") 華為智能駕駛芯片深度分析
華為智能駕駛芯片深度分析

華為智能汽車部門IntelligentAutomotive Solutions(IAS)下設(shè)包括提供應(yīng)用算法的AutonomousDriving Solution (ADS)部門、提供域控制器的Mobile Data Center(MDC)和提供傳感器系統(tǒng)的集成感知事業(yè)部。其中,ADS負(fù)責(zé)算法研究,下分很多小組,分得特別精細(xì),比如有Obstacle Detection Team障礙物探測、Prediction and Decision預(yù)測與決策;MDC類似于Tier1,前身為中央計(jì)算部門,主要為華為ARM服務(wù)器業(yè)務(wù)提供硬件。華為智能駕駛使用的芯片由海思提供,華為ARM服務(wù)器芯片也由海思提供,智能駕駛和ARM服務(wù)器芯片共用大部分研發(fā)成果。
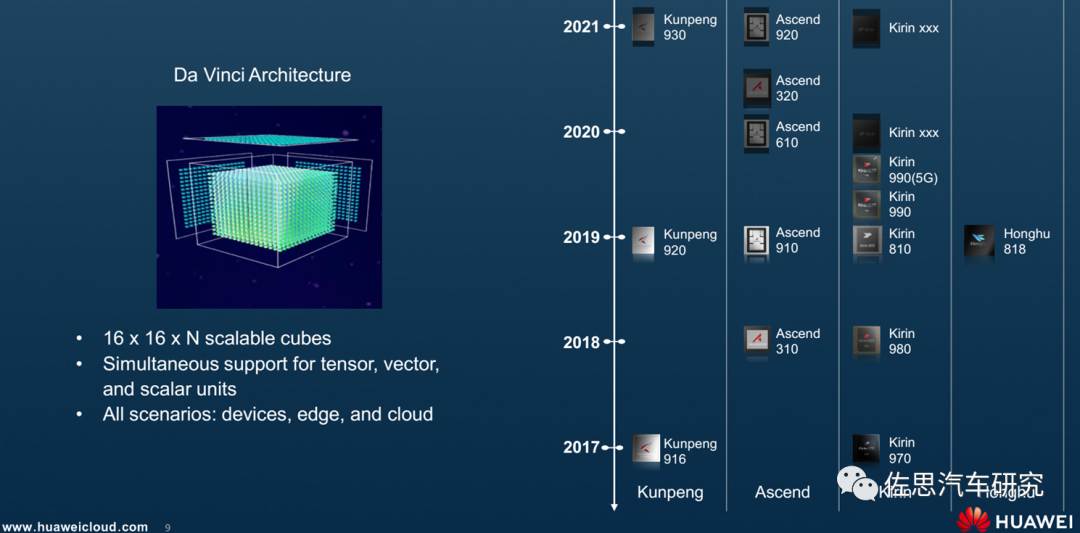
華為海思AI產(chǎn)品線規(guī)劃路線圖
圖片來源:https://ggim.un.org/meetings/2019/Deqing/documents/1-3%20Huawei%20slides.pdf
海思AI產(chǎn)品線規(guī)劃有四條,分別為鯤鵬、昇騰、麒麟和鴻鵠。其中,鯤鵬系列主要是CPU,昇騰是AI加速器,麒麟主要是針對手機(jī),鴻鵠針對電視。智能駕駛是昇騰產(chǎn)品線的延伸。此外基于麒麟990的麒麟990A則是華為汽車座艙芯片。
華為智能駕駛芯片主要有昇騰310、昇騰610和昇騰620,這三款芯片還可以級聯(lián)增加性能。https://www-file.huawei.com/-/media/corp2020/pdf/publications/huawei-research/2022/huawei-research-issue1-en.pdf,這個(gè)文檔里有華為昇騰系列芯片的詳細(xì)解釋,本文主要資料來源就是這個(gè)文檔。
