") CVPR 2023中的領(lǐng)域適應(yīng): 通過自蒸餾正則化實現(xiàn)內(nèi)存高效的CoTTA
CVPR 2023中的領(lǐng)域適應(yīng): 通過自蒸餾正則化實現(xiàn)內(nèi)存高效的CoTTA

CVPR 2023 中的領(lǐng)域適應(yīng): 通過自蒸餾正則化實現(xiàn)內(nèi)存高效的 CoTTA
目錄
前言
內(nèi)存比較
EcoTTA 實現(xiàn)
Memory-efficient Architecture
Self-distilled Regularization
實驗
分類實驗
分割實驗
總結(jié)
參考
前言
我們介紹了 CoTTA 方法,這次介紹的是基于它的優(yōu)化工作:EcoTTA,被接受在 CVPR 2023 上。
推薦閱讀順序是:
CoTTA
本篇文章
DIGA
上一篇文章我們提到 CoTTA 的輸入是隨時間軸變化的數(shù)據(jù)(比如自動駕駛中不斷切換的天氣條件),且是測試伴隨訓(xùn)練任務(wù)。所以,CoTTA 通常在內(nèi)存有限的邊緣設(shè)備上進行,因此減少內(nèi)存消耗至關(guān)重要。先前的 TTA 研究忽略了減少內(nèi)存消耗的重要性。此外,上一篇文章也提到了長期適應(yīng)通常會導(dǎo)致災(zāi)難性的遺忘和錯誤積累,從而阻礙在現(xiàn)實世界部署中應(yīng)用 TTA。
EcoTTA 包括解決這些問題的兩個組成部分。第一個組件是輕量級元網(wǎng)絡(luò),它可以使凍結(jié)的原始網(wǎng)絡(luò)適應(yīng)目標域。這種架構(gòu)通過減少反向傳播所需的中間激活量來最大限度地減少內(nèi)存消耗。第二個組成部分是自蒸餾正則化,它控制元網(wǎng)絡(luò)的輸出,使其與凍結(jié)的原始網(wǎng)絡(luò)的輸出不顯著偏離。這種正則化可以保留來自源域的知識,而無需額外的內(nèi)存。這種正則化可防止錯誤累積和災(zāi)難性遺忘,即使在長期的測試時適應(yīng)中也能保持穩(wěn)定的性能。
內(nèi)存比較
