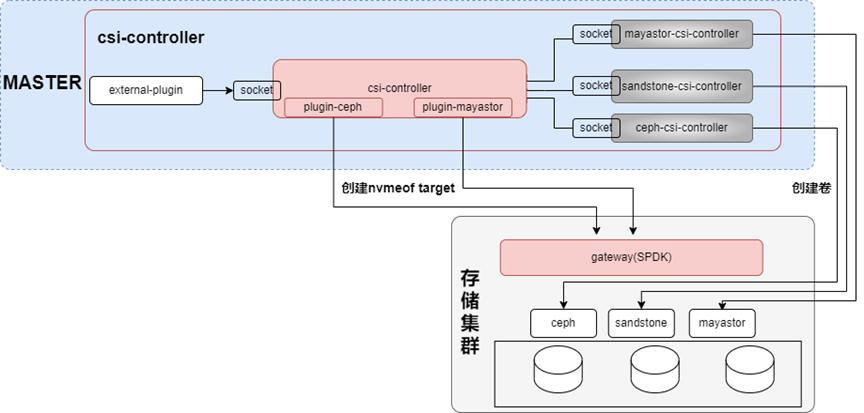
在csi-controller pod中,包含對接存儲的csi-controller容器,主要用于在對接存儲上創建卷,除此之外,為了讓對接存儲也能用nvmeof的方式,本架構也開發了對應的插件系統,由插件負責NVMe-oF target的管理。
結合K8s csi的external plugin,csi-controller主要實現以下兩類功能:
針對pvc,調用第三方的controller,創建卷,創建快照和擴容等;
針對pod(本質上volumeattachment,簡稱va),兩種連接模式,AIO和NVMe-oF(因為opi目前只支持這兩種)。如果是NVMe-oF,則調用不同的plugin在GATEWAY上創建NVMe-oF target;相關的target參數會持久化到va的status,此時va的狀態變為attached=true。
2.2.1.2. csi-node
Csi-node以daemonset的形式,部署在所有節點,其架構如下圖所示:
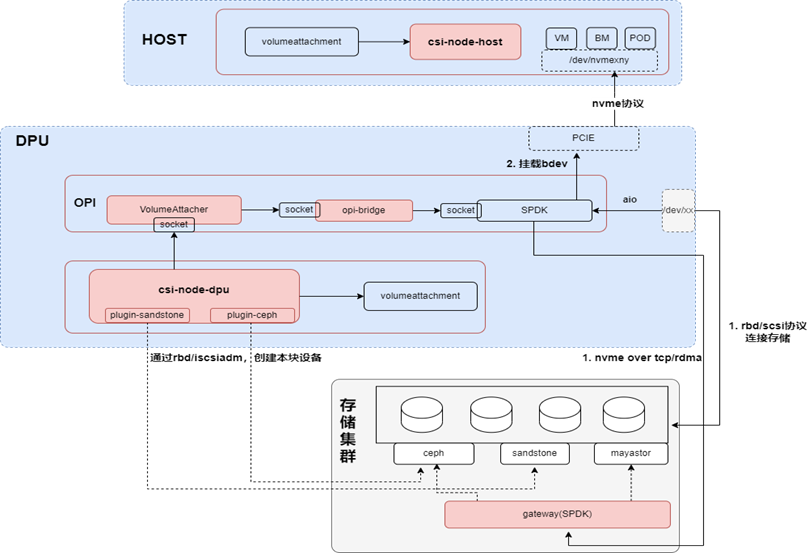
在csi-node的架構中,沒有整合第三方的csi-node,是因為第三方csi-node往往是針對非DPU的場景,所以在本框架中,也是使用插件系統,對接不同的第三方存儲。插件系統主要用于直連存儲,比如通過RBD或者ISCSI,會在本地生成一個塊設備,最后把這個塊設備再以AIO的方式掛載到PCIE上;如果是使用本框架的NVMe-oF的方式,由csi-node-dpu負責從va獲取對應的連接信息,連接NVMe-oF target。