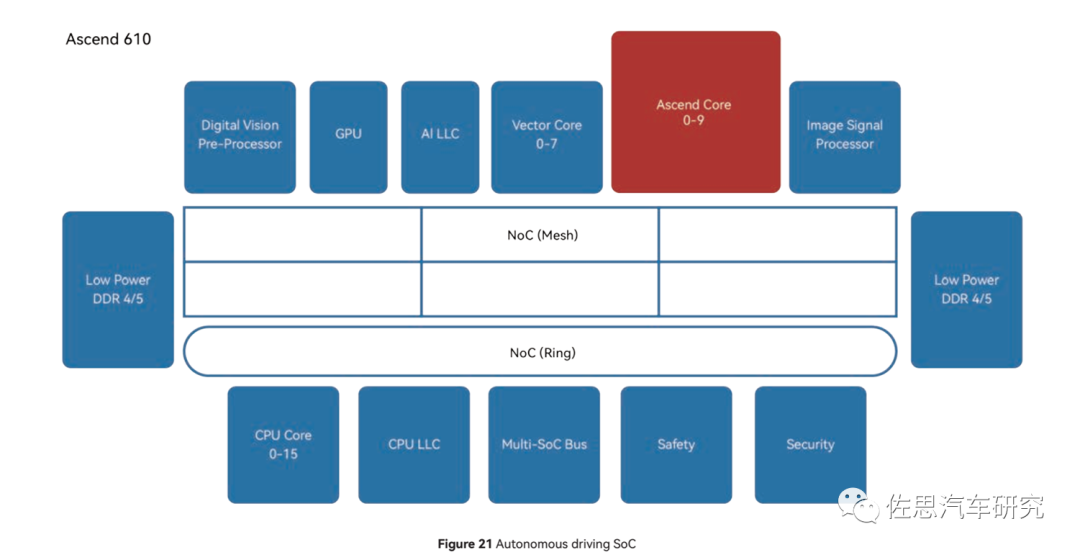
昇騰610的內(nèi)部框架圖
圖片來源:華為
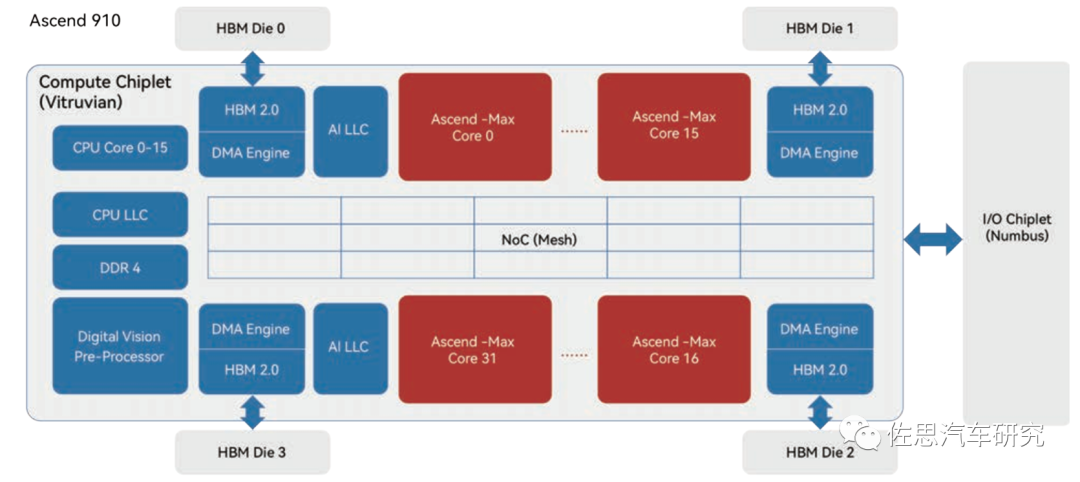
昇騰910內(nèi)部框架圖
圖片來源:華為
華為設(shè)計(jì)芯片是模塊形式,盡量復(fù)用研發(fā)成果,昇騰系列芯片的CPU和AI核心基本是相同的,只是核心數(shù)量不同。
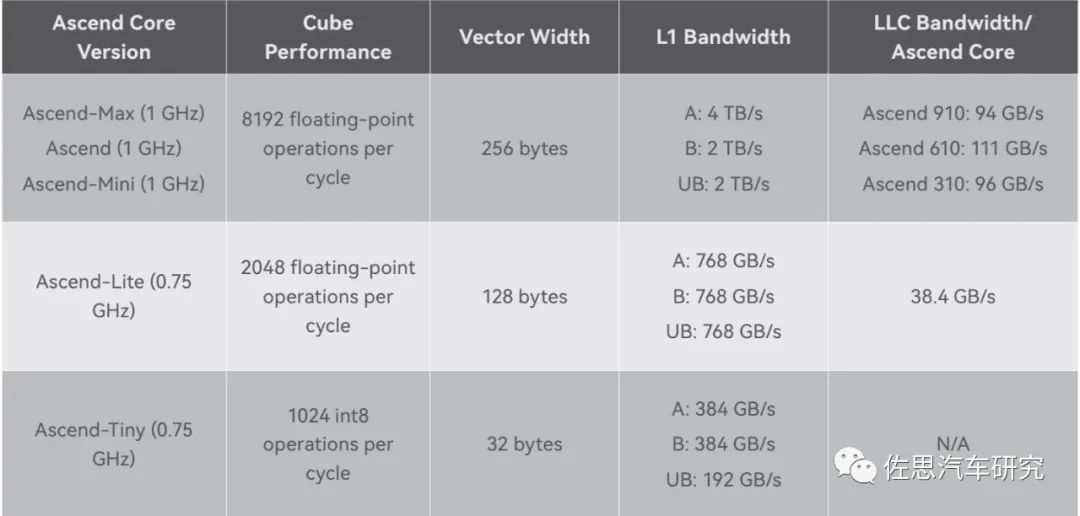
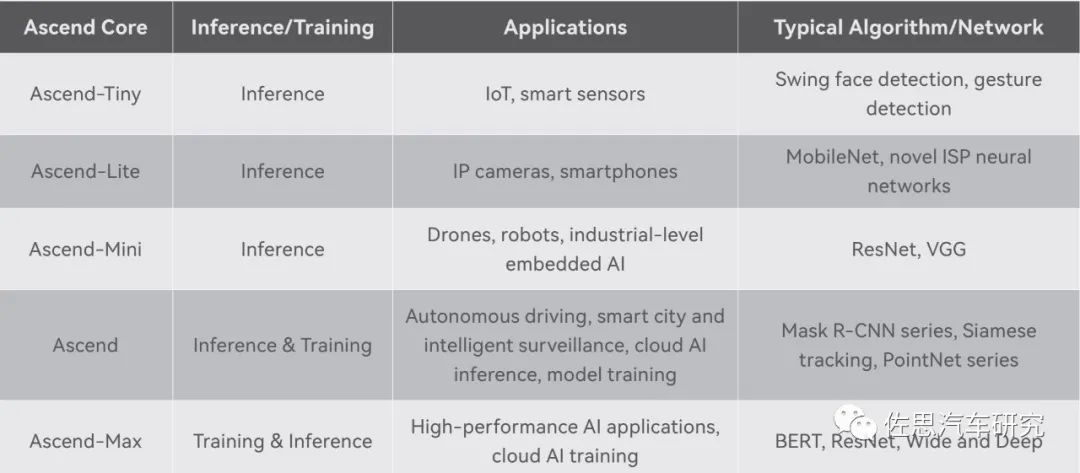
華為昇騰核心特性一覽表
圖片來源:華為
昇騰核心即AI核,分原始、Max、Mini、Lite、Tiny幾個(gè)版本,針對不同的應(yīng)用使用不同的核心和數(shù)量配置,如針對手機(jī)領(lǐng)域的麒麟990,是兩個(gè)Lite和一個(gè)Tiny核心,三個(gè)加起來是6.88TOPS@INT8算力。昇騰310則是兩個(gè)Mini核心,昇騰610則是10個(gè)原始核心,昇騰910是32個(gè)Max核心。昇騰620可能是10個(gè)Max核心。每個(gè)核心基本是相同的,主要是緩存配置和頻率配置不同。
不同的核心對應(yīng)不同的算法網(wǎng)絡(luò)
圖片來源:華為
昇騰Max核心內(nèi)部框架
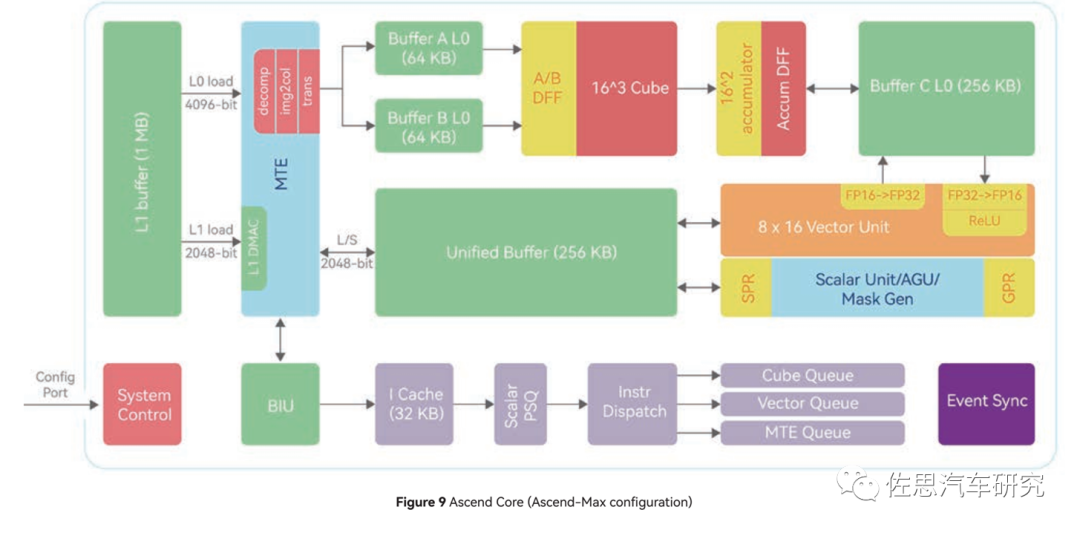
圖片來源:華為
上圖為Max核心內(nèi)部框架,主要包括標(biāo)量Scalar、矢量Vector和張量Tensor三個(gè)運(yùn)算單元。標(biāo)量單元負(fù)責(zé)任務(wù)調(diào)度,矢量單元負(fù)責(zé)深度學(xué)習(xí)最后的激活階段,張量負(fù)責(zé)卷積矩陣乘法。
三種運(yùn)算單元的計(jì)算模式
