") CMU&MIT最新開源!超強(qiáng)通用視覺位置識別!
CMU&MIT最新開源!超強(qiáng)通用視覺位置識別!

0. 筆者個(gè)人體會
這項(xiàng)工作可以簡稱為"識別一切"!。看到官方demo的一瞬間,真的是感覺很驚嘆。
視覺位置識別的工作有很多,本質(zhì)上都可以歸類為構(gòu)建圖像數(shù)據(jù)庫+查詢圖像檢索的過程。現(xiàn)在的主要問題是,很多識別算法都是針對特定環(huán)境進(jìn)行的,換一個(gè)環(huán)境很可能直接就掛掉了。
那么,一個(gè)真正通用的位置識別算法,應(yīng)該做到什么呢?
答案就是三個(gè)關(guān)鍵詞:任何地點(diǎn)(無縫地運(yùn)行在任何環(huán)境中,包括空中、地下和水下),任何時(shí)間(對場景中的時(shí)間變化,如晝夜或季節(jié)變化,或?qū)εR時(shí)物體具有魯棒性),以及跨任何視角(對視角變化具有魯棒性,包括完全相反的視角)。也就是說,在任何地點(diǎn)、任何時(shí)間、任何視角下都可以魯棒得進(jìn)行位置識別。這個(gè)任務(wù)想想就非常難!
但是最近有一個(gè)團(tuán)隊(duì)就推出了這樣的工作,也就是CMU、IIIT Hyderabad、MIT、AIML聯(lián)合開源的AnyLoc,性能非常的魯棒,并且實(shí)驗(yàn)做得很詳細(xì)。今天筆者就將帶領(lǐng)讀者一起欣賞一下這一力作,當(dāng)然筆者水平有限,如果有理解不當(dāng)?shù)牡胤綒g迎大家一起交流。限于篇幅,對本文的的深入思考與理解,我們發(fā)表在了「3D視覺從入門到精通」知識星球。
注:本文使用VPR做為視覺位置識別的簡稱(Visual Place Recognition)。
1. 效果展示
先來看一個(gè)最基礎(chǔ)的任務(wù),就是根據(jù)查詢圖像進(jìn)行位置識別。這也是官方主頁上提供的交互式demo,直接點(diǎn)擊左側(cè)Query圖像上的任一點(diǎn),就可以在右側(cè)識別出選擇的位置。感興趣的小伙伴可以去官方主頁上進(jìn)行嘗試!這里也推薦「3D視覺工坊」新課程《面向自動駕駛領(lǐng)域目標(biāo)檢測中的視覺Transformer》。
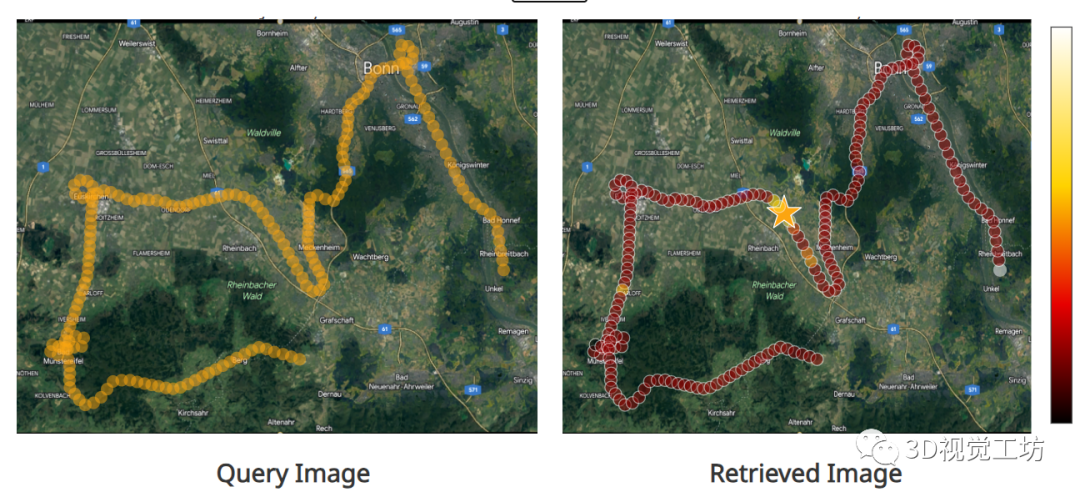
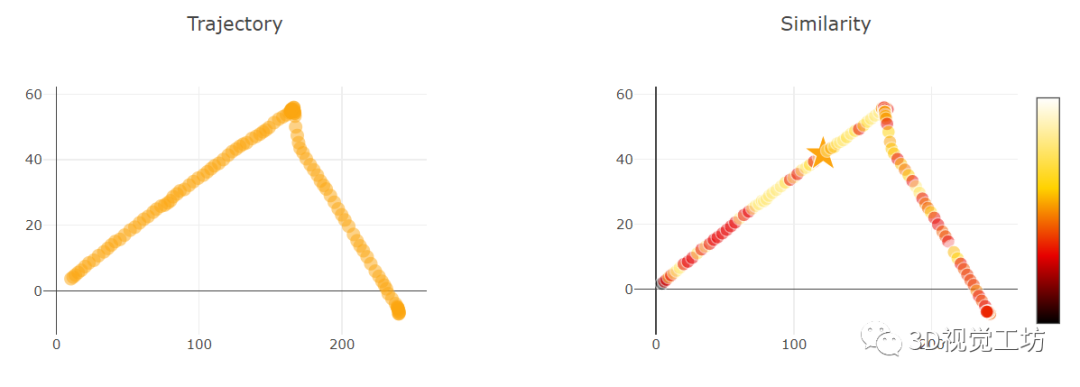
就像論文中提到的那樣,AnyLoc在任何地點(diǎn)、任何時(shí)間、任何視角都可以進(jìn)行位置識別。最關(guān)鍵的是,在各種結(jié)構(gòu)化、非結(jié)構(gòu)化、光照變化等挑戰(zhàn)性場景中都可以進(jìn)行準(zhǔn)確識別!