Csi-node按node角色分為csi-node-dpu、csi-node-host和csi-node-default,不同角色的csi-node功能不同,下面分別加以說明:
csi-node-dpu需要處理host和DPU側的掛盤請求,待csi-node-dpu根據不同的連接模式(AIO或者NVMe-oF),連接遠程存儲;在pf或者vf上掛載磁盤后,會把掛盤的信息添加到va的annotation;
csi-node-host就能根據va的annotation找到掛載的disk,進行下一步操作;
csi-node-default 也就是默認的工作模式,同非DPU場景的csi-node工作方式。
2.2.2. opi-framework
主要用來兼容不同卡的功能,對上提供統一的接口;通過opi-framework,我們能將第三方存儲快速對接到其他DPU。不同DPU通過opi-bridge對接到opi框架,再由volume-attacher提供opi框架沒有的功能,其架構如下圖所示:
Opi-framewark包括volume-attacher、opi-yusur-bridge、opi-nvidia-bridge和SPDK,提供存儲卸載和加速能力。
volume-attacher是bridge之上的一層封裝,其主要作用有三個:
參數計算,比如掛載那個vf,使用那個nsid等;同時保證相同的盤,掛載到相同的掛載點;
因為opi-bridge和SPDK都沒有數據持久化,所以一旦opi-bridge或者SPDK重啟之后,需要volume-attacher進行數據恢復
從上我們知道,opi框架提供的能力有限,比如backend,只支持AIO和NVMe-oF;一旦要使用其他的bdev,比如lvol,此時就沒法通過opi-bridge操作,所以volume-attacher還封裝了對底層SPDK的操作。
opi-bridge是對opi標準的實現,不同的卡會有不同的bridge,存儲方面主要包括對接SPDK的三類接口(frontendmiddleendbackend)。
SPDK是卡上的服務,除了原生SPDK的功能外,主要作用是在pf或者vf上掛載bdev。
2.2.3. storage
除了第三方或者開源的存儲系統之外,還提供一個GATEWAY,GATEWAY的能力就是在靠近存儲的地方(所以往往和存儲系統部署在一起),把卷通過NVMe-oF target的方法是暴露出去;同時支持NVMe-oF multipath實現高可用。
3. 方案測試結果
3.1. Pod掛盤
首先創建pvc,然后在pod的volumes中以Block或者Filesystem的方式使用pvc,關鍵參數如下所示:
##pvc-xxx.yaml 關鍵參數 storageClassName: class-ceph ## 通過不同的storageclass,使用AIO或者nvmeof的方式
創建后,相關資源信息如下:
HOST側,使用nvme list和nvme list-subsys可查看對應的disk和system,如下圖所示:

