") 數(shù)據(jù)中心以太網(wǎng)和RDMA:超大規(guī)模環(huán)境下的問題
數(shù)據(jù)中心以太網(wǎng)和RDMA:超大規(guī)模環(huán)境下的問題

摘要
我們觀察到新興的人工智能、高性能計算和存儲工作負載對大規(guī)模數(shù)據(jù)中心網(wǎng)絡提出了新的挑戰(zhàn)。基于融合以太網(wǎng)的RDMA協(xié)議(RoCE,RDMA over Converged Ethernet) 是將現(xiàn)代的遠程直接內存訪問(RDMA,Remote Direct Memory Access)功能引入現(xiàn)有以太網(wǎng)的一種嘗試。十年過去了,我們重新審視了RoCE的設計要點,并得出結論認為必須解決其幾個缺點,以滿足超大規(guī)模數(shù)據(jù)中心的需求。我們預測,數(shù)據(jù)中心和高性能計算市場將會融合,并在未來十年內采用現(xiàn)代化以太網(wǎng)為基礎的高性能網(wǎng)絡解決方案,取代TCP和RoCE。
數(shù)據(jù)中心以太網(wǎng)的新環(huán)境
以太網(wǎng)在有線局域網(wǎng)(LAN)領域占據(jù)主導地位已經幾十年了,從私人住宅的部署到最大的數(shù)據(jù)中心。在過去的十年里,數(shù)據(jù)中心經歷了巨大的增長,連接的機器數(shù)量超過了目前最大的超級計算機規(guī)模。雖然仍然存在一些差異,但這類超大規(guī)模的超級計算機和數(shù)據(jù)中心的網(wǎng)絡需求非常相似[1]。然而,超級計算機通常使用專用的互連方式進行連接,而數(shù)據(jù)中心則建立在以太網(wǎng)之上。由于相似的需求和規(guī)模經濟效益,隨著每一代新技術的出現(xiàn),二者繼續(xù)趨近于融合。我們認為現(xiàn)在是重新思考融合互連的基本假設和架構的合適時機。
多種技術趨勢加速了高性能互連的融合。主要的是,不斷增加的網(wǎng)絡性能要求推動了更高效的主機堆棧的發(fā)展,以支持新興的數(shù)據(jù)密集型應用,如人工智能(AI),所需的Tb帶寬、每秒數(shù)億次的事務和個位數(shù)微秒級的延遲[2]。這些極端需求要求所有的協(xié)議和硬件盡可能高效,排除了許多傳統(tǒng)驅動數(shù)據(jù)中心網(wǎng)絡的類似TCP/IP的堆棧。遠程直接內存訪問(RDMA)是近30年來為高性能計算(HPC)工作負載開發(fā)的,并且后來擴展到目標存儲與InfiniBand(IB)Verbs RDMA。RDMA使CPU可以通過網(wǎng)絡進行硬件加速的直接內存訪問。在過去的10年里,RDMA成為低開銷和高速網(wǎng)絡的事實標準。幾乎所有的超級計算機架構以及領先的數(shù)據(jù)中心供應商都在生產環(huán)境中使用RDMA。
幾十年前確定的負載平衡、擁塞控制和錯誤處理方面的簡單假設,對于今天的網(wǎng)絡來說已經不適用,現(xiàn)在的網(wǎng)絡帶寬高出100倍以上,消息速率高出10倍以上。此外,簡單的RDMA網(wǎng)絡接口卡(NIC)通常會增加額外的功能。由此產生的“智能NIC”通常會卸載重要服務并實現(xiàn)專門的網(wǎng)絡協(xié)議。現(xiàn)代網(wǎng)絡交換機還具備改進的能力,包括先進的網(wǎng)絡遙測、網(wǎng)絡計算能力以及網(wǎng)絡負載均衡或擁塞控制[3]。我們認為當前現(xiàn)有的標準和部署基礎設施存在根本性的差距,必須在不久的將來加以解決,以支持高效的高性能網(wǎng)絡。
以太網(wǎng)RDMA簡史
RDMA最初是為高性能計算系統(tǒng)開發(fā)的,早期應用包括Paragon、Cray的T3D/T3E和ASCI Red等。后來,InfiniBand Verbs RDMA成為超級計算領域中的標準解決方案。隨后,在數(shù)據(jù)中心環(huán)境中采用了“RDMA over Converged Ethernet”(RoCE)來在向后兼容的以太網(wǎng)環(huán)境中提供RDMA的優(yōu)勢。另一個協(xié)議iWARP(參見IETF 2007年,RFC 5040-5044、6580、6581、7306)將RDMA語義層置于TCP或SCTCP之上。iWARP和RoCE都使用InfiniBand的Verbs與用戶軟件堆棧進行接口,因此對用戶而言基本透明。盡管iWARP一開始就支持互聯(lián)網(wǎng)兼容的路由,但并沒有廣泛采用。這可能是因為相對于RoCE所基于的非常簡單的協(xié)議,一個完整的TCP/IP堆棧在硬件上的卸載是復雜而昂貴的。事實上,RoCEv1只是在以太網(wǎng)的L2報頭之上采用了類似InfiniBand的傳輸層(即Base Transport Header,BTH)。后來,RoCEv2添加了IP/UDP L3報頭以支持數(shù)據(jù)中心內部和跨數(shù)據(jù)中心的路由。目前,RoCEv2 NIC的部署數(shù)量超過了InfiniBand NIC。
RoCE - 融合還是臨時應急?