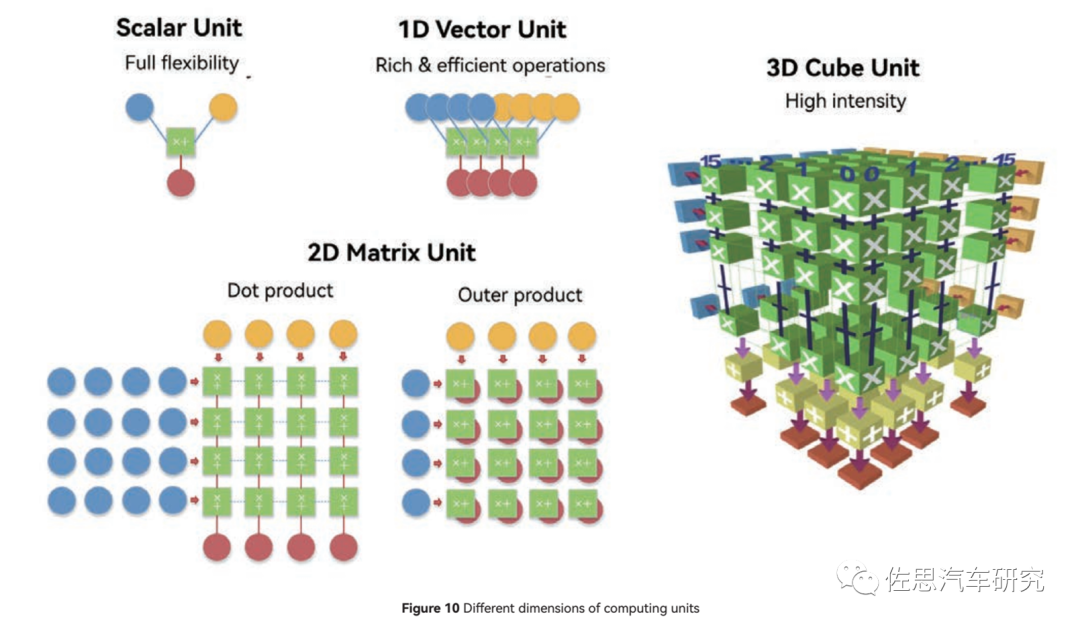
圖片來源:華為
標(biāo)量基本近似CPU,靈活性最高,但針對AI運(yùn)算力最低。1D矢量近似于GPU,靈活性居中,AI算力中等,CUBE針對2D矩陣,也就是一般意義上的張量。
如果按照嚴(yán)格數(shù)學(xué)的定義,那么矢量是一階張量,矩陣是二階張量,CUBE核跟英偉達(dá)的所謂張量核Tensor基本一致。
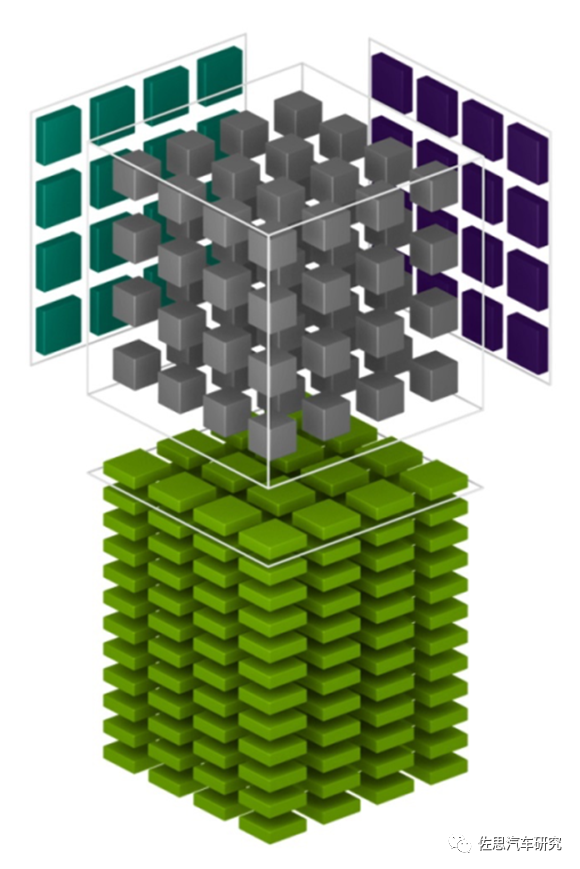
英偉達(dá)自Turing架構(gòu)開始用的張量核架構(gòu)和華為的CUBE基本一致,都是三維架構(gòu)。
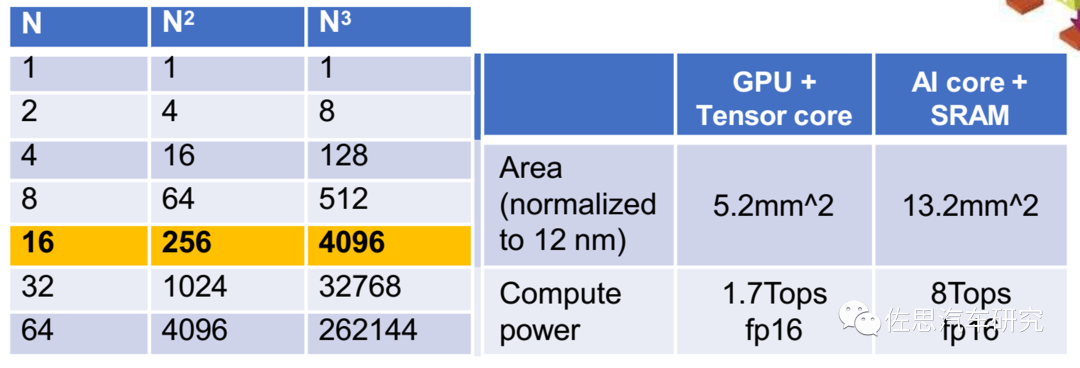
三種運(yùn)算核心的對比
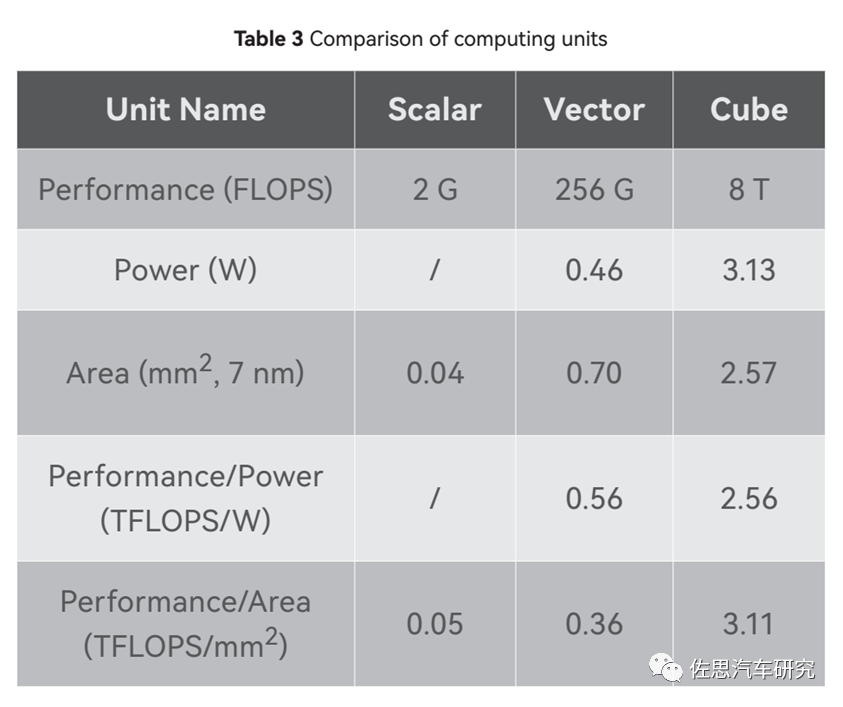
圖片來源:華為
一個(gè)CUBE核是8TOPS@FP16的算力,注意是FP16不是常見的INT8,車載領(lǐng)域一般是INT8。一個(gè)CUBE內(nèi)部包含4096個(gè)FP16 MACs,8192個(gè)INT8 MACs,而一個(gè)MAC是包含兩個(gè)Ops,因此如果運(yùn)行頻率是1GHz,那FP16算力就是1G*2*4096=8T。
同樣,谷歌的TPU V1是65000個(gè)FP16 MAC,運(yùn)行頻率0.7GHz,那么算力就是65000*0.7G*2=91T。特斯拉第一代FSD兩個(gè)NPU,每個(gè)NPU是9216個(gè)INT8 MAC,運(yùn)行頻率是2GHz,算力就是2*2*2G*9216=73TOPS。所謂算力基本就是MAC數(shù)量的堆砌,堆的越多,算力越高,面積也越大,成本就越高。
算力這個(gè)數(shù)字不用較真。
幾個(gè)手機(jī)芯片的AI算力對比
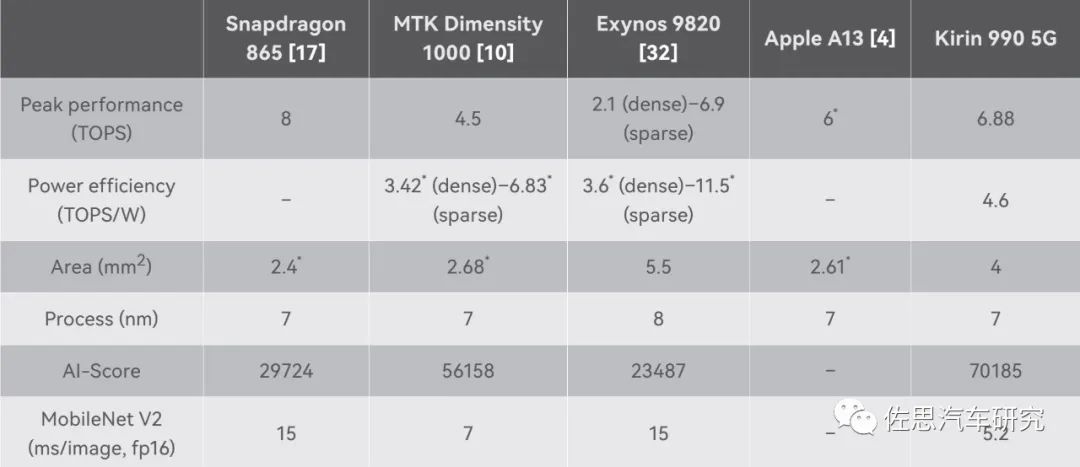