DPU側,使用rpc.py查看對應的bdev,nvme_ns, nvme_ctrl
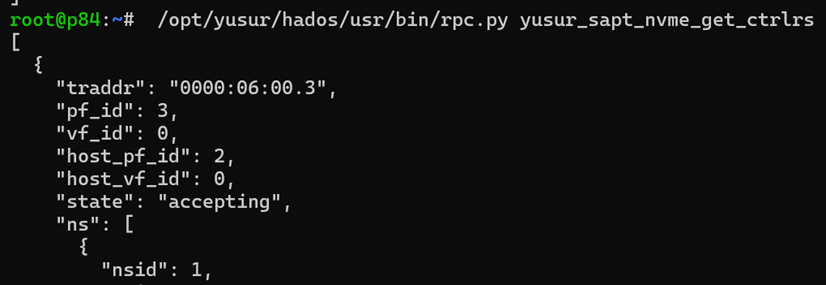
查看對應的bdev,如下所示:
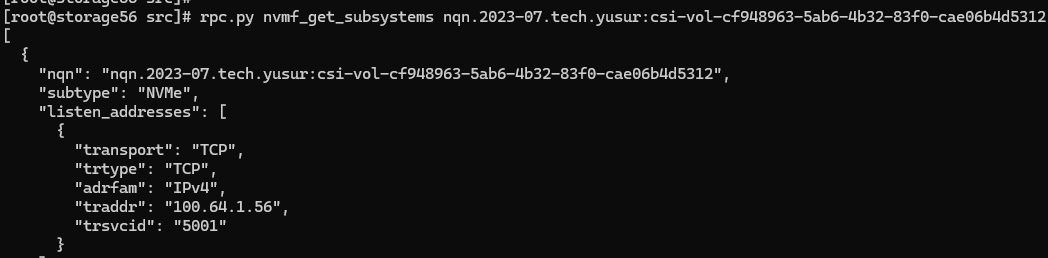
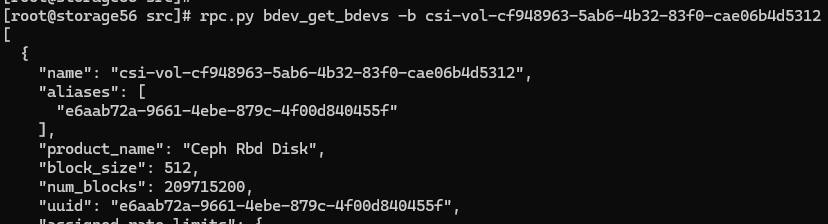
GATEWAY側,使用rpc.py查看nvme_subsystem,bdev
查看對應的bdev,如下所示:
3.2. 性能對比
本方案基于單節點ceph創建單副本存儲池,在以下測試場景與傳統ceph方案進行對比:
AIO:DPU上通過RBD協議連接存儲,然后把/dev/rbd0通過AIO給到Host;
Host-RBD:測試節點上用RBD 協議連接存儲,也是傳統ceph方案的方式;
LOCAL-RBD:存儲節點上用RBD協議連接存儲,用于對比Host-RBD;
Host-NVMe-CLI/TCP:測試節點上通過NVMe-CLI以NVMe/TCP的方式連接存儲上的GATEWAY,用來對比卸載模式的性能;
Host-NVMe-CLI/RDMA:測試節點上通過NVMe-CLI以NVMe/RDMA方式連接存儲上的GATEWAY,用來對比卸載模式的性能;
NVMe/TCP:DPU上直接TCP協議連接GATEWAY,是本方案的一種連接方式;
NVMe/RDMA:DPU上直接通過RDMA協議連接GATEWAY,是本方案的一種連接方式。
測試不同blocksize下的隨機讀寫指標包括iops,吞吐,延遲和Host CPU消耗。
