 NeurIPS23|視覺 「讀腦術」:從大腦活動中重建你眼中的世界
NeurIPS23|視覺 「讀腦術」:從大腦活動中重建你眼中的世界

在這篇 NeurIPS23 論文中,來自魯汶大學、新加坡國立大學和中科院自動化所的研究者提出了一種視覺 「讀腦術」,能夠從人類的大腦活動中以高分辨率出解析出人眼觀看到的圖像。
人類的感知不僅由客觀刺激塑造,而且深受過往經驗的影響,這些共同促成了大腦中的復雜活動。在認知神經科學領域,解碼大腦活動中的視覺信息成為了一項關鍵任務。功能性磁共振成像(fMRI)作為一種高效的非侵入性技術,在恢復和分析視覺信息,如圖像類別方面發揮著重要作用。
然而,由于 fMRI 信號的噪聲特性和大腦視覺表征的復雜性,這一任務面臨著不小的挑戰。針對這一問題,本文提出了一個雙階段 fMRI 表征學習框架,旨在識別并去除大腦活動中的噪聲,并專注于解析對視覺重建至關重要的神經激活模式,成功從大腦活動中重建出高分辨率且語義上準確的圖像。

論文鏈接:https://arxiv.org/abs/2305.17214
項目鏈接:https://github.com/soinx0629/vis_dec_neurips/
論文中提出的方法基于雙重對比學習、跨模態信息交叉及擴散模型,在相關 fMRI 數據集上取得了相對于以往最好模型接近 40% 的評測指標提升,在生成圖像的質量、可讀性及語義相關性相對于已有方法均有肉眼可感知的提升。該工作有助于理解人腦的視覺感知機制,有益于推動視覺的腦機接口技術的研究。相關代碼均已開源。
功能性磁共振成像(fMRI)雖廣泛用于解析神經反應,但從其數據中準確重建視覺圖像仍具挑戰,主要因為 fMRI 數據包含多種來源的噪聲,這些噪聲可能掩蓋神經激活模式,增加解碼難度。此外,視覺刺激引發的神經反應過程復雜多階段,使得 fMRI 信號呈現非線性的復雜疊加,難以逆轉并解碼。
傳統的神經解碼方式,例如嶺回歸,盡管被用于將 fMRI 信號與相應刺激關聯,卻常常無法有效捕捉刺激和神經反應之間的非線性關系。近期,深度學習技術,如生成對抗網絡(GAN)和潛在擴散模型(LDMs),已被采用以更準確地建模這種復雜關系。然而,將視覺相關的大腦活動從噪聲中分離出來,并準確進行解碼,依然是該領域的主要挑戰之一。
為了應對這些挑戰,該工作提出了一個雙階段 fMRI 表征學習框架,該方法能夠有效識別并去除大腦活動中的噪聲,并專注于解析對視覺重建至關重要的神經激活模式。該方法在生成高分辨率及語義準確的圖像方面,其 50 分類的 Top-1 準確率超過現有最先進技術 39.34%。
方法概述
fMRI 表征學習 (FRL)
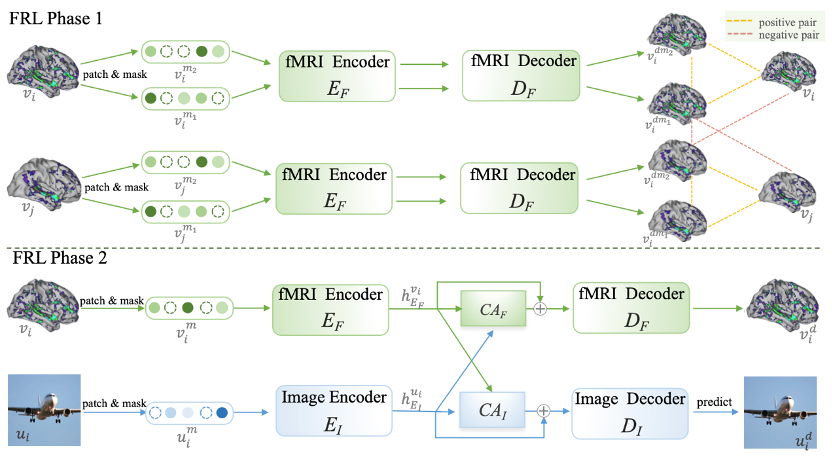
為了在不同人群中區分共有的大腦活動模式和個體噪聲,本文引入了 DC-MAE 技術,利用未標記數據對 fMRI 表征進行預訓練。DC-MAE 包含一個編碼器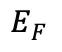 和一個解碼器
和一個解碼器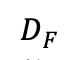 ,其中以遮蔽的 fMRI 信號為輸入,?則被訓練以預測未遮蔽的 fMRI 信號。所謂的 “雙重對比” 是指模型在 fMRI 表征學習中優化對比損失并參與了兩個不同的對比過程。
,其中以遮蔽的 fMRI 信號為輸入,?則被訓練以預測未遮蔽的 fMRI 信號。所謂的 “雙重對比” 是指模型在 fMRI 表征學習中優化對比損失并參與了兩個不同的對比過程。
在第一階段的對比學習中,每個包含 n 個 fMRI 樣本 v 的批次中的樣本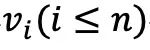 被隨機遮蔽兩次,生成兩個不同的遮蔽版本
被隨機遮蔽兩次,生成兩個不同的遮蔽版本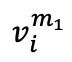 和