來源:華為
高通驍龍865標(biāo)稱最高,有8TOPS,但AI得分很低,遠(yuǎn)低于4.5TOPS的聯(lián)發(fā)科天璣1000,更低于華為的麒麟990,顯然高通的水分很大,聯(lián)發(fā)科則太老實(shí)了,標(biāo)稱比實(shí)際低了至少1TOPS。
華為在2019年在IEEE上發(fā)表論文《Kunpeng 920: The First 7-nm Chiplet-Based 64-Core ARM SoC for CloudServices》,鏈接為https://ieeexplore.ieee.org/document/9444893,這可是要付費(fèi)瀏覽的論文,不是ARXIV那種只要你投就發(fā)表的論文,IEEE的論文是要嚴(yán)格審核的。
華為的論文主要說了LLC,即最后一級緩存。鯤鵬920的設(shè)計(jì)中,將SoC的全局LLC切片到各個(gè)CPU Cluster中,使LLC與CPU Cluster形成NUMA關(guān)系。因此,需要仔細(xì)考慮如何選擇每個(gè)集群的適當(dāng)大小,以最大限度地發(fā)揮其效益。綜合考慮多種因素,選擇每個(gè)集群4個(gè)CPU核心,以獲得當(dāng)前進(jìn)程節(jié)點(diǎn)的最佳PPA分?jǐn)?shù)。
LLC采用私有模式或共享模式:私有模式通常用于每個(gè)CPU核心承載相對獨(dú)立的任務(wù)數(shù)據(jù)時(shí);當(dāng)SoC內(nèi)的任務(wù)共享大量數(shù)據(jù)時(shí),通常使用共享模式。
在私有模式下,每個(gè)CPU集群和對應(yīng)的LLC切片組成一個(gè)私有組,可以避免集群訪問高延遲的緩存切片。
在共享模式下,所有 LLC切片組合在一起充當(dāng)一個(gè)塊,以提高 SoC 內(nèi)部數(shù)據(jù)的重用率。