RoCE的核心設計是繼承自20年前為簡單硬件開發(fā)的技術,對于今天的以太網(wǎng)環(huán)境來說并不是最優(yōu)解。例如,RoCE使用基于InfiniBand的簡單傳輸層,它在很大程度上依賴于按順序傳遞和回退N(go-back-n)重傳語義,這基本上需要一個高度可靠的按順序傳遞的基礎架構才能實現(xiàn)高效的運行。因此,RoCE在無丟包的有序傳輸環(huán)境(如InfiniBand)中運行效果最佳。傳統(tǒng)上,以太網(wǎng)在交換機緩沖區(qū)已滿時會丟棄數(shù)據(jù)包,并依賴端到端的重傳機制。為了支持RoCE,"融合以太網(wǎng)"(CE,Converged Ethernet)引入了優(yōu)先流控制(PFC,Priority Flow Control)來實現(xiàn)鏈路級無丟包操作。PFC重新利用了以太網(wǎng)中的PAUSE幀,以支持具有不同鏈路傳輸速率的網(wǎng)絡。PFC通過增強PAUSE幀來停止(或限制)特定優(yōu)先級類別的流量,以避免數(shù)據(jù)包丟失。不幸的是,這一復雜的協(xié)議集干擾了網(wǎng)絡中的不同層次,并降低了對一些當今最重要的工作負載的效率。
RoCE的語義、負載平衡和擁塞控制機制都是繼承自InfiniBand。這意味著所有的消息應該按照順序到達目的地,就像它們是通過靜態(tài)路由傳輸一樣,這本質上禁止了許多分組級別的負載平衡機制。對于長期流程的AI訓練工作負載,多路徑機制可以極大地提高作業(yè)完成時間。此外,RoCEv2使用基于IP的簡化擁塞控制機制,基于明確擁塞通知(ECN,Explicit Congestion Notification)的機制。當檢測到擁塞時,ECN兼容的交換機會標記數(shù)據(jù)包,并將該信息傳回接收方,接收方再將其傳遞給發(fā)送方,發(fā)送方根據(jù)一個參數(shù)減少注入速率。在無擁塞期之后,速率會自動增加,使用第二個配置參數(shù)。ECN使用二進制標志表示經歷過擁塞,缺乏細粒度的指示會導致需要許多往返時間(RTTs,Round Trip Times)來確定正確的速率。這種簡單的機制與InfiniBand最初的前向和后向明確擁塞通知(FECN/BECN)非常相似。它承諾可以與其它流量共存,但在實踐中很難進行配置[4],[5],[6]。
現(xiàn)在我們簡要討論一些高性能計算(HPC)和數(shù)據(jù)中心流量中的重要流量模式,然后詳細討論RoCE的缺點。
指導流量模式
為了討論方便,我們將確定三種流量模式,代表了當前大部分RDMA工作負載。不幸的是,這些模式也凸顯了RoCE的不足之處。在這里,我們重點關注在HPC、AI訓練和分布式推理、存儲以及一般微服務或函數(shù)即服務(FaaS)流量中使用的東西(內部)數(shù)據(jù)中心流量。
Incast(IN)
當多個源進程以可能不協(xié)調但同時的流量模式針對同一目標進程時,就會發(fā)生incast流量模式。它的特點是具有多個源進程和一個事務大小。實際中,當服務在同一時間被許多不協(xié)調的客戶端請求時,這種模式通常會隨機出現(xiàn)。例如,假設有100個客戶端想要向同一個存儲服務器提交一個10kiB的寫事務。所有客戶端可能會以滿帶寬發(fā)送,因為他們不知道即將發(fā)生的擁塞。數(shù)據(jù)包將快速填滿網(wǎng)絡緩沖區(qū),可能妨礙其它流量,并最終違反服務級別協(xié)議(SLA)。最具挑戰(zhàn)性的incast模式是由于事務小于帶寬-延遲乘積而導致?lián)砣刂茩C制在事務完成之前無法獲得可靠的信號。我們指出,不斷增長的帶寬將越來越多的工作負載推入這個關鍵區(qū)域。
Oblivious bulk synchronous(OBS)