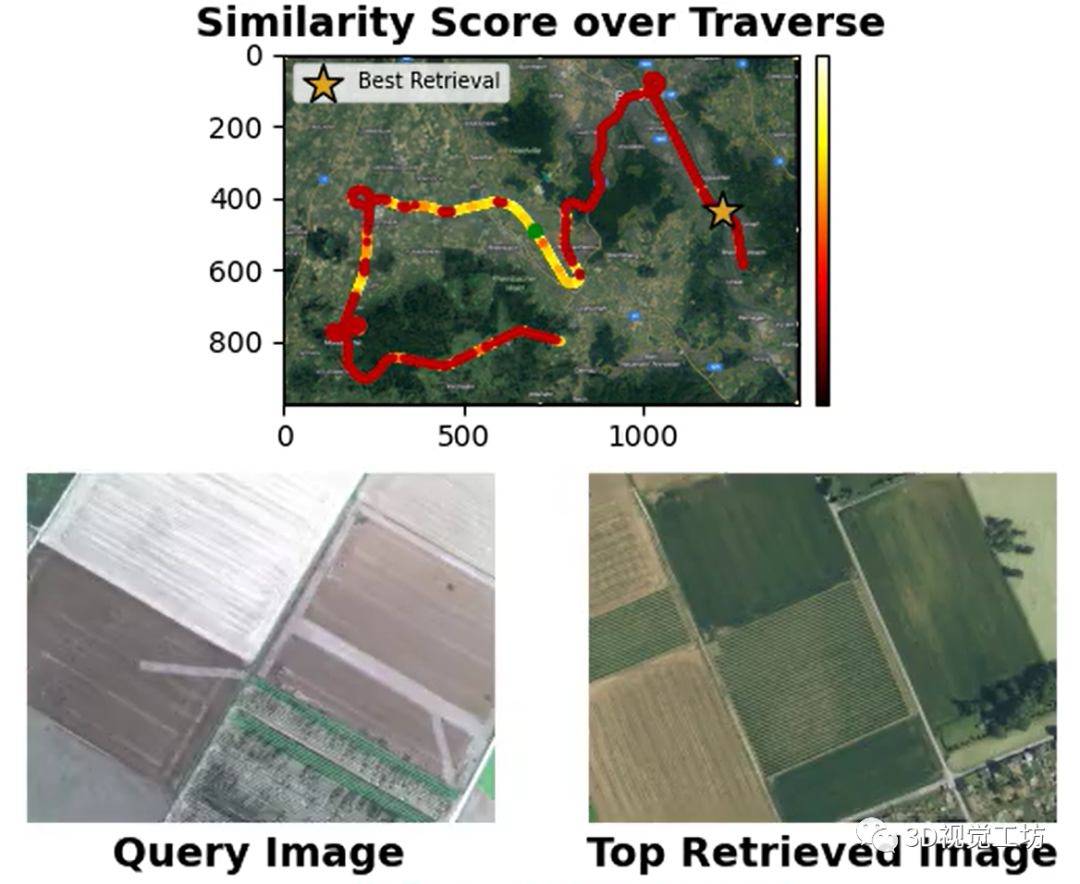
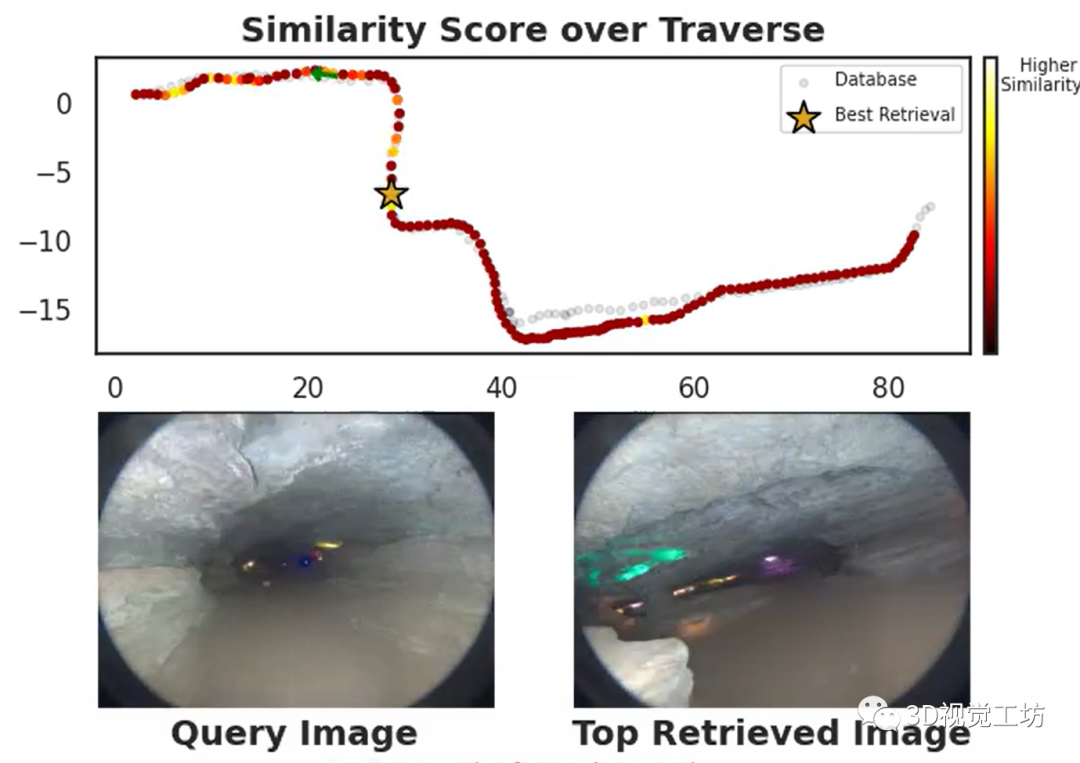
AnyLoc在室內(nèi)室外、結(jié)構(gòu)化非結(jié)構(gòu)化、光照視角變化等挑戰(zhàn)性場景中的性能都遠(yuǎn)遠(yuǎn)超過了同類算法,簡直是"八邊形戰(zhàn)士"!
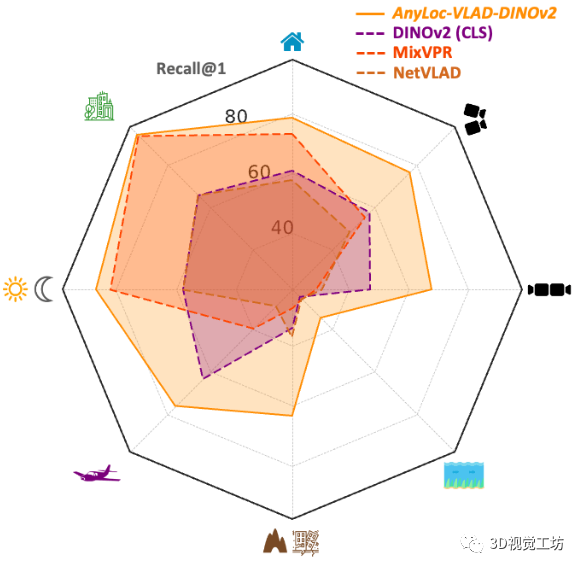
總之,算法已經(jīng)開源了,官方主頁上也提供了很多的demo。感興趣的小伙伴趕快去試試吧,下面來看一下具體的論文信息。
3. 摘要
視覺位置識別( Visual Place Recognition,VPR )對機(jī)器人定位至關(guān)重要。迄今為止,性能最高的VPR方法都是針對環(huán)境和任務(wù)的:盡管它們在結(jié)構(gòu)化環(huán)境(以城市駕駛為主)中表現(xiàn)出強(qiáng)勁的性能,但它們在非結(jié)構(gòu)化環(huán)境中的性能嚴(yán)重下降,這使得大多數(shù)方法在實(shí)際部署中表現(xiàn)不佳。在這項(xiàng)工作中,我們開發(fā)了一個(gè)通用的VPR解決方案------一種跨越廣泛的結(jié)構(gòu)化和非結(jié)構(gòu)化環(huán)境(城市、室外、室內(nèi)、空中、水下和地下環(huán)境)的技術(shù),無需任何重新訓(xùn)練或微調(diào)。