再來看CPU部分,昇騰610里是16核心的CPU,按照慣例這里的CPU核心很可能就是鯤鵬里的CPU核心,即《Kunpeng 920: The First 7-nm Chiplet-Based 64-Core ARM SoC for CloudServices》里所說的TAISHAN V110,眾所周知,泰山也是華為服務(wù)器的產(chǎn)品線名稱。TAISHAN V110是ARM系列的魔改,因?yàn)門AISHAN V120內(nèi)核是基于ARM Cortex-A76的魔改,https://www.huaweicentral.com/kirin-990a-huaweis-first-auto-chipset-installed-in-arcfox-alpha-s-smart-car/,這里提到了麒麟990A的CPU是TAISHAN V120的lite版,而https://www.hisilicon.com/en/products/Kirin/Kirin-flagship-chips/Kirin-990-5G,則直接承認(rèn)麒麟990的CPU就是ARM Cortex-A76,因此TAISHANV110很可能是ARM Cortex-A75或A73或者是ARM服務(wù)器系列的N1。和英偉達(dá)的Orin使用的ARM Cortex-A78AE差距很大,但華為用數(shù)量彌補(bǔ)了這一差距,基本與英偉達(dá)旗鼓相當(dāng)。
NoC方面是2D的4*6 MESH網(wǎng)格,節(jié)點(diǎn)間工作頻率2GHz,帶寬1024位即256GB/s,這個(gè)在2019年是比較高端的配置,但現(xiàn)在是2023年了,只能是中等配置。
華為與其他智能駕駛芯片的對比
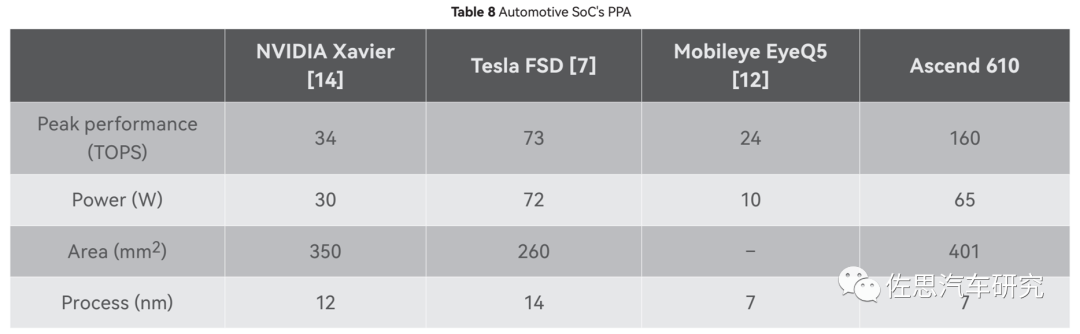
圖片來源:華為