許多HPC和AI訓練工作負載可以采用無感知的批量同步模型(OBS)表示,其中計算步驟與通信步驟交替進行,通常同步進程。無感知意味著應用程序的通信模式取決于少量參數(shù)(如大小或進程數(shù)),并且不依賴于被處理的數(shù)據(jù)。它通常可以在應用程序啟動之前靜態(tài)確定。例如,消息傳遞接口(MPI)標準[7]中的所有集合操作都是無感知的。因此,OBS工作負載可以在算法上避免incast!深度學習訓練中的三維并行性[2]是一個典型的例子。OBS可以通過進程數(shù)、計算持續(xù)時間和通信大小(每個端點)建模。如果計算和通信都很小,那么整體工作負載對延遲敏感,這種模式在HPC和AI推理中經常出現(xiàn)。大型通信在AI訓練工作負載中通常具有帶寬敏感性。
Latency-sensitive (LS)
對于某些工作負載,消息延遲(有時也包括消息速率)起著核心作用。其中一些屬于OBS類別,但其它工作負載具有復雜的、數(shù)據(jù)相關的消息鏈,形成應用程序中的關鍵性能路徑。這些通常是強可伸縮性的工作負載,解決方案的時間很重要,必須容忍低效的執(zhí)行。嚴格遵守截止日期的大規(guī)模模擬,如天氣預報和石油勘探,屬于這一類別,但也包括一些事務處理或搜索/推理工作負載。在這種情況下,通常具有嚴格的(個位數(shù)微秒)延遲要求。
部署特性
除了流量類型外,部署環(huán)境也在發(fā)生變化。新出現(xiàn)的機密計算理念要求所有流量在傳輸過程中進行加密。理想情況下,流量在安全隔離環(huán)境中端到端進行加密和解密,不信任任何網(wǎng)絡設備(網(wǎng)卡或交換機)。此外,新出現(xiàn)的多租戶場景要求從單個主機管理數(shù)以萬計的連接。這些通常由管理資源(如帶寬和安全性)的智能網(wǎng)卡通過速率限制和過濾來支持。此外,新的成本效益高的低直徑和專用拓撲結構對于極高帶寬部署而言,更高級的負載平衡和路由成為必要條件[8],[2]。這些要求的許多組合對下一代高性能網(wǎng)絡提出了重大挑戰(zhàn)。
RoCE需要改進的方面
RoCE的許多問題已經在過去進行了討論[9],并且已經有許多研究工作提出了各種解決方案[10]。在這里,我們概述了我們認為可以進行改進的潛在措施,并將其與上述關鍵工作負載和部署用例聯(lián)系起來。我們現(xiàn)在提供一個列舉的問題列表,可以改進以實現(xiàn)在基于以太網(wǎng)的高性能RDMA或智能網(wǎng)卡系統(tǒng)中更高效的操作。
1)PFC需要過多的緩沖區(qū)來實現(xiàn)無丟包傳輸
優(yōu)先流控制(PFC)是實現(xiàn)融合以太網(wǎng)上無丟包傳輸?shù)暮诵摹Mㄟ^PFC,接收方監(jiān)視可用輸入緩沖區(qū)空間。一旦此緩沖區(qū)空間降低到與帶寬-延遲乘積BWRTT相關的某個閾值以下,它會向發(fā)送方發(fā)送一個PAUSE幀。此時,已經有BWRTT/2字節(jié)在傳入線上,但在發(fā)送方接收到PAUSE幀之前,它將發(fā)送另外BWRTT/2字節(jié)。完全無丟包傳輸所需的最小緩沖區(qū)要求將是BWRTT + MTU,其中MTU是數(shù)據(jù)包的最大大小。然而,這僅適用于數(shù)據(jù)包立即被接收方處理的情況。即使是最輕微的轉發(fā)延遲也可能顯著降低鏈路利用率。
BWRTT緩沖區(qū)空間用于覆蓋PAUSE消息的傳輸延遲,通常被稱為“剩余緩沖區(qū)”,類似于InfiniBand或光纖通道中使用的基于credit的流量控制方案所需的緩沖區(qū)。在這些方案中,接收方主動向發(fā)送方發(fā)送credit(緩沖區(qū)分配),以保持輸入緩沖區(qū)空間處于均衡狀態(tài),而不是在PFC使其過于充滿之后才作出反應。這兩種方案都有其優(yōu)點:credit可以主動地向源端傳遞,而PFC方案在為不同源鏈路分配共享緩沖區(qū)空間時可以更具反應性(延遲綁定)。這兩種方案基本上需要為每條鏈路保留BWRTT的空間,僅用于覆蓋鏈路的往返控制延遲,這樣就會導致有效轉發(fā)的空間減少。
