 基于OpenCV的路面質量檢測
基于OpenCV的路面質量檢測

本期我們將展示一種對路面類型和質量進行分類的方法及其步驟。為了測試這種方法,我們使用了我們制作的RTK數據集。
該數據集[1]包含用低成本相機拍攝的圖像,以及新興國家常見的場景,其中包含未鋪砌的道路和坑洼。路面類型是有關人或自動駕駛車輛應如何駕駛的重要信息。除了乘客舒適度和車輛維護以外,它還涉及每個人的安全。我們可以通過[2]中的簡單卷積神經網絡(CNN)結構來實現。
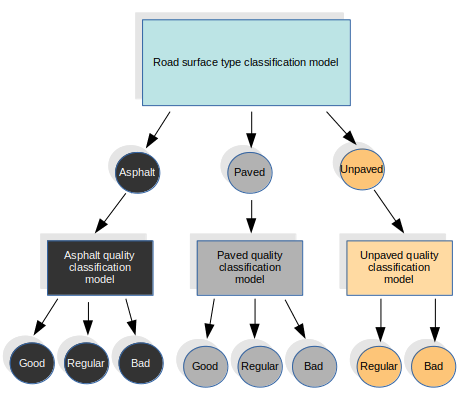
在這種方法中,我們對表面類型分類任務使用特定的模型,我們將其定義為以下類別:瀝青,已鋪設(用于所有其他類型的路面)和未鋪設。對于表面質量,我們使用其他三種不同的模型,每種類型的表面都使用一種。這四個模型都具有相同的結構。我們從第一個模型中得出結果,并稱為特定質量模型。
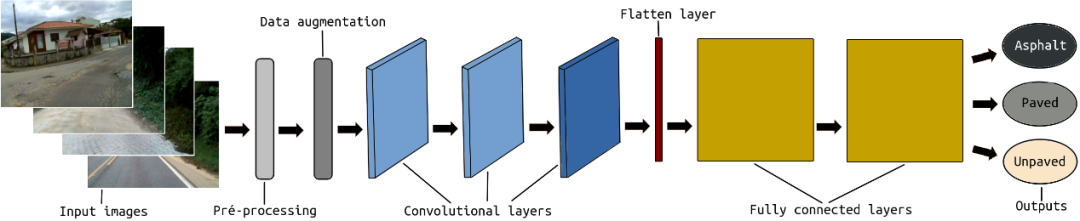
在CNN結構之前,將感興趣區域(ROI)定義為每個輸入幀的預處理步驟。畢竟,我們不需要整個圖像來對道路進行分類。ROI旨在僅保留圖像中實際包含道路像素的部分。圖像的上半部分以及圖像底部的一小部分都將被丟棄,因為在某些幀中,它可能包含負責捕獲圖像的部分車輛。ROI采用硬編碼,因為如果我們使用自適應ROI,它可能會導致失敗并損害模型訓練。
在此預處理之后執行數據擴充步驟。數據增強包括增加和減少每幀的亮度。這樣,我們可以改進訓練輸入集,并幫助我們的系統學習識別具有不同照明條件的相同類型和質量的道路。
最后,將輸入圖像傳遞到包含三個卷積層和兩個完全連接層的CNN結構。
01.RTK數據集
數據集包含具有不同類型的表面和質量的圖像。
02.路面類型分類
我們使用了Python,TensorFlow和OpenCV。
讓我們逐步分析一下…
首先,我們需要建立表面類型分類模型。為此,您將需要準備數據以訓練模型。您可以使用RTK數據集中的圖像或制作自己的圖像。圖像需要按地面道路類型進行組織。