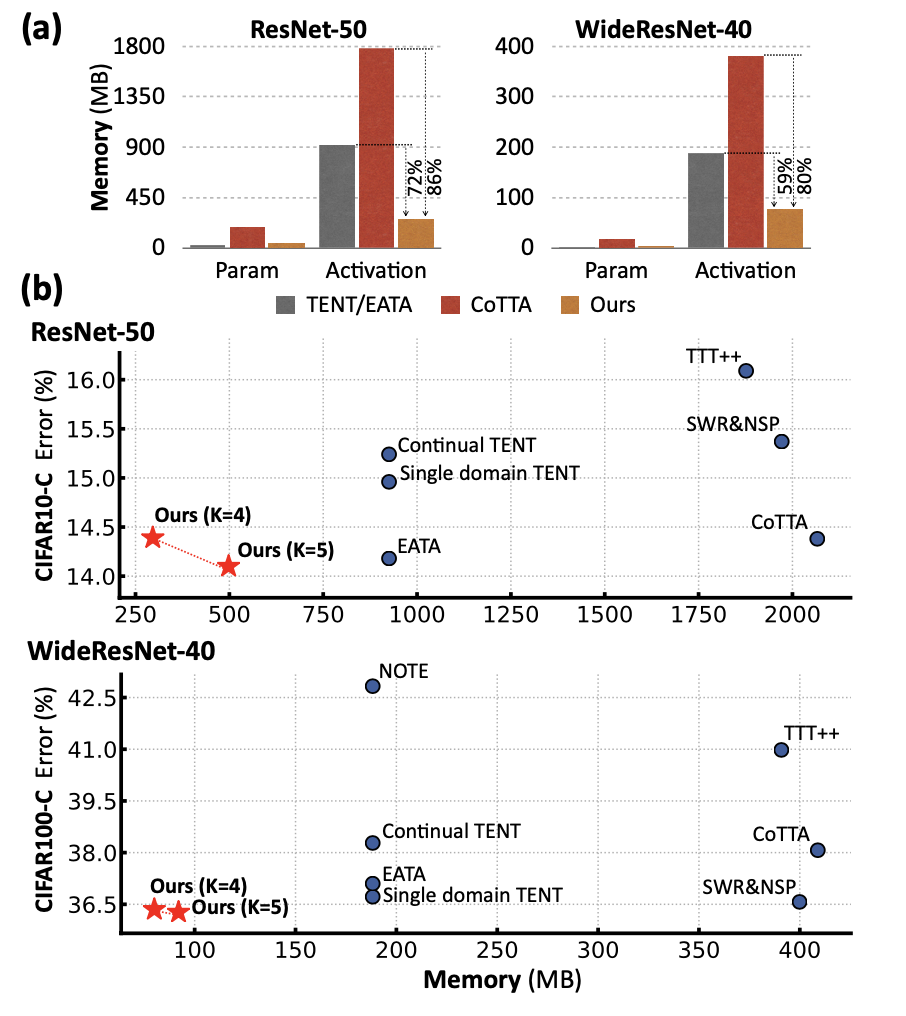
首先,我們先看一下 EcoTTA 和其他方法的內(nèi)存比較。下圖(a)表示在訓(xùn)練過程中,與參數(shù)相比,激活的大小是主要的內(nèi)存瓶頸。下圖(b)中,x 軸和 y 軸分別表示所有平均誤差和總內(nèi)存消耗,包括參數(shù)和激活。對 CIFAR-C 數(shù)據(jù)集進行連續(xù)的在線適應(yīng),EcoTTA在消耗最少的內(nèi)存的同時取得了最佳結(jié)果。這里我們發(fā)現(xiàn),作者全文的實驗只對比了類 ResNet 架構(gòu),而 CoTTA 中性能最高的架構(gòu)是 SegFormer。
EcoTTA 實現(xiàn)
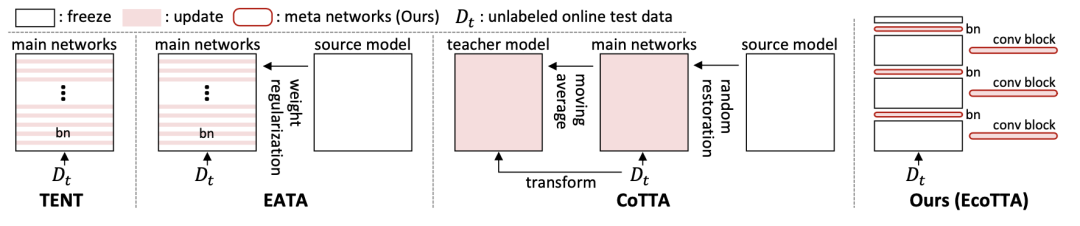
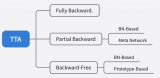
關(guān)于相關(guān)工作的部分,我們已經(jīng)在 CoTTA 中介紹過了。將 EcoTTA 的策略和其他方法(都是 TTA 的)對比如下圖,包括 TENT、EATA 和 CoTTA。TENT 和 EATA 更新了多個 BN 層,這需要存儲大量激活以進行梯度計算。這可能會導(dǎo)致內(nèi)存問題,尤其是在內(nèi)存有限的邊緣設(shè)備上。CoTTA 使用額外的持續(xù)適應(yīng)策略來訓(xùn)練整個網(wǎng)絡(luò),這需要大量的內(nèi)存和時間。相比之下,EcoTTA 要求通過僅更新幾層來最大限度地減少激活量。這減少了內(nèi)存消耗,使其適用于內(nèi)存有限的邊緣設(shè)備。
下面我們關(guān)注 EcoTTA 兩個部分的實現(xiàn)。
Memory-efficient Architecture
假設(shè)模型中的第 i 個線性層由權(quán)重 W 和偏置 b 組成,該層的輸入特征和輸出特征分別為 fi 和 fi+1。給定 fi+1 = fiW + b 的前向傳播,從第 i+1 層到第 i 層的反向傳播和權(quán)重梯度分別制定為:
