 浪潮信息Owen ZHU:大模型百花齊放,算力效率決定速度
浪潮信息Owen ZHU:大模型百花齊放,算力效率決定速度

北京2023年8月31日/美通社/ -- 與狹義的人工智能相比,通用人工智能通過跨領域、跨學科、跨任務和跨模態的大模型,能夠滿足更廣泛的場景需求、實現更高程度的邏輯理解能力與使用工具能力。2023年,隨著 LLM 大規模語言模型技術的不斷突破,大模型為探索更高階的通用人工智能帶來了新的曙光。通用人工智能進入了快速發展期,在中國,大模型已經呈現出百花齊放的態勢,各種大模型層出不窮。
要想在"百模爭秀"的時代占得先機,AI開發團隊需要著力化解算力、算法、數據層面的巨大挑戰,而開發效率和訓練速度是保障大模型市場競爭力的核心關鍵因素,也是未來的核心發力點。近日,浪潮信息人工智能與高性能應用軟件部 AI 架構師Owen ZHU參與首屆由CSDN、《新程序員》聯合主辦的NPCon大會,發表重要技術演講,分享面向新一輪AIGC產業革命,AI大模型的算力系統解決之道,并強調算力、算法、數據和系統架構等多個方面的綜合優化對大模型訓練到了至關重要的作用。
以下為Owen ZHU在NPCon大會的演講實錄整理:
"百模爭秀"時代的算力瓶頸
大模型研發的核心技術是由預訓練與Alignment組成的,第一部分就是預訓練,需要用大量的數據使模型收斂速度更快、性能更好。第二部分則是Alignment,Alignment不完全等于強化學習,其通過使用多種方式/策略優化模型輸出,讓AI在和人的交流反饋中學會如何溝通表達,這兩部分是提升大模型質量的核心要素。
目前來看,模型基礎能力取決于數據、模型參數量和算力。模型參數量越大、投入的訓練數據越大,模型泛化能力越強。由于資源限制,在兩者不可兼得的時候,應該如何進行取舍呢?OpenAI的研究結論認為,與增加數據量相比,先增大模型參數量受益則會更好,用一千億的模型訓練兩千億的Token和兩千億模型訓練一千億的Token,后者的模型性能會更高。
由此可見,參數量是衡量模型能力的一個重要指標,當模型參數量增長超過一定閾值時,模型能力表現出躍遷式的提升,表現出來語言理解能力、生成能力、邏輯推理能力等能力的顯著提升,這也就是我們所說的模型的涌現能力。
模型規模多大能產生涌現能力呢?現在來看,百億參數是模型具備涌現能力的門檻,千億參數的模型具備較好的涌現能力。但這并不意味著模型規模就要上升到萬億規模級別的競爭,因為現有大模型并沒有得到充分訓練,如GPT-3的每個參數基本上只訓練了1-2個Token,DeepMind的研究表明,如果把一個大模型訓練充分,需要把每個參數量訓練20個Token。所以,當前的很多千億規模的大模型還需要用多10倍的數據進行訓練,模型性能才能達到比較好的水平。
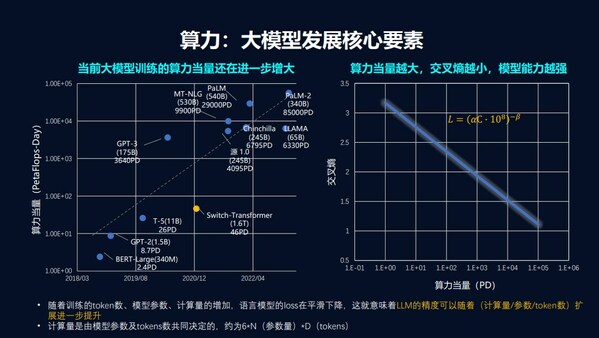
無論是提高模型參數量還是提升數據規模,算力依舊是大模型能力提升的核心驅動力:需要用"足夠大"的算力,去支撐起"足夠精準"模型泛化能力。當前大模型訓練的算力當量還在進一步增大,從GPT-3到GPT-4算力當量增長了68倍。算力當量越大,交叉熵越小,模型能力越強。隨著訓練的token數、模型參數、計算量的增加,語言模型的loss在平滑下降,這就意味著大語言模型的精度可以隨著計算量、參數規模、token數擴展進一步提升。
欲煉大模型,先利其器