和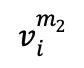 ,作為對比的正樣本對。隨后,1D 卷積層將這兩個版本轉換為嵌入式表示,分別輸入至 fMRI 編碼器。解碼器?接收這些編碼的潛在表示,產生預測值
,作為對比的正樣本對。隨后,1D 卷積層將這兩個版本轉換為嵌入式表示,分別輸入至 fMRI 編碼器。解碼器?接收這些編碼的潛在表示,產生預測值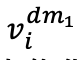 和
和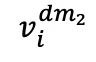 。通過 InfoNCE 損失函數計算的第一次對比損失,即交叉對比損失,來優化模型:
。通過 InfoNCE 損失函數計算的第一次對比損失,即交叉對比損失,來優化模型:
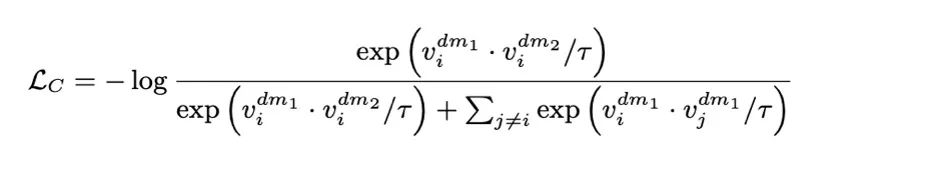
在第二階段對比學習中,每個未遮蔽的原始圖像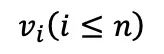 及其相應的遮蔽圖像
及其相應的遮蔽圖像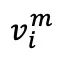 形成一對天然正樣本。這里的
形成一對天然正樣本。這里的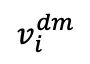 代表解碼器預測出的圖像。第二次對比損失,也就是自對比損失,根據以下公式進行計算:
代表解碼器預測出的圖像。第二次對比損失,也就是自對比損失,根據以下公式進行計算:
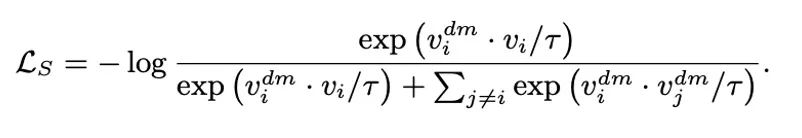
優化自對比損失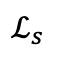 能夠實現遮蔽重建。無論是
能夠實現遮蔽重建。無論是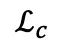 還是,負樣本
還是,負樣本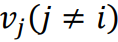 都來自同一批次的實例。和共同按如下方式優化:
都來自同一批次的實例。和共同按如下方式優化: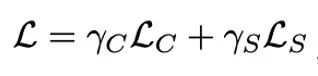 ,其中超參數
,其中超參數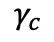 和
和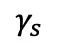 用于調節各損失項的權重。
用于調節各損失項的權重。
-
第二階段:使用跨模態指導進行調整
考慮到 fMRI 記錄的信噪比較低且高度卷積的特性,專注于與視覺處理最相關且對重建最有信息價值的大腦激活模式對 fMRI 特征學習器來說至關重要。
在第一階段預訓練后,fMRI 自編碼器通過圖像輔助進行調整,以實現 fMRI 的重建,第二階段同樣遵循此過程。具體而言,從 n 個樣本批次中選擇一個樣本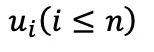 及其對應的 fMRI 記錄的神經反應
及其對應的 fMRI 記錄的神經反應 。
。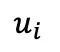 和經過分塊和隨機遮蔽處理,分別轉變為
和經過分塊和隨機遮蔽處理,分別轉變為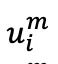 和,然后分別輸入到圖像編碼器
和,然后分別輸入到圖像編碼器 和 fMRI 編碼器中,生成
和 fMRI 編碼器中,生成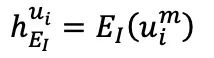 和
和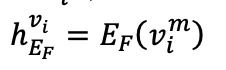 。為重建 fMRI,利用交叉注意力模塊將