意味著需要更新權(quán)重 W 的可學(xué)習(xí)層必須存儲中間激活 fi 以計算權(quán)重梯度。相反,凍結(jié)層的反向傳播可以在不保存激活的情況下完成,只需要其權(quán)重 W。
相對于可學(xué)習(xí)參數(shù),激活占據(jù)了訓(xùn)練模型所需內(nèi)存的大部分。基于這個事實,CoTTA 需要大量的內(nèi)存(因為要更新整個 model)。另外,僅僅更新 BN 層中的參數(shù)(例如 TENT 和 EATA)并不是一種足夠有效的方法,因為它們?nèi)匀槐4媪硕鄠€ BN 層的大量中間激活。EcoTTA 提出了一種簡單而有效的方法,通過丟棄這些激活來顯著減少大量的內(nèi)存占用。
在這里插入圖片描述
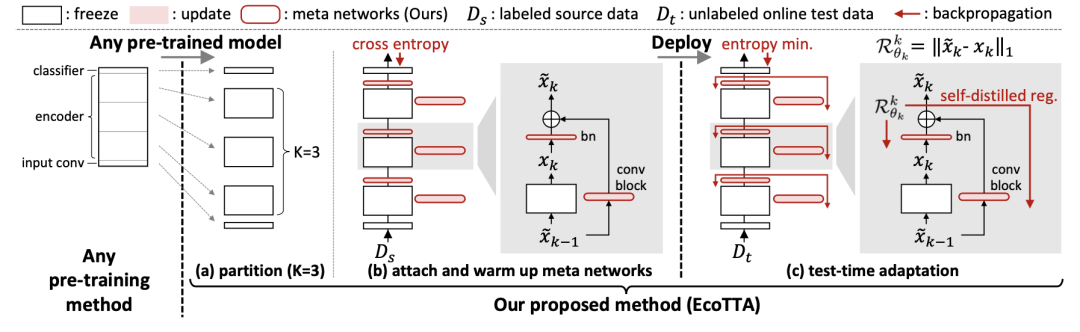
在部署之前,我們首先使用任何預(yù)訓(xùn)練方法獲取一個預(yù)訓(xùn)練模型。然后,我們將預(yù)訓(xùn)練模型的編碼器分成 K 個部分,如上圖(a)所示。一個元網(wǎng)絡(luò)組由一個批歸一化層和一個卷積塊(ConvBN-Relu)組成,將輕量級元網(wǎng)絡(luò)附加到原始網(wǎng)絡(luò)的每個部分上,如上圖(b)所示。我們在源數(shù)據(jù)集上對元網(wǎng)絡(luò)進行預(yù)訓(xùn)練,同時凍結(jié)原始網(wǎng)絡(luò)。這個預(yù)熱過程完成后,我們可以進行模型部署。強調(diào)一點,在測試時不需要源數(shù)據(jù)集 Ds,所以本質(zhì)上還是 TTA 的范式。更詳細的元網(wǎng)絡(luò)組成如下:
在這里插入圖片描述
此外,我們需要預(yù)訓(xùn)練模型的幾個分區(qū)。先前解決域偏移的 TTA 研究表明,相對于更新深層,更新淺層對于改善適應(yīng)性能更為關(guān)鍵。受到這樣的發(fā)現(xiàn)啟發(fā),假設(shè)預(yù)訓(xùn)練模型的編碼器被劃分為模型分區(qū)因子 K(例如 4 或 5),我們將編碼器的淺層部分(即 Dense)相對于深層部分進行更多的劃分,表現(xiàn)如下表所示。
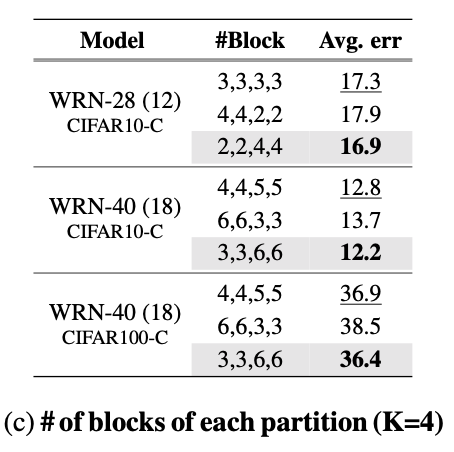