實際上,緩沖區(qū)空間對于吸收不斷變化的流量峰值以進行時間和空間負載平衡非常寶貴。此外,僅僅是所需的剩余緩沖區(qū),如果不冒著丟包的風險,無法用于其它用途,對于下一代交換機的擴展構成了重大挑戰(zhàn)。圖1a顯示了在三層Fat Tree上,假設平均延遲為600ns(包括仲裁、前向糾錯(FEC)和導線延遲)的9kB數(shù)據(jù)包和8個流量優(yōu)先級類別(每個類別具有單獨的緩沖區(qū))的情況下,各種交換機世代所需的剩余空間(不包括其它緩沖區(qū)!)。隨著高性能地理復制數(shù)據(jù)中心的普及,覆蓋較長距離(從而引起延遲)也具有挑戰(zhàn)性。圖1b顯示了相同配置情況下,每個端口所需的剩余緩沖區(qū),假設端口速率為800G,導線延遲為5ns/m,以及不同的部署類型。
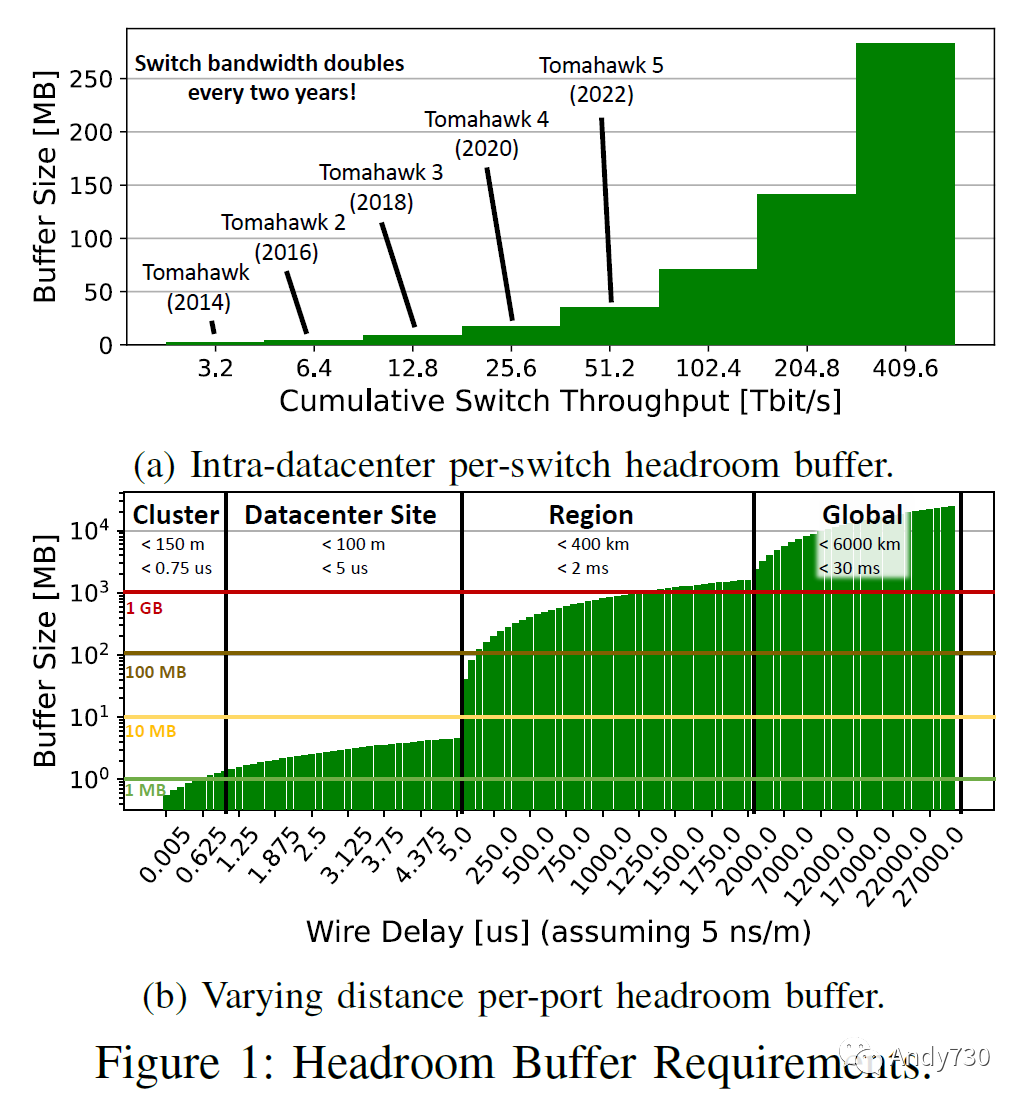
人們可能會考慮使用有丟失的鏈路層協(xié)議來重新利用這些緩沖區(qū)進行轉發(fā)功能。然而,這會與錯誤處理協(xié)議發(fā)生交互,我們很快將看到。無論如何,浪費的緩沖區(qū)空間是影響所有可能受益于附加緩沖區(qū)的工作負載的一般問題,如果這些空間可用于數(shù)據(jù)包轉發(fā),將會提供幫助。
2)受害者流、擁塞樹、PFC風暴和死鎖
另一個問題源于PFC停止整個流量類別(僅使用三個比特進行編碼)以及其中的所有流量。這可能導致受阻的受害者流:假設我們有兩個流A和B共享一個鏈路L。流A沒有擁塞,可以以滿帶寬發(fā)送。然而,流B在下游端口某處被阻塞,并填滿了鏈路L的輸入緩沖區(qū)。最終,鏈路L的分配緩沖區(qū)將被流B的數(shù)據(jù)包填滿,并發(fā)送一個PAUSE幀。該幀還會停止流A的傳輸,而流A本來可以獨立進行。因此,未擁塞的流可能會受到其它擁塞流的影響。這種現(xiàn)象也被稱為排頭堵塞(Head of Line blocking)。
由于下游端口的任何擁塞都會填滿上游緩沖區(qū),除非端點的擁塞控制協(xié)議作出反應,因此PFC事件可以快速形成逆向“擁塞樹”,跟隨網(wǎng)絡中受害流量的流動。擁塞樹是無丟包網(wǎng)絡中的一個普遍問題,有時被稱為PFC風暴。可以通過更細粒度地跟蹤擁塞情況來解決這個問題,例如在個別流量而不是優(yōu)先級的基礎上。然而,這要求網(wǎng)絡交換機維護流狀態(tài)以識別個別流量。另一種方法是嘗試將擁塞流動態(tài)地移動到擁塞優(yōu)先級中,以避免受害者(參見擁塞隔離,P802.1Qcz)。另一個問題是無丟包通道現(xiàn)在消耗了已經稀缺的流量類別(獨立的緩沖區(qū)空間)。這從數(shù)據(jù)中心提供商那里奪取了一個重要的資源,他們已經將這些流量類別用于差異化服務,如大流備份、低延遲視頻會議等。用于RoCE(或其它無丟包)流量的任何流量類別都會在整個網(wǎng)絡中丟失。
這種擁塞樹對于incast工作負載尤其成問題,它們可能會阻塞整個網(wǎng)絡,特別是在包級自適應或無感知路由的背景下。然而,在incast鏈路上,每個流量的帶寬非常低,這意味著理論上這些流量只需要很少的網(wǎng)絡緩沖區(qū)就可以飽和鏈路。RoCE擁塞控制的純速率特性允許源端注入(過多)的數(shù)據(jù)包,這些數(shù)據(jù)包會迅速填滿網(wǎng)絡緩沖區(qū)。例如,基于窗口的方案將允許管理員直接控制每個流的網(wǎng)絡范圍內的緩沖區(qū)占用情況。
任何具有有限緩沖區(qū)的無丟包方案都會遇到死鎖問題,如果路由允許形成循環(huán)。可以通過無環(huán)路由方案或特殊緩沖策略來避免死鎖,但這都會帶來一定的(小)成本。即使路由通常是無死鎖的,鏈路故障后發(fā)生的瞬態(tài)狀態(tài)也可能導致死鎖。避免這些情況更加困難,但可以通過在交換機中配置數(shù)據(jù)包超時來動態(tài)解決這個問題。
3)回退N(Go-back-N)重傳