。為重建 fMRI,利用交叉注意力模塊將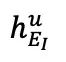 和
和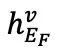 進行合并:
進行合并:
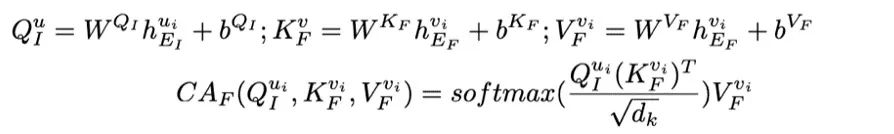
W 和 b 分別代表相應線性層的權重和偏置。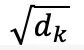 是縮放因子,
是縮放因子,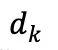 是鍵向量的維度。CA 是交叉注意力(cross-attention)的縮寫。
是鍵向量的維度。CA 是交叉注意力(cross-attention)的縮寫。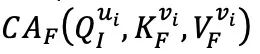 加上后,輸入到 fMRI 解碼器中以重建,得到
加上后,輸入到 fMRI 解碼器中以重建,得到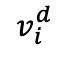 :
:
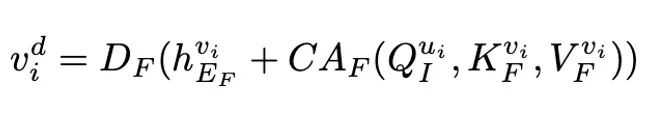
圖像自編碼器中也進行了類似的計算,圖像編碼器的輸出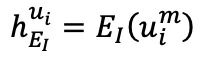 通過交叉注意力模塊
通過交叉注意力模塊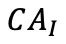 與的輸出合并,然后用于解碼圖像,得到
與的輸出合并,然后用于解碼圖像,得到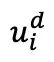 :
:
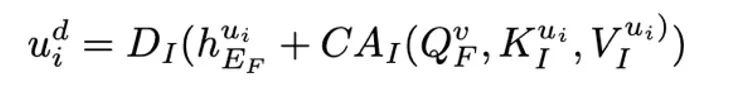
通過優化以下損失函數,fMRI 和圖像自編碼器共同進行訓練:
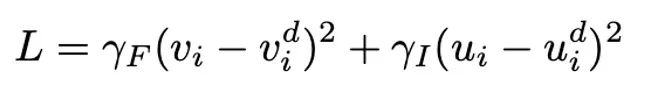
使用潛在擴散模型 (LDM) 生成圖像
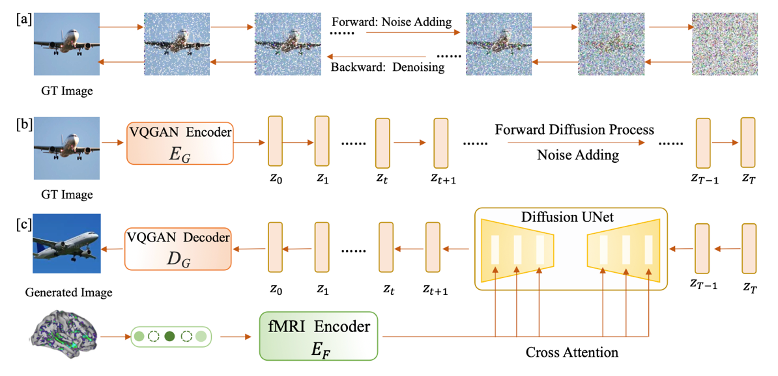
在完成 FRL 第一階段和第二階段的訓練后,使用 fMRI 特征學習器的編碼器來驅動一個潛在擴散模型(LDM),從大腦活動生成圖像。如圖所示,擴散模型包括一個向前的擴散過程和一個逆向去噪過程。向前過程逐漸將圖像降解為正態高斯噪聲,通過逐漸引入變方差的高斯噪聲。
該研究通過從預訓練的標簽至圖像潛在擴散模型(LDM)中提取視覺知識,并利用 fMRI 數據作為條件生成圖像。這里采用交叉注意力機制,將 fMRI 信息融入 LDM,遵循穩定擴散研究的建議。為了強化條件信息的作用,這里采用了交叉注意力和時間步條件化的方法。在訓練階段,使用 VQGAN 編碼器 和經 FRL 第一和第二階段訓練的 fMRI 編碼器處理圖像 u 和 fMRI v,并在保持 LDM 不變的情況下微調 fMRI 編碼器,損失函數為:
和經 FRL 第一和第二階段訓練的 fMRI 編碼器處理圖像 u 和 fMRI v,并在保持 LDM 不變的情況下微調 fMRI 編碼器,損失函數為:
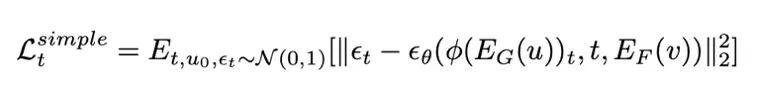
其中,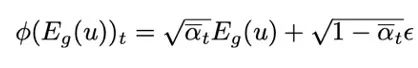 是擴散模型的噪聲計劃。在推理階段,過程從時間步長 T 的標準高斯噪聲開始,LDM 依次遵循逆向過程逐步去除隱藏表征的噪聲,條件化在給定的 fMRI 信息上。當到達時間步長零時,使用 VQGAN 解碼器
是擴散模型的噪聲計劃。在推理階段,過程從時間步長 T 的標準高斯噪聲開始,LDM 依次遵循逆向過程逐步去除隱藏表征的噪聲,條件化在給定的 fMRI 信息上。當到達時間步長零時,使用 VQGAN 解碼器 將隱藏表征轉換為圖像。
將隱藏表征轉換為圖像。
實驗
重建結果