在這里插入圖片描述
在部署期間,我們只對目標域適應(yīng)元網(wǎng)絡(luò),而凍結(jié)原始網(wǎng)絡(luò)。適應(yīng)過程中,我們使用熵最小化方法對熵小于預(yù)定義閾值的樣本進行適應(yīng),計算方法如下面的公式所示,并使用自提出的正則化損失來防止災(zāi)難性遺忘和錯誤累積。
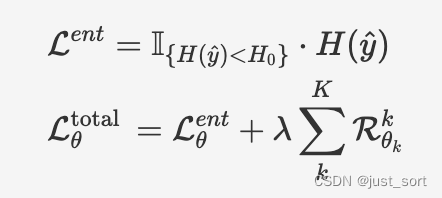
在這里插入圖片描述
在第二個公式中,左右兩項分別表示適應(yīng)損失(主要任務(wù)是適應(yīng)目標域)和正則化損失。整體而言,EcoTTA 在內(nèi)存使用方面比之前的工作更加高效,平均使用的內(nèi)存比 CoTTA 和 TENT/EATA 少 82% 和 60%。
Self-distilled Regularization
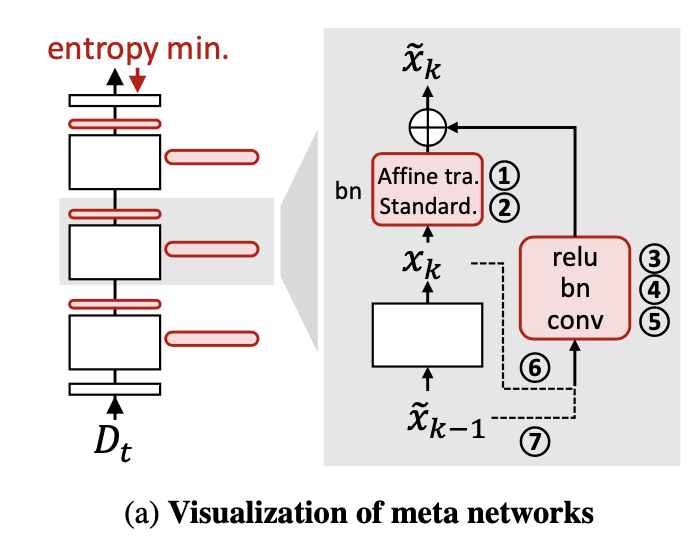
無標簽測試數(shù)據(jù)集 Dt 上的無監(jiān)督損失往往會向模型提供錯誤的信號(即噪聲,,其中 是測試樣本的真實標簽)。使用無監(jiān)督損失進行長期適應(yīng)會導(dǎo)致過擬合(由于誤差累積)和災(zāi)難性遺忘的問題。為了解決這些關(guān)鍵問題,EcoTTA 提出了一種自蒸餾正則化方法。如上圖(c)所示,對每個元網(wǎng)絡(luò)的第 k 組輸出 進行正則化,使其與凍結(jié)的原始網(wǎng)絡(luò)的第 k 部分輸出 保持接近。正則化損失使用平均絕對誤差(L1 Loss)進行計算,表達式如下:
由于原始網(wǎng)絡(luò)不會被更新,從中提取的輸出 , k~K 被認為包含了從源域?qū)W到的知識。利用這個事實,通過將元網(wǎng)絡(luò)的輸出 與原始網(wǎng)絡(luò)的輸出進行知識蒸餾的方式進行正則化。也就是說,防止適應(yīng)模型與原始模型顯著偏離,可以避免災(zāi)難性遺忘。通過保留源域知識和利用原始模型的類別區(qū)分度,避免誤差累積。值得注意的是,與先前的方法不同,自蒸餾正則化方法無需保存額外的原始網(wǎng)絡(luò),它只需要很少的計算量和內(nèi)存開銷。