3.2.1. 存儲IOPS
測試結果如下:
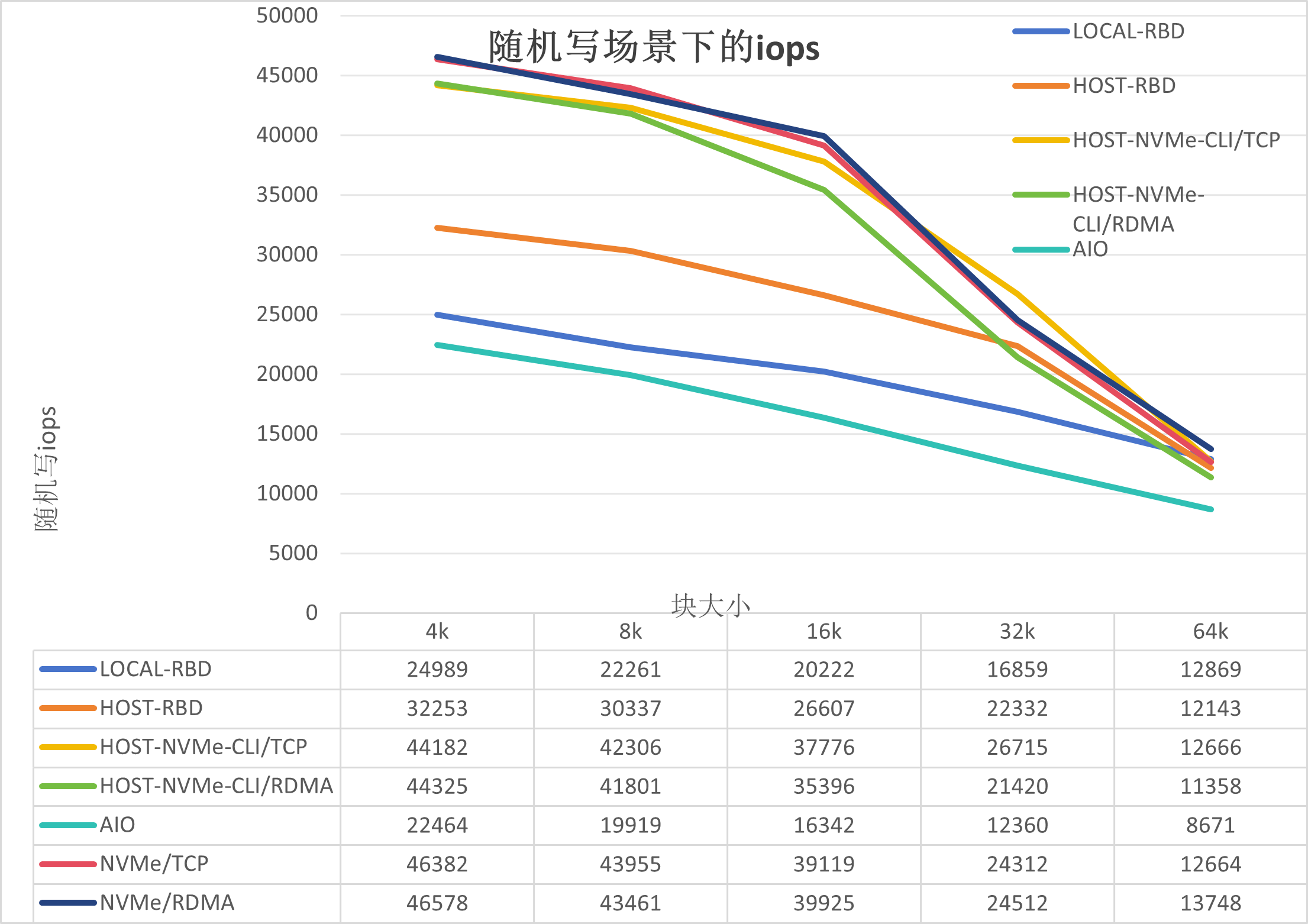
從上圖我們可以得出以下結論:
AIO性能最差,是因為AIO是通過DPU里面librbd連接存儲,受限于DPU的資源;
LOCAL-RBD的性能較Host-RBD低,是因為本地測試時,內核RBD模塊與osd存在資源競爭,導致ceph-osd的CPU上不去,在950%左右,但是在Host-RBD測試時ceph-osd的CPU在1050%左右;
NVMe/TCP的性能較Host-NVMe-CLI/TCP和Host-NVMe-CLI/RDMA稍高,是因為兩者的路徑不一樣,有可能是DPU的SPDK服務帶來的加速效果;
NVMe/RDMA與NVMe/TCP基本持平,是因為瓶頸在ceph,這個會基于裸盤給出結論
NVMe/RDMA,NVMe/TCP,Host-NVMe-CLI/TCP和Host-NVMe-CLI/RDMA,高于Host-RBD,是因為GATEWAY的加速作用,能把ceph-osd的CPU進一步提高到1150%左右。
隨機讀iops如下圖所示:
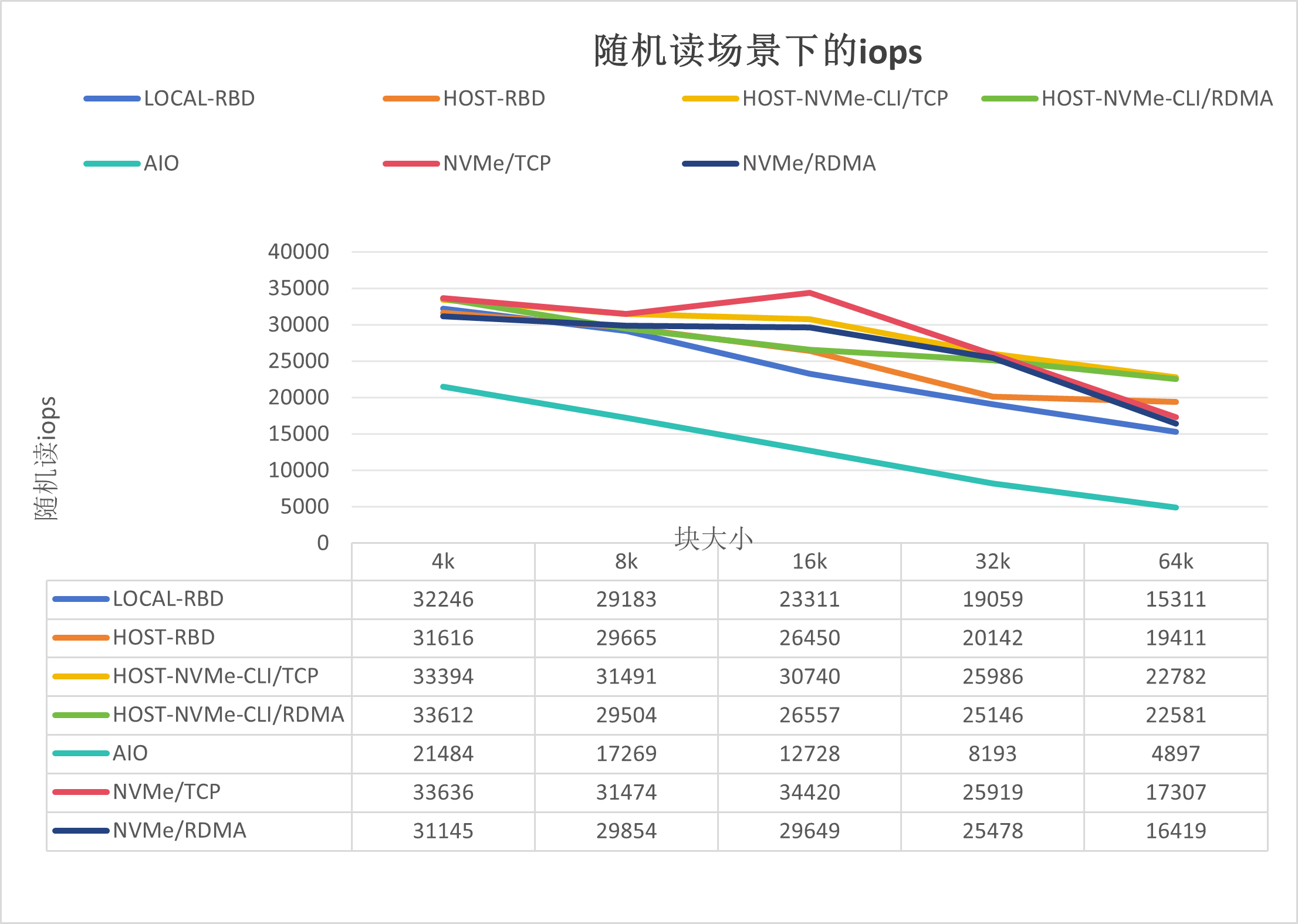
如上圖所示,可以得出如下結論:
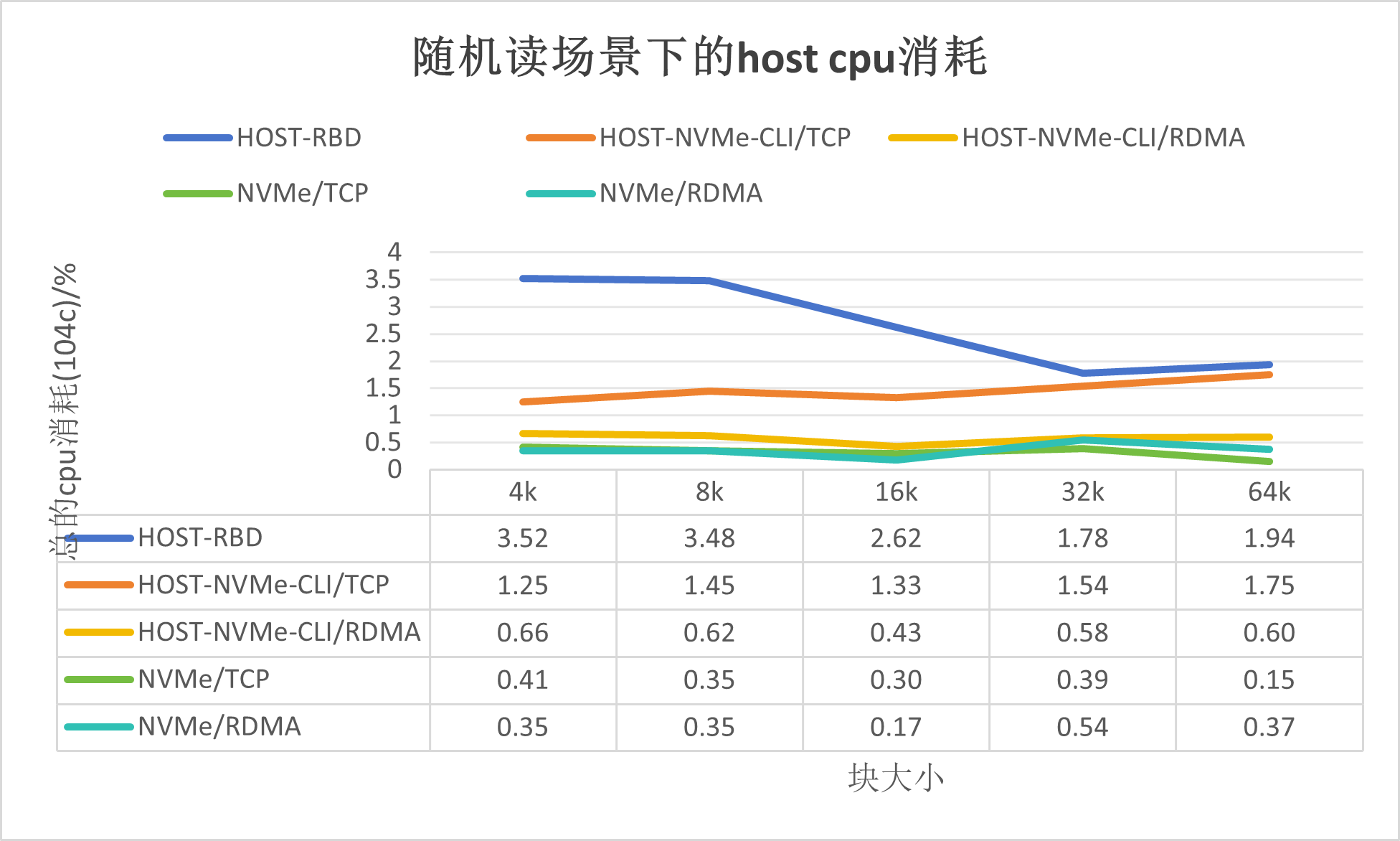
NVMe/TCP的性能與Host-NVMe-CLI/TCP基本持平,好于Host-RBD;
NVMe/RDMA的性能較NVMe/TCP的稍低,有可能是在隨機讀場景下RDMA協議的損耗導致。