RoCE的設計針對的是非常簡單的硬件,遵循InfiniBand的有序和基于credit的無丟包傳輸。這意味著數(shù)據(jù)包只有在被位錯誤破壞時才會丟失,這是非常罕見的事件。因此,重傳邏輯可以很簡單:如果接收方檢測到數(shù)據(jù)包流中的間隙(即跳過的序列號),它向發(fā)送方發(fā)送負確認(NACK)并丟棄所有后續(xù)數(shù)據(jù)包。然后發(fā)送方從丟失的數(shù)據(jù)包開始重新發(fā)送所有數(shù)據(jù)包。這個方案實際上丟棄并重傳了一個完整的端到端的BW*RTT(帶寬延遲乘積)的數(shù)據(jù)。
假設一個具有800Gb/s鏈路速度和最壞情況下每跳延遲為600ns的三層Fat Tree網(wǎng)絡。端點觀察到的總往返時間(RTT)將為3.6微秒。每條鏈路上的有效誤碼率可以高達1e-12(根據(jù)以太網(wǎng)規(guī)范提出的建議) ,我們假設使用9kiB的幀,單個幀丟失的概率為3.3e-8(有關推導請參見附錄A)。因此,由于回退N重傳而造成的總帶寬損失可以忽略不計,僅為0.00013%。
簡單的回退N重傳方案的一個更大問題是它不支持多路徑傳輸或無序傳輸。任何兩個經過的數(shù)據(jù)包都會觸發(fā)一次昂貴的重傳事件,導致整個BW*RTT傳輸丟失。最新一代的RoCE網(wǎng)絡接口卡引入了選擇性重傳來緩解這個問題。然而,這些功能通常是有限的。例如,NVIDIA的ConnectX6適配器不支持啟用選擇性重傳的標簽匹配的自適應路由。然而,回退N重傳具有一個有趣的優(yōu)勢:如果發(fā)生了位錯誤并且數(shù)據(jù)包在較低層次被(悄悄地)丟棄,一旦下一個數(shù)據(jù)包到達,錯誤就會立即被檢測到。而支持無序傳輸?shù)钠渌桨感枰却l(fā)送方的超時到期,這可能導致更長的恢復時間和抖動。因此,在設計新的傳輸協(xié)議時,需要仔細考慮所有這些權衡。
4)擁塞控制與其它流量的協(xié)同
RoCE的默認擁塞控制依賴于與無丟包傳輸假設密切相關的非常簡單的速率控制。許多研究人員已經意識到,這種簡單的機制與TCP/IP等其它流量集成不良,并且在數(shù)據(jù)中心環(huán)境中通常可以改進。諸如DCQCN [5]、TIMELY [6]和HPCC [4]之類的機制構建在RoCE之上,以改善流量的傳輸。目前大多數(shù)RoCE部署使用非標準的擁塞控制機制,這導致不同供應商之間甚至同一供應商的不同硬件版本之間的互操作性困難。這是因為擁塞控制仍然是一個棘手的問題,不同的工作負載可能需要協(xié)議的不同調優(yōu)版本。
例如,在無感知同步工作負載中,通常重復的端點非擁塞自由的大規(guī)模數(shù)據(jù)傳輸可以基于預期的流量模式進行快速學習甚至靜態(tài)配置[2],[13]。高度動態(tài)的incast場景需要通過接收方或網(wǎng)絡信號協(xié)調多個發(fā)送方。小于帶寬延遲乘積的小消息的延遲敏感工作負載可能是最棘手的,特別是如果它們以不可預測的數(shù)據(jù)驅動通信模式出現(xiàn)。這些可能需要依靠交換機緩沖區(qū)來吸收網(wǎng)絡級的臨時負載不平衡。總的來說,擁塞控制方案是并將繼續(xù)是研究的重點,即使在部署后也需要不斷進行調優(yōu)。與TCP或QUIC等不同類型的流量共存還需要不斷的采用。因此,這些方案不僅需要在硬件上快速和廉價,還需要靈活并支持廣泛的參數(shù)化設置。
另一方面的論點考慮了交換機的隊列大小和占用情況。數(shù)據(jù)中心交換機傳統(tǒng)上具有大容量(深度)的緩沖區(qū),以適應流量突發(fā)情況,而無需進行丟包來適應慢速的端到端速率調整。另一方面,用于HPC的交換機通常使用非常淺的緩沖區(qū)并具有嚴格的反向壓力,這是由于它們可靠的鏈路級流控制機制所決定的[3]。此外,HPC網(wǎng)絡拓撲通常具有比數(shù)據(jù)中心部署更低的直徑[14]。因此,HPC部署支持較低延遲操作,因為小的數(shù)據(jù)包不太可能在較長的流量后面的緩沖區(qū)中等待。采用RoCE的數(shù)據(jù)中心網(wǎng)絡通常在效率上結合了這兩者:它們使用了帶有所有問題的無丟包傳輸,而交換機的緩沖區(qū)相對較大。因此,許多現(xiàn)代擁塞控制機制的目標是保持緩沖區(qū)占用率較低,使這個非常昂貴的資源不被利用!