華為最后也做了與其他智能駕駛芯片的對比,從中也可以看出昇騰610的die size尺寸很大,有401平方毫米。根據(jù)TechanaLye的分析,英偉達(dá)Orin的die size是455平方毫米,不過英偉達(dá)是三星的8納米工藝,如果用和昇騰一樣的臺積電7納米工藝,那么面積應(yīng)該與昇騰610差不多,也就是說昇騰610的硬件成本和英偉達(dá)Orin是基本一致的。依照昇騰610的功率,水冷散熱是少不了的。
算力實(shí)際上很難對比,英偉達(dá)的一般都是稀疏算力,而華為據(jù)說是稠密,通常兩者會差一倍。英偉達(dá)Orin有多個(gè)版本,最頂級版本的275TOPS@稀疏INT8,算力實(shí)際上是兩部分:一部分由2048個(gè)CUDA貢獻(xiàn),最高頻率1.3GHz,貢獻(xiàn)170TOPS@稀疏INT8算力;另一部分是64個(gè)張量核貢獻(xiàn),最高頻率1.6GHz,貢獻(xiàn)105TOPS@INT8稀疏算力,如果是FP32稠密格式那么算力僅為5.3TOPS(此時(shí)只有CUDA能處理FP32數(shù)據(jù)),并且CUDA核和張量核很難同時(shí)達(dá)到最大化性能。張量核主要做矩陣乘法,CUDA主要做矩陣與矢量乘法,矢量與矢量之間乘法,CPU會根據(jù)數(shù)據(jù)和任務(wù)的不同安排誰來工作。
此外稀疏和稠密有三種不同的定義,一種稀疏是計(jì)算稀疏,稀疏指計(jì)算密度低,谷歌第四代TPU就特設(shè)稀疏核,就是針對稀疏計(jì)算部分如transformer的嵌入部分。另一種是輸入數(shù)據(jù)本身就是稀疏矩陣,還有一種是密集權(quán)重模型經(jīng)過剪枝后的稀疏模型。天然稀疏矩陣指原始數(shù)據(jù)就包含很多0的矩陣,激光雷達(dá)的信息矩陣就是典型的稀疏矩陣,RGB攝像頭一般是稠密矩陣。
在汽車這種嵌入式領(lǐng)域,算力和存儲帶寬限制需要盡可能地降低權(quán)重規(guī)模,對模型進(jìn)行剪枝或者說蒸餾,這種屬于主動將模型稀疏化,通常有四級,分別是Fine-grained、Vector、Kernel和Filter,分別對應(yīng)單個(gè)權(quán)重、行或列、通道和卷積核。