我們證明,從沒有VPR特定訓(xùn)練的現(xiàn)成的自監(jiān)督模型中得到的通用特征表示是構(gòu)建這種通用VPR解決方案的正確基礎(chǔ)。將這些派生特征與無監(jiān)督的特征聚合相結(jié)合,使得我們的方法AnyLoc能夠獲得比現(xiàn)有方法高達(dá)4倍的性能。通過表征這些特征的語義屬性,我們進(jìn)一步獲得了6 %的性能提升,揭示了封裝來自相似環(huán)境的數(shù)據(jù)集的獨(dú)特領(lǐng)域。我們詳細(xì)的實(shí)驗(yàn)和分析為構(gòu)建可以在任何地方、任何時(shí)間、任何視角部署的VPR解決方案奠定了基礎(chǔ)。我們鼓勵(lì)讀者瀏覽我們的項(xiàng)目頁面和互動演示。
4. 算法解析
本質(zhì)上來說,VPR可以被定義為一個(gè)圖像檢索問題。機(jī)器人首先穿越環(huán)境采集圖像,建立圖像數(shù)據(jù)庫,然后在后續(xù)的運(yùn)行時(shí)提供查詢圖像,在參考數(shù)據(jù)庫中檢索與該圖像最接近的匹配。但是具體的實(shí)現(xiàn)方式就多種多樣了,大家可能更熟悉的是描述子方法,包括局部描述子還有全局描述子。
但想要達(dá)到最優(yōu)性能,一般還是要針對特定環(huán)境進(jìn)行大規(guī)模訓(xùn)練。只是這種高性能帶來的是低泛化性,在自動駕駛場景中訓(xùn)練的模型,幾乎不可能泛化到室內(nèi)場景和非結(jié)構(gòu)化場景中。