5)報頭大小、數(shù)據(jù)包速率、可擴展性
RoCEv2除了InfiniBand的基本傳輸頭(BTH)外,還使用了完整的以太網(wǎng)L2和UDP/IP報頭。因此,每個數(shù)據(jù)包的報頭開銷相當大:22字節(jié)的L2報頭、20字節(jié)的IP報頭、8字節(jié)的UDP報頭、12字節(jié)的BTH報頭和4字節(jié)的ICRC,總共為66字節(jié)。例如,本地路由的InfiniBand只有總報頭大小為20字節(jié):8字節(jié)用于本地路由報頭,12字節(jié)用于BTH報頭。其它HPC協(xié)議的報頭大小小于40字節(jié)。
這既影響原始數(shù)據(jù)包速率,也影響處理開銷和成本,因為復雜的報頭需要更多的報頭處理。僅僅對于小有效載荷的數(shù)據(jù)包速率可能是有問題的。假設我們以8字節(jié)消息為例,用于共軛梯度求解器的單元素約簡操作或精細全局圖更新。在800Gb/s的鏈路上,最大速率(不包括報頭)將達到12.5千億數(shù)據(jù)包每秒(Gpps)。使用InfiniBand報頭,速率將下降到3.5Gpps,使用RoCEv2報頭將下降到1.4Gpps。數(shù)據(jù)包中將近90%是報頭開銷!而我們忽略了用于MPI或RDMA終端的其它協(xié)議報頭。然而,鑒于目前的NIC數(shù)據(jù)包處理速度較慢(每個NIC小于1Gpps),報頭大小可能不是最大的問題。此外,NIC需要處理確認數(shù)據(jù)包,這對于選擇性確認和重傳協(xié)議可能是特別具有挑戰(zhàn)性的。高用戶級和協(xié)議消息速率要求在NIC中進行并行處理,考慮到時鐘速率的停滯。
RoCE的數(shù)據(jù)包格式與InfiniBand的傳輸層謂詞緊密相關,它的基本概念是隊列對(QP)之間的連接。單個連接的上下文狀態(tài)大小取決于實現(xiàn)細節(jié),但是大型集群的全互聯(lián)可能會有問題。每個隊列對至少需要保持連接信息和狀態(tài),如序列號、目標地址和隊列對號碼。連接狀態(tài)可能相對較大,在某些實現(xiàn)中可達1kB每個連接。
在對延遲敏感的工作負載中,小數(shù)據(jù)包通常很重要,其中一些工作負載受限于NIC發(fā)出新消息的速率。更精簡的報頭潛在地降低延遲并增加消息速率,同時允許更高效的帶寬利用率。
6)不支持智能堆棧
隨著網(wǎng)絡開銷在數(shù)據(jù)中心工作負載中變得更加重要,設計了更智能的堆棧。例如,QUIC協(xié)議允許將傳輸處理推向應用程序,應用程序可以定義特定于應用程序的協(xié)議。這使得可以為不同的服務需求運行不同的協(xié)議,例如對延遲不敏感的視頻流,對延遲敏感的音頻會議,或者通常具有彈性但大型備份流量。RoCE的硬件加速哲學不支持不同的傳輸協(xié)議,即使用戶級堆棧能夠指定流量的其它屬性(例如,將消息標記為對亂序傳遞具有彈性)。
新興的智能網(wǎng)卡在這一領域帶來了新的機會,用戶可配置的內核可以在網(wǎng)卡上執(zhí)行數(shù)據(jù)包和協(xié)議處理[15]。此外,網(wǎng)絡中的遙測(INT)可以為這些協(xié)議提供額外的信號以做出相應的反應。因此,即使堆棧對流量類型有額外的了解,當前的RoCE也將其限制在相對簡單且不靈活的協(xié)議中,無法充分利用這些知識。
7)安全性
RoCE已知存在一些安全問題[16],[17],特別是在多租戶環(huán)境中。其中許多問題源于協(xié)議的安全性、身份驗證和加密在設計時的次要地位。然而,今天,這些屬性變得更加重要。
IPSEC可以用于保護L3報頭和有效載荷,但需要基于每個隊列對啟用,以確保沒有兩個租戶共享一組密鑰。這在連接上下文開銷和性能方面可能相當昂貴。此外,RoCE不支持將內存區(qū)域子委托給其它節(jié)點。這兩個問題可以通過現(xiàn)代密鑰派生協(xié)議來解決[16]。
8)鏈路級可靠性
向更高的收發(fā)器速度邁進導致了在不斷增長的頻率下運行的更復雜的編碼和調制方案。在50G通道上,以太網(wǎng)從簡單的兩電平NRZ轉移到了四電平PAM4編碼。如今的100G通道以25GHz運行,接收器需要在納秒級內區(qū)分四個電平。電纜和連接器中的信號衰減以及越來越復雜的模擬電路導致比特錯誤率(BER)很快會達到1e-4的高水平。
前向糾錯(FEC)被引入以避免由于網(wǎng)絡中丟棄損壞的數(shù)據(jù)包而導致過多的端到端重傳。以太網(wǎng)在鏈路層目標為1e-12的誤碼率(BER),目前使用Reed-Solomon編碼,使用包含514個這樣的符號的塊,以及30個附加的編碼符號(RS544)。這使得接收器能夠糾正15個隨機比特錯誤和最多150個連續(xù)(突發(fā))比特錯誤。其它FEC編碼,如LLFEC(RS272,RS544的一半大小)和Firecode提供較低的延遲,但對比特錯誤的保護也較低。