大模型能力來源于大量工程實踐經驗,預訓練的工程挑戰巨大,這表現在如下幾個方面:首先,AI大模型的演化對于集群的并行運算效率、片上存儲、帶寬、低延時的訪存等也都提出了較高的需求,萬卡AI平臺的規劃建設、性能調優、算力調度都是很難解決的難題;其次,大規模訓練普遍存在硬件故障、梯度爆炸等小規模訓練不會遇到的問題;再次,工程實踐方面的缺乏導致企業難以在模型質量上實現快速提升。
作為最早布局大模型的企業之一,浪潮信息在業界率先推出了中文AI巨量模型"源1.0",參數規模高達2457億。千億參數規模的大模型創新實踐,使得浪潮信息在大模型領域積累了實戰技術經驗并擁有專業的研發團隊,為業界提供AI算力系統參考設計。在算力效率層面,針對大模型訓練中存在計算模式復雜,算力集群性能較低的情況,源1.0在大規模分布式訓練中采用了張量并行、流水線并行和數據并行的三維并行策略,訓練耗時約15天,共計訓練了180 billion token,并將模型最后的loss值收斂至1.73,顯著低于GPT-3等業界其他語言模型。首次提出面向效率和精度優化的大模型結構協同設計方法,圍繞深度學習框架、訓練集群IO、通信開展了深入優化,在僅采用2x200G互聯的情況下,源1.0的算力效率達到45%,算力效率世界領先。在集群高速互聯層面,基于原生RDMA實現整個集群的全線速組網,并對網絡拓撲進行優化,可以有效消除混合計算的計算瓶頸,確保集群在大模型訓練時始終處于最佳狀態。
為大模型良好生態發展尋找最優解
當前,中國和業界先進水平大模型的算力差距依然較大,從算力當量來看,GPT-4的算力當量已經達到了248,842PD,而國內大多數主流的大模型算力大量僅為數千PD,差距高達近百倍。
同時,中國和業界先進水平大模型在算法、數據方面也存在巨大差距。在算法方面,雖然開源為國內大模型發展帶來了彎道超車的良機,但LLaMA等開源大模型相比GPT4等頂級水平自研模型的性能,開源模型的能力存在"天花板"。
在數據方面,中文數據集和英文數據集相比較,在規模、質量上均存在顯著差距,相較于動輒數千億單詞量級的英文數據,中文大模型的數據量級僅為百億左右,而且開源程度較低,封閉程度較高。
開發大模型、發展通用人工智能是一項非常復雜的系統工程,我們亟需從系統層面為未來大模型的良好生態發展尋找最優解。從實戰中走來,通過構建高效穩定的智算系統,加速模型開發效率提升。
日前,浪潮信息大模型智算軟件棧OGAI(Open GenAI Infra)——"元腦生智"已正式發布。浪潮信息正通過"工具化、系統化、全鏈條"的全棧賦能能力,讓煉大模型省時、省力,讓大模型更快、更穩、更智能,助力百模真正實現"競速AIGC"。
審核編輯 黃宇
-
AI
+關注
關注
91文章
40616瀏覽量
302275 -
人工智能
+關注
關注
1819文章
50213瀏覽量
266476 -
大模型
+關注
關注
2文章
3716瀏覽量
5248
發布評論請先 登錄
海光主板,3450G強算力加快數智技術創新

國產工業操作系統選型指南:硬實時、功能安全與生態怎么選
京東方華燦光電MPD技術打造新型顯示創新生態


國產AI芯片真能扛住“算力內卷”?海思昇騰的這波操作藏了多少細節?
公布2025年中國十大智能電表廠家品牌排行榜

中國智能算力規模增長將超40%
浪潮信息發布"元腦SD200"超節點,面向萬億參數大模型創新設計

積算科技上線赤兔推理引擎服務,創新解鎖FP8大模型算力
浙江移動攜手華為全面推進AI+賦能應用百花齊放
瑞芯微生態百花齊放,我在第九屆開發者大會看到了未來!

一文看懂AI算力集群

飛利信與浪潮信息達成戰略合作
基于算力魔方的智能文檔信息提取方案



 工商網監
工商網監
評論