這篇文章的亮點(diǎn)就在于,分析了VPR的任務(wù)無關(guān)的ViT特征提取和融合,并開發(fā)了一個(gè)通用的解決方案,不需要任何針對特定VPR任務(wù)的訓(xùn)練!作者發(fā)現(xiàn),來自現(xiàn)成基礎(chǔ)模型的逐像素特征表現(xiàn)出顯著的視覺和語義一致性,雖然用于通用VPR時(shí),每個(gè)圖像的特性都不是最佳的,但是可以將這些逐像素不變性轉(zhuǎn)移到圖像級別以識別地點(diǎn)。
那么,要選擇何種基礎(chǔ)模型呢?
想要提取任務(wù)無關(guān)的視覺特征,這樣的自監(jiān)督基礎(chǔ)模型有三大類:
(1)聯(lián)合嵌入方法(DINO、DINOv2);
(2)對比學(xué)習(xí)方法(CLIP);
(3)基于掩碼的自編碼方法(MAE)。
作者經(jīng)過實(shí)驗(yàn),發(fā)現(xiàn)聯(lián)合嵌入學(xué)習(xí)模型可以更好得捕獲長范圍的全局信息,因此AnyLoc使用DINO和DIONv2 ViT模型來提取視覺特征。
另一個(gè)問題來了,要從這些預(yù)訓(xùn)練的ViT中提取什么視覺特征呢?
與提取單幅圖像特征(圖像特征向量)相比,提取逐像素特征可以實(shí)現(xiàn)更細(xì)粒度的匹配。而ViT的每一層都有多個(gè)特征(Query、Key、Value、Token)。因此,作者嘗試從中間層提取特征,而不使用CLS Token。具體來說,就是從數(shù)據(jù)庫圖像中選擇一個(gè)點(diǎn),將其與來自查詢圖像的所有像素特征進(jìn)行匹配,并繪制熱力圖。
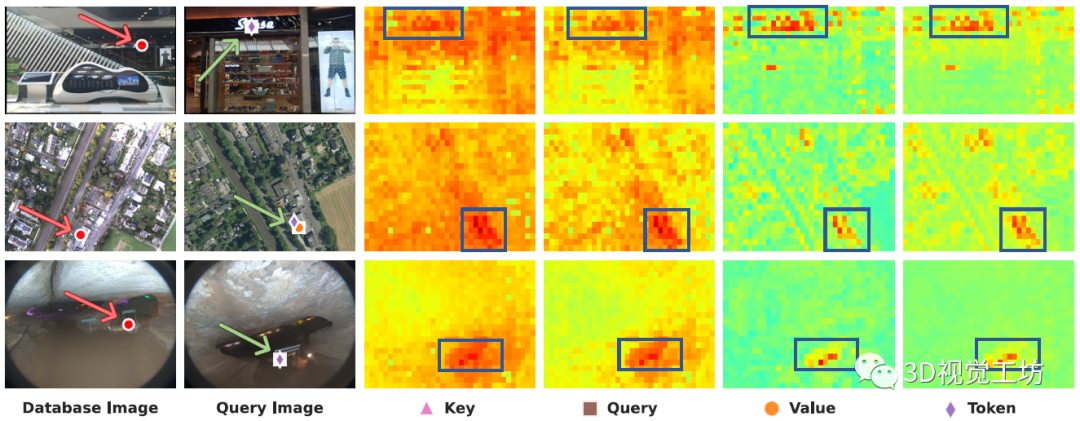
有什么發(fā)現(xiàn)呢?