一般來說,F(xiàn)EC帶來的延遲和能耗成本分為兩類:(1)累積5,140比特的數(shù)據(jù)和(2)編碼和解碼編碼符號。前者隨著鏈路帶寬的增加而減少,后者取決于實現(xiàn),實際上的延遲在20到100納秒之間。圖2顯示了不同鏈路帶寬下的預期RS544 FEC情況。
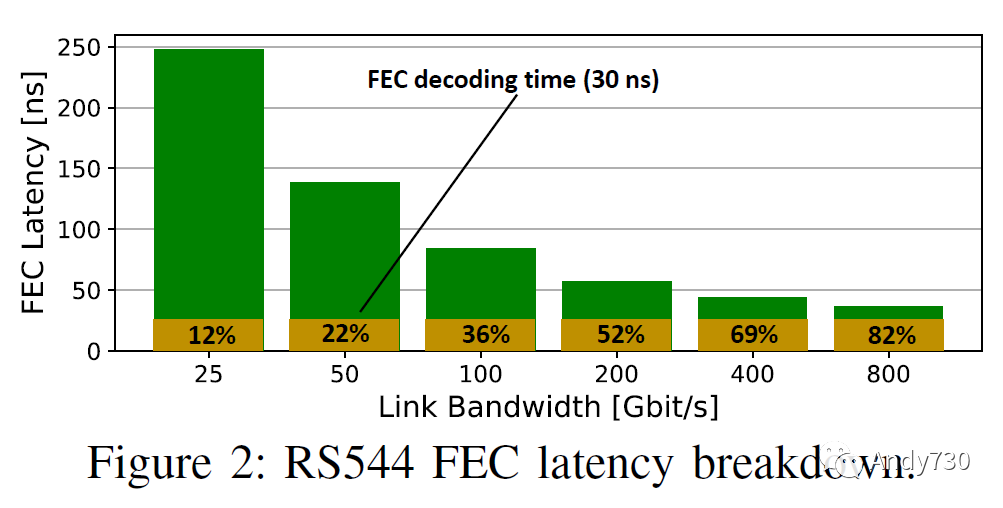
對于固定的RS544 FEC,延遲隨著更快的鏈路帶寬而減少,但不會低于FEC計算開銷。然而,更快的通道可能導致顯著更高的比特錯誤率。事實上,RS544可能無法將預期的1e-4的BER糾正到所需的1e-12。因此,未來的以太網(wǎng)標準可能采用更復雜的FEC機制,這可能會顯著增加延遲。
在PCIe中使用了一種替代方法,它也涉及由于復雜連接器而導致的相對較高的BER,但它被設計為低延遲的本地互連,目標延遲約為5納秒。例如,即將推出的PCIe 6.0規(guī)范使用6個字節(jié)的FEC來保護242字節(jié)的塊,還有額外的8字節(jié)CRC。接收器首先使用FEC來糾正一些比特錯誤,然后檢查CRC。如果此檢查失敗,它將啟動一個簡單的鏈路層重傳協(xié)議以再次請求數(shù)據(jù)。FEC將比特錯誤率從1e-4降低到1e-6,然后CRC觸發(fā)的重傳概率小于1e-5。由于FEC導致的延遲增加不到2納秒,由于重傳導致的帶寬減少不到2%。以太網(wǎng)面臨的挑戰(zhàn)是更長的鏈路導致更高的鏈路延遲。
系統(tǒng)問題
不斷增長的鏈路級和因此的端到端延遲可能導致系統(tǒng)級問題增加。較高的延遲導致更高的緩沖區(qū)占用和能耗。不太明顯的是,較高的延遲導致?lián)砣刂菩式档停簜鬏斔俣瓤煊趩蝹€往返時間(RTT)的消息無法從依賴接收器通知的擁塞控制機制中受益。因此,對于具有小消息的不良incast情況來說,情況變得更糟或至少更常見,因為“小消息”的大小增加。圖3顯示了當前數(shù)據(jù)中心中一些實際延遲下的帶寬延遲乘積的大小,顯示即使對于1 MiB的消息,通過限制發(fā)送者的速度來有效處理incast仍然被認為“太小”。因此,具有較高延遲的問題性incast模式可能會變得更加常見!
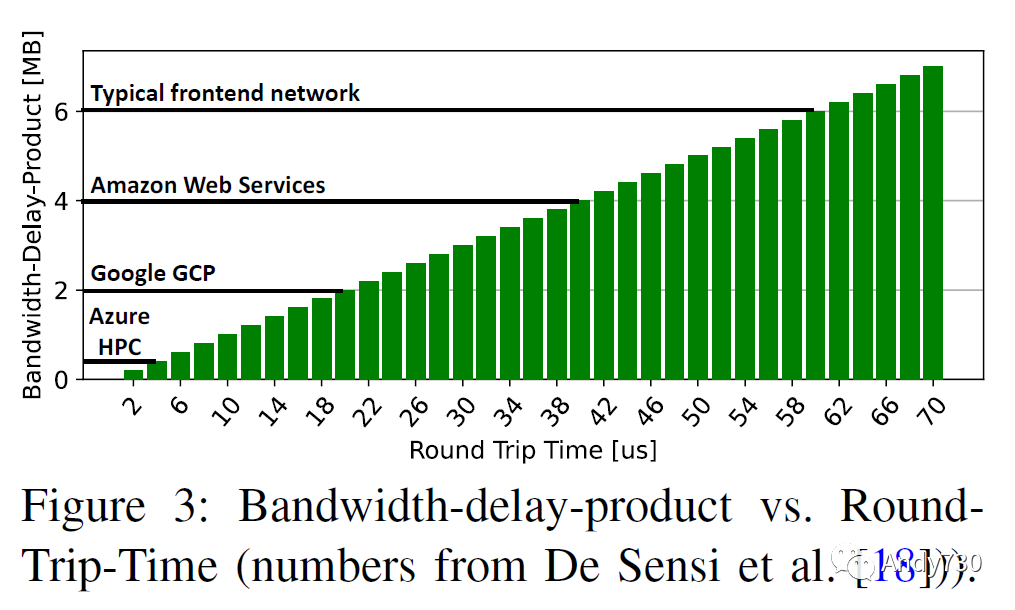
換句話說,如果系統(tǒng)可以快速地限制發(fā)送者的速度,那么可以將消息大小降低到incast成為問題的下限以下。這可以通過降低延遲或讓交換機直接向源報告incast擁塞(而不經過接收器)來實現(xiàn)。此外,如果只有非常小的消息會導致糟糕的incast情況,那么交換機緩沖區(qū)可能在常見情況下僅吸收它們,而不會耗盡資源。當沿著incast樹傳播時,多組交換機緩沖區(qū)可以吸收瞬態(tài)incast消息,當然,這可能導致網(wǎng)絡中的擁塞樹。這樣的整體系統(tǒng)問題仍然是一個開放的討論話題,但似乎較低的延遲通常會簡化這些問題。
還需要關注整體堆棧的其它方面,這些方面可能相當復雜。例如,簡單而清晰的(遠程)內存語義很難定義、推理和正確實現(xiàn)[19]。此外,將進程本地虛擬地址暴露給遠程主機可能會對安全性和性能造成問題。可以考慮使用相對于內存區(qū)域的尋址方案[20]。從安全性的角度來看,這兩種方案都有其弱點:暴露地址可以了解遠程進程的信息,然而對于攻擊者來說,固定偏移量更容易猜測[17]。我們指出,這些問題是所有RDMA系統(tǒng)的普遍問題,而不僅僅是RoCE。
路由和負載均衡仍然是一個開放性挑戰(zhàn)-大多數(shù)HPC網(wǎng)絡使用具有相對先進的網(wǎng)絡內部機制的分組級自適應路由[3],而大多數(shù)數(shù)據(jù)中心網(wǎng)絡使用簡單的由端點驅動的無感知ECMP,它通過更改頭字段以非常簡單的方式指導路徑選擇。數(shù)據(jù)中心中這種ECMP負載均衡的粒度從傳統(tǒng)上的完整流量到最近考慮的流塊都有。流塊是具有足夠間隙的連續(xù)數(shù)據(jù)包序列,即使沿不同路徑發(fā)送,它們也無法相互交錯。這種間隙可以通過延遲數(shù)據(jù)包或自然產生。最近,數(shù)據(jù)中心網(wǎng)絡正朝著更細粒度的負載均衡機制發(fā)展。另一個挑戰(zhàn)是一些應用程序要求按順序傳遞消息。總的來說,亂序的粒度和能力嚴重依賴于應用程序的要求和端點NIC的能力。更細粒度和更好的亂序能力簡化了網(wǎng)絡負載均衡。
預測