英偉達(dá)對于最高級的fine grained做了特別優(yōu)化,相對稠密模型,計(jì)算速度提高一倍,也就是算力數(shù)值高了一倍,英偉達(dá)公布的算力數(shù)值,一般默認(rèn)是稀疏。如果沒有針對fine grained優(yōu)化,那么計(jì)算速度還是與稠密模型時(shí)一致。順便說一句,對于激光雷達(dá)這種稀疏矩陣,人類目前沒有找到好的優(yōu)化加速的方法。
算力數(shù)值實(shí)際和算法高度捆綁。若算法不匹配,最糟糕的情況下,算力只能發(fā)揮1%不到,也就是如果是100TOPS的算力,那么實(shí)際只發(fā)揮了不到1TOPS,這種情況不算罕見。
昇騰的軟件開發(fā)棧
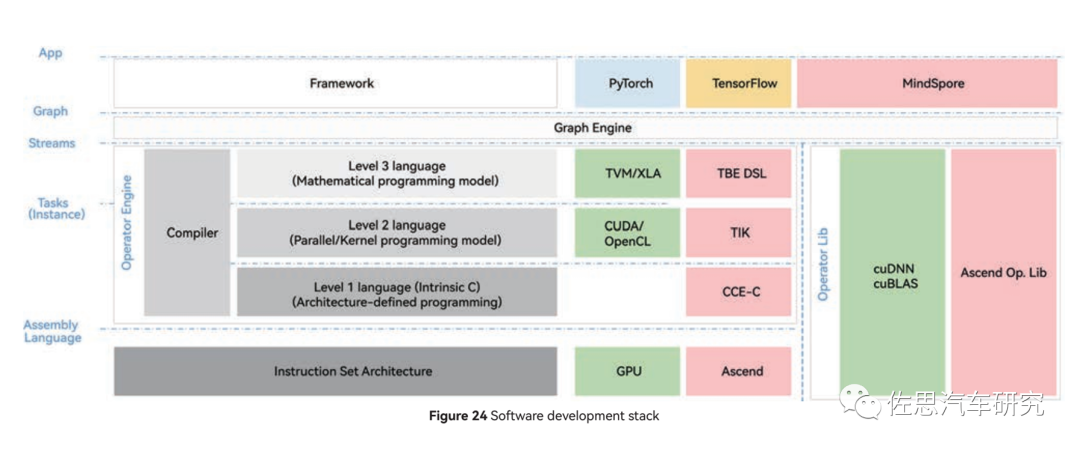
圖片來源:華為
上圖是昇騰的軟件開發(fā)棧,CUDA還是必須使用,算子庫還是常見的cuBLAS,英偉達(dá)的GPU此時(shí)會更占優(yōu)勢。
Transformer時(shí)代,存儲帶寬比算力數(shù)值更有價(jià)值。CNN時(shí)代,卷積之類的稠密算子占了90%以上的計(jì)算,而Transformer時(shí)代稠密算子所占的部分大幅下降,對存儲帶寬要求高的存儲密集型算子大幅增加數(shù)倍,80-90%的計(jì)算延遲都是由這些算子造成的。
存儲帶寬方面,昇騰910不計(jì)成本使用了HBM,不過2019年只有HBM一代,昇騰910的存儲帶寬是1TB/s,和目前主流AI加速器比差距較大;昇騰610自然無法用昂貴的HBM,只能是LPDDR4/5,估計(jì)是100-200GB/s之間;昇騰310考慮成本,存儲帶寬只有47.8GB/s。特斯拉二代FSD用了GDDR6做存儲,可輕易超過400GB/s。