首先,即使存在語義文本和尺度變化(第一行)、感知混淆和視點(diǎn)偏移(第二行)、低光照結(jié)合相反視角(第三行),這些匹配關(guān)系也是魯棒的。
最關(guān)鍵的來了。注意如何在匹配點(diǎn)和背景之間表現(xiàn)出最大的對比度,這對于抵抗圖像中干擾物的魯棒性至關(guān)重要。
通過進(jìn)一步的跨層分析,可以發(fā)現(xiàn)一個(gè)很有意思的現(xiàn)象。ViT的較早層(頂行),特別是Key和Query,表現(xiàn)出很高的位置編碼偏差,而第31層(更深的層)的Value在相似度圖中的反差最大。
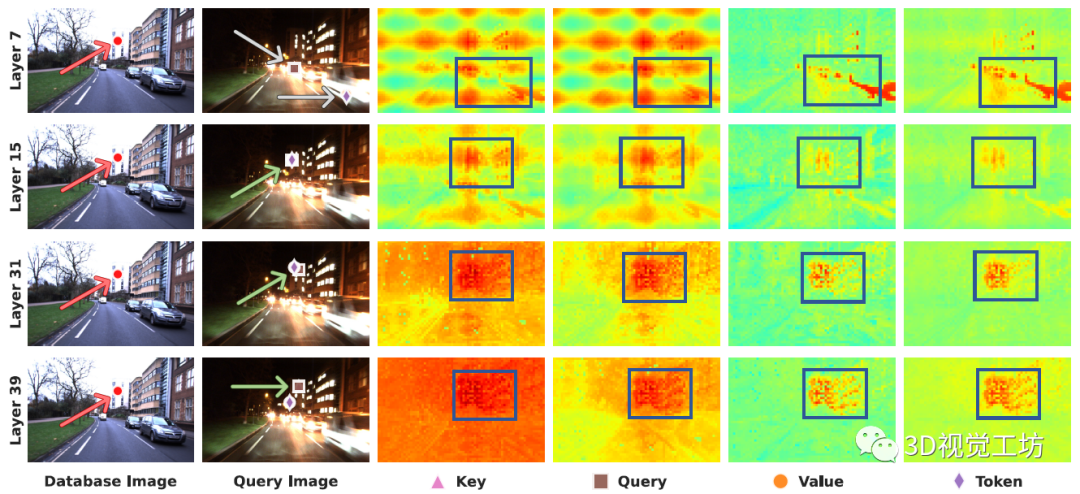
因此,作者選擇Layer 31和Value做為局部特征表征。
特征提取完了,下面該聊聚合了。
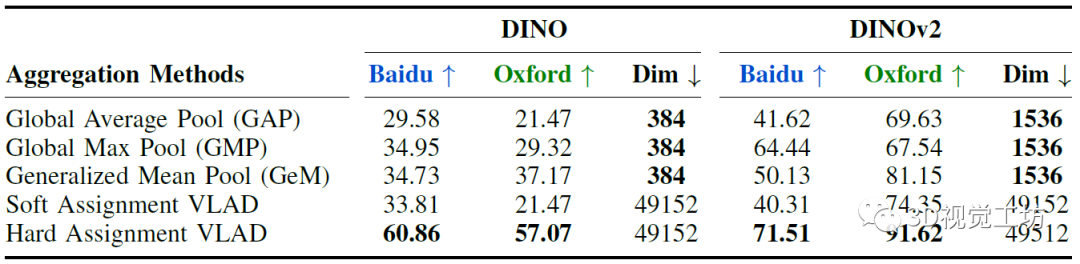
也就是如何將局部特征組合在一起以描述圖像的各個(gè)部分,并最終描述一個(gè)環(huán)境。作者全面探索了多種無監(jiān)督聚合技術(shù):全局平均池化(GAP)、全局最大池化(GMP)、廣義平均池化(GeM)以及VLAD的軟硬對齊變體。最終選擇了內(nèi)部歸一化、級聯(lián)、間歸一化來獲取最終的VLAD描述子。
最后,構(gòu)建詞袋模型。
這一部分的目的是在不同的環(huán)境中,表征全局聚合的局部特征的獨(dú)特語義屬性。先前基于VLAD的工作雖然在城市場景中表現(xiàn)良好,但是并不適合基礎(chǔ)模型特征編碼中的開放集語義屬性。因此,作者通過對GeM描述子進(jìn)行表征來指導(dǎo)VLAD的詞袋選擇。這里也有個(gè)trick。就是使用PCA投影全局描述子可以在潛在空間發(fā)現(xiàn)不同的域,并且表征相似屬性(Urban,Indoor,Air,SubT,Degrad和Underwater)。而且可以觀察到查詢圖像的投影特征與各自數(shù)據(jù)庫圖像的投影特征接近,因此,最終VLAD的詞袋構(gòu)建是基于PCA分離進(jìn)行的。
5. 實(shí)驗(yàn)