實驗
分類實驗
下表是在 CIFAR-C 數(shù)據(jù)集上的錯誤率比較結(jié)果。包括連續(xù) TTA 上處理了 15 種不同的損壞樣本后的平均錯誤率,并考慮了模型參數(shù)和激活大小所需的內(nèi)存。其中,還使用了 AugMix 數(shù)據(jù)處理方法來增強模型的魯棒性。Source 表示未經(jīng)過適應(yīng)的預(yù)訓(xùn)練模型。single domain的 TENT 是在適應(yīng)到新的目標域時重置模型(因為這篇論文和 CoTTA 都是在 domian flow 的 setting 下考慮的,而不是 single domain),因此需要使用域標簽來指定目標域。
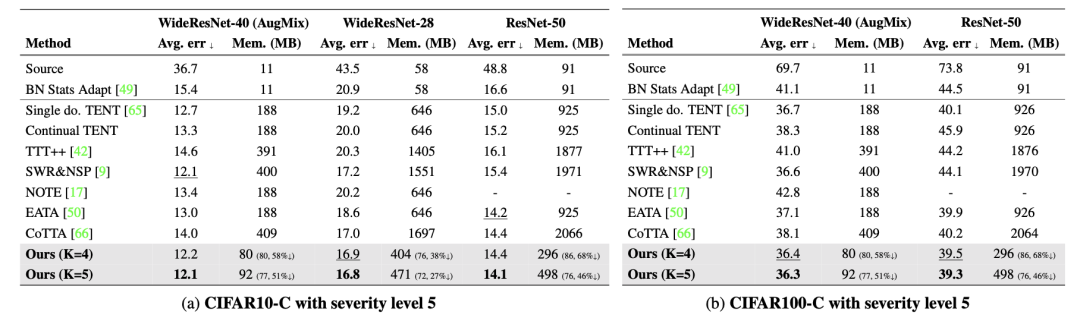
在這里插入圖片描述
下表是 ImageNet 到 ImageNet-C 的結(jié)果:
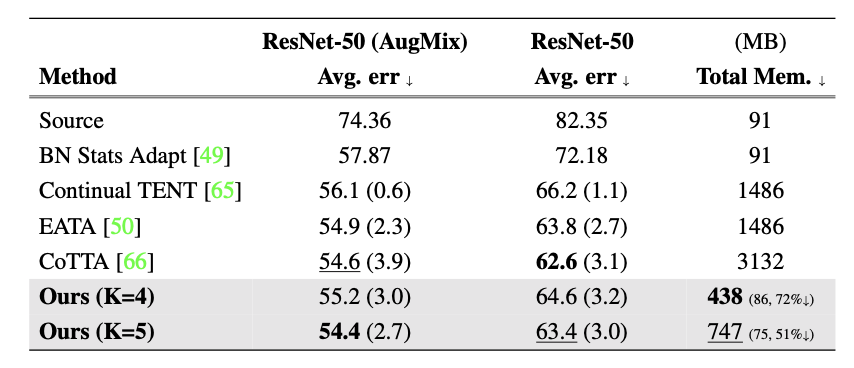
在這里插入圖片描述
分割實驗
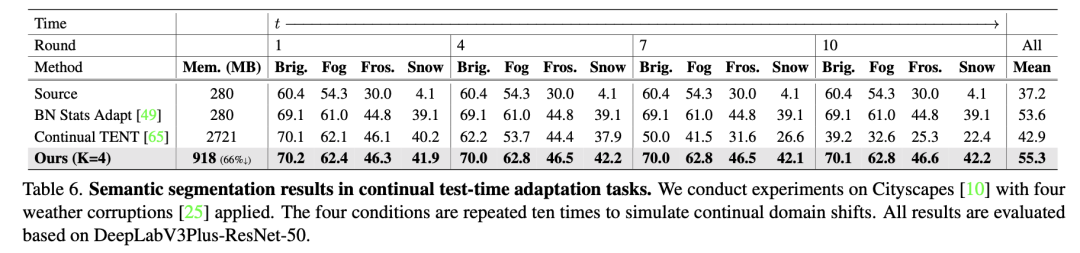
下表是分割實驗的對比結(jié)果,可以發(fā)現(xiàn)沒有和 CoTTA 比較,因為 EcoTTA 沒有用和 CoTTA 一樣的 backbone: Segformer,而是 ResNet family。這里我的考慮是,在 Segformer 上性能提高可以可能不明顯,并且 Segformer 的內(nèi)存占用更大。
在這里插入圖片描述
總結(jié)
這個工作改進了 CoTTA 的性能并節(jié)省了大量內(nèi)存,適用于內(nèi)存有限的邊緣設(shè)備(例如,具有 512MB 的樹莓派和具有 4G B的 iPhone 13)。首先,提出了一種內(nèi)存高效的架構(gòu),由原始網(wǎng)絡(luò)和元網(wǎng)絡(luò)組成。通過減少用于梯度計算的中間激活值,該架構(gòu)所需的內(nèi)存大小比先前的 TTA 方法要小得多。其次,在解決長期適應(yīng)問題中,提出了自蒸餾正則化方法,以保留源知識并防止由于噪聲的無監(jiān)督損失導(dǎo)致的錯誤累積。