基于所有這些觀點,我們預測學術界和行業(yè)將重新審視數(shù)據(jù)中心以太網(wǎng)。下一代以太網(wǎng)可能會支持有損和無損的RDMA連接傳輸模式,以允許智能交換機緩沖區(qū)管理。這將使提供預留空間緩沖區(qū)成為可選項,并避免無損網(wǎng)絡的其它問題,如受害流和擁塞樹。下一代以太網(wǎng)也不太可能采用Go-Back-N的重傳語義,而是選擇更細粒度的機制,如選擇性確認。此外,它可能會將擁塞管理作為規(guī)范的一部分。對于與其它流共存的情況,將特別注意,尤其是在有損流量類別中。這些協(xié)議將以靈活的方式設計,以支持智能的網(wǎng)絡堆棧,安全性將最終成為重要的一環(huán)。我們還可能在報頭和可靠性方法方面看到創(chuàng)新。
這些現(xiàn)代化將推動人工智能、高性能計算和存儲系統(tǒng)的新一代高性能網(wǎng)絡生態(tài)系統(tǒng),這些系統(tǒng)是超大規(guī)模數(shù)據(jù)中心的核心。這種發(fā)展將結束HPC和數(shù)據(jù)中心網(wǎng)絡的融合!
審核編輯:劉清
-
以太網(wǎng)
+關注
關注
41文章
6097瀏覽量
181341 -
人工智能
+關注
關注
1819文章
50207瀏覽量
266429 -
有線局域網(wǎng)
+關注
關注
0文章
4瀏覽量
6065 -
RDMA
+關注
關注
0文章
100瀏覽量
9651 -
TCP通信
+關注
關注
0文章
146瀏覽量
4870
原文標題:數(shù)據(jù)中心以太網(wǎng)和RDMA:超大規(guī)模環(huán)境下的問題
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
WBS Power推進3.2吉瓦超大規(guī)模數(shù)據(jù)中心園區(qū)能源基礎設施建設
中科曙光scaleX萬卡超集群重塑超大規(guī)模算力基礎設施
淺談新一代數(shù)據(jù)中心先進熱管理策略
數(shù)據(jù)中心 / 工業(yè)車間通用:RJ45+POE 以太網(wǎng)溫濕度傳感器選型手冊
RDMA設計12:融合以太網(wǎng)協(xié)議棧設計1
新思科技VIP全面支持超以太網(wǎng)與UALink協(xié)議
NVIDIA Spectrum-X 以太網(wǎng)交換機助力 Meta 和 Oracle 加速網(wǎng)絡性能

睿海光電以高效交付與廣泛兼容助力AI數(shù)據(jù)中心800G光模塊升級
AI網(wǎng)絡管理新范式:精要解讀超以太網(wǎng)聯(lián)盟(UEC)1.0 規(guī)范(2025Q2)

偉創(chuàng)力高效電源模塊在超大規(guī)模數(shù)據(jù)中心的應用
RDMA簡介3之四種子協(xié)議對比
RDMA簡介1之RDMA開發(fā)必要性
是德科技解讀IEEE P802.3dj最新以太網(wǎng)標準

納微半導體推出12kW超大規(guī)模AI數(shù)據(jù)中心電源
BDx成功融資助力香港超大規(guī)模數(shù)據(jù)中心擴建
- 設計技術
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術
- 測量儀表
- 嵌入式技術
- 制造/封裝
- 模擬技術
- RF/無線
- 接口/總線/驅動
- 處理器/DSP
- EDA/IC設計
- 存儲技術
- 光電顯示
- EMC/EMI設計
- 連接器
- 行業(yè)應用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設備
- 機器人
- 安全設備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 電子發(fā)燒友
- 關于我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡
- 微博
- 移動端
- 發(fā)燒友APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內容合作
- 張迎輝:mikezhang@elecfans.com
-
關注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察

版權所有 ? 長沙勒克斯教育咨詢有限公司
湖南省長沙市開福區(qū)月湖街道匍園路20號聚恒科技園1棟2301-1房
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023036445號-105-1
工商網(wǎng)監(jiān)
湘ICP備2023036445號-105-1
評論