訓練數據文件夾結構
在我們的實驗中,我們使用了6264幀:
l鋪砌(瀝青):4344,用于柏油馬路。
l鋪砌的(混凝土的):1337用于不同的人行道,例如鵝卵石。
l未鋪砌:585用于未鋪砌,土路,越野。
接下來,在train.py中,定義從何處收集訓練數據。我們應該將20%的數據分開以自動用于驗證。我們還定義了batch_size為32。
classes = os.listdir('training_data')
num_classes = len(classes)
batch_size = 32
validation_size = 0.2
img_size = 128
num_channels = 3
train_path='training_data'
在train.py上設置的參數將在dataset.py類上讀取。
data = dataset.read_train_sets(train_path, img_size, classes, validation_size=validation_size)
在dataset.py類中,我們定義了ROI和數據擴充。帶有數據解釋功能的兩個函數,Adjust_gamma可以降低亮度,而Adjust_gammaness可以提高亮度。
def adjust_gamma(image):
gamma = 0.5
invGamma = 1.0 / gamma
table = np.array([((i / 255.0) ** invGamma) * 255
for i in np.arange(0, 256)]).astype("uint8")
return cv2.LUT(image, table)
def increase_brightness(img, value):
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
lim = 255 - value
v[v > lim] = 255
v[v <= lim] += value
final_hsv = cv2.merge((h, s, v))
img = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2BGR)
return img
加載輸入數據時,將為每個圖像定義ROI。
for fields in classes:
index = classes.index(fields)
print('Now going to read {} files (Index: {})'.format(fields, index))
path = os.path.join(train_path, fields, '*g')
files = glob.glob(path)
for fl in files:
image = cv2.imread(fl)
# Region Of Interest (ROI)
height, width = image.shape[:2]
newHeight = int(round(height/2))
image = image[newHeight-5:height-50, 0:width]
brght_img = increase_brightness(image, value=150)
shaded_img = adjust_gamma(image)
image = cv2.resize(image, (image_size, image_size),0,0, cv2.INTER_LINEAR)
image = image.astype(np.float32)
image = np.multiply(image, 1.0 / 255.0)
brght_img = cv2.resize(brght_img, (image_size, image_size),0,0, cv2.INTER_LINEAR)
brght_img = brght_img.astype(np.float32)
brght_img = np.multiply(brght_img, 1.0 / 255.0)
shaded_img = cv2.resize(shaded_img, (image_size, image_size),0,0, cv2.INTER_LINEAR)
shaded_img = shaded_img.astype(np.float32)
shaded_img = np.multiply(brght_img, 1.0 / 255.0)
我們還會平衡輸入圖像,因為瀝青的圖像更多,而未鋪砌和未鋪砌的道路更少。
if index == 0: #asphalt
images.append(image)
images.append(brght_img)
images.append(shaded_img)
elif index == 1: #paved
for i in range(3):
images.append(image)
images.append(brght_img)
images.append(shaded_img)
elif index == 2: #unpaved
for i in range(6):
images.append(image)
images.append(brght_img)
images.append(shaded_img)
回到train.py,讓我們定義TensorFlow教程[2]中所示的CNN層。所有選擇到訓練步驟的圖像都將傳遞到第一卷積層,其中包含有關通道的寬度,高度和數量的信息。前兩層包含32個大小為3x3的濾鏡。緊接著是一個具有3x3大小的64個濾鏡的圖層。所有的步幅都定義為1,填充的定義為0。正態分布用于權重初始化。為了在尺寸上減少輸入,這有助于分析輸入子區域中的特征信息,在所有卷積層中應用了最大池。在每個卷積層的末尾,在最大合并功能之后,將ReLU用作激活功能。
def create_convolutional_layer(input, num_input_channels, conv_filter_size, num_filters): weights = create_weights(shape=[conv_filter_size, conv_filter_size, num_input_channels, num_filters]) biases = create_biases(num_filters) layer = tf.nn.conv2d(input=input, filter=weights, strides=[1, 1, 1, 1], padding='SAME') layer += biases layer = tf.nn.max_pool(value=layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') layer = tf.nn.relu(layer)
在卷積層之后,平坦層用于將卷積多維張量轉換為一維張量。
def create_flatten_layer(layer):
layer_shape = layer.get_shape()