AnyLoc的實(shí)驗(yàn)可謂無限創(chuàng)造困難,提供了前所未有的環(huán)境多樣性(任何地方),加上一系列時(shí)間(任何時(shí)候)和相機(jī)視點(diǎn)(任何視圖)的變化。其中結(jié)構(gòu)化環(huán)境使用了6個(gè)基準(zhǔn)的室內(nèi)和室外數(shù)據(jù)集,包含劇烈的視點(diǎn)偏移、感知混疊和顯著的視覺外觀變化。非結(jié)構(gòu)化環(huán)境使用空中、水下、地下場景,包含各種視覺退化、衛(wèi)星圖像、低光照以及季節(jié)變化。
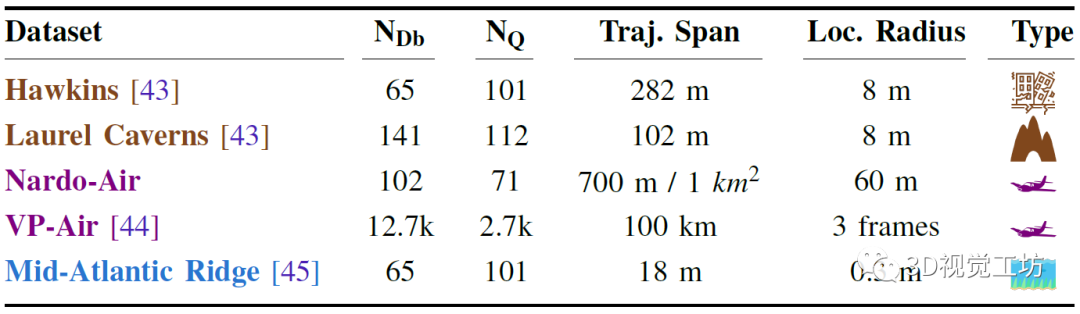
評估指標(biāo)主要使用Recall,實(shí)驗(yàn)都在3090上進(jìn)行。對比方案也都是SOTA方案,包含在大規(guī)模城市數(shù)據(jù)集上為VPR任務(wù)訓(xùn)練的3個(gè)特定baseline,以及使用基礎(chǔ)模型CLS Token的3個(gè)新baseline。
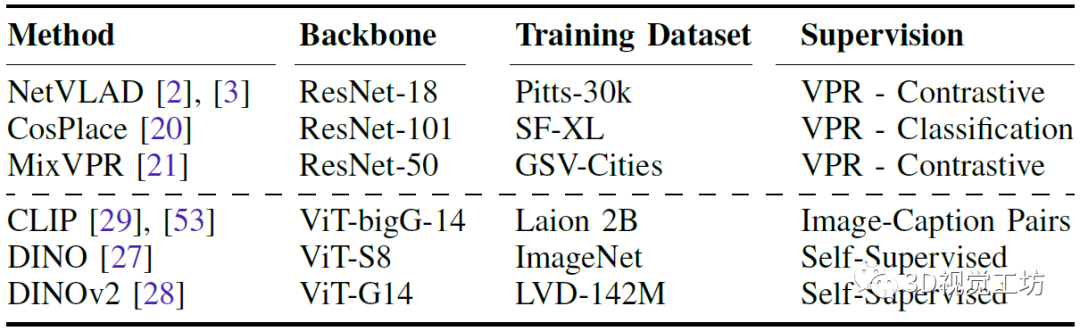
首先對比AnyLoc在結(jié)構(gòu)、非結(jié)構(gòu)環(huán)境、視點(diǎn)偏移、時(shí)間外觀變化上對比其他SOTA VPR方案的結(jié)果。AnyLoc-VLAD-DINOv2在所有的室內(nèi)數(shù)據(jù)集上都取得了最高的召回率,室外環(huán)境稍差,但在Oxford數(shù)據(jù)集上效果尤其的好。而且比較有意思的是,在DINOv2上簡單地使用GeM池化就可以顯著提高性能。
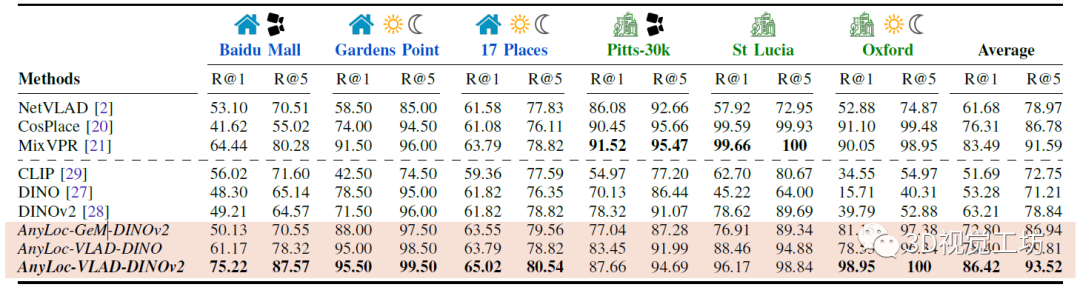
在非結(jié)構(gòu)化環(huán)境中,AnyLoc很大程度上優(yōu)于所有baseline,尤其是對于時(shí)間和視角變化。而聚合方法也很明顯優(yōu)于CLS方法。另一方面,NetVLAD、CosPlace和MixVPR這三個(gè)特定baseline也證實(shí)了隨著城市訓(xùn)練數(shù)據(jù)規(guī)模的增加,在特定任務(wù)上回表現(xiàn)得更好。
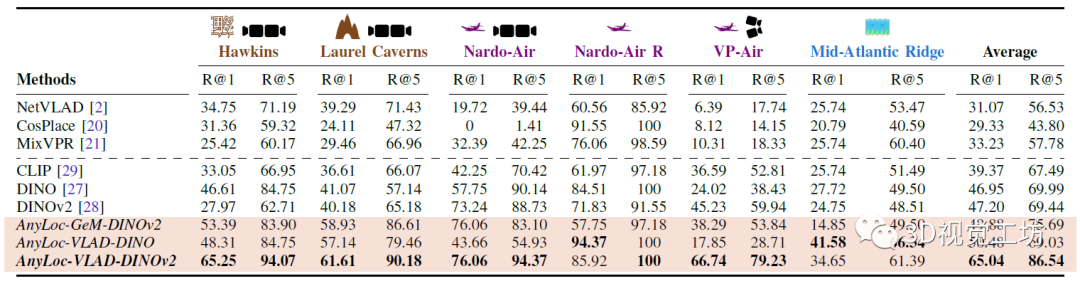
之后,對AnyLoc的設(shè)計(jì)進(jìn)行詞袋分析,特定領(lǐng)域的詞袋可以帶來最優(yōu)性能。