通過與 DC-LDM、IC-GAN 和 SS-AE 等先前研究的對比,并在 GOD 和 BOLD5000 數據集上的評估中顯示,該研究提出的模型在準確率上顯著超過這些模型,其中相對于 DC-LDM 和 IC-GAN 分別提高了 39.34% 和 66.7%
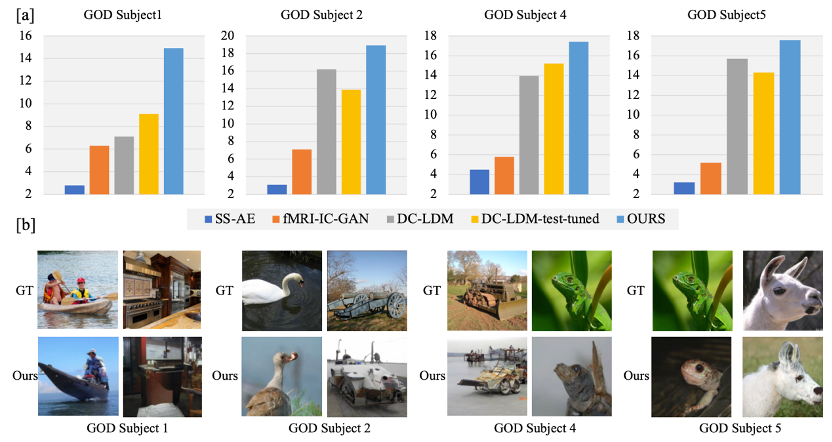
在 GOD 數據集的其他四名受試者上的評估顯示,即使在允許 DC-LDM 在測試集上進行調整的情況下,該研究提出的模型在 50 種方式的 Top-1 分類準確率上也顯著優于 DC-LDM,證明了提出的模型在不同受試者大腦活動重建方面的可靠性和優越性。
實驗結果表明,利用所提出的 fMRI 表示學習框架和預先訓練的 LDM,可以更好的重建大腦的視覺活動,大大優于目前的基線。該工作有助于進一步挖掘神經解碼模型的潛力。
原文標題:NeurIPS23|視覺 「讀腦術」:從大腦活動中重建你眼中的世界
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
-
物聯網
+關注
關注
2945文章
47820瀏覽量
414908
原文標題:NeurIPS23|視覺 「讀腦術」:從大腦活動中重建你眼中的世界
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【匠師共研】系列之一 器件賦能系統,打通從生物大腦到新型半導體器件應用新途

泰克專家探討類腦計算背后的器件邏輯與現實挑戰
高隱蔽性的柔性耳周腦電采集系統優勢幾何?

地平線五篇論文入選NeurIPS 2025與AAAI 2026

網絡接口:數字世界的“門鈴”,你了解多少?
激光焊接技術在焊接腦機接口工藝中的應用

腦機接口:運動康復與神經康復的創新突破
僅使用智能手機在NVIDIA Isaac Sim中重建場景
時域干涉電刺激tTIS可持續增強運動皮層活動?
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+神經形態計算、類腦芯片
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+可期之變:從AI硬件到AI濕件
中國植入式腦機接口取得新突破
【書籍評測活動NO.64】AI芯片,從過去走向未來:《AI芯片:科技探索與AGI愿景》
具身智能×邊緣計算:AI的“大腦”和“身體”如何聯手闖蕩世界?

腦電基礎系列之腦電電極的分類與技術對比



 工商網監
工商網監
評論