num_features = layer_shape[1:4].num_elements()
layer = tf.reshape(layer, [-1, num_features])
return layer
最后添加兩個完全連接的層。在第一個完全連接的層中,應用了ReLU激活功能。第二個完全連接的層具有可能的輸出,所需的類別。
def create_fc_layer(input,
num_inputs,
num_outputs,
use_relu=True):
weights = create_weights(shape=[num_inputs, num_outputs])
biases = create_biases(num_outputs)
layer = tf.matmul(input, weights) + biases
if use_relu:
layer = tf.nn.relu(layer)
return layer
我們使用softmax函數來實現每個類的概率。最后,我們還使用Adam優化器,該優化器根據訓練中使用的輸入數據更新網絡權重。
layer_conv1 = create_convolutional_layer(input=x,
num_input_channels=num_channels,
conv_filter_size=filter_size_conv1,
num_filters=num_filters_conv1)
layer_conv2 = create_convolutional_layer(input=layer_conv1,
num_input_channels=num_filters_conv1,
conv_filter_size=filter_size_conv2,
num_filters=num_filters_conv2)
layer_conv3= create_convolutional_layer(input=layer_conv2,
num_input_channels=num_filters_conv2,
conv_filter_size=filter_size_conv3,
num_filters=num_filters_conv3)
layer_flat = create_flatten_layer(layer_conv3)
layer_fc1 = create_fc_layer(input=layer_flat,
num_inputs=layer_flat.get_shape()[1:4].num_elements(),
num_outputs=fc_layer_size,
use_relu=True)
layer_fc2 = create_fc_layer(input=layer_fc1,
num_inputs=fc_layer_size,
num_outputs=num_classes,
use_relu=False)
y_pred = tf.nn.softmax(layer_fc2,name='y_pred')
y_pred_cls = tf.argmax(y_pred, dimension=1)
session.run(tf.global_variables_initializer())
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=layer_fc2,
labels=y_true)
cost = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost)
correct_prediction = tf.equal(y_pred_cls, y_true_cls)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
可以python train.py在終端中訓練模型的運行:
現在,有了經過訓練的模型,我們就可以測試。首先,讓我們準備好接收輸入測試幀和輸出文件名。
outputFile = sys.argv[2]
# Opening frames
cap = cv.VideoCapture(sys.argv[1])
vid_writer = cv.VideoWriter(outputFile, cv.VideoWriter_fourcc('M','J','P','G'), 15, (round(cap.get(cv.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv.CAP_PROP_FRAME_HEIGHT))))
檢索訓練好的模型并訪問圖形。
sess = tf.Session()
saver = tf.train.import_meta_graph('roadsurface-model.meta')
saver.restore(sess, tf.train.latest_checkpoint('./'))
graph = tf.get_default_graph()
y_pred = graph.get_tensor_by_name("y_pred:0")
x = graph.get_tensor_by_name("x:0")
y_true = graph.get_tensor_by_name("y_true:0")
y_test_images = np.zeros((1, len(os.listdir('training_data'))))
請記住,我們不需要整個圖像,我們的培訓著重于使用ROI,在這里我們也使用它。
width = int(round(cap.get(cv.CAP_PROP_FRAME_WIDTH)))
height = int(round(cap.get(cv.CAP_PROP_FRAME_HEIGHT)))
newHeight = int(round(height/2))
while cv.waitKey(1) < 0:
hasFrame, images = cap.read()
finalimg = images
images = images[newHeight-5:height-50, 0:width]
images = cv.resize(images, (image_size, image_size), 0, 0, cv.INTER_LINEAR)
images = np.array(images, dtype=np.uint8)
images = images.astype('float32')
images = np.multiply(images, 1.0/255.0)
最后,基于輸出預測,我們可以在每幀中打印分類的表面類型。
x_batch = images.reshape(1, image_size, image_size, num_channels)
feed_dict_testing = {x: x_batch, y_true: y_test_images}
result = sess.run(y_pred, feed_dict=feed_dict_testing)