下面來展示特定領(lǐng)域詞袋的魯棒域內(nèi)一致性,具體做法是使用領(lǐng)域特定的詞匯對局部特征的聚類賦值進(jìn)行可視化。在Urban域中,道路、路面、建筑物和植被在不斷變化的條件和地點(diǎn)被一致地分配到同一個(gè)簇中。對于室內(nèi)域,可以觀察到地板和天花板的域內(nèi)一致性,以及文字標(biāo)志和家具的域內(nèi)一致性。對于航空領(lǐng)域,可以觀察到道路、植被和建筑物在農(nóng)村和城市圖像中都被分配到獨(dú)特的簇中。

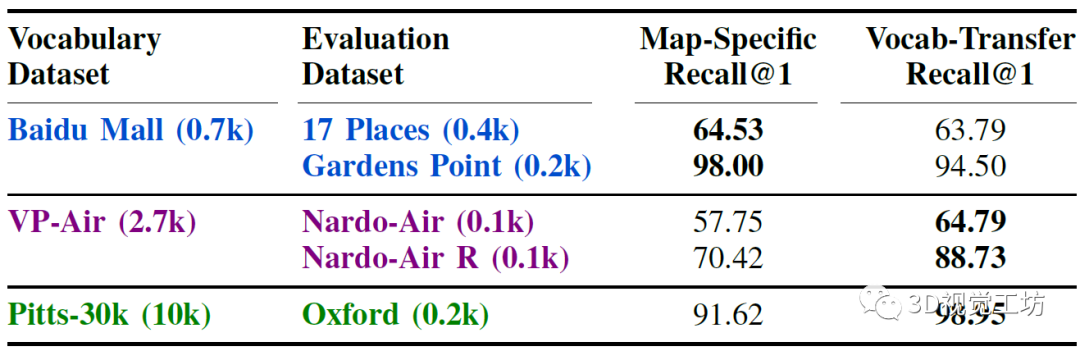
進(jìn)一步可以證明,這種域內(nèi)的魯棒一致性能夠在缺乏信息豐富度的小型參考數(shù)據(jù)庫的目標(biāo)環(huán)境中部署AnyLoc-VLAD。對于屬于給定領(lǐng)域的數(shù)據(jù)集,選擇最大的參考數(shù)據(jù)庫來形成詞袋,并在來自該領(lǐng)域的其他數(shù)據(jù)集上進(jìn)行評估。對于航拍和城市領(lǐng)域,可以觀察到,當(dāng)使用更大的詞袋來源時(shí),與僅僅使用較小的地圖相比,可以實(shí)現(xiàn)7-18 %更高的召回率,從而證明了詞袋在同一領(lǐng)域內(nèi)的可遷移性。
作者還對比了不同的ViT架構(gòu)、選擇的Layer以及不同的Facet對性能的影響。

還詳細(xì)對比了各種無監(jiān)督局部特征聚合方法對性能的影響,顯示GeM聚合性能更優(yōu)。有一點(diǎn)需要注意,就是硬分配比軟分配要快1.4倍。
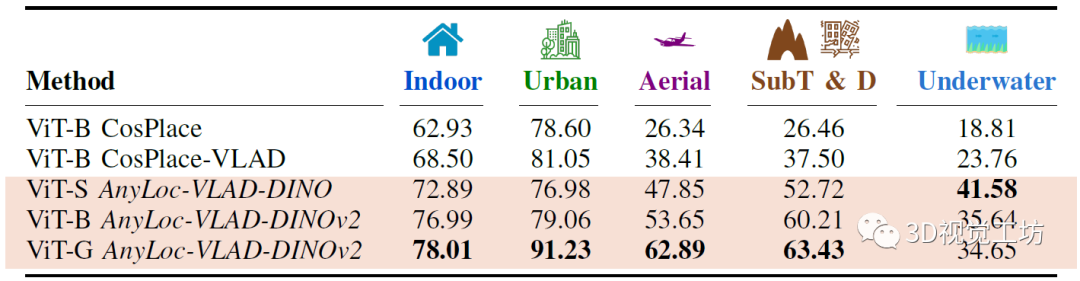
最后,還將專門面向VPR(CosPlace)訓(xùn)練的ViT與基于自監(jiān)督(DINO、DINOv2)的ViT進(jìn)行比較。舉個(gè)例子,對比基于ViT-B的方法,即使CosPlace系的整體性能有所改善,但AnyLoc-VLAD-DINOv2仍然比VLAD提高了8-13 %。這里也推薦「3D視覺工坊」新課程《面向自動駕駛領(lǐng)域目標(biāo)檢測中的視覺Transformer》。
6. 總結(jié)
非常有意思的工作!
站在上帝視角來看,會覺得AnyLoc的思想很簡單,就是使用任務(wù)無關(guān)的基礎(chǔ)ViT模型來提取逐像素特征,然后進(jìn)行特征聚合。但其實(shí)整個(gè)分析問題,解決問題的思路非常巧妙。尤其是AnyLoc的結(jié)果很棒,將機(jī)器人定位擴(kuò)展到任何地點(diǎn)、任何時(shí)間、任何視角下,這對于機(jī)器人下游任務(wù)至關(guān)重要。