該方法通過控制元網(wǎng)絡(luò)的輸出與原始網(wǎng)絡(luò)的輸出沒有顯著偏離來實現(xiàn)。通過對多個數(shù)據(jù)集和主干網(wǎng)絡(luò)進行廣泛的實驗證明了 EcoTTA 的內(nèi)存效率和 TTA 上的性能。
參考
https://arxiv.org/abs/2303.01904
https://mp.weixin.qq.com/s/kWzXWENTTBKHKZxKKECdlQ
-
內(nèi)存
+關(guān)注
關(guān)注
9文章
3210瀏覽量
76375 -
架構(gòu)
+關(guān)注
關(guān)注
1文章
532瀏覽量
26590 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1236瀏覽量
26196
原文標題:CVPR 2023 中的領(lǐng)域適應(yīng): 通過自蒸餾正則化實現(xiàn)內(nèi)存高效的 CoTTA
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是正則表達式?正則表達式如何工作?哪些語法規(guī)則適用正則表達式?
一種基于機器學(xué)習(xí)的建筑物分割掩模自動正則化和多邊形化方法
喜訊!華秋榮獲2023中國產(chǎn)業(yè)數(shù)字化百強榜企業(yè)
華秋榮獲2023中國產(chǎn)業(yè)數(shù)字化百強榜企業(yè)
自適應(yīng)正則化項去除乘性噪聲

dropout正則化技術(shù)介紹
基于正則化超分辨率的自適應(yīng)閾值去噪方法
自適應(yīng)正則化活動輪廓模型
詳解機器學(xué)習(xí)和深度學(xué)習(xí)常見的正則化
正則化方法DropKey: 兩行代碼高效緩解視覺Transformer過擬合
CoTTA的新方法:用于在非平穩(wěn)環(huán)境下進行持續(xù)的測試時間適應(yīng)



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論