outputs = [result[0,0], result[0,1], result[0,2]]
value = max(outputs)
index = np.argmax(outputs)
if index == 0:
label = 'Asphalt'
prob = str("{0:.2f}".format(value))
color = (0, 0, 0)
elif index == 1:
label = 'Paved'
prob = str("{0:.2f}".format(value))
color = (153, 102, 102)
elif index == 2:
label = 'Unpaved'
prob = str("{0:.2f}".format(value))
color = (0, 153, 255)
cv.rectangle(finalimg, (0, 0), (145, 40), (255, 255, 255), cv.FILLED)
cv.putText(finalimg, 'Class: ', (5,15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1)
cv.putText(finalimg, label, (70,15), cv.FONT_HERSHEY_SIMPLEX, 0.5, color, 1)
cv.putText(finalimg, prob, (5,35), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1)
vid_writer.write(finalimg.astype(np.uint8))
可以測試在終端中運行的模型:python test.py PATH_TO_YOUR_FRAMES_SEQUENCE NAME_YOUR_VIDEO_FILE.avi。
03.路面質量分類
現在讓我們包括質量分類。我們僅使用用于訓練表面類型分類模型的相同CNN架構,并分別在每個表面類別上應用每個質量類別。因此,除了現有模型外,我們還培訓了3種新模型。為此,大家將需要準備用于訓練每個表面類別的模型的數據。在RTK數據集頁面中,我們已經給出了按班級組織的框架。
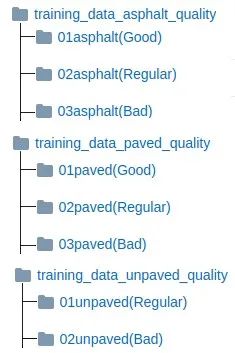
用于質量課程的培訓數據文件夾結構
要訓練每種模型,小伙伴們可以在終端中運行:
python trainAsphaltQuality.py python trainPavedQuality.py python trainUnpavedQuality.py
現在,預測部分發生了什么變化。我們使用四個不同的圖,每個訓練模型一個。
graph = tf.Graph() graphAQ = tf.Graph() graphPQ = tf.Graph() graphUQ = tf.Graph()
04.模型恢復
恢復類型模型
with graph.as_default():
saver = tf.train.import_meta_graph('roadsurfaceType-model.meta')
y_pred = graph.get_tensor_by_name("y_pred:0")
x = graph.get_tensor_by_name("x:0")
y_true = graph.get_tensor_by_name("y_true:0")
y_test_images = np.zeros((1, len(os.listdir('training_data_type'))))
sess = tf.Session(graph = graph)
saver.restore(sess, tf.train.latest_checkpoint('typeCheckpoint/'))
恢復瀝青質量模型
with graphAQ.as_default():
saverAQ = tf.train.import_meta_graph('roadsurfaceAsphaltQuality-model.meta')
y_predAQ = graphAQ.get_tensor_by_name("y_pred:0")
xAQ = graphAQ.get_tensor_by_name("x:0")
y_trueAQ = graphAQ.get_tensor_by_name("y_true:0")
y_test_imagesAQ = np.zeros((1, len(os.listdir('training_data_asphalt_quality'))))
sessAQ = tf.Session(graph = graphAQ)
saverAQ.restore(sessAQ, tf.train.latest_checkpoint('asphaltCheckpoint/'))
恢復鋪砌的質量模型
with graphPQ.as_default():
saverPQ = tf.train.import_meta_graph('roadsurfacePavedQuality-model.meta')
y_predPQ = graphPQ.get_tensor_by_name("y_pred:0")
xPQ = graphPQ.get_tensor_by_name("x:0")
y_truePQ = graphPQ.get_tensor_by_name("y_true:0")
y_test_imagesPQ = np.zeros((1, len(os.listdir('training_data_paved_quality'))))
sessPQ = tf.Session(graph = graphPQ)
saverPQ.restore(sessPQ, tf.train.latest_checkpoint('pavedCheckpoint/'))
恢復未鋪砌的質量模型
with graphUQ.as_default():
saverUQ = tf.train.import_meta_graph('roadsurfaceUnpavedQuality-model.meta')
y_predUQ = graphUQ.get_tensor_by_name("y_pred:0")
xUQ = graphUQ.get_tensor_by_name("x:0")
y_trueUQ = graphUQ.get_tensor_by_name("y_true:0")
y_test_imagesUQ = np.zeros((1, len(os.listdir('training_data_unpaved_quality'))))
sessUQ = tf.Session(graph = graphUQ)
saverUQ.restore(sessUQ, tf.train.latest_checkpoint('unpavedCheckpoint/'))
此時,輸出預測也要考慮質量模型,我們可以在每個幀中打印分類的表面類型以及該表面的質量。
if index == 0: #Asphalt
label = 'Asphalt'