另一方面,模型大一統(tǒng)真的是一個(gè)大趨勢,不停的出現(xiàn)一個(gè)大模型實(shí)現(xiàn)這個(gè)領(lǐng)域內(nèi)的所有功能。那么,下一個(gè)"一切"是什么呢?讓我們拭目以待。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
31079瀏覽量
222225 -
開源
+關(guān)注
關(guān)注
3文章
4207瀏覽量
46134 -
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52104
原文標(biāo)題:CMU&MIT最新開源!超強(qiáng)通用視覺位置識別!任何地點(diǎn)!任何時(shí)間!任何視角!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【KV260視覺入門套件試用體驗(yàn)】六、VITis AI車牌檢測&車牌識別
CMU200手機(jī)專用測試儀表
R&S/CMU300特價(jià)清銷CMU300基站綜測儀CMU300
基于CNN的惡意軟件加密C&C通信流量識別方法
【新品發(fā)布】教育領(lǐng)域新成果,P &T AI計(jì)算機(jī)視覺開發(fā)套件

存儲類&作用域&生命周期&鏈接屬性

2021 Kubernetes on AI &amp;amp;amp; Edge Day圓滿舉行 共探邊緣云融合

如何區(qū)分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),為true,你敢信?

HarmonyOS &amp;amp;amp;潤和HiSpark 實(shí)戰(zhàn)開發(fā),“碼”上評選活動,邀您來賽!!!

攝像機(jī)&amp;amp;雷達(dá)對車輛駕駛的輔助
FS201資料(pcb &amp; DEMO &amp; 原理圖)
onsemi LV/MV MOSFET 產(chǎn)品介紹 &amp;amp; 行業(yè)應(yīng)用

視覺傳感器 | 這些常見的Q&amp;amp;A!今天統(tǒng)一回答!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論