考慮到華為的智能駕駛芯片是2019年確定設(shè)計(jì)框架的,這在2019年毫無疑問是全球最先進(jìn)的,沒有之一,即便到了2023年,這個(gè)設(shè)計(jì)仍然不算落伍,但與英偉達(dá)和高通的下一代相比,難免出現(xiàn)差距。特別是Transformer對AI運(yùn)算有非常大的改變,必須做出對應(yīng)的修改。
-
華為
+關(guān)注
關(guān)注
218文章
36098瀏覽量
262342 -
智能駕駛
+關(guān)注
關(guān)注
5文章
3021瀏覽量
51318 -
cnn
+關(guān)注
關(guān)注
3文章
355瀏覽量
23473
原文標(biāo)題:華為智能駕駛芯片深度分析
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
黑芝麻智能華山A2000芯片與Nullmax VLA算法完成深度適配
看點(diǎn):馬斯克:將深度參與特斯拉芯片設(shè)計(jì) 華為首款透明天線路由器開售
攜手行業(yè)領(lǐng)軍企業(yè),磐時(shí)深度賦能黑芝麻智能高端智駕芯片安全

【新啟航】深度學(xué)習(xí)在玻璃晶圓 TTV 厚度數(shù)據(jù)智能分析中的應(yīng)用

黑芝麻智能端到端全棧式輔助駕駛系統(tǒng)的應(yīng)用場景

智能駕駛科技公司Nullmax與國汽智控達(dá)成戰(zhàn)略合作


《汽車智能駕駛技術(shù)及產(chǎn)業(yè)發(fā)展白皮書》終于來了!華為乾崑給智駕產(chǎn)業(yè)“開視野”!
貞光科技:紫光國芯車規(guī)DDR3在智能駕駛與ADAS中的應(yīng)用

存儲示波器的存儲深度對信號分析有什么影響?
CASAIM與華為達(dá)成深度合作
新能源車軟件單元測試深度解析:自動駕駛系統(tǒng)視角
Rightware攜手采埃孚開辟智能駕駛新賽道
黑芝麻A2000#高階智能駕駛與通用AI計(jì)算芯片詳細(xì)解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論