prob = str("{0:.2f}".format(value))
color = (0, 0, 0)
x_batchAQ = images.reshape(1, image_size, image_size, num_channels)
feed_dict_testingAQ = {xAQ: x_batchAQ, y_trueAQ: y_test_imagesAQ}
resultAQ = sessAQ.run(y_predAQ, feed_dict=feed_dict_testingAQ)
outputsQ = [resultAQ[0,0], resultAQ[0,1], resultAQ[0,2]]
valueQ = max(outputsQ)
indexQ = np.argmax(outputsQ)
if indexQ == 0: #Asphalt - Good
quality = 'Good'
colorQ = (0, 255, 0)
probQ = str("{0:.2f}".format(valueQ))
elif indexQ == 1: #Asphalt - Regular
quality = 'Regular'
colorQ = (0, 204, 255)
probQ = str("{0:.2f}".format(valueQ))
elif indexQ == 2: #Asphalt - Bad
quality = 'Bad'
colorQ = (0, 0, 255)
probQ = str("{0:.2f}".format(valueQ))
elif index == 1: #Paved
label = 'Paved'
prob = str("{0:.2f}".format(value))
color = (153, 102, 102)
x_batchPQ = images.reshape(1, image_size, image_size, num_channels)
feed_dict_testingPQ = {xPQ: x_batchPQ, y_truePQ: y_test_imagesPQ}
resultPQ = sessPQ.run(y_predPQ, feed_dict=feed_dict_testingPQ)
outputsQ = [resultPQ[0,0], resultPQ[0,1], resultPQ[0,2]]
valueQ = max(outputsQ)
indexQ = np.argmax(outputsQ)
if indexQ == 0: #Paved - Good
quality = 'Good'
colorQ = (0, 255, 0)
probQ = str("{0:.2f}".format(valueQ))
elif indexQ == 1: #Paved - Regular
quality = 'Regular'
colorQ = (0, 204, 255)
probQ = str("{0:.2f}".format(valueQ))
elif indexQ == 2: #Paved - Bad
quality = 'Bad'
colorQ = (0, 0, 255)
probQ = str("{0:.2f}".format(valueQ))
elif index == 2: #Unpaved
label = 'Unpaved'
prob = str("{0:.2f}".format(value))
color = (0, 153, 255)
x_batchUQ = images.reshape(1, image_size, image_size, num_channels)
feed_dict_testingUQ = {xUQ: x_batchUQ, y_trueUQ: y_test_imagesUQ}
resultUQ = sessUQ.run(y_predUQ, feed_dict=feed_dict_testingUQ)
outputsQ = [resultUQ[0,0], resultUQ[0,1]]
valueQ = max(outputsQ)
indexQ = np.argmax(outputsQ)
if indexQ == 0: #Unpaved - Regular
quality = 'Regular'
colorQ = (0, 204, 255)
probQ = str("{0:.2f}".format(valueQ))
elif indexQ == 1: #Unpaved - Bad
quality = 'Bad'
colorQ = (0, 0, 255)
probQ = str("{0:.2f}".format(valueQ))
打印結果
cv.rectangle(finalimg, (0, 0), (145, 80), (255, 255, 255), cv.FILLED) cv.putText(finalimg, 'Class: ', (5,15), cv.FONT_HERSHEY_DUPLEX, 0.5, (0,0,0)) cv.putText(finalimg, label, (70,15), cv.FONT_HERSHEY_DUPLEX, 0.5, color) cv.putText(finalimg, prob, (5,35), cv.FONT_HERSHEY_DUPLEX, 0.5, (0,0,0)) cv.putText(finalimg, 'Quality: ', (5,55), cv.FONT_HERSHEY_DUPLEX, 0.5, (0,0,0)) cv.putText(finalimg, quality, (70,55), cv.FONT_HERSHEY_DUPLEX, 0.5, colorQ) cv.putText(finalimg, probQ, (5,75), cv.FONT_HERSHEY_DUPLEX, 0.5, (0,0,0))
大家可以在終端中測試運行情況:python testRTK.py PATH_TO_YOUR_FRAMES_SEQUENCE NAME_YOUR_VIDEO_FILE.avi。
審核編輯:黃飛
-
OpenCV
+關注
關注
33文章
652瀏覽量
44799 -
cnn
+關注
關注
3文章
355瀏覽量
23422
原文標題:基于OpenCV的路面質量檢測
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在OpenCV中使用基于深度學習的邊緣檢測?

如何使用Python中的OpenCV模塊檢測顏色
如何使用Python OpenCV進行面部標志檢測

OpenCV中支持的非分類與檢測視覺模型

路面壓實度實時監測系統與傳統檢測方法分析

路面攤鋪壓實施工質量管理系統推進路面智慧工地監測
基于機器視覺的公路路面檢測

路面智能攤鋪壓實管理系統通過先進的技術手段提升了路面施工質量

從暴雨到積水,地埋式路面檢測儀實時掌握路面情況

智能路面施工質量智能管理系統對路面施工工藝進行過程監督管理描述

公路路面裂縫病害檢測




 工商網監
工商網監
評論