3.2.2. 存儲延遲
測試結果如下:
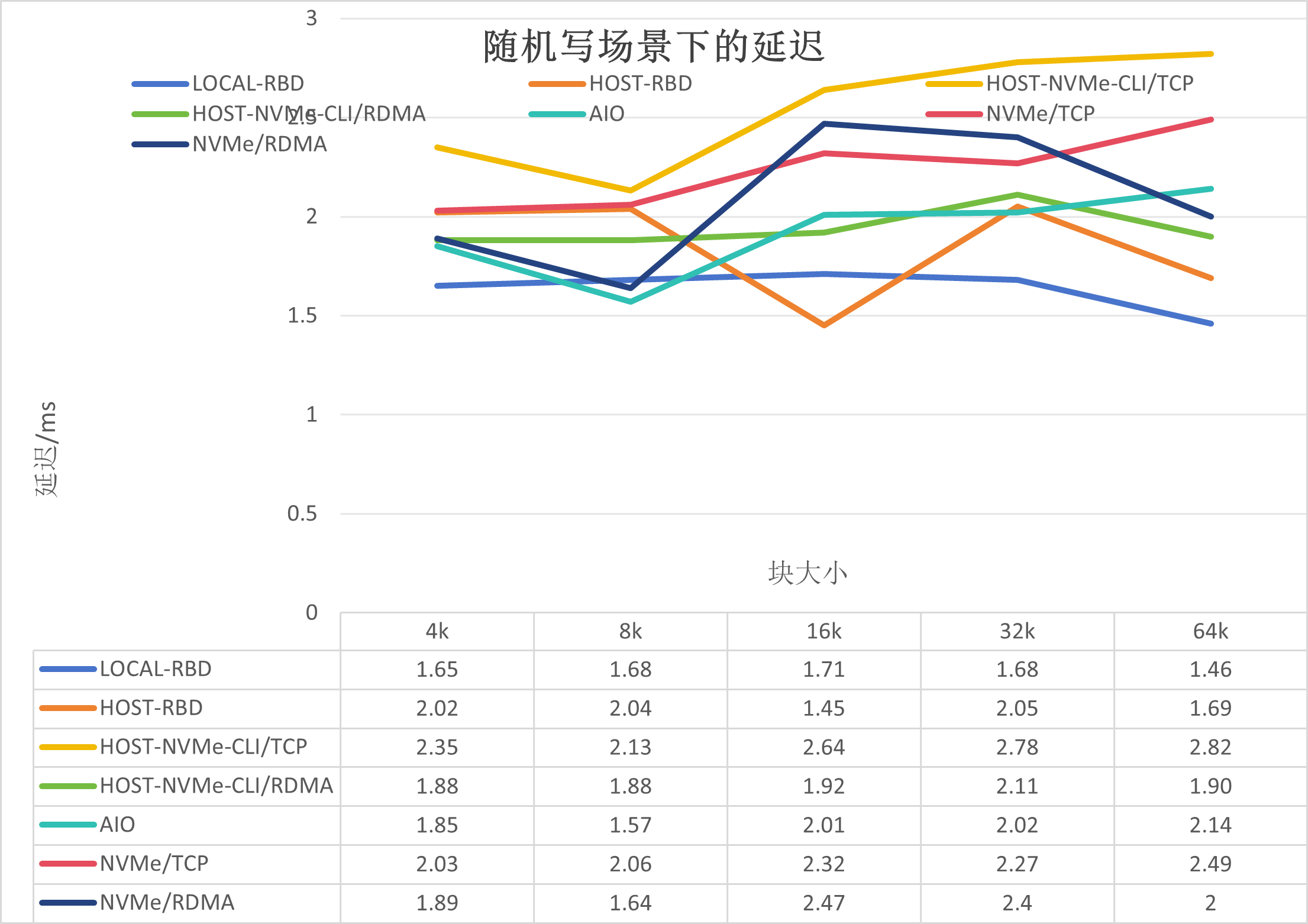
如上圖所示,可以得出如下結論:
RDMA的延遲要好于TCP;
HOST-RBD好于其他非本地場景,是因為整體io路徑較其他的短。
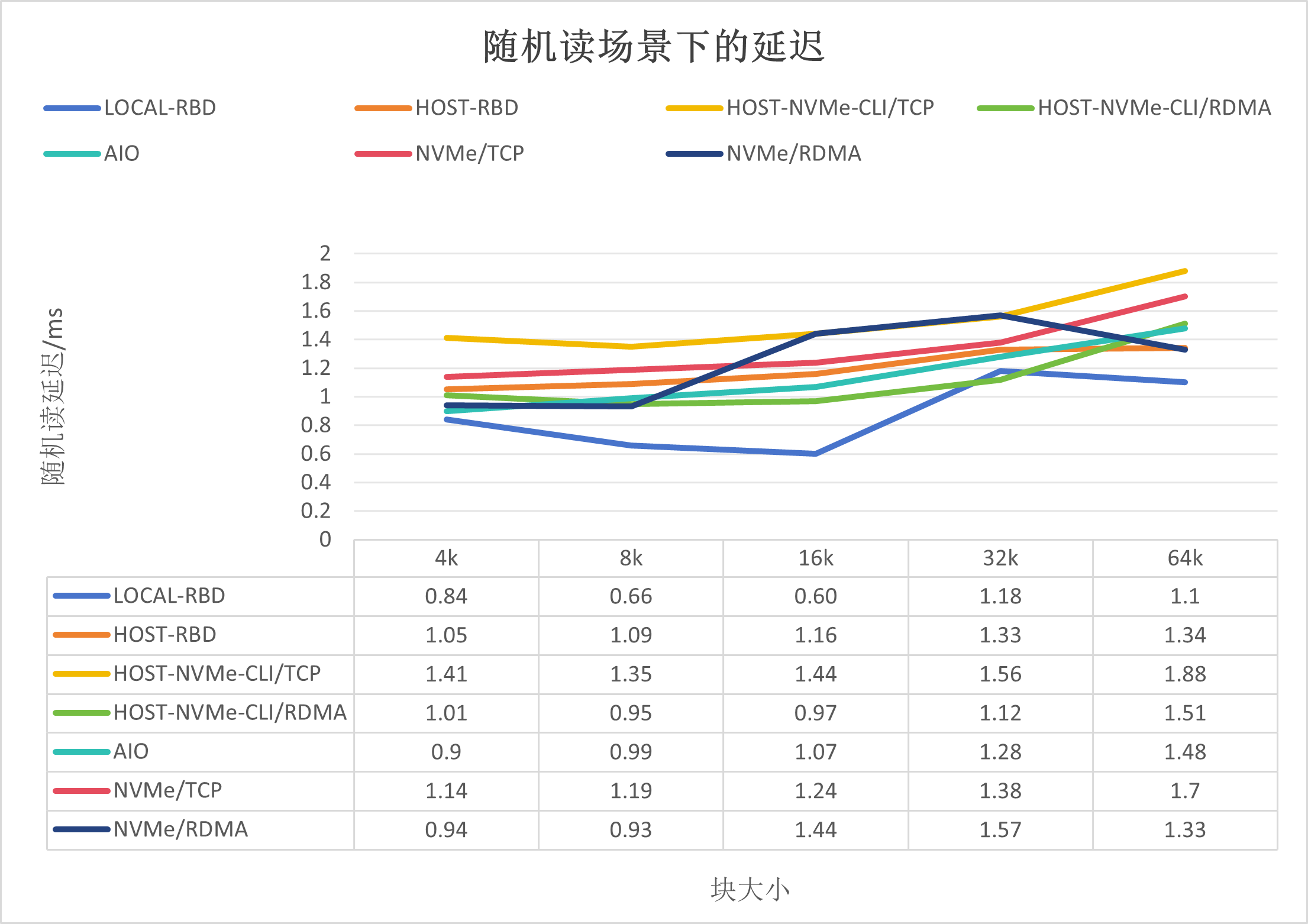
隨機讀場景下的延遲,如下所示:
3.2.3. CPU消耗
測試結果如下:
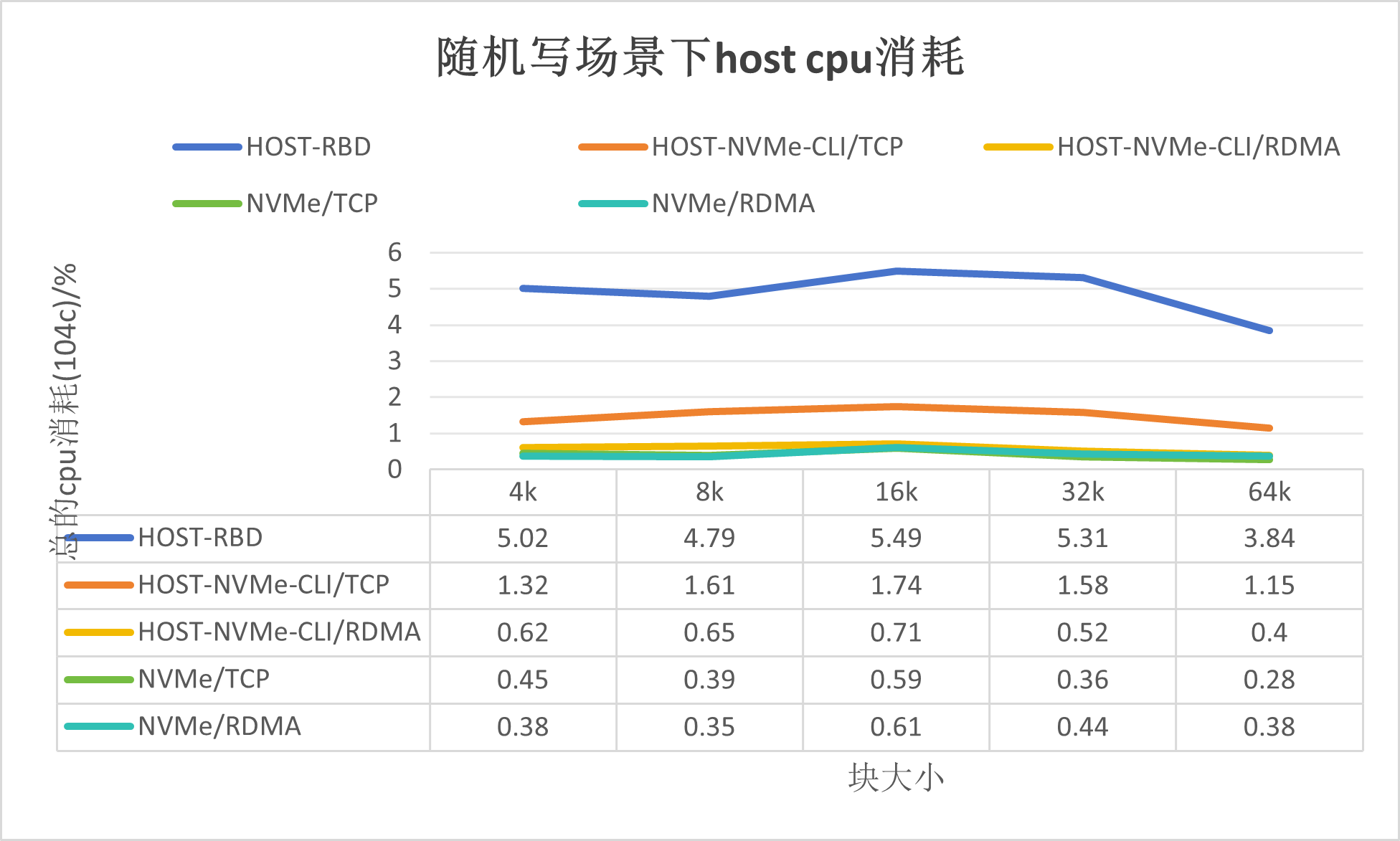
如上圖所示,可以得出如下結論:
基于傳統的Ceph解決方案,消耗Host CPU在400%-600%之間,其資源消耗在內核模塊RBD;
使用Host-NVMe-CLI/TCP的方式,消耗Host CPU在70%-200%之間, 其資源消耗在內核模塊NVMe/TCP;
使用Host-NVMe-CLI/RDMA的方式,其資源消耗和卸載模式相當;
基于DPU的ceph解決方案,NVMe/TCP和NVMe/RDMA的Host CPU消耗很低。
隨機讀場景下的資源消耗,如下所示:
4. 總結
4.1. 方案優勢
基于DPU(Data Processing Unit)的Ceph存儲解決方案,為云原生存儲領域帶來了顯著的資源優化,在性能上也有一定改善,具體優勢體現在以下幾個方面:
1. 資源效率大幅提升:通過將Ceph的控制面和數據面操作下沉至DPU處理,顯著減輕了宿主機(Host)的資源消耗。測試結果顯示,在并行度為8的場景下,blocksize為4KB時,宿主機CPU資源的使用率明顯下降,從502%的消耗,降低到了僅45%,這意味著在實際應用場景中,將大大節省了寶貴的CPU資源,讓這些資源能夠被應用服務更高效地利用。
2. 性能保持與優化:在對比分析中,基于DPU的Ceph解決方案不僅保持了與傳統Ceph部署在性能上的競爭力,而且還展示了顯著的提升潛力。通過對比使用Host-NVMe-CLI(分別通過TCP和RDMA協議)、NVMe/TCP和NVMe/RDMA的傳統Ceph性能數據,發現基于DPU的方案并未降低原有的Ceph性能表現,反而在某些指標上有所增強。特別是當直接對比基于Host的RBD訪問、NVMe/TCP和NVMe/RDMA的性能時,DPU方案展現出了超越這些傳統訪問方式的性能提升,這表明DPU不僅有效卸載了存儲處理任務,還通過其硬件加速特性提升了存儲I/O性能。
3. 填補Kubernetes生態空白:在Kubernetes(K8s)生態系統中,雖然有多種存儲解決方案和插件,但之前缺乏針對DPU優化的存儲卸載和加速服務。這一自研的基于DPU的Ceph解決方案,填補了這一技術空白,為Kubernetes環境下的應用提供了更高效、低延遲的存儲支持。通過集成DPU加速能力,不僅增強了云原生應用的存儲性能,還為用戶提供了更多選擇和優化存儲配置的靈活性,有助于提升整個云平臺的運行效率和成本效益。
綜上所述,基于DPU的Ceph存儲解決方案通過自研的Kubernetes組件、引入DPU深度優化存儲處理流程,顯著降低了宿主機資源消耗,保持甚至提升了存儲性能,同時為Kubernetes生態引入了創新的存儲加速服務,是面向未來云原生架構的重要技術進步。
本方案來自于中科馭數軟件研發團隊,團隊核心由一群在云計算、數據中心架構、高性能計算領域深耕多年的業界資深架構師和技術專家組成,不僅擁有豐富的實戰經驗,還對行業趨勢具備敏銳的洞察力,該團隊致力于探索、設計、開發、推廣可落地的高性能云計算解決方案,幫助最終客戶加速數字化轉型,提升業務效能,同時降低運營成本。
審核編輯 黃宇
-
云計算
+關注
關注
39文章
8036瀏覽量
144667 -
存儲
+關注
關注
13文章
4853瀏覽量
90200 -
DPU
+關注
關注
0文章
415瀏覽量
27122 -
Ceph
+關注
關注
1文章
25瀏覽量
9699
發布評論請先 登錄
海康存儲亮相CFMS 2026 全場景解決方案賦能AI存儲新生態

慧榮科技于Embedded World 2026展示AI優化的啟動存儲與企業級解決方案

DRAM動態隨機存取存儲器DDR2 SDRAM內存解決方案
分布式數據恢復—Ceph+TiDB數據恢復報告


HighPoint與 ICY DOCK 達成合作,為專業計算提供高速靈活的 NVMe 存儲擴展解決方案
NVIDIA推出全新BlueField-4 DPU
芯盛智能自研存儲解決方案助力工業應用蓬勃發展
基于NVIDIA BlueField DPU的5G UPF數據面加速方案
Ceph集群部署與運維完全指南
K8s存儲類設計與Ceph集成實戰
Ceph分布式存儲系統解析
第三屆NVIDIA DPU黑客松開啟報名
芯啟源提供DPU產品與解決方案



 工商網